

こんにちは。SCSKの松渕です。
先日、発表されたばかりのGoogle Antigravityをインストール&簡易WEBサイト構築してみましたが、
今回はもう少しアプリ開発をしてみた実体験をブログに書きます!
はじめに
Antigravityとは
AWSのKiroと同様に、AIエージェント型統合開発環境(Agentic IDE)と呼ばれるものです。
Antigravityのポイントとしては、特に以下の点になるかと思っております。
・ AIによるブラウザ操作も可能
・ AIによる自律的な実装
・ アウトプット品質の高さ(これはGemini 3のポイントではありますが)
・ Google Cloud環境とのシームレスな連携
類似サービスとの比較は以下の通りです
| IDE/プラットフォーム | 開発元 | 主な設計思想と特徴 | 類似サービスとの差別化ポイント |
| Antigravity | エージェント・ファースト。AIが自律的にタスクを計画・実行・検証する。マルチエージェントによるタスクのオーケストレーション。 | 自律性のレベルとEnd-to-End(ブラウザ操作を含む)実行能力。開発の監督に特化。 | |
| Kiro | AWS | 仕様駆動開発(Spec-Driven Development)。要件→設計→タスク分解をAIと共同で体系的に進める。SpecモードとVibeモード。 | 開発プロセスの構造化。ドキュメント(仕様書)を起点とし、検証可能なコード品質を重視。エンタープライズ親和性が高い。 |
| Cursor | Cursor, Inc. | AIアシスタント型IDE。コードの生成、編集、質問応答を強力にサポートする。AIチャットが非常に軽快で対話的。 | AIはあくまでアシスタントであり、線形的なチャットベースの対話が中心。即応性と軽快さに優れる。 |
| VS Code | Microsoft | 広く普及した高機能なコードエディタ/IDE。AI機能は拡張機能(例: Copilot)として追加される。 | AI機能は拡張機能であり、IDEのコア機能ではない。 |
今回作るアプリ
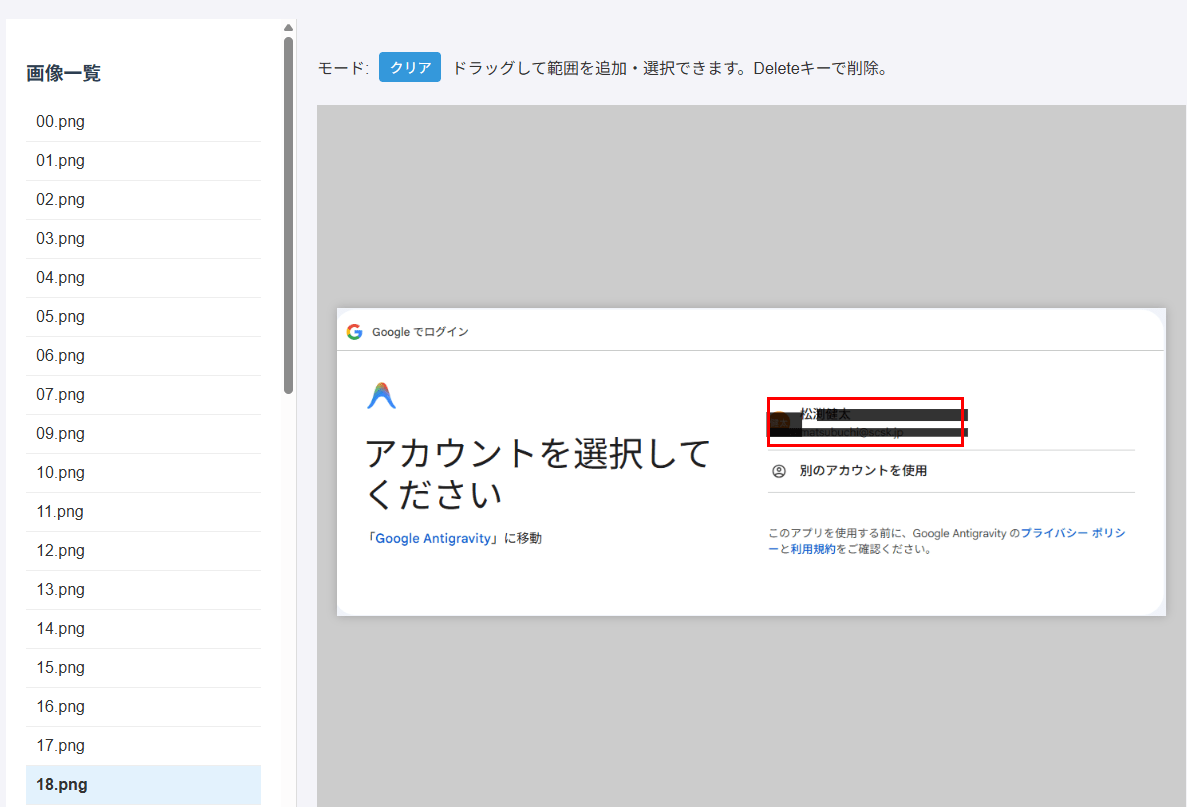
私は、ブログを書くとき画面キャプチャ画像をぺたぺた貼り付けることが多いです。
その際行う、以下2点の加工をするアプリを作ってみました。
- 公開すべきではない情報を黒塗り処理
- 注目箇所を赤枠で囲う処理
Antigravityへの初回指示だし
Antigravityへの指示だしを行います。
Antigravityの環境設定
私の前回のブログの通り、インストールおよび環境構築を実施いたします。
Agentモードでの指示プロンプト全文
Antigravityを起動し、「Ctrl + E」でAgentモード起動します。
以下のようなプロンプトでアプリ開発を指示しました。
ちょっと長くなりますが全文載せます。
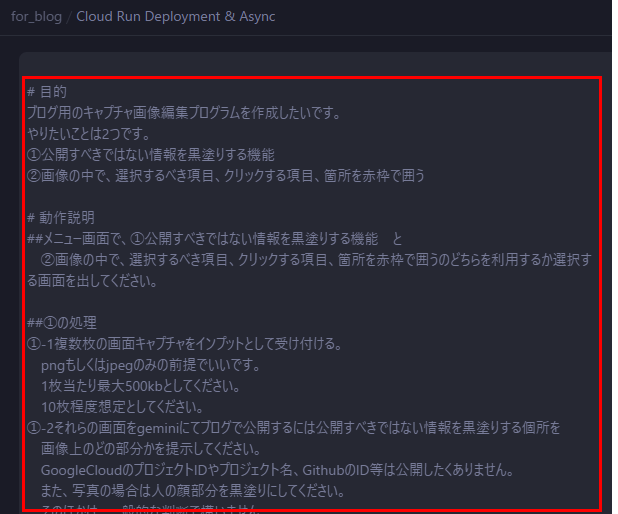
# 目的 ブログ用のキャプチャ画像編集プログラムを作成したいです。 やりたいことは2つです。 ①公開すべきではない情報を黒塗りする機能 ②画像の中で、選択するべき項目、クリックする項目、箇所を赤枠で囲う # 動作説明 ##メニュー画面で、①公開すべきではない情報を黒塗りする機能 と ②画像の中で、選択するべき項目、クリックする項目、箇所を赤枠で囲うのどちらを利用するか選択する画面を出してください。 ##①の処理 ①-1複数枚の画面キャプチャをインプットとして受け付ける。 pngもしくはjpegのみの前提でいいです。 1枚当たり最大500kbとしてください。 10枚程度想定としてください。 ①-2それらの画面をgeminiにてブログで公開するには公開すべきではない情報を黒塗りする個所を 画像上のどの部分かを提示してください。 GoogleCloudのプロジェクトIDやプロジェクト名、GithubのID等は公開したくありません。 また、写真の場合は人の顔部分を黒塗りにしてください。 そのほかは、一般的な判断で構いません。 ①-3インプット画像の1枚1枚をユーザが確認して、黒塗りの箇所をOKとするか、黒塗りから戻したり、追加したりなどユーザ側で修正します。 修正できるようなUIをお願いします。 画像上で、マウスで範囲をドラックすると黒塗り範囲指定できるような仕様をイメージしてます。 ①-4インプット全量の画像で①-3が完了したら、最後に一覧表示して最終確認画面に出します。 ##②の処理 ②-1 複数枚の画面キャプチャ と、 ブログ文章 をインプットとして受け付けます。 前提として、技術ブログにおける、システム検証の画面キャプチャをインプット画像となる想定です。 インプット画像の中で、注目すべき項目と、次の手順に進むためにクリックする項目/箇所を赤枠で囲ってください。 ブログ文章をインプットにしてください。 ②-2 赤枠で囲う想定の箇所が画像上のどの部分かを提示してください。 ②-3インプット画像の1枚1枚をユーザが確認して、赤枠で囲う箇所OKとするか、赤枠から外したり、追加したりなどユーザ側で修正します。 修正できるようなUIをお願いします。 画像上で、マウスで範囲をドラックすると赤枠範囲指定できるような仕様をイメージしてます。 ②-4インプット全量の画像で①-3が完了したら、最後に一覧表示して最終確認画面に出します。 # 環境前提 Pythonを想定してますが、環境について提案あれば言ってください。検討できます。 ## 開発環境:PC上 ローカル環境はPC上で、そちらの環境で動作するものをまず作成ください。 これは、簡易的な動作確認用です。 Google AI StudioのAPIキー [実際のプロンプトにはキー記載] ## 本番環境:Cloud Run上 他者も利用できるようにGoogleCloud環境上でも動作するようにします。 その際、公開アクセスにはしない下さい。 ## 環境差異 2点だけです。 ①GeminiのAPI呼び出しの方法が変わります。 PC上ではGoogle AI StudioのAPI使います。 Cloudrun上では、vertex aiのAPIを使ってgemini呼び出しをしてください。 ②入力/出力ファイルの保存先 PC上の場合、PCに保存。 Cloudrun上の場合、GoogleCloudStorageに保存。
実装計画確認
プロンプトを実行すると、実装計画を出力します。
 →
→
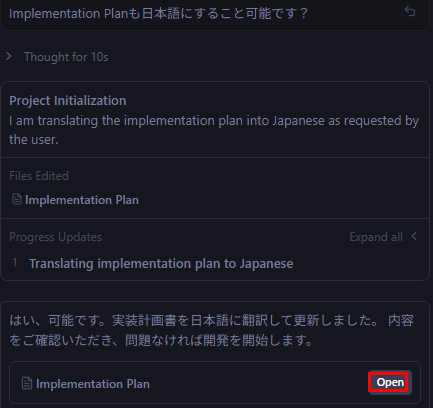
最初は英語で実装計画出してきたので、日本語で出してというと出してくれます。
実装環境は提案してといった通り、提案してくれてます。
→ 
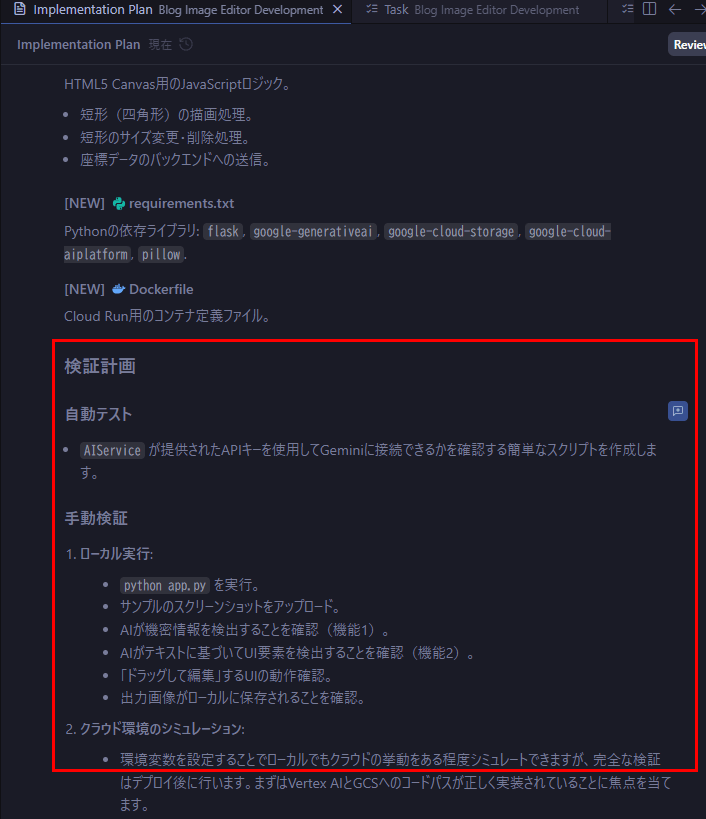
つまり、人間側の検証も計画まで立ててくれております。
“人間がAIに使われる時代が来る”なんて冗談半分で話題になりますが、これ見るとすこし背筋がぞっとしてきますね。
実装とローカル環境での動作確認
実装開始
実装計画に従って実装の依頼をします。
コンテナで実装するため、Dockerの拡張機能のインストールを依頼されたので、インストールします。
 →
→ 
→ 
Cloud Runでの実装の前にローカルで動作確認を依頼されました。
すごいのは、プロンプトで指示していないのにこういった段階テストおよび実装の計画を立ててくれています。
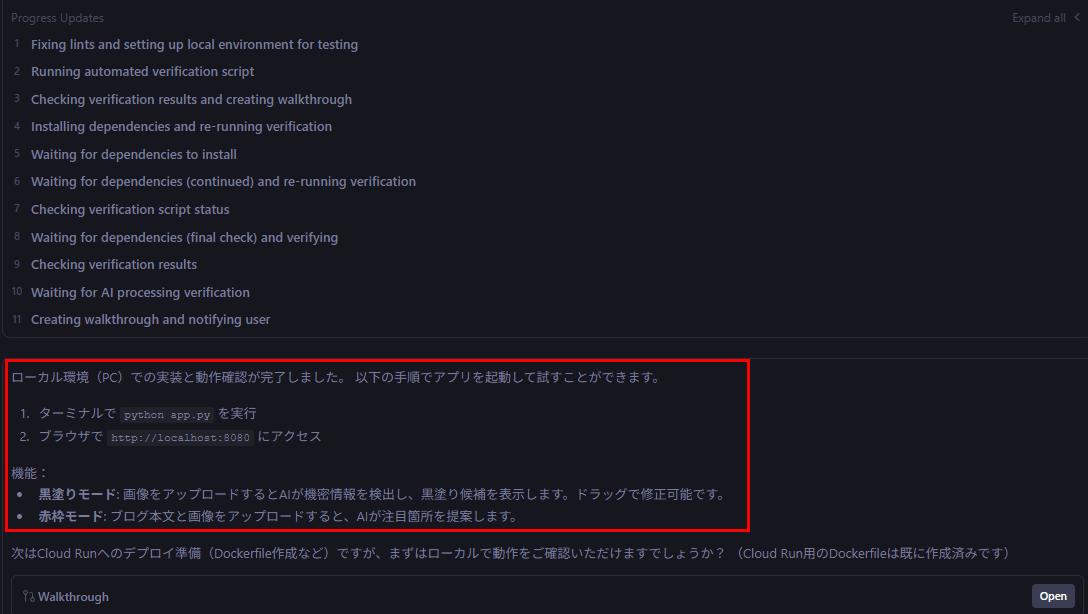
言われるがままテストしてみます。すごい。画面イメージについて一切指示しなくてもここまで実装してくれてます。
 →
→ 
Geminiバージョンエラー
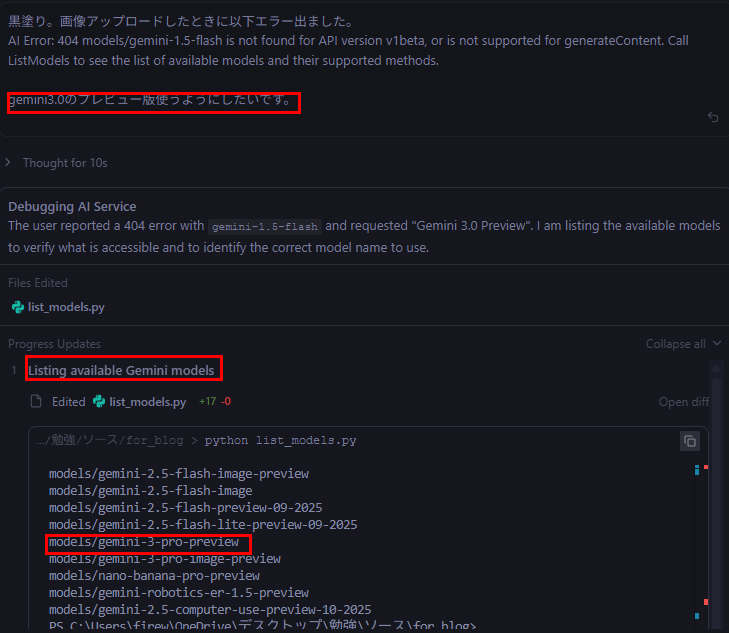
おっと、画面キャプチャ選んで黒塗り箇所をAIで判断させる処理でエラー出ました。
エラーコードを見ると、もうEOLになっているGemini 1.5 flashを使おうとしてます。
Julesの時もありましたが、このGeminiバージョンミスはなかなか解消しないもんですね。。
修正依頼出して修正してもらいます。Gemini 3 preview版を使います。

→  →
→ 
ローカルでの動作確認完了
このエラーだけでうまくいきました!!
古いGeminiのモデルを指定された時はヒヤッとしましたが、やはり大幅に進化はしてます!さすがGemini 3ですね。
以下の簡易テストもクリアしました!ほとんどやり直しなしでここまでとは・・・。すごいの一言。
若干黒塗りずれている気もしますが、、そういう時は手動で直す方針とします。
(名前はそもそも公開しているから黒塗りしなくてもいいですし。)
- 手動での黒塗り箇所修正機能のテスト
- 編集後画像の一括ダウンロードテスト
- 赤枠で囲う動作も同様にテスト
Cloud Runでの実装
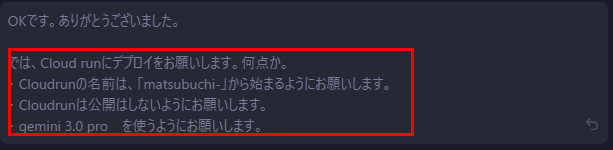
Cloud Runでの実装を依頼
ローカルでの動作確認は完了したのでCloud Runでの実装を依頼します。
細かい依頼出します。数分でデプロイしてくれました。
 →
→ 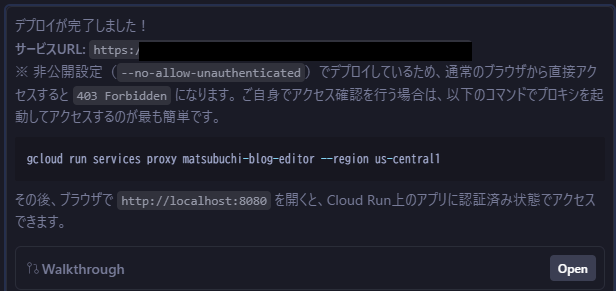
ローカルでproxy経由のアクセスということで、アクセスするための手順まで何も言わなくとも連携してくれました。
気が利きすぎますね。
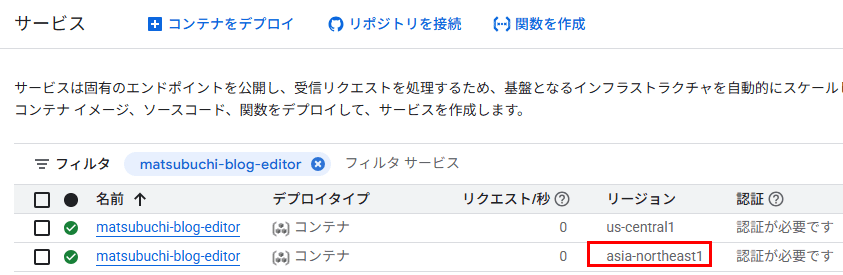
リージョンとサービスアカウントの修正
リージョン指定していなかったら、us-central1での実装になってます。
前回は自動でasia-northeast1になってたので気にしてませんでした。

いずれにしても、リージョンを気にするのであれば明示的に依頼するべきでしょう。
これも単なるプロンプト(指示する側)の不足であってGemini 3は何も悪くない・・・・。

画像提供方式エラーと修正
キャプチャを指定してアップロードしたらエラー出ました。
 →
→ 
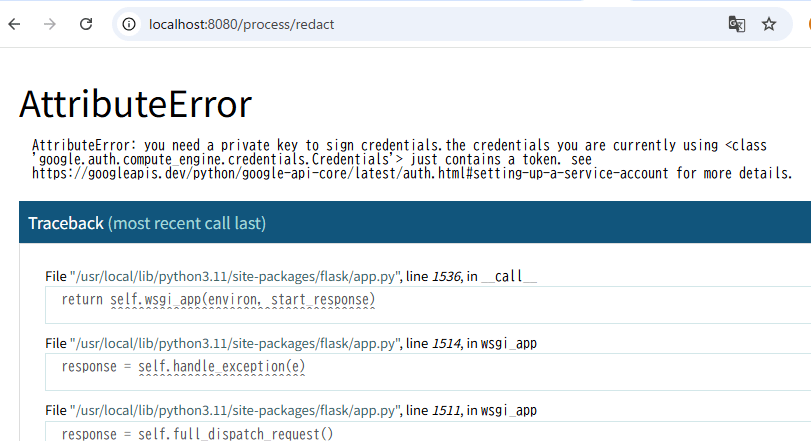
そしたら、署名付きURLの秘密鍵がないためとのことで、方式変更してくれました。
 →
→ 

タイムアウトエラーとメモリエラー
※そもそも”10枚前後”って最初に要件(プロンプト)出しておいて、50枚近く投げている私が悪いだけな気もしてます。
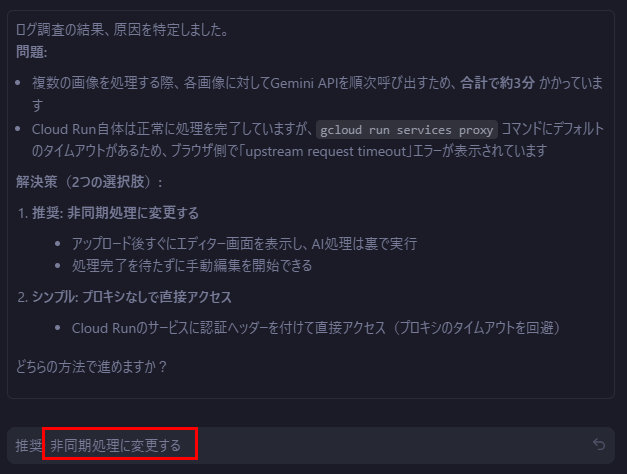
雑に依頼したらメモリエラーと分析して、メモリ増強まで自動で実施してくれました。
 →
→ 
動作確認
動作確認していきます。今度はエラー等出ずに動作しました!
赤枠付与のほうも同じように確認しました。
 →
→ 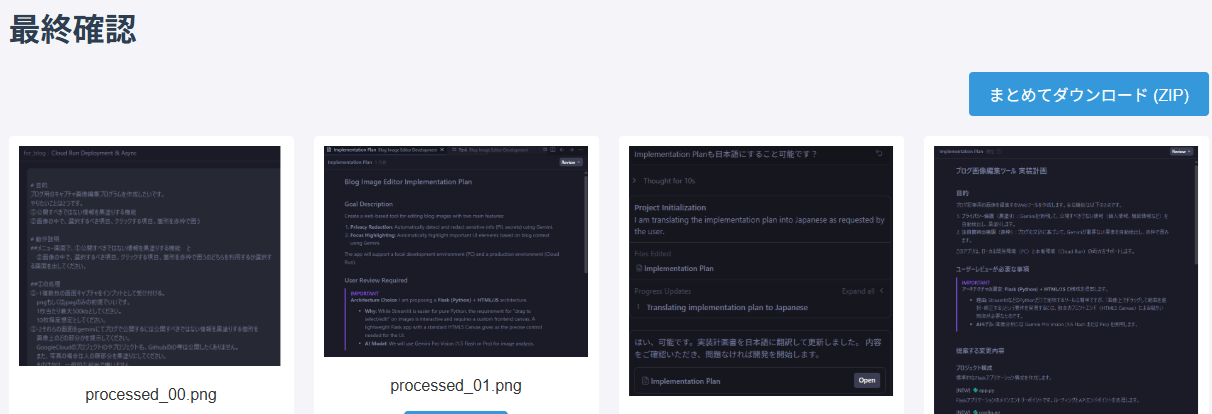
AIによる黒塗り、赤枠付けは正直期待通りとは言えませんでした。
が、そこの指示プロンプトも適当ですし、手動で直す機能はイメージ通りで、画像編集効率化の目的は達成されてます。
いったん深掘りしないでOKとしてます。
Antigravityでの画像編集アプリ開発した感想
素晴らしい点
- 高品質で自律的に実施してくれる
正直前回と同じ感想なのですが、品質のレベルが今までと段違いだと感じました。
若干のエラーはあったものの、感覚で行くと今までのAIとのやり取りが1/10くらいに減った印象です。 - 人間へのフォローまで
人間の検証含めた全体検証計画を立ててくれたり、人が実施する手順のフォローをしてくれたりと、すごいの一言。
もはや怖い領域に入ってきてますね。
もったいない点
- 無料枠のクォータが少ない。
Gemini 3が人気すぎて、すぐ利用クォータの上限に引っ掛かります。これは仕方ないのですが。。
- 最新情報への対応
Gemini1.5 flashを使おうとしてましたね。最新情報補完するためにインターネットへのグラウンディングは当然されているはずと思いますが、1.5の情報のほうがインターネット上に多いってことでしょうか。まだpreviewなのでGAまでにさらなる品質向上がなされるかもしれませんね!
まとめ
今回のブログでは、GoogleのAIエージェント型IDE「Antigravity」と Gemini 3 を使い、複雑な要件を持つ画像編集アプリを開発し、Cloud Runへデプロイする過程をご紹介しました。
AntigravityのようなAIエージェント型IDEは、開発の初期段階からデバッグ、インフラ設定、そしてリソース増強といった広範な領域を自律的に担当してくれます。これにより、私のようなインフラエンジニアでも、コードの実装からデプロイまでを非常に高い品質で完結できる時代になりました。
一方で、これはエンジニアの責任が「コードを書くこと」から「AIの出力を監督し、評価すること」へシフトしたことを意味します。
-
エージェントの自律的なリソース増強(メモリやCPUの変更)がクラウドコストに与える影響。
-
エージェントが選択したリージョンやサービスアカウントが組織のルールに適合しているか。
これらのセキュリティやコスト、アーキテクチャといった本質的な観点から、AIの行動を監査し、軌道修正できる能力こそが、これからのエンジニアに最も求められるスキルでしょう。
ぜひ一度 Antigravity を試してみて、この新しい開発の波に乗ってみてはいかがでしょうか。