

 本記事は 新人ブログマラソン2024 の記事です。 本記事は 新人ブログマラソン2024 の記事です。 |
皆さんこんにちは!入社して間もない新米エンジニアの佐々木です。
最近、実務でAWSやSnowflakeを用いたデータ活用基盤の構築に携わっており、日々新しい技術に触れる毎日です。中でも特に興味を持ったのが、SnowflakeのCortexAIという機能です。
どうやらCortexAIという機能を利用すると「データ分析の自動化」や「機械学習モデルの簡単な構築」を実現できるそうです。
一方で、やはり正直最初は半信半疑でした。一体どれほど簡単に使えるのか、実際に試してみなければ!
しかし、いざ試そうとしたところ「何から手をつければいいのか?」と戸惑うことばかり、、、
そこで、Snowflakeが提供する公式チュートリアルに助けを求めることにしました。
本記事では、私がCortexAIの公式チュートリアルを実践する中で気づいたこと、そしてそこから得られた学びについてお話していきます。これからSnowflakeやCortexAIを触れようと考えている方の参考になれば幸いです!
Snowflakeとは
Snowflakeは、Snowflake社が提供するクラウドデータプラットフォームです。
データウェアハウス、セキュリティ、ガバナンス、可用性、データレジリエンスなど、データ分析に必要な機能をすべて網羅したフルマネージドサービスなんです。
そんなSnowflakeが最近着目しているキーワードとして「AIデータクラウド」があります。
AIデータクラウドとは、データウェアハウスとAI/ML機能を統合したクラウドベースのプラットフォームのことを指します。
Snowflake社はこのAIデータクラウドを通して、データサイエンスと機械学習を民主化し、あらゆる規模の組織がデータドリブンな意思決定を容易に行えるようにすることを目指しています。
Snowflakeクラウドデータプラットフォーム | Snowflake AIデータクラウド
CortexAIとは
Cortex AIは、Snowflakeが提供する機械学習プラットフォームです。
Snowflakeのデータウェアハウス上で直接機械学習モデルの構築、トレーニング、デプロイをできるという特徴があります。また、難しいプログラミングや専門知識がなくても、ある程度の分析や予測が比較的簡単にできるという特徴もあります。
Snowflake Cortex for Generative AI
公式チュートリアルの概要
本記事で取り扱う公式チュートリアルは以下の通りです!
Build A Document Search Assistant using Vector Embeddings in Cortex AI
このチュートリアルでは、Snowflake Cortex AIのベクトル埋め込み機能を利用して、ドキュメント検索アシスタントを構築します。因みに文書検索アシスタントとは、大量のドキュメントデータの中からユーザーが求める情報を見つけ出すのを支援するツールのことを指します。
チュートリアル全体の手順は以下の大きく3つの流れです。
- データ準備と前処理: 検索対象となるドキュメントデータの準備、データベース、スキーマ、ウェアハウスの作成、ドキュメント分割関数の作成を行います。
- ベクターストアの構築: CortexAIを用いて各ドキュメントを数値ベクトルとして表現し、ベクターストアの作成を行います。
- チャットUIおよびロジック構築: 前工程で作成したベクターストアを利用して、誰でも簡単に文書検索ができるように、SnowflakeのStreamlitを使用して簡単なフロントエンドの作成を行います。
実際に挑戦してみた!!
データ準備と前処理
データ準備
まず初めに、今回検索対象となるドキュメントデータを準備します。
今回はチュートリアルで配布されている以下の4つの英文ファイルを使用しました。これらのドキュメントは様々な自転車に関する情報が記述されているPDFファイルです。
- Mondracer Infant Bike
- Premium Bycycle User Guide
- Ski Boots TDBootz Special
- The Ultimate Downhill Bike
データベース、スキーマ、ウェアハウスの作成
次に今回使用するデータベース、スキーマ、ウェアハウスを作成していきます。
そのために、Snowflakeのワークシートを新規で作成し、以下のコードを実行します。
CREATE DATABASE CC_QUICKSTART_CORTEX_DOCS; --create databse CREATE SCHEMA DATA; --create schema USE CC_QUICKSTART_CORTEX_DOCS.DATA; CREATE OR REPLACE WAREHOUSE XS_WH WAREHOUSE_SIZE = XSMALL; --create warehouse USE WAREHOUSE XS_WH;
これにより、データベース、スキーマ、ウェアハウスの大枠の準備ができました!
ドキュメント分割関数の作成
次にドキュメントデータを読み取り、それらをチャンクに分割するためのユーザー定義関数(pdf_text_chunker)を作成します。
ここでユーザー定義関数とは、SQLクエリ内で呼び出せる、ユーザーが作成した再利用可能なコードブロックのことを指します。
またチャンク分割とは、Snowflakeがデータを効率的に管理・処理するために、自動的にデータを小さなブロックに分割する仕組みのことを指します。これによって、大量のドキュメントデータでも高速にアクセス・検索することが可能になるというメリットがあります!
関数を作成するために、Snowflakeのワークシートで以下のコードを実行します。
create or replace function pdf_text_chunker(file_url string)
returns table (chunk varchar)
language python
runtime_version = '3.9'
handler = 'pdf_text_chunker'
packages = ('snowflake-snowpark-python','PyPDF2', 'langchain')
as
$$
from snowflake.snowpark.types import StringType, StructField, StructType
from langchain.text_splitter import RecursiveCharacterTextSplitter
from snowflake.snowpark.files import SnowflakeFile
import PyPDF2, io
import logging
import pandas as pd
class pdf_text_chunker:
def read_pdf(self, file_url: str) -> str:
logger = logging.getLogger("udf_logger")
logger.info(f"Opening file {file_url}")
with SnowflakeFile.open(file_url, 'rb') as f:
buffer = io.BytesIO(f.readall())
reader = PyPDF2.PdfReader(buffer)
text = ""
for page in reader.pages:
try:
text += page.extract_text().replace('\n', ' ').replace('\0', ' ')
except:
text = "Unable to Extract"
logger.warn(f"Unable to extract from file {file_url}, page {page}")
return text
def process(self,file_url: str):
text = self.read_pdf(file_url)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 4000, #Adjust this as you see fit
chunk_overlap = 400, #This let's text have some form of overlap. Useful for keeping chunks contextual
length_function = len
)
chunks = text_splitter.split_text(text)
df = pd.DataFrame(chunks, columns=['chunks'])
yield from df.itertuples(index=False, name=None)
$$;上記のコードについて補足説明をします。
6行目:
packages = ('snowflake-snowpark-python','PyPDF2', 'langchain')必要なPythonパッケージを指定しています。snowflake-snowpark-pythonはPythonコードの埋め込み、PyPDF2でPDFファイルの読み込み、langchainでテキストの分割処理に利用します。
18行目~35行目:
def read_pdf(self, file_url: str) -> str:PDFファイルの読み込みをするための関数です。ページごとにテキストを抽出し、改行文字やNULL文字をスペースに置換して連結した文字列を返します。
37行目~50行目:
def process(self,file_url: str):テキストを指定されたサイズに分割するための関数です。今回のコードではチャンクサイズを4000文字、チャンク間のオーバーラップを400文字に設定しています。
これにより、ドキュメントを分割するための関数ができました!
ドキュメントアップロード用ステージの作成
次にドキュメントをアップロードするステージを作成します。
そのために、ワークシートで以下のコードを実行します。
create or replace stage docs ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE') DIRECTORY = ( ENABLE = true );その後、作成したDOCSステージに準備した4つのドキュメントデータを以下のようにアップロードします。
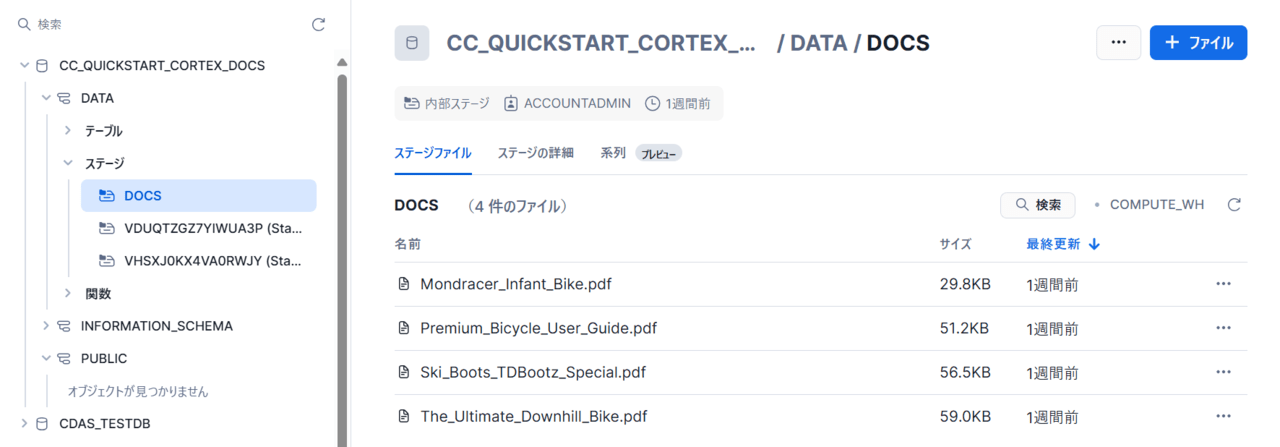
以上でデータ準備および前処理は完了です!!
ベクターストアの構築
次にベクターストアを構築していきます。
ベクターストアとは、文書のベクトル表現(数値ベクトル)を保存するデータベースのことを指します。
これにより、従来のテキスト検索では難しい「意味的な検索」についても、文書間の意味の類似度を計算することで実現することができるようです!
テーブルの作成
まず初めに、各ドキュメントのチャンクとベクトルを保存するためのテーブル(DOCS_CHUNKS_TABLE)を作成するために、以下のコードを実行します。
create or replace TABLE DOCS_CHUNKS_TABLE (
RELATIVE_PATH VARCHAR(16777216), -- Relative path to the PDF file
SIZE NUMBER(38,0), -- Size of the PDF
FILE_URL VARCHAR(16777216), -- URL for the PDF
SCOPED_FILE_URL VARCHAR(16777216), -- Scoped url (you can choose which one to keep depending on your use case)
CHUNK VARCHAR(16777216), -- Piece of text
CHUNK_VEC VECTOR(FLOAT, 768) ); -- Embedding using the VECTOR data type上記で作成したテーブルのCHUNKカラムにドキュメントのチャンクが、CHUNK_VECカラムにチャンクから計算されたベクトル値が格納されます。
テーブルへのデータ挿入
次に、作成したドキュメント分割関数(pdf_text_chunker)を利用して、ドキュメントを処理し、チャンクを抽出します。そして抽出したチャンクからベクトル値を計算し、テーブル(DOCS_CHUNKS_TABLE)にそれらの情報を挿入します。
insert into docs_chunks_table (relative_path, size, file_url,
scoped_file_url, chunk, chunk_vec)
select relative_path,
size,
file_url,
build_scoped_file_url(@docs, relative_path) as scoped_file_url,
func.chunk as chunk,
SNOWFLAKE.CORTEX.EMBED_TEXT_768('e5-base-v2',chunk) as chunk_vec
from
directory(@docs),
TABLE(pdf_text_chunker(build_scoped_file_url(@docs, relative_path))) as func;上記のコードについて補足説明をします。
8行目:
SNOWFLAKE.CORTEX.EMBED_TEXT_768('e5-base-v2',chunk) as chunk_vecSnowflakeのCortex機能を使用して、チャンクのベクトル値を生成します。様々あるモデルの内、今回はe5-base-v2というモデルを使用してベクトル値を生成しています。
11行目:
TABLE(pdf_text_chunker(build_scoped_file_url(@docs, relative_path))) as func;build_scoped_file_url(@docs, relative_path)では、各ドキュメントの相対パス(relative_path)とステージパス(@docs)を組み合わせてSnowflake内で一意に参照できるURLを生成しています。
その後、生成したURLをもとに作成した関数(pdf_text_chunker)でドキュメントをチャンクに分割し、戻り値をfuncというエイリアスで参照できるようにしている形です。
これで、チャンクとベクトル値を含むベクターストアを作成することができました!
チャットUIおよびロジックの構築
最後に、作成したベクターストアを利用して、誰でも簡単に文書検索ができるように、SnowflakeのStreamlitを使用して単純なフロントエンドを作成していきます。
具体的には、SnowflakeのCortexとStreamlitを使って、ユーザーがアップロードしたドキュメントをコンテキストとして利用(RAG)し、大規模言語モデル(LLM)で質問に答えるアプリケーションを作成します。
Streamlitとは、カスタムWebアプリを簡単に素早く構築することができるオープンソースのPythonライブラリです。
さらにStreamlitを使用することで、アプリ実行を同じアカウント内の他のユーザーと共有することができ、データの安全性と保護が維持されるというメリットがあります。
Streamlit構築
早速、Streamlitで以下のようにコードを変更します。
import streamlit as st # Import python packages
from snowflake.snowpark.context import get_active_session
session = get_active_session() # Get the current credentials
import pandas as pd
pd.set_option("max_colwidth",None)
num_chunks = 3 # Num-chunks provided as context. Play with this to check how it affects your accuracy
def create_prompt (myquestion, rag):
if rag == 1:
cmd = """
with results as
(SELECT RELATIVE_PATH,
VECTOR_COSINE_SIMILARITY(docs_chunks_table.chunk_vec,
SNOWFLAKE.CORTEX.EMBED_TEXT_768('e5-base-v2', ?)) as similarity,
chunk
from docs_chunks_table
order by similarity desc
limit ?)
select chunk, relative_path from results
"""
df_context = session.sql(cmd, params=[myquestion, num_chunks]).to_pandas()
context_lenght = len(df_context) -1
prompt_context = ""
for i in range (0, context_lenght):
prompt_context += df_context._get_value(i, 'CHUNK')
prompt_context = prompt_context.replace("'", "")
relative_path = df_context._get_value(0,'RELATIVE_PATH')
prompt = f"""
'You are an expert assistance extracting information from context provided.
Answer the question based on the context. Be concise and do not hallucinate.
If you don´t have the information just say so.
Context: {prompt_context}
Question:
{myquestion}
Answer: '
"""
cmd2 = f"select GET_PRESIGNED_URL(@docs, '{relative_path}', 360) as URL_LINK from directory(@docs)"
df_url_link = session.sql(cmd2).to_pandas()
url_link = df_url_link._get_value(0,'URL_LINK')
else:
prompt = f"""
'Question:
{myquestion}
Answer: '
"""
url_link = "None"
relative_path = "None"
return prompt, url_link, relative_path
def complete(myquestion, model_name, rag = 1):
prompt, url_link, relative_path =create_prompt (myquestion, rag)
cmd = f"""
select SNOWFLAKE.CORTEX.COMPLETE(?,?) as response
"""
df_response = session.sql(cmd, params=[model_name, prompt]).collect()
return df_response, url_link, relative_path
def display_response (question, model, rag=0):
response, url_link, relative_path = complete(question, model, rag)
res_text = response[0].RESPONSE
st.markdown(res_text)
if rag == 1:
display_url = f"Link to [{relative_path}]({url_link}) that may be useful"
st.markdown(display_url)
#Main code
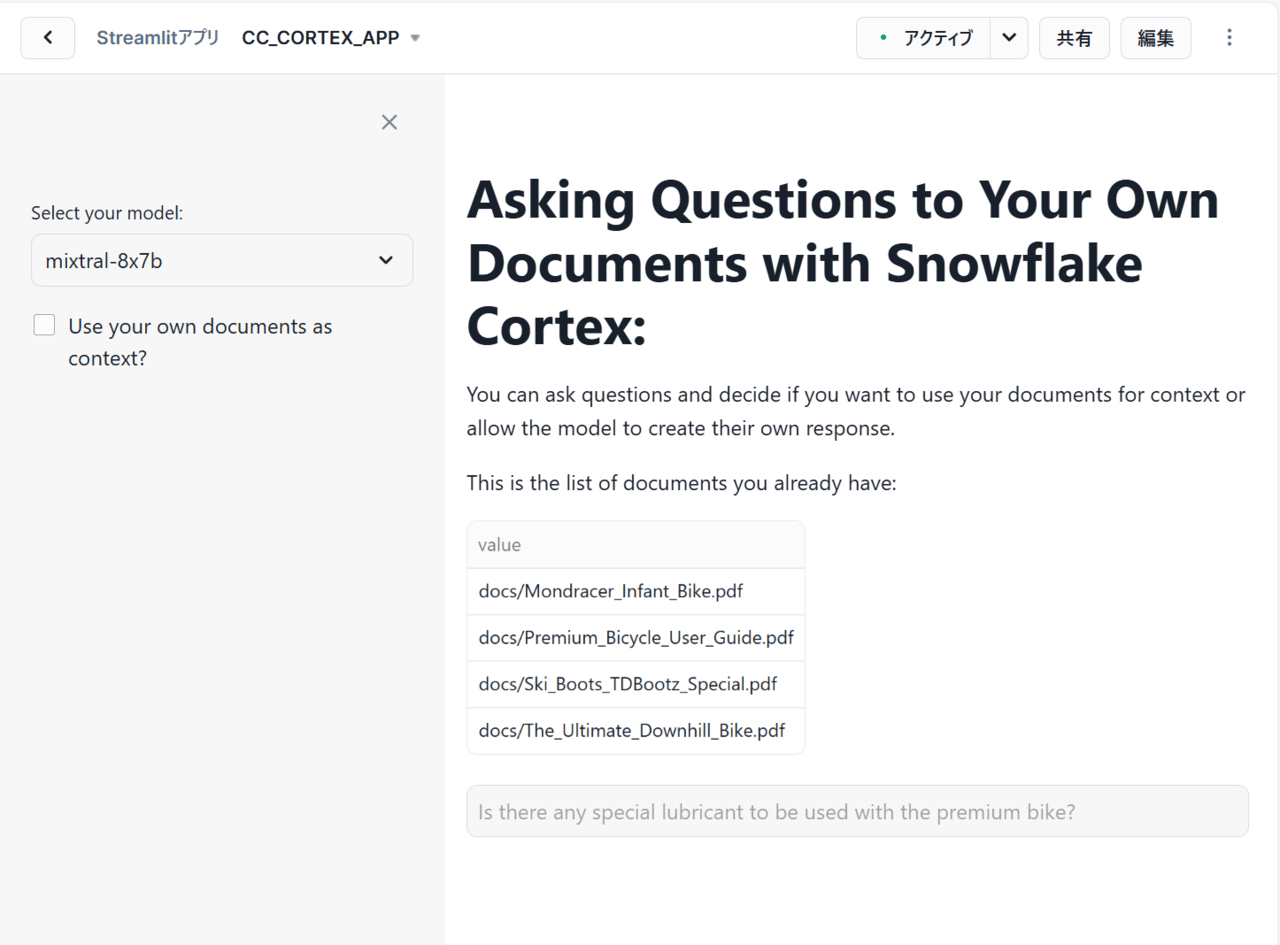
st.title("Asking Questions to Your Own Documents with Snowflake Cortex:")
st.write("""You can ask questions and decide if you want to use your documents for context or allow the model to create their own response.""")
st.write("This is the list of documents you already have:")
docs_available = session.sql("ls @docs").collect()
list_docs = []
for doc in docs_available:
list_docs.append(doc["name"])
st.dataframe(list_docs)
#Here you can choose what LLM to use. Please note that they will have different cost & performance
model = st.sidebar.selectbox('Select your model:',(
'mixtral-8x7b',
'snowflake-arctic',
'mistral-large',
'llama3-8b',
'llama3-70b',
'reka-flash',
'mistral-7b',
'llama2-70b-chat',
'gemma-7b'))
question = st.text_input("Enter question", placeholder="Is there any special lubricant to be used with the premium bike?", label_visibility="collapsed")
rag = st.sidebar.checkbox('Use your own documents as context?')
print (rag)
if rag:
use_rag = 1
else:
use_rag = 0
if question:
display_response (question, model, use_rag)上記のコードについて補足説明をします。
10行目~59行目:
def create_prompt (myquestion, rag):LLMへのプロンプトを作成する関数を定義しています。
特にここではRAGの有無を検証するために、変数ragの値を切り替えることでRAGを利用するかしないかを簡単に選択できるようにしています。rag=1の場合は、ユーザーが自身のドキュメントをコンテキストとして使用し、質問に対して類似度の高いチャンクを検索し、それらを追加した形でプロンプトを作成しています。一方でrag=0の場合は、ドキュメントをコンテキストとして使用せず、質問に回答するシンプルなプロンプトを作成しています。
61行目~69行目:
def complete(myquestion, model_name, rag = 1):LLMを使用して質問に回答する関数を定義しています。
SnowflakeのSNOWFLAKE.CORTEX.COMPLETE関数を使用して、指定されたLLMモデルとプロンプトを使用して、テキストの生成を行います。
71行目~77行目:
def display_response (question, model, rag=0):LLMからの応答とドキュメントへのリンク(rag == 1 の場合)をStreamlitで表示する関数を定義しています。
81行目~114行目:
メインのコードです。ここでは以下の処理を行っています。
- Streamlitアプリケーションのタイトルと説明を表示
- ユーザーがアップロードしたドキュメントの一覧を表示
- LLMモデルを選択できるセレクトボックスをサイドバーに表示
- 質問を入力できるテキストボックスを表示
- ドキュメントをコンテキストとして使用するかを選択できるチェックボックスをサイドバーに表示
- 質問が入力された場合、
display_response関数を呼び出して回答を表示
上記のコードを実行することで無事アプリが表示されました!
検証
ここでRAGを利用した場合と、利用しない場合とで回答にどのような違いがあるのかを確認してみます。
そこで「What is the temperature to store the ski boots?(スキーブーツを保管する温度はどれくらいですか?)」という質問をしてみたいと思います。
まずはRAGを利用した場合の回答です。
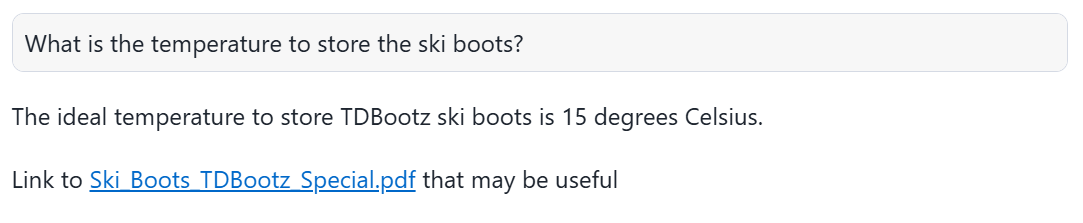
上記の回答を日本語訳すると、
TDBootzスキーブーツを保管する理想的な温度は摂氏15度です。
参考になる可能性のある資料へのリンク:Ski_Boots_TDBootz_Special.pdf
上記から分かるように、RAGを利用すると精度および具体性の高い回答をしていることが分かります。これは、LLMのテキスト生成に信頼性の高い外部情報(今回はドキュメントデータ)を組み合わせているからだと言えます。
次にRAGを利用しなかった場合の回答です。
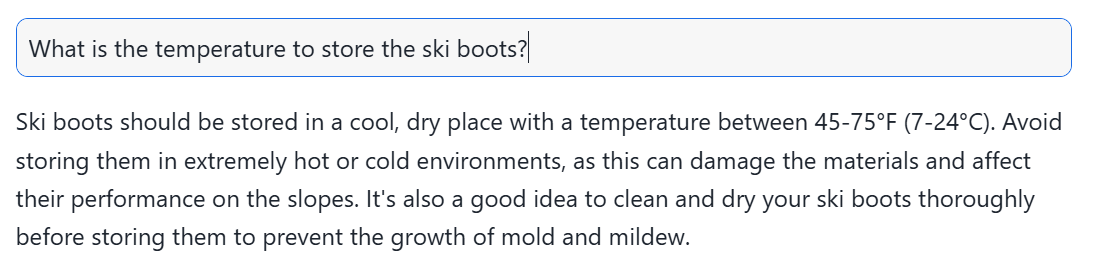
上記の回答を日本語訳すると、
スキーブーツは、摂氏7~24度(華氏45~75度)の涼しく乾燥した場所に保管する必要があります。極端に高温または低温の環境での保管は避けてください。これにより、素材が損傷し、ゲレンデでの性能に影響を与える可能性があります。また、カビや mildew(かびの一種)の発生を防ぐために、保管前にスキーブーツを完全に清掃して乾燥させることも良いでしょう。
上記から分かるように、RAGを利用しないと具体性に欠ける一般的な回答しかできていないことが分かります。これは、LLMが内部知識のみを利用し、事前に学習済みのデータに基づいて回答を生成するからだと言えます。
まとめ
本記事では、Snowflakeの公式チュートリアルを実践することで、CortexAIの使い方や利便性について確認することができました。
特にチュートリアルを通して感じたCortexAIの魅力的ポイントを3つ挙げてみました!
-
シームレスなSnowflake連携: Snowflakeデータウェアハウスに直接統合されており、データの移動や変換が不要となる。これにより、Snowflake内のデータに対して直接機械学習モデルを構築・実行でき、データサイエンスワークフローがシームレスになり、開発効率が劇的に向上する
-
高度な埋め込みベクトル機能: テキストデータの埋め込みベクトル生成をスムーズに行えるため、セマンティック検索や類似テキスト検索といった高度な機能を容易に実装できる
-
様々なLLMモデルへの対応: 複数のLLMモデルに対応しているため、プロジェクトのニーズやコストに合わせて最適なモデルを選択できる
このような魅力的ポイントを持つCortexAIは、様々なビジネス課題への応用が期待でき、今後ますます注目を集める技術だと思います。
ぜひ、皆さんもCortexAIを試してみて、その可能性を体感してみてください!