

こんにちは。SCSKの松渕です。
Google Cloudでファインチューニングが簡単に実装できると聞いたので、実践してみたいと思います。
はじめに
ファインチューニングとは
ファインチューニングとは、事前学習済みの大規模言語モデル(LLM)を、特定のタスクやデータセットに合わせて、追加で学習・調整することです。
これは、モデルの基本的な知識や言語能力を活かしつつ、特定の用途(例:社内文書の要約、特定のトーンでの応答、固有の知識の習得)に特化させるために行われます。
なんだか、RAGとの違いがよく分からないですね。ということでRAGとの違い、使い分けを整理します。
RAGとの違い
Geminiに整理いただきました。
| 特徴 | RAG (検索拡張生成) | ファインチューニング (モデル調整) |
| 目的 | 最新・専門の外部情報に基づいて、正確な回答を生成すること。 | モデルの振る舞い(スタイル、トーン、出力形式)やドメイン知識を改善すること。 |
| 仕組み | 質問と関連性の高い外部文書を検索し、その文書をプロンプトに追記してLLMに入力する。モデル自体は変化しない。 | カスタムデータを使ってモデルの重み(パラメータ)を更新し、モデルを恒久的に変更する。 |
| 必要なデータ | 検索対象となる参照文書(PDF、社内文書、データベースなど)。 | 高品質な質問と回答のペアや指示データ。 |
| コスト/時間 | 低い。主に検索システム(ベクトルデータベースなど)の構築・維持費用。 | 高い。大量のGPUリソースと時間が必要(特にベースモデルが大きい場合)。 |
| 更新頻度 | 容易。参照文書を更新するだけで、即座に結果に反映される。 | 困難。データが更新されるたびに、トレーニングをやり直す必要がある。 |
| 学習限界 | モデルが参照文書にない情報を生成することはできない。 | モデルが学習データに含まれない知識(新しい事実)を知ることはできない。 |
RAGのほうが向いているケース
- 情報が頻繁に更新される
- 情報の出典を明確化したい
※どのドキュメントの何ページ目 まで出典明記したい場合、チャンク化やメタデータ設計を適切に実施する必要あり - 事実の正確性が最重要(ハルシネーション対策)
ファインチューニングのほうが向いているケース
- 特定のスタイルやトーンの統一(jsonなどの出力形式の固定なども可能)
- トークン効率の改善。モデルのプロンプトサイズを削減し、コストとレイテンシを改善したい場合
ハイブリッド(RAG + ファインチューニング)
上記参照いただくとわかる通り、RAGとファインチューニングは二者択一のものではありません。これら二つを組み合わせることで、
ファインチューニングでモデルに出力形式とスタイルを学習させ、RAGでモデルに最新かつ正確な事実を提供する、カスタムAIシステムを構築できます。
今回実装する方式について
今回は、Google Cloudで簡単にファインチューニングできる教師ありファインチューニングサービスを利用します!
詳細は以下参照ください。
Gemini モデルの教師ありファインチューニングについて(Google Cloud ドキュメント)
事前準備
やりたいことを整理
何より大事ですね。RAGとの使い分けの部分の調査から、Geminiの応答口調を調整してみようと思います。
小難しいカタカナ英語ばっかり使うようにファインチューニングします。
データさえあれば、「〇〇さんっぽく応答してくるAI」とかは盛り上がること間違いなし!
データの準備
学習大規模言語モデル(LLM)のファインチューニングには、対話形式のデータセットを学習用データとして準備する必要があります。
特定のタスク(この場合は要約)をモデルに学習させるための入力(ユーザーのプロンプト)と、それに対する理想的な出力(モデルの応答)のペアとして構成されています。
Google社が提供している学習データのサンプルがこちら。JSON Lines形式で記載されています。
私が準備した学習データの一行抜粋します。(私は今回、Gemini使って400行程度準備してもらいました)
{“contents”: [{“role”: “user”, “parts”: [{“text”: “業務の引き継ぎで失敗しないためには?”}]}, {“role”: “model”, “parts”: [{“text”: “タスクのスコープとネクストアクションをマストで文書化し、クリティカルなプロセスは複数のメンバーでコンセンサスを取るべきです。”}]}]}
実際に言われたら、私なら思わず聞き返してしまうかもしれません。
1行で対話のひとつのターン(発話)を表しています。
"role": "user":この発話がユーザー(入力側)からのものであることを示しています。"parts": [...]:発話の内容(テキストや画像など)を格納する配列です。"text": "...":ユーザーがモデルに与えた指示(プロンプト)の本文です。
この例では、「業務の引き継ぎで失敗しないためには?」という文章です。
"role": "model":この発話がモデル(出力側)の理想的な応答であることを示しています。"text": "...":モデルがこのプロンプトに対して学習すべき正解の回答です。
小難しい横文字ばかり使ってますね。
データ数としては、100 個のサンプルから始めて、必要に応じて数千にスケールすることをおすすめします。データセットは量よりも質のほうがはるかに重要です。
Gemini モデルの教師ありファインチューニング データを準備する(Google Cloud ドキュメント)
ファインチューニング実施
ファインチューニング開始
「Vertex AI」の「チューニング」画面から、「チューニング済モデルを作成」を押下します
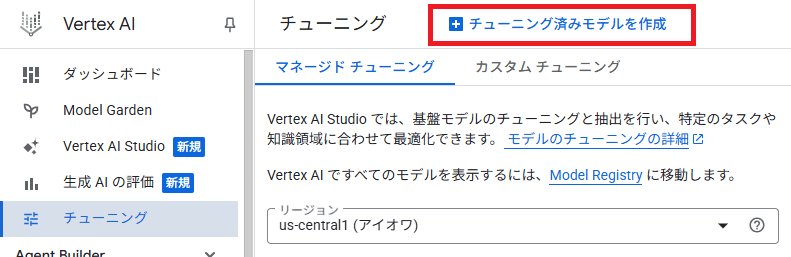
作成画面に移ります。
- モデル名は適当に入力します。(キャプチャは入力前ですが)
- ベースモデルを選択します。今回はgemini-2.5-flash-lightを選択します。
- リージョンを選択します。日本のリージョンは選択できませんでした。(2025/10現在)
EUかアメリカのどこかを選択します。
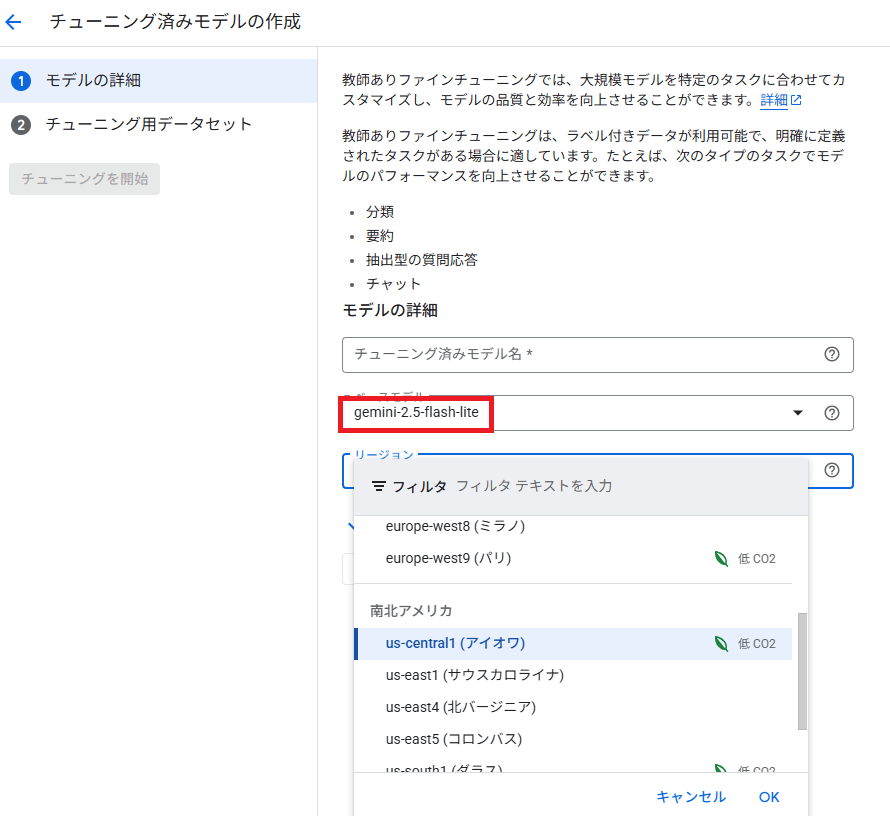
エポック数、学習率の乗数など細かい設定も可能です。今回はデフォルトのまま進めます。

データセットを選択します。Geminiに作成してもらったデータから一部(20サンプル)を検証用データセットとして設定します。
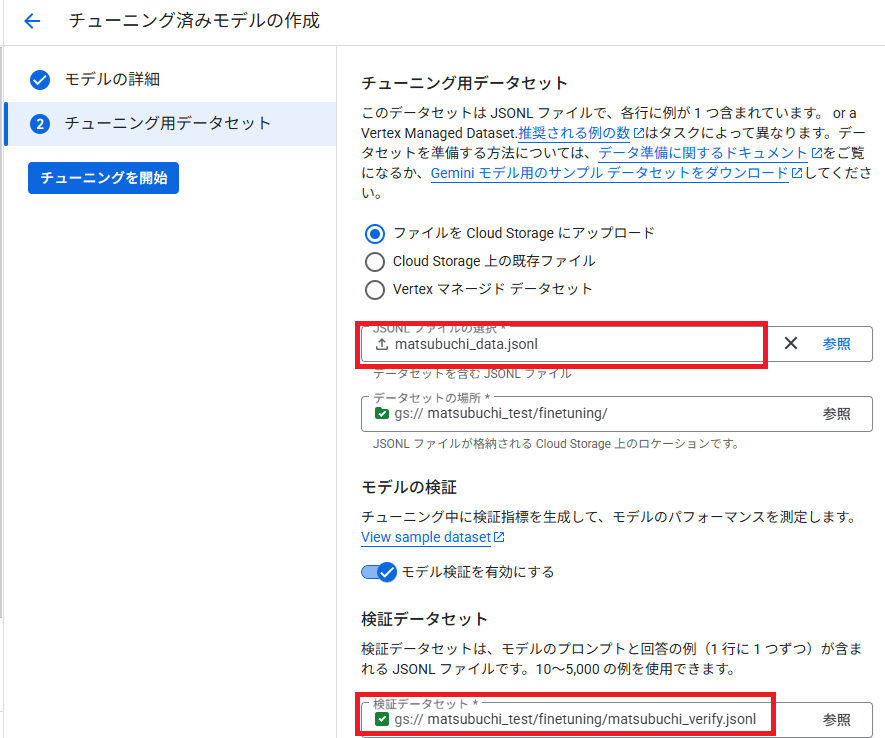
マネージドのメリットを最大限生かすためにも、検証データセットを用意しましょう。
検証用データと学習データは重複しないように準備します。
学習待ち
「Vertex AI」の「チューニング」画面に作成中のモデルの表示が出てきますので、完了まで待ちます。
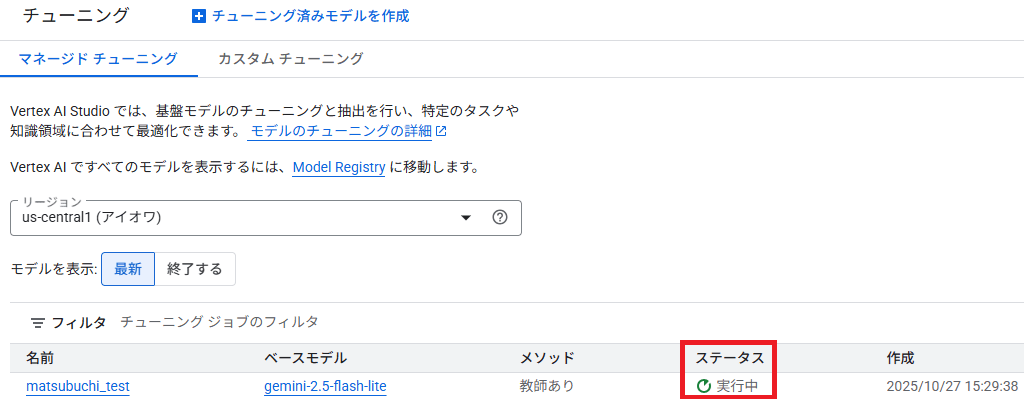
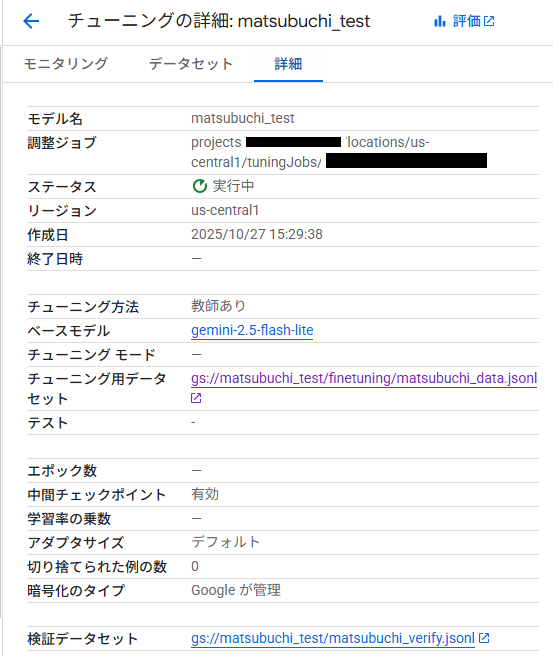
結果確認とテスト
結果確認
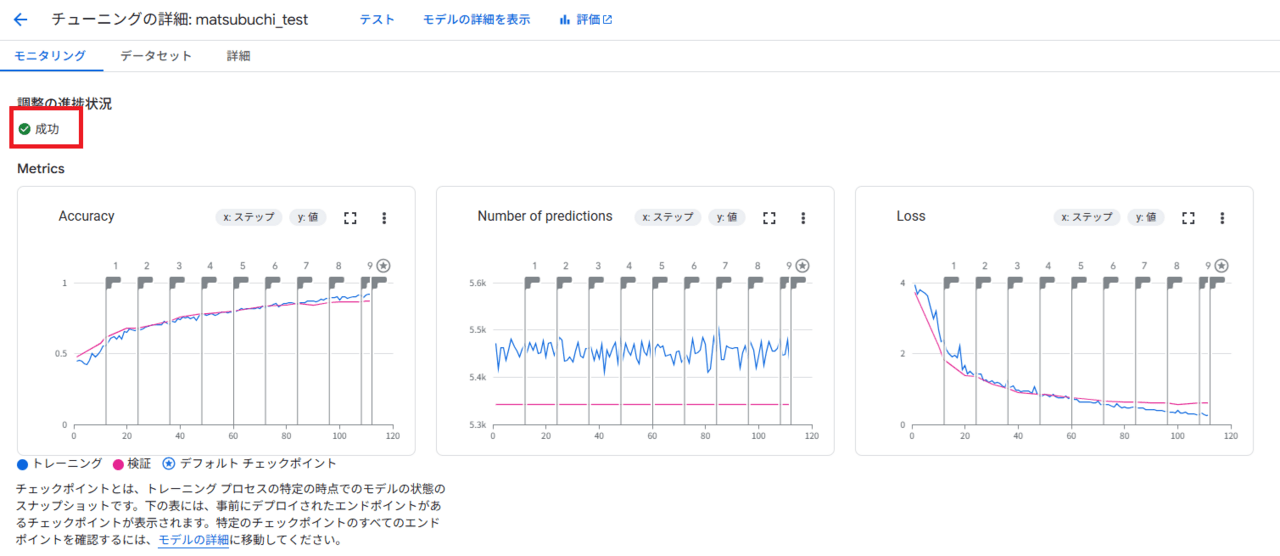
テスト完了したら、結果を確認します。「成功」と表示されているので、大丈夫そうです。
そのほか、各種評価指標もよさげです。正確性が1に近く、Lossも0に近い。
ピンク(検証用データの値)と青(学習用データの値)も大きく差はなさそうに見えます。
テスト
「テスト」ボタンが上部にありましたので、押下します。
モデル選択画面が出てきますので、先ほど作成したモデルを選びます。
Google検索へのグラウンディング、RAGへのグラウンディングも可能です。
今回は使わないのでOFFのまま。
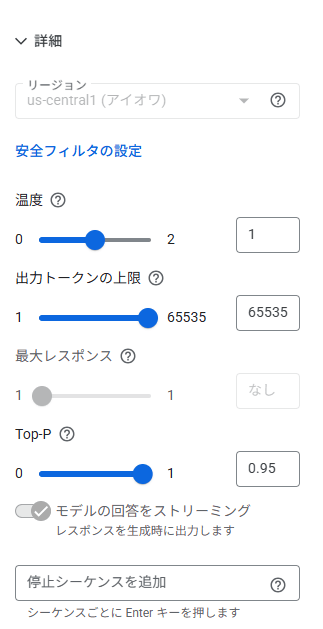
温度(temperature)やTop-Pなどのチューニングも可能。
今回はデフォルトのままで進めます。
適当にプロンプト投げて応答の確認見てみます。左がモデルの応答で、右が私のプロンプトです。
いい感じに煩わしいですね!!大成功です!!

コストの確認
後日、コスト確認しました。合計 \161- でした。(Gemini 2.5 flash lite tuning の料金)
安っ・・・!!
まとめ
本ブログでは、Google CloudのVertex AIを活用し、大規模言語モデル(LLM)のファインチューニングを実践しました。基本的な知識から実践的な手順、そして成功の鍵となるRAGとの使い分けまでを解説しました。
本ブログを書く中で、RAGとファインチューニングの使い分けを整理、理解できたのは大きかったです。
また、ファインチューニングはハードル高い技術だと思ってましたが、ここまで簡単に実装できるとは驚きが隠せません。
AutoMLの時も、コーディングAIエージェントの時も驚きでしたが、AI周りの技術は本当に日々進歩してますね。。
データ準備さえできたら、「〇〇さんそっくりAI」はいつか作ろうと思います!!