

 本記事は 新人ブログマラソン2024 の記事です。 本記事は 新人ブログマラソン2024 の記事です。 |
皆さんこんにちは!入社して間もない新米エンジニアの佐々木です。
前回、前々回と2回に渡って、Snowflake CortexAIを使ってドキュメント検索アシスタントを構築するチュートリアルに挑戦し、その様子を記事にまとめさせていただきました。多くの方々に読んでいただき、大変嬉しく思っています。
まだ読めていないという方は、以下の記事をまずは読んでいただけると幸いです!!
新米エンジニアが挑む!Snowflake CortexAIでドキュメント検索アシスタントを構築してみる – TechHarmony
新米エンジニアが挑む!Snowflake CortexAIでドキュメント検索アシスタントを構築してみる【チャットボットバージョン】 – TechHarmony
さて今回の記事は、ようやくこのチュートリアルの最終話となります。最終話の立ち位置としては、前回までの内容にオプション機能を追加するライトな内容となります!
具体的には、前回まででチャットボットバージョンのドキュメント検索アシスタントの構築が完了したため、今回は新しいドキュメントの自動処理に踏み込んでみたいと思います。
それでは早速行きましょう!!
前回までの振り返り
前回、前々回と以下の公式チュートリアルをハンズオン形式で実践し、Snowflake Cortex AIのベクトル埋め込み機能を利用して、ドキュメント検索アシスタントを構築しました!
特に前回は、前々回の内容にプラスしてより高度なチャットボットバージョンのドキュメント検索アシスタントの構築をしました!
具体的なStreamlitのコード解説が気になる方は前回の記事を参照していただきたいのですが、最終的には以下のようなアプリを構築することができました!
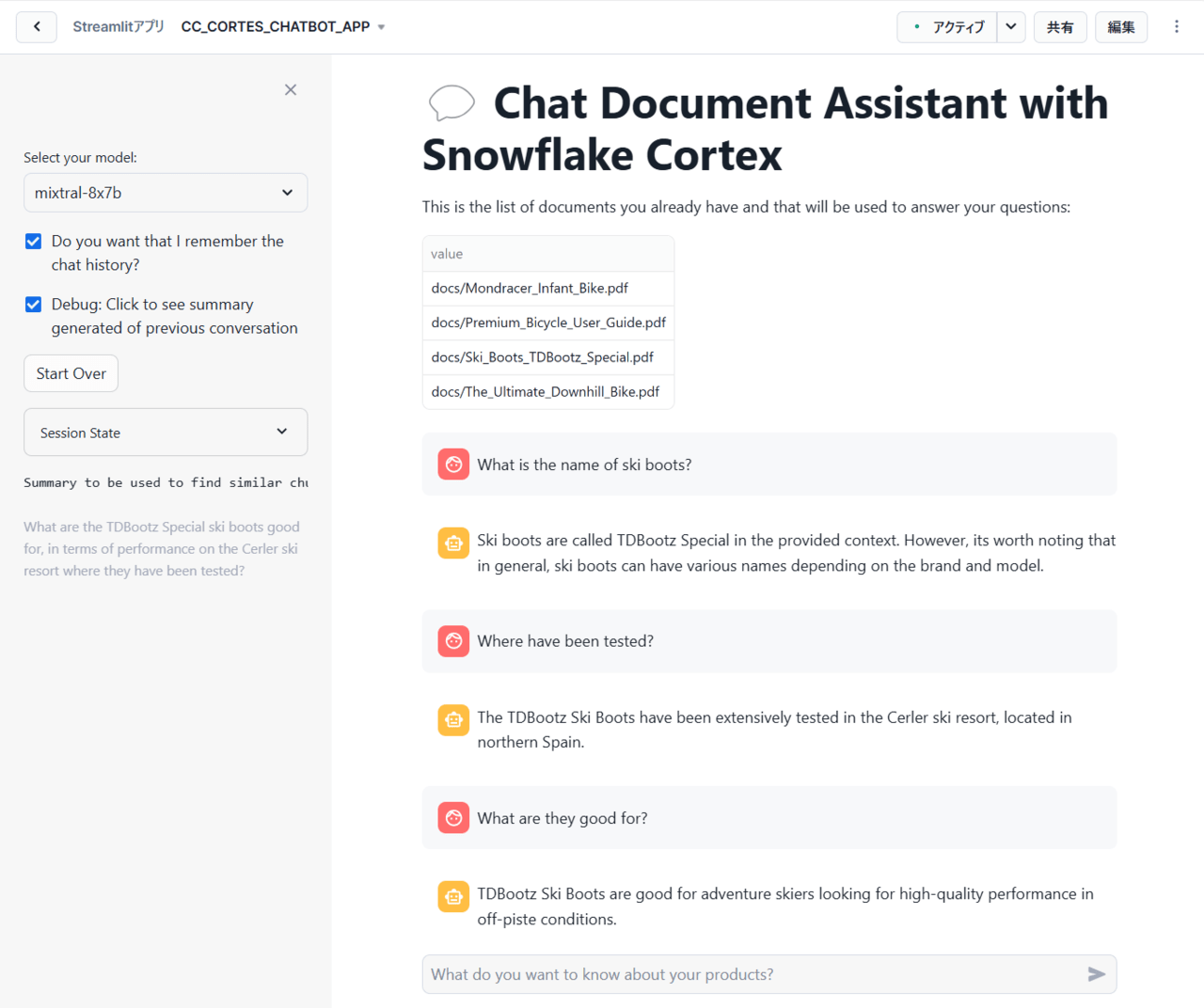
上記を見てわかる通り、ユーザーとの会話内容を記憶して、チャットボットのように会話できるアプリとなっています。
なぜこのようなチャットのような会話が実現できるのかについて簡単に説明します。
まず、ユーザーが質問を投げかけると予めSnowflake上に格納されたドキュメントをもとにLLMが回答を作成(RAG)し応答します。このとき、ユーザーの質問と作成された回答をペアとしてStreamlitのセッション領域に一時的に格納します。
次に、ユーザーが続いて質問をすると、セッションに格納したチャット履歴と質問内容を組み合わせて要約された内容がLLMに渡され、回答作成および応答するという仕組みです。
これにより、前回の会話内容を記憶した会話形式が実現できるわけです。
大雑把な説明とはなってしまいましたが、詳細が気になる方は前回の記事をぜひご覧ください!!
今回実施するチュートリアルの概要
前回実施したチュートリアルでは前述したとおり、ユーザーとの会話内容を記憶して、チャットボットのように会話できるアプリを構築しました。
ここまでの内容でドキュメント検索アシスタントの9割以上は構築完了しているのですが、1つだけ不便な点があります。
それは新しいドキュメントを追加したいときです。
現状だと、Snowflakeのステージ上に新しいドキュメントを追加しただけでは、RAGで検索対象のドキュメントとはなりません。なぜなら、ドキュメントを検索する際にはステージ上のドキュメントそのものを参照するのではなく、ドキュメントのチャンクが格納された独自のテーブル(docs_chunk_table)を参照するためです。このようにしている理由は、検索効率を向上させるためです。
つまり、現状だと新しいドキュメントをRAGの検索対象にしたいのであれば、ドキュメントをもとに分割されたチャンクをdocs_chunk_tableにinsertするコマンドを手動で実行しなくてはならないという不便さがあります。
そこで、より快適な運用に向けて新しいドキュメントを自動処理する仕組みを構築していきたいと思います!
実際に挑戦してみた!!
ワークロード定義
新しいドキュメントの自動処理を実現するために、今回はSnowflakeのストリームとタスクという2つを用います!
早速ですが、Snowflakeワークシートで以下のコードを実行します。
create or replace stream docs_stream on stage docs;
create or replace task task_extract_chunk_vec_from_pdf
warehouse = COMPUTE_WH
schedule = '1 minute'
when system$stream_has_data('docs_stream')
as
insert into docs_chunks_table (relative_path, size, file_url,
scoped_file_url, chunk, chunk_vec)
select relative_path,
size,
file_url,
build_scoped_file_url(@docs, relative_path) as scoped_file_url,
func.chunk as chunk,
SNOWFLAKE.CORTEX.EMBED_TEXT_768('e5-base-v2',chunk) as chunk_vec
from
docs_stream,
TABLE(pdf_text_chunker(build_scoped_file_url(@docs, relative_path))) as func;
alter task task_extract_chunk_vec_from_pdf resume;上記のコードについて補足説明をします。
コード全体としては、新しいPDFファイルがステージに追加されるたびに、自動的にテキストチャンクを抽出し、埋め込みベクトルを生成するというワークロードを定義しています。
では具体的に、各行がどのような処理を行っているのかについて触れていきます。
1行目:
create or replace stream docs_stream on stage docs;docs_streamという名前のストリームを新たに作成しています。
ストリームは、テーブル、ビュー、またはスキーマに加えられたDML変更(挿入、更新、削除)の変更履歴を記録する役割を持ちます。これにより、新しいPDFファイルがdocsステージに追加されると、docs_streamはこれらの変更を記録することができます。
3行目:
create or replace task task_extract_chunk_vec_from_pdf task_extract_chunk_vec_from_pdfという名前のタスクを作成しています。
タスクは、SQLステートメント(クエリ、DML操作、ストアドプロシージャの実行など)を自動的に実行するようにスケジュールできるデータベースオブジェクトです。
4行目~6行目:
warehouse = XS_WH
schedule = '1 minute'
when system$stream_has_data('docs_stream')上記タスクを実行するウェアハウス、頻度、条件を定義しています。
具体的には以下の定義です。
- ウェアハウス:COMPUTE_WH
- 頻度: 毎分
- 条件:docs_streamストリームに新しいレコードがある場合に実行
9行目~19行目:
insert into docs_chunks_table (relative_path, size, file_url,
scoped_file_url, chunk, chunk_vec)
・・・タスクで実行するSQLステートメントを定義しています。
具体的には、docs_chunks_tableテーブルにデータを挿入するクエリを定義しています。テーブルには、ファイルパス、サイズ、URL、チャンクテキスト、そして埋め込みベクトルなどの情報が格納されます。
21行目:
alter task task_extract_chunk_vec_from_pdf resume;タスクを再開するための処理です。
タスクは手動停止やエラー発生時など様々な理由で一時停止状態になることがあります。そのため、一時停止状態のタスクを再開し、スケジュールされた通り、またはトリガー条件が満たされたときに実行されるようにできます。
検証
では実際に新しいドキュメントをステージ上にアップロードすることで、自動的にタスクが実行されるかについて確認してみましょう!
具体的には、ドキュメントをアップロードする前と後の状態でドキュメントに関連する質問を投げかけ、的確な回答が返ってくるか否かを確認してみます。想定としては、ドキュメントをアップロードする前の状態だと的確な回答が返ってこないのに対して、アップロードした後の状態だと的確な回答が返ってくるはずです。
では実際にアップロードするドキュメントについてですが、今回は公式チュートリアルから拝借した「The_Xtreme_Road_Bike_105_SL.pdf」というエクストリームロードバイクに関するPDFファイルを使用したいと思います。
そして、このドキュメントに関連する「Is there any discount for the Xtreme Road Bike?(エクストリームロードバイクの割引はありますか?)」という質問をチャットで投げかけてみたいと思います。
ドキュメントアップロード前
まずは、ドキュメントをアップロードする前の状態でチャットに質問を投げかけてみます。
投げかけた結果、以下のような回答が返されました。
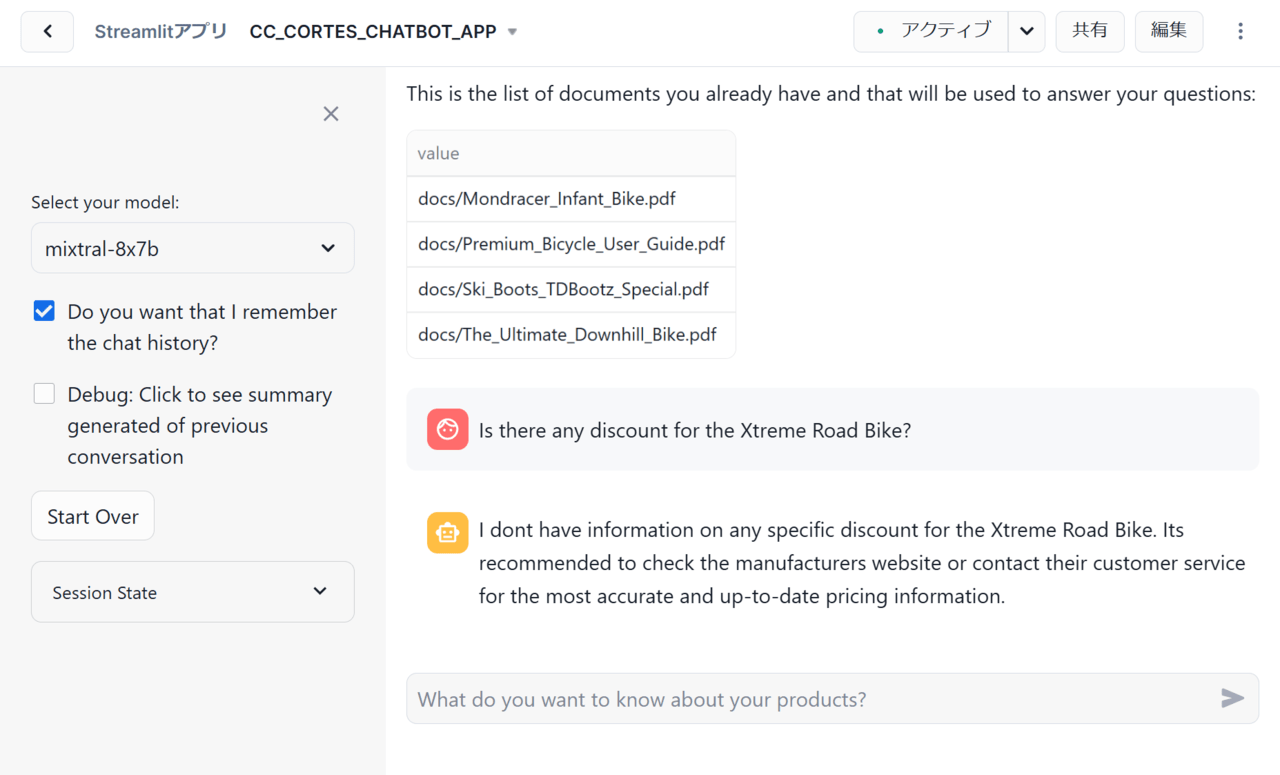
上記のチャット内容を日本語に訳すと以下の通りです。ここで、黒文字が質問、赤文字が回答となります。
エクストリームロードバイクの割引はありますか?
エクストリーム・ロードバイクの割引情報はありません。最も正確で最新の価格情報については、メーカーのウェブサイトを確認するか、カスタマーサービスに問い合わせることをお勧めします。
ドキュメントアップロード後
次に、ドキュメントをアップロードした前の状態でチャットに質問を投げかけてみます。
投げかけた結果、以下のような回答が返されました。
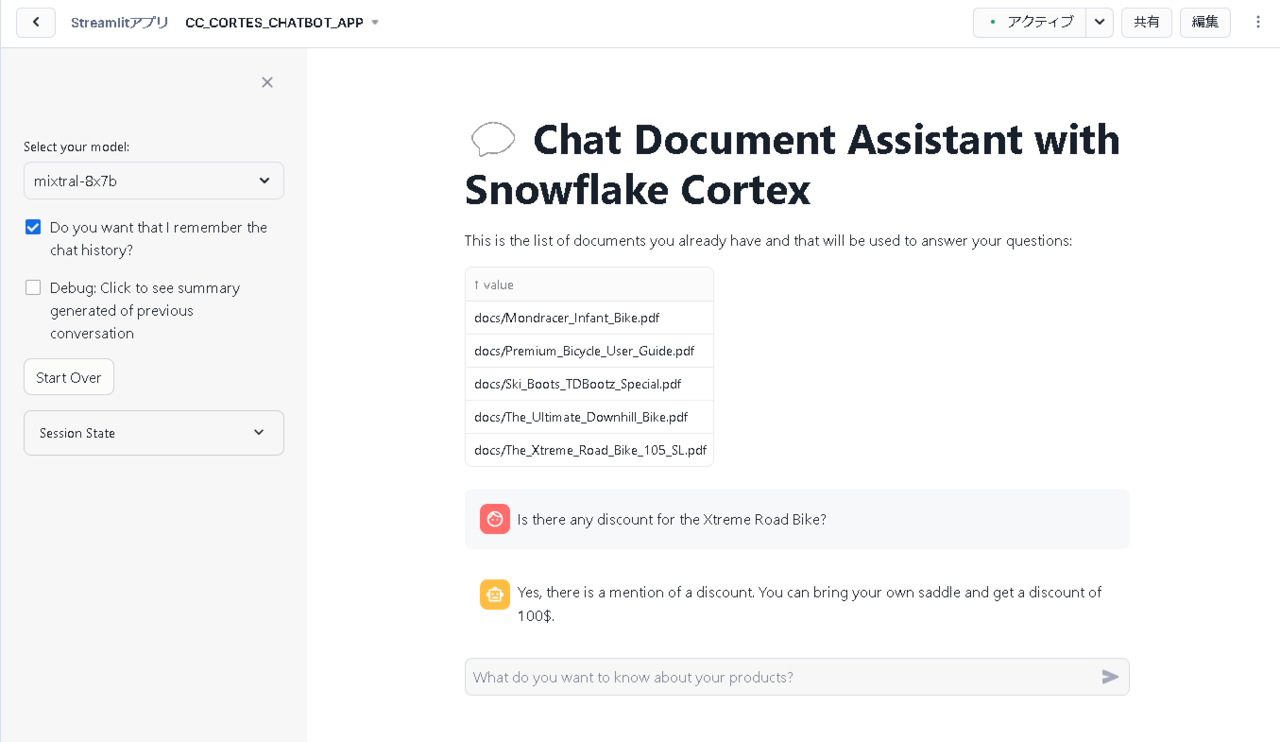
上記のチャット内容を日本語に訳すと以下の通りです。ここで、黒文字が質問、赤文字が回答となります。
エクストリームロードバイクの割引はありますか?
はい、割引の話があります。自分のサドルを持参すると100ドル割引になります。
まとめ
本記事では、前回の記事までで作成したチャットボットUIに対して、新たなドキュメントを自動処理するためのワークフローについて解説しました。
従来、ドキュメントの検索や分析には、手動でのアップロードやインデックス作成が必要で、時間と労力を要していました。しかし、Snowflakeが提供するストリームやタスクの機能を使うことで、これらのプロセスを自動化できることが分かりました!
これにより、迅速な情報検索が可能になり、業務効率の大幅な向上が期待できるというメリットがあります。 さらに、様々なファイル形式に対応しているため、様々な種類のドキュメントを統一的に管理・検索できる点も大きなメリットだと考えられます。そのため、大量のドキュメントを扱う企業にとって、この機能は業務効率化の強力なツールとなるでしょう。
ぜひ、前回、前々回で紹介したCortexAIを用いたドキュメント検索アシスタント、本記事で紹介したドキュメントの自動処理機能を参考にして、RAGシステムの構築や情報検索の効率化に活かしてみてください!