
こんにちは、広野です。
大量のデータに対して、生成 AI で同じプロンプトを使用する問い合わせをしたかったので、CSV データを読み込んで結果を CSV に追記して返してくれるジョブを AWS 上に作成しました。
簡単なつくりですが、プロンプトを変えることでいろいろな処理に活用できると思います。
つくったもの
以下のフォーマットの CSV ファイルをインプットにします。サンプルデータのソースは AWS ドキュメントです。

結果の CSV ファイルです。本記事ではサンプルとして元データテキスト(英語)を翻訳してサマリーするだけとします。

CSV ファイルを AWS マネジメントコンソールで所定の Amazon S3 バケットに保存すると、自動的にジョブが実行され、結果 CSV ファイルがバケットに保存されるとともに、メールで完了通知が届く仕組みです。
アーキテクチャ
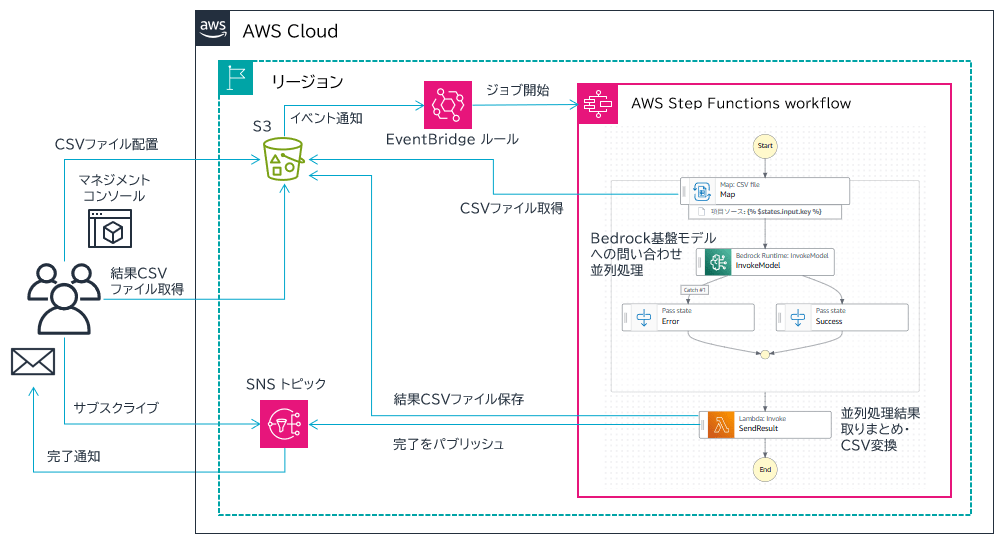
- Amazon S3 バケット内、input フォルダに CSV ファイルが保存されると、イベント通知が Amazon EventBridge に送信されます。
- Amazon EventBridge ルールがそれを検知し、AWS Step Functions ステートマシンを開始します。その際、CSV ファイルが配置された Amazon S3 バケットとキーを渡します。
- ステートマシンは該当の Amazon S3 バケットとキーを元に、CSV ファイルを取得します。CSV ファイルの中身を参照して、行単位で Map ステートによる並列処理を行います。
- 並列実行される各処理内では、データ 1 件ごとに Amazon Bedrock 基盤モデルに問い合わせます。すべての並列処理が完了後、各処理の結果がとりまとめられ、AWS Lambda 関数に渡します。
- AWS Lambda 関数内では、結果データ (JSON) を CSV に変換し、Amazon S3 バケットに保存します。最後、Amazon SNS に完了通知をパブリッシュします。
※本記事の構成では、生成 AI のモデルに Claude 3.7 Sonnet を使用したかったので、オレゴンリージョンにデプロイしました。執筆時点では東京リージョンで 3.7 がリリースされておらず。
設定解説
Amazon EventBridge
Amazon S3 の設定は省略します。Amazon S3 バケットに Amazon EventBridge へのイベント通知が有効になっている状態で、Amazon EventBridge ルールを設定します。イベントパターンは以下のように設定しています。バケット名指定で、キーはワイルドカードで input フォルダにある .csv ファイルであれば発動する条件です。
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["bedrockjob-test"]
},
"object": {
"key": [{
"wildcard": "input/*.csv"
}]
}
}
}
ターゲットは AWS Step Functions ステートマシンです。開始するには ARN さえ設定できればよいのですが、ステートマシンの引数は Amazon S3 バケット名とキーなので、以下のように入力トランスフォーマーで絞り込みました。
- 入力パス
{
"bucket": "$.detail.bucket.name",
"key": "$.detail.object.key"
}
- 入力テンプレート
{
"bucket": <bucket>,
"key": <key>
}
AWS Step Functions
ステートマシンのタスク単位で説明します。設定の記法は JSONata を使用しています。
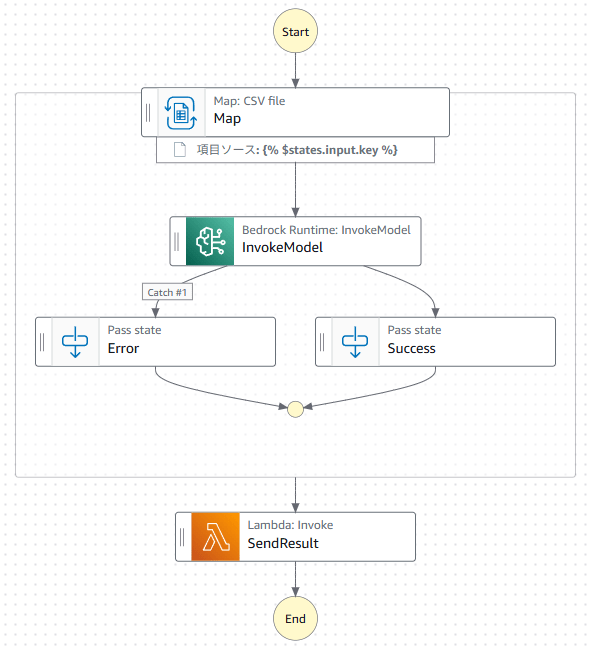
Map ステート
ステートマシンが開始したとき、Map ステートから始まります。この時点のインプットは以下のようにデータが格納された CSV ファイルの S3 バケット名、キーになります。
{
"input": {
"bucket": "bedrockjob-test",
"key": "input/testdata3.csv"
},
"inputDetails": {
"truncated": false
},
"roleArn": "arn:aws:iam::xxxxxxxxxxxx:role/bedrockjob-StateMachineExecutionRole-test"
}
インプットにしたいデータが純粋な JSON データであれば処理モードは「インライン」で良いのですが、今回のように Amazon S3 にあるファイルがインプットの場合は「分散」を選択します。
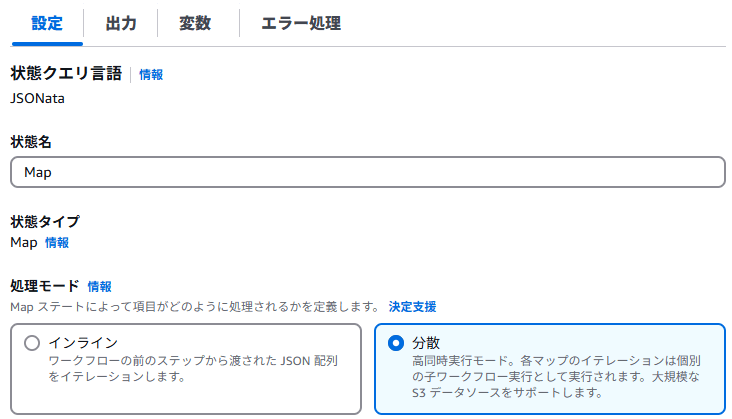
データが CSV 形式の場合、専用の設定があります。
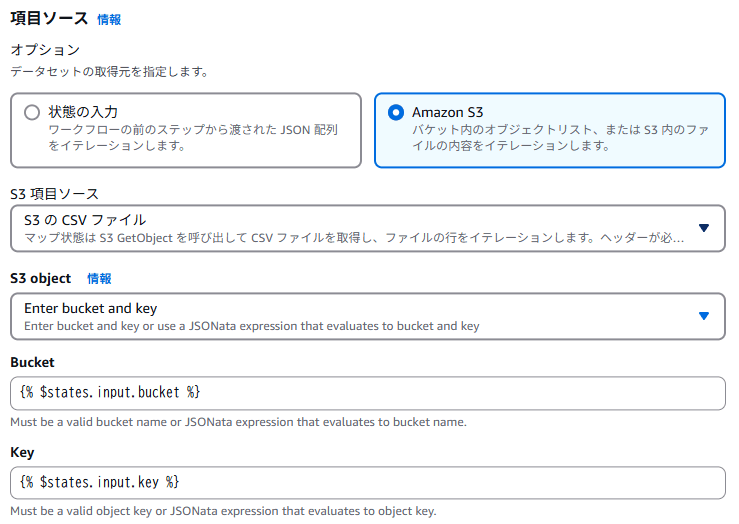
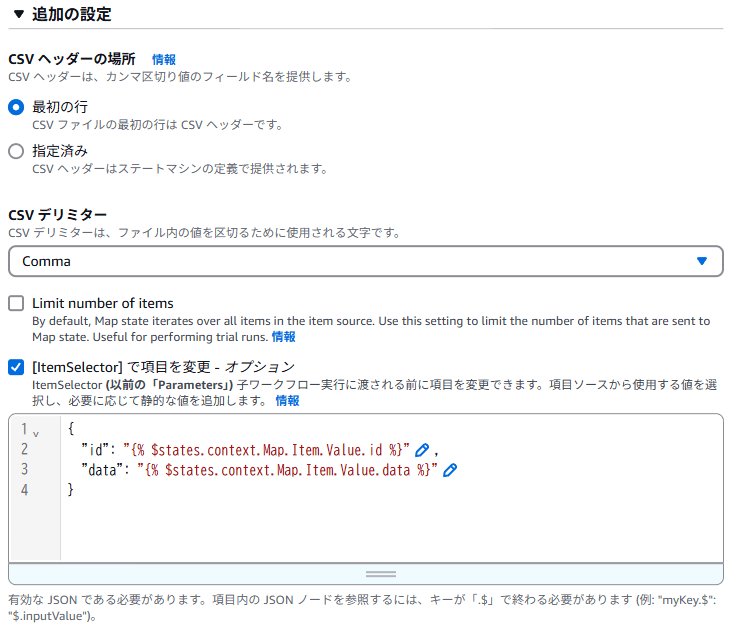
- CSV ファイルは先頭行に項目名を入れているため、CSV ヘッダーの場所を「最初の行」に設定します。CSV なのでデリミタは Comma です。
- CSV データからどのようにデータを取得するか、後工程でわかりやすくするため、ItemSelector を設定します。CSV 内には id, data の列があり、その項目名で JSON データに変換するイメージです。
- Map ステートでは CSV 各行のデータは $states.context.Map.Item.Value に格納される仕様になっており、その中に id, data が格納されるので上記のような書き方になります。
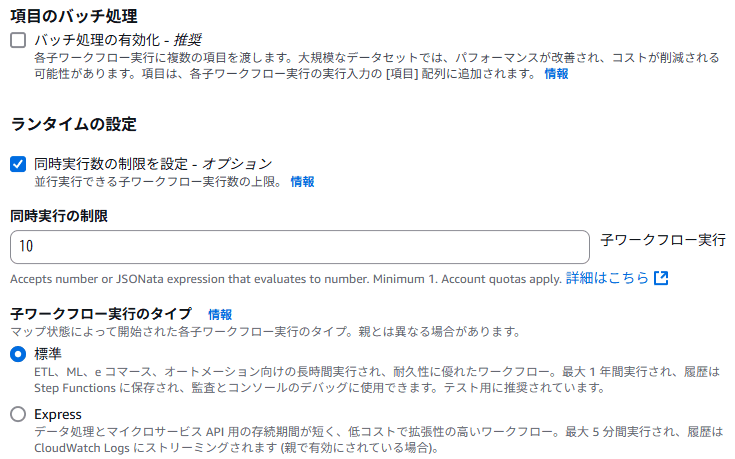
同時実行数制限は 10 にしました。Amazon Bedrock の基盤モデルを呼び出す類のリクエスト数は分単位での実行数制限があります。しかし、数百から数千単位の数なので、同時実行 10 であればさほど気にすることはないだろう、と考えました。
InvokeModel
Amazon Bedrock InvokeModel ランタイムを使用します。基本的には boto3 で InvokeModel するときと同じ引数 (パラメータ) を指定することになります。以下は例ですので、必要に応じてパラメータは変更しましょう。
注意点ですが、AWS Step Functions から直接 API を呼び出す場合、JSON 的に最初の階層の項目名は Pascal case、つまり先頭を大文字にしないとエラーになります。例えば modelId は ModelId にします。
{
"ModelId": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"ContentType": "application/json",
"Accept": "application/json",
"Trace": "DISABLED",
"PerformanceConfigLatency": "standard",
"Body": {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2000,
"top_k": 250,
"stop_sequences": [],
"temperature": 1,
"top_p": 0.999,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "{% 'Please translate the following text into Japanese and summarize it in no more than 300 characters.\n' & $states.input.data %}"
}
]
}
]
}
}
プロンプトは “text”: の部分に書いてある
です。日本語も問題ないですが、なんとなく英語で書きました。
その続きに、& 区切りで変数を追加しています。$states.input.data が CSV ファイルから読み取った元データです。これら引数は使用する基盤モデルによって変わることがありますので、ご注意ください。
出力は、成功時、エラー時ともに同じフォーマットに統一したかったので、以下のように固定で項目名を設定しています。
{
"id": "{% $states.input.id %}",
"data": "{% $states.input.data %}",
"result": "{% $parse($states.result.Body).content[0].text %}",
"status": "succeeded"
}
id と data は、インプットに入っていたものをそのまま後続に渡します。
result には、Amazon Bedrock 基盤モデルが返してきたレスポンスから、メッセージ部分だけを抽出して格納します。
status には、成功時は succeeded 固定です。
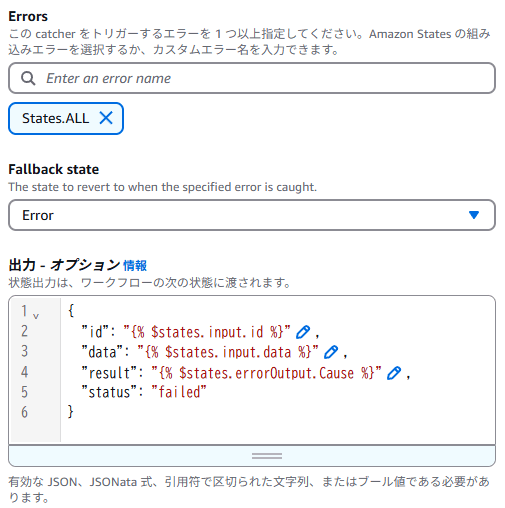
エラー処理には、キャッチャーを 1 つ設定し以下のように入れています。result にエラーメッセージ ($states.errorOutput.Cause) を、status には failed が格納されるようにしました。
Success/Error
これらのタスクは、ジョブフローの見た目で成功か失敗かをわかりやすくするために入れた Pass ステートです。特に何もしていません。
SendResult
このタスクは AWS Lambda 関数を呼び出しています。AWS Step Functions のデフォルト設定で Lambda 関数を紐づけているだけです。ここでは Lambda 関数のコードを紹介します。
Lambda 関数へのインプットは、以下のような JSON データになります。このデータが Lambda 関数内の event 変数に格納されます。
[
{
"id": "1",
"data": "Amazon Bedrock is a fully managed service that makes high-performing foundation models... 以下略",
"result": "# 日本語翻訳と要約\n\nAmazon Bedrockは、主要AI企業とAmazonの高性能基盤モデル(FM)を統一...以下略",
"status": "succeeded"
},
{
"id": "2",
"data": "With AWS Step Functions, you can create workflows, also called State machines, to build...以下略",
"result": "# 日本語訳と要約\n\nAWS Step Functionsでは、分散アプリケーション構築、プロセス自動化...以下略",
"status": "succeeded"
}
]
ユーザーには CSV ファイルとして結果を返したいので、この Lambda 関数内で pandas を使用して JSON を CSV に変換し、Amazon S3 バケットに保存します。
今回の仕様では、元データの CSV ファイルを保存した Amazon S3 バケットの output フォルダに結果 CSV ファイルを保存します。
- Lambda 関数
import json
import pandas as pd
import datetime
import boto3
s3 = boto3.resource('s3')
client = boto3.client('s3')
sns = boto3.client('sns',region_name='us-west-2')
def datetimeconverter(o):
if isinstance(o, datetime.datetime):
return str(o)
def lambda_handler(event, context):
try:
df = pd.DataFrame(event)
jstdelta = datetime.timedelta(hours=9)
JST = datetime.timezone(jstdelta, 'JST')
dtnow = datetime.datetime.now(JST)
fileNameDateTime = dtnow.strftime('%Y%m%d%H%M%S')
tempFileName = '/tmp/result_' + fileNameDateTime + '.csv'
outputBucket = 'bedrockjob-test'
outputS3Key = 'output/result_' + fileNameDateTime + '.csv'
# JSON to CSV
df.to_csv(tempFileName, encoding='utf-8_sig', index=None)
# upload CSV into S3
s3.meta.client.upload_file(tempFileName, outputBucket, outputS3Key)
# publish SNS
res = sns.publish(TopicArn='arn:aws:sns:us-west-2:xxxxxxxxxxxx:bedrockjob-SNSTopic-xxxxxxxxxxxx',Message='Your Bedrock job has been completed.\nS3Bucket: ' + outputBucket + '\nS3Key: ' + outputS3Key)
except Exception as e:
print(e)
return {
"result": str(e)
}
else:
return {
"result": res
}
最後、Amazon SNS トピックに完了メッセージを送信しています。本記事の主要なテーマではないので詳細は割愛します。
この Lambda 関数は pandas を使用するため、以下のブログ記事で紹介しているように、Lambda レイヤーの設定が必要になります。

ここで行っている JSON から CSV 変換ですが、他のアーキテクチャも考えました。AWS Glue や Amazon Athena を使用して簡単に (極力ノーコードで) できないかと思ったんですが、カタログやテーブル的なものを作成しなければならなかったので、このようなスポット的な変換処理、かつ所詮 CSV レベルのデータ量であれば Lambda でいいか、と落ち着きました。
参考: AWS CloudFormation テンプレート
これらリソース一式を AWS CloudFormation でデプロイできるようにしてあります。詳細な設定はこちらをご確認ください。Amazon SNS トピックはトピックを作成するところまでとなっていますので、サブスクライブは手動で実施ください。
AWSTemplateFormatVersion: 2010-09-09
Description: The CloudFormation template that creates a S3 bucket, a Lambda function, a Step Functions workflow, an EventBridge rule, a SNS topic, and relevant IAM roles.
# ------------------------------------------------------------#
# Input Parameters
# ------------------------------------------------------------#
Parameters:
SubName:
Type: String
Description: System sub name of the Bedrock job. (e.g. prod or test)
Default: test
MaxLength: 30
MinLength: 1
S3BucketNameSdk:
Type: String
Description: S3 bucket name in which you uploaded sdks for Lambda Layers. (e.g. sdkbucket)
Default: sdkbucket
MaxLength: 50
MinLength: 1
S3KeyPandasSdk:
Type: String
Description: S3 key of pandas.zip. Fill the exact key name if you renamed. (e.g. sdk/Python3.13/pandas223.zip)
Default: sdk/Python3.13/pandas223.zip
MaxLength: 50
MinLength: 1
BedrockClaudeModelId:
Type: String
Description: The Bedrock Model ID.
Default: "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
MaxLength: 100
MinLength: 1
BedrockOptionTopK:
Type: Number
Description: Top K parameter. The data type is int. The range is 0 to 500.
Default: 250
MaxValue: 500
MinValue: 0
BedrockOptionTopP:
Type: String
Description: Top P parameter. The data type is float. The range is 0 to 1.
Default: 0.999
MaxLength: 5
MinLength: 1
BedrockOptionTemperature:
Type: String
Description: Temperature parameter. The data type is float. The range is 0 to 1.
Default: 1
MaxLength: 5
MinLength: 1
BedrockOptionMaxTokens:
Type: Number
Description: Max Tokens parameter. The data type is int. The range is 100 to 64000.
Default: 2000
MaxValue: 64000
MinValue: 100
Resources:
# ------------------------------------------------------------#
# S3
# ------------------------------------------------------------#
S3BucketBedrockJob:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub bedrockjob-${SubName}
LifecycleConfiguration:
Rules:
- Id: AutoDelete
Status: Enabled
ExpirationInDays: 7
OwnershipControls:
Rules:
- ObjectOwnership: BucketOwnerEnforced
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
NotificationConfiguration:
EventBridgeConfiguration:
EventBridgeEnabled: true
Tags:
- Key: Cost
Value: !Sub bedrockjob-${SubName}
# ------------------------------------------------------------#
# Lambda S3 and SNS Invocation Role for Sfn (IAM)
# ------------------------------------------------------------#
LambdaS3SnsInSfnRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub bedrockjob-LambdaS3SnsInSfnRole-${SubName}
Description: This role allows Lambda functions to invoke S3 and SNS.
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
Path: /
Policies:
- PolicyName: !Sub bedrockjob-LambdaS3SnsInSfnPolicy-${SubName}
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Resource:
- !Ref SNSTopic
Action:
- sns:Publish
- Effect: Allow
Action:
- s3:PutObject
Resource:
- !Sub "${S3BucketBedrockJob.Arn}/*"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
- arn:aws:iam::aws:policy/AWSXRayDaemonWriteAccess
DependsOn:
- S3BucketBedrockJob
- SNSTopic
# ------------------------------------------------------------#
# Lambda Layer
# ------------------------------------------------------------#
LambdaLayerPandas223:
Type: AWS::Lambda::LayerVersion
Properties:
LayerName: !Sub bedrockjob-pandas223-${SubName}
Description: !Sub Pandas 2.2.3 for Python to load in bedrockjob-${SubName}
CompatibleRuntimes:
- python3.13
Content:
S3Bucket: !Sub ${S3BucketNameSdk}
S3Key: !Sub ${S3KeyPandasSdk}
LicenseInfo: BSD-3-Clause
# ------------------------------------------------------------#
# Lambda
# ------------------------------------------------------------#
LambdaSendResult:
Type: AWS::Lambda::Function
Properties:
FunctionName: !Sub bedrockjob-SendResult-${SubName}
Description: Lambda Function to send the Step Functions job result.
Runtime: python3.13
Timeout: 240
MemorySize: 256
Role: !GetAtt LambdaS3SnsInSfnRole.Arn
Handler: index.lambda_handler
Layers:
- !Ref LambdaLayerPandas223
Tags:
- Key: Cost
Value: !Sub bedrockjob-${SubName}
Code:
ZipFile: !Sub |
import json
import pandas as pd
import datetime
import boto3
s3 = boto3.resource('s3')
client = boto3.client('s3')
sns = boto3.client('sns',region_name='${AWS::Region}')
def datetimeconverter(o):
if isinstance(o, datetime.datetime):
return str(o)
def lambda_handler(event, context):
try:
df = pd.DataFrame(event)
jstdelta = datetime.timedelta(hours=9)
JST = datetime.timezone(jstdelta, 'JST')
dtnow = datetime.datetime.now(JST)
fileNameDateTime = dtnow.strftime('%Y%m%d%H%M%S')
tempFileName = '/tmp/result_' + fileNameDateTime + '.csv'
outputBucket = '${S3BucketBedrockJob}'
outputS3Key = 'output/result_' + fileNameDateTime + '.csv'
# JSON to CSV
df.to_csv(tempFileName, encoding='utf-8_sig', index=None)
# upload CSV into S3
s3.meta.client.upload_file(tempFileName, outputBucket, outputS3Key)
# publish SNS
res = sns.publish(TopicArn='${SNSTopic}',Message='Your Bedrock job has been completed.\nS3Bucket: ' + outputBucket + '\nS3Key: ' + outputS3Key)
except Exception as e:
print(e)
return {
"result": str(e)
}
else:
return {
"result": res
}
# ------------------------------------------------------------#
# State Machine Execution LogGroup (CloudWatch Logs)
# ------------------------------------------------------------#
LogGroupStateMachineBedrockJob:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/vendedlogs/states/bedrockjob-${SubName}
RetentionInDays: 365
Tags:
- Key: Cost
Value: !Sub bedrockjob-${SubName}
# ------------------------------------------------------------#
# State Machine Execution Role (IAM)
# ------------------------------------------------------------#
StateMachineExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub bedrockjob-StateMachineExecutionRole-${SubName}
Description: This role allows State Machines to call specified AWS resources.
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
states.amazonaws.com
Action:
- sts:AssumeRole
Path: /
Policies:
- PolicyName: !Sub bedrockjob-StateMachineExecutionPolicy-${SubName}
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource:
- !Sub "${S3BucketBedrockJob.Arn}/*"
- Effect: Allow
Action: states:StartExecution
Resource: "*"
- Effect: Allow
Action: states:DescribeExecution
Resource: "*"
- Effect: Allow
Action:
- bedrock:InvokeModel*
- bedrock:CreateInferenceProfile
Resource:
- arn:aws:bedrock:*::foundation-model/*
- arn:aws:bedrock:*:*:inference-profile/*
- arn:aws:bedrock:*:*:application-inference-profile/*
- Effect: Allow
Action:
- bedrock:GetInferenceProfile
- bedrock:ListInferenceProfiles
- bedrock:DeleteInferenceProfile
- bedrock:TagResource
- bedrock:UntagResource
- bedrock:ListTagsForResource
Resource:
- arn:aws:bedrock:*:*:inference-profile/*
- arn:aws:bedrock:*:*:application-inference-profile/*
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaRole
- arn:aws:iam::aws:policy/CloudWatchLogsFullAccess
- arn:aws:iam::aws:policy/AWSXrayWriteOnlyAccess
DependsOn:
- S3BucketBedrockJob
# ------------------------------------------------------------#
# Step Functions
# ------------------------------------------------------------#
StateMachineBedrockJob:
Type: AWS::StepFunctions::StateMachine
Properties:
StateMachineName: !Sub bedrockjob-${SubName}
StateMachineType: STANDARD
DefinitionSubstitutions:
DSLambdaSendResultArn: !GetAtt LambdaSendResult.Arn
DSBedrockClaudeModelId: !Ref BedrockClaudeModelId
DSBedrockOptionTopK: !Ref BedrockOptionTopK
DSBedrockOptionTopP: !Ref BedrockOptionTopP
DSBedrockOptionTemperature: !Ref BedrockOptionTemperature
DSBedrockOptionMaxTokens: !Ref BedrockOptionMaxTokens
DefinitionString: |-
{
"Comment": "The state machine to invoke Bedrock job.",
"QueryLanguage": "JSONata",
"StartAt": "Map",
"States": {
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "STANDARD"
},
"StartAt": "InvokeModel",
"States": {
"InvokeModel": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:bedrockruntime:invokeModel",
"Next": "Success",
"Output": {
"id": "{% $states.input.id %}",
"data": "{% $states.input.data %}",
"result": "{% $parse($states.result.Body).content[0].text %}",
"status": "succeeded"
},
"TimeoutSeconds": 600,
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Comment": "Error",
"Next": "Error",
"Output": {
"id": "{% $states.input.id %}",
"data": "{% $states.input.data %}",
"result": "{% $states.errorOutput.Cause %}",
"status": "failed"
}
}
],
"QueryLanguage": "JSONata",
"Arguments": {
"ModelId": "${DSBedrockClaudeModelId}",
"ContentType": "application/json",
"Accept": "application/json",
"Trace": "DISABLED",
"PerformanceConfigLatency": "standard",
"Body": {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": ${DSBedrockOptionMaxTokens},
"top_k": ${DSBedrockOptionTopK},
"stop_sequences": [],
"temperature": ${DSBedrockOptionTemperature},
"top_p": ${DSBedrockOptionTopP},
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "{% 'Please translate the following text into Japanese and summarize it in no more than 300 characters.\n' & $states.input.data %}"
}
]
}
]
}
}
},
"Error": {
"Type": "Pass",
"End": true,
"QueryLanguage": "JSONata"
},
"Success": {
"Type": "Pass",
"End": true,
"QueryLanguage": "JSONata"
}
}
},
"Label": "Map",
"MaxConcurrency": 10,
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW",
"CSVDelimiter": "COMMA"
},
"Arguments": {
"Bucket": "{% $states.input.bucket %}",
"Key": "{% $states.input.key %}"
}
},
"ItemSelector": {
"id": "{% $states.context.Map.Item.Value.id %}",
"data": "{% $states.context.Map.Item.Value.data %}"
},
"QueryLanguage": "JSONata",
"ToleratedFailureCount": 5,
"Next": "SendResult"
},
"SendResult": {
"QueryLanguage": "JSONata",
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Output": "{% $states.result.Payload %}",
"Arguments": {
"FunctionName": "${DSLambdaSendResultArn}",
"Payload": "{% $states.input %}"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"End": true,
"Comment": "Invoke the Lambda function to send the result of this state machine via email.",
"TimeoutSeconds": 300
}
},
"TimeoutSeconds": 7200
}
LoggingConfiguration:
Destinations:
- CloudWatchLogsLogGroup:
LogGroupArn: !GetAtt LogGroupStateMachineBedrockJob.Arn
IncludeExecutionData: true
Level: ERROR
RoleArn: !GetAtt StateMachineExecutionRole.Arn
TracingConfiguration:
Enabled: true
Tags:
- Key: Cost
Value: !Sub bedrockjob-${SubName}
DependsOn:
- LogGroupStateMachineBedrockJob
- StateMachineExecutionRole
# ------------------------------------------------------------#
# EventBridge Role (IAM)
# ------------------------------------------------------------#
EventBridgeRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub bedrockjob-EventBridgeRole-${SubName}
Description: This role allows EventBridge to call the Step Functions state machine.
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: events.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: !Sub bedrockjob-EventBridgePolicy-${SubName}
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action: states:StartExecution
Resource: !Ref StateMachineBedrockJob
DependsOn:
- StateMachineBedrockJob
# ------------------------------------------------------------#
# EventBridge Rule
# ------------------------------------------------------------#
EventBridgeRule:
Type: AWS::Events::Rule
Properties:
Name: !Sub bedrockjob-StartStateMachine-${SubName}
Description: This rule starts the Step Functions state machine when the CSV data is put in the S3 bucket.
EventBusName: default
State: ENABLED
EventPattern: !Sub |-
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["${S3BucketBedrockJob}"]
},
"object": {
"key": [{
"wildcard": "input/*.csv"
}]
}
}
}
Targets:
- Arn: !Ref StateMachineBedrockJob
RoleArn: !GetAtt EventBridgeRole.Arn
Id: !Sub bedrockjob-StartStateMachine-${SubName}
InputTransformer:
InputPathsMap:
bucket: "$.detail.bucket.name"
key: "$.detail.object.key"
InputTemplate: |
{
"bucket": ,
"key":
}
RetryPolicy:
MaximumRetryAttempts: 1
MaximumEventAgeInSeconds: 3600
DependsOn:
- S3BucketBedrockJob
- EventBridgeRole
# ------------------------------------------------------------#
# SNS Topic
# ------------------------------------------------------------#
SNSTopic:
Type: AWS::SNS::Topic
Properties:
TracingConfig: PassThrough
DisplayName: !Sub bedrockjob-notification-${SubName}
FifoTopic: false
Tags:
- Key: Cost
Value: !Sub bedrockjob-${SubName}
まとめ
いかがでしたでしょうか?
プロンプトの調整、インプットデータのサニタイズ、センシティブ情報のマスキングなど課題はありますが、個人利用であれば運用でカバーできると思っています。
本記事が皆様のお役に立てれば幸いです。