

前回の記事では AWS DRS の設定までできたので、今回はリカバリ(フェイルオーバー)を実施したいと思います。
リカバリ(フェイルオーバー)
リカバリ前準備
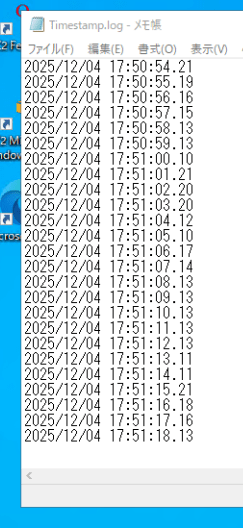
どのくらいリアルタイムで復旧できるのか確認するために、毎秒時刻をテキストファイルに出力させました。
リカバリ開始
「リカバリジョブを開始」ー「リカバリを開始」を押下します。
※リカバリとリカバリドリルの挙動に違いはありませんが、リカバリジョブの履歴にそのジョブがドリルであったかリカバリであったかが記録されます。訓練 (ドリル) 目的であったのか実際のリカバリを実施したのかを区別するのに役立ちます。
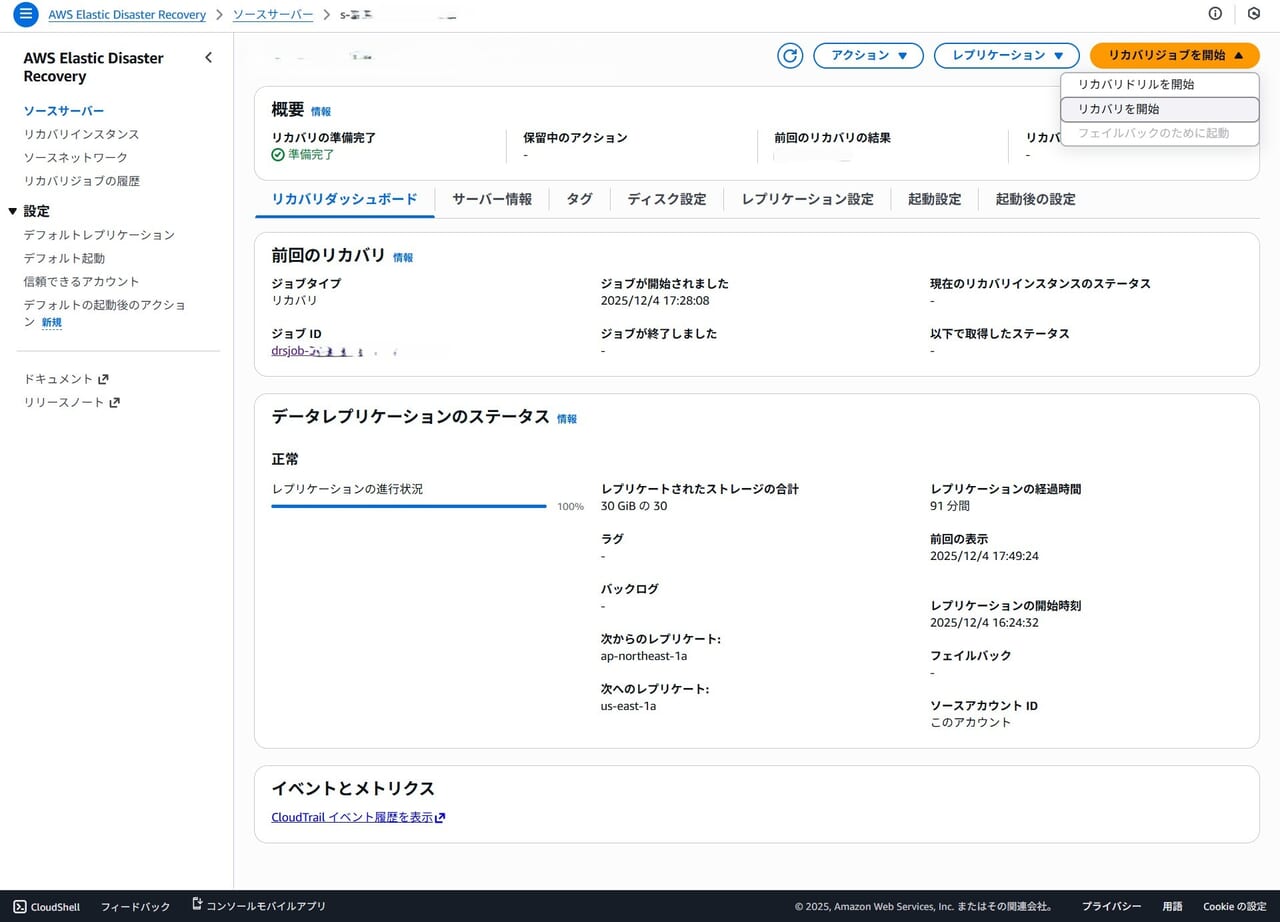
復旧ポイントを選択します。
今回は最新のデータを選択しました。
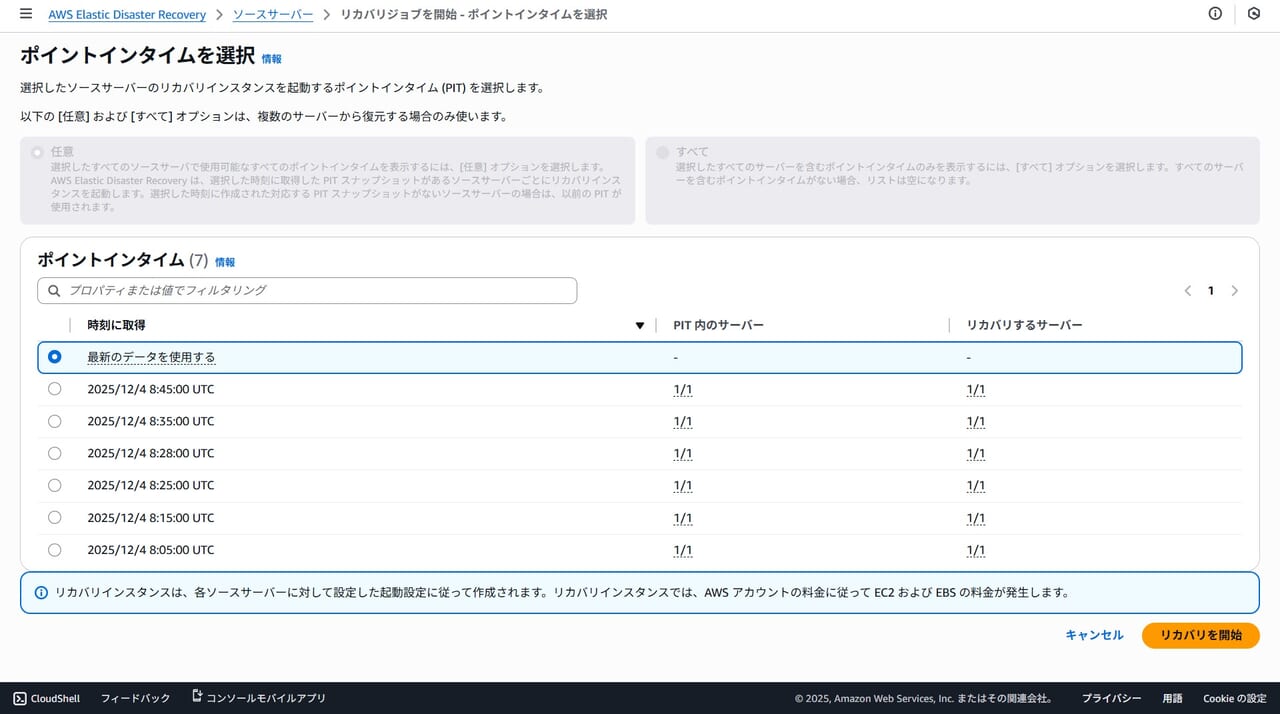
リカバリジョブが開始されると「AWS Elastic Disaster Conversion Server」というサーバが起動しました。

Conversion Server は、AWS Elastic Disaster Recovery において、フェイルオーバー時にレプリケートされたデータを EC2 として起動可能な形に変換するための一時的なサーバのようです。通常時は起動しておらず、フェイルオーバー時のみ自動的に起動・停止されます。
「AWS Elastic Disaster Conversion Server」の停止後、リカバリインスタンスが起動してきました。
ジョブの実行履歴を確認すると20分ほどで復旧できたようです。
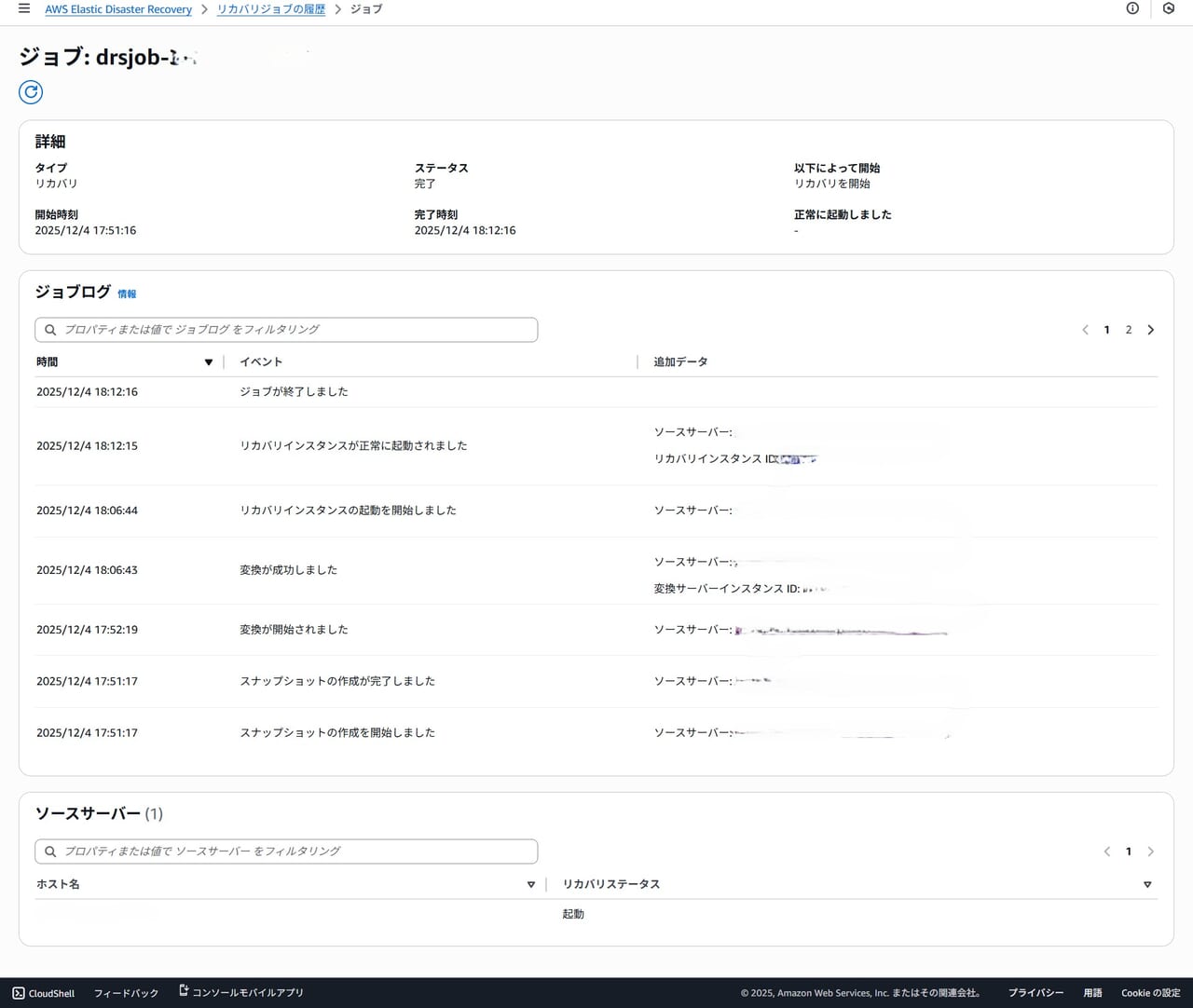
復旧したリカバリインスタンスはDRSコンソールからも確認できます。
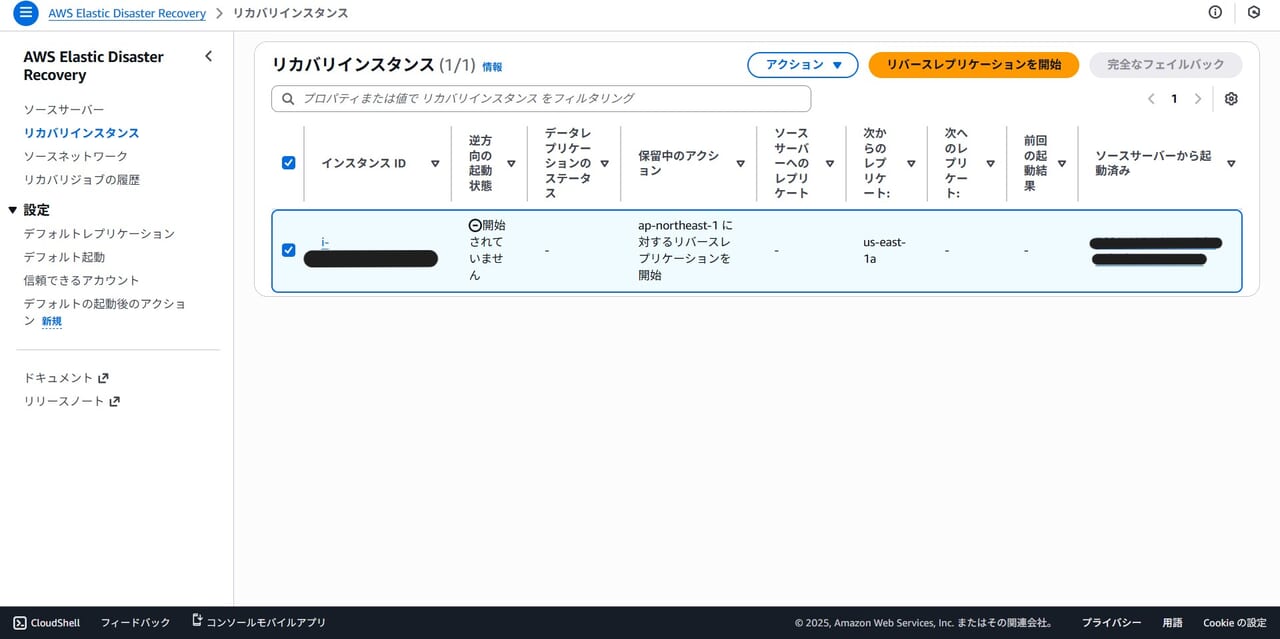
リカバリインスタンスの確認
復旧したインスタンスの状態を確認します。
ホスト名とプライベートIPアドレスは復旧前後で変わりませんでした。
インスタンスタイプは起動設定で「インスタンスタイプの適切なサイジング」を指定しているため、自動的に割り当てられました。
←ソースインスタンス(復旧前) →リカバリインスタンス(復旧後)

次に最後に出力された時刻を確認します。
リカバリジョブを開始してから2秒後の時刻まで書き込まれています。
ほぼほぼリアルタイムで復旧することができました。
実際の障害時には障害発生より前のポイント指定することになりますが、
達成したいRPOが存在する場合は、環境要因により変動するので事前検証をおすすめします。
フェイルバック検証
では、続いてフェイルバックを検証してみたいと思います。
今度はリカバリインスタンスを起点に東京リージョンに向けて、リバースレプリケーションを実施していきます。
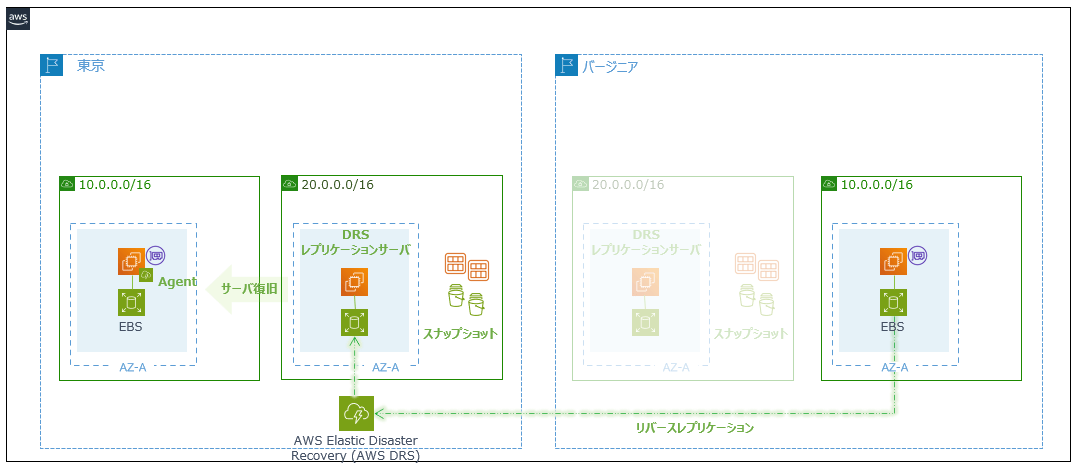
DR先リージョン(今回はバージニア)のDRSコンソールからリカバリインスタンスを選択し、「リバースレプリケーションを開始」をクリックします。
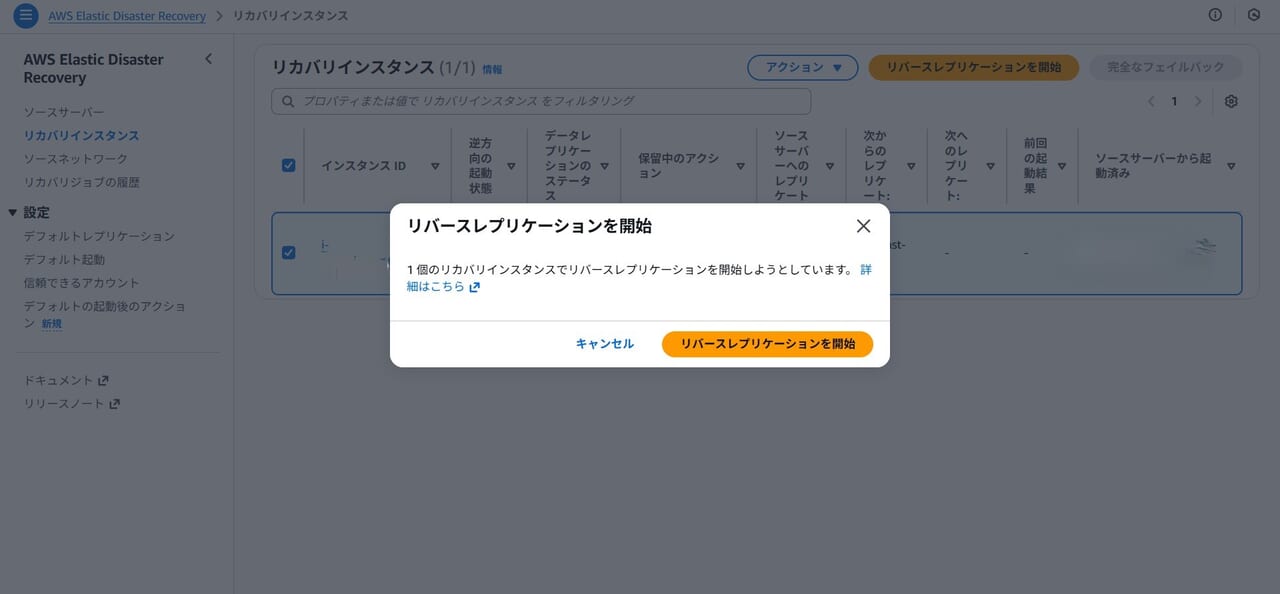
バージニアリージョンのDRSコンソールを確認すると、東京リージョンへのレプリケーションが開始されました。
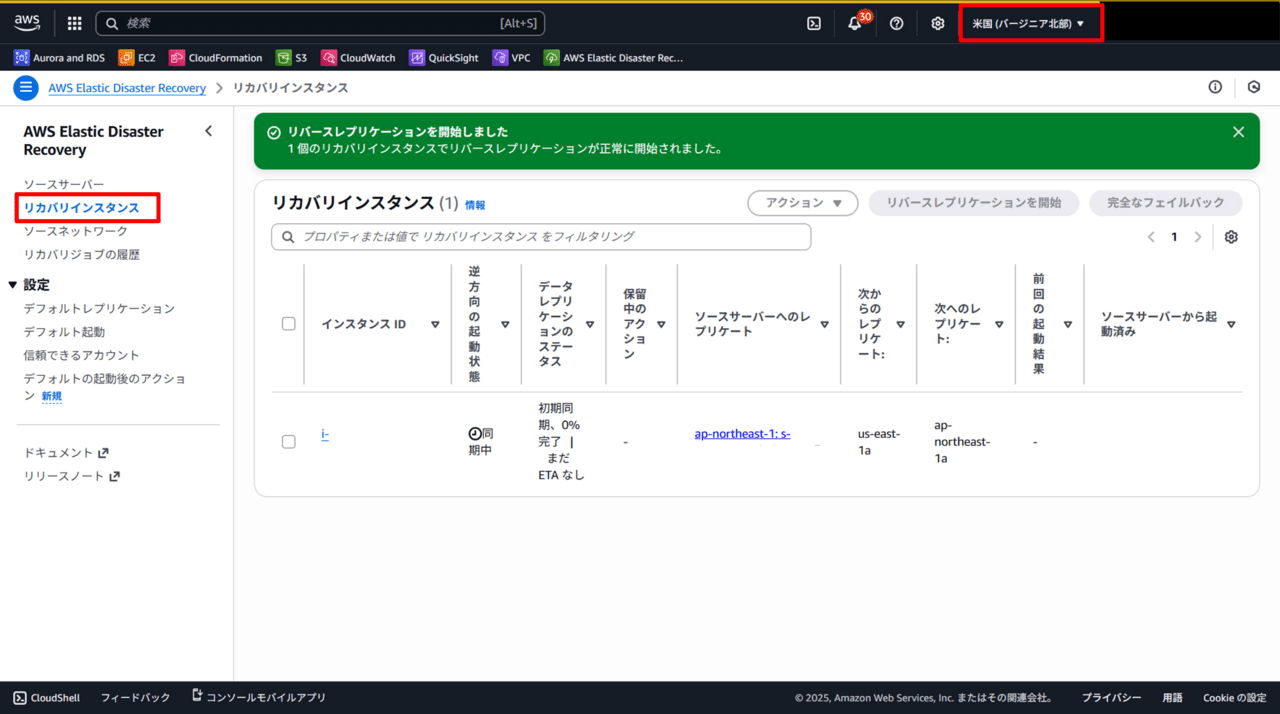
東京リージョンのDRSコンソールを確認すると、新しくソースサーバが登録されました。
ここはフルコピーとなるため、完了まで1時間半ほどかかりました。
データ量やネットワーク帯域によるので、実際に本番のフェイルバック時は考慮が必要です。 
ソースサーバの登録が完了したら、リカバリジョブを実行すればサーバ復旧できます。
これ以降の流れはフェイルオーバーの時と同様のため、割愛します。
まとめ
AWS Elastic Disaster Recovery(DRS)の操作は、ほぼすべてAWSマネジメントコンソール上で完結しており、専門的な手作業を求められる場面は多くありません。設定項目も整理されており、初見でも理解しやすい構成となっている点が印象的でした。
フェイルオーバー操作は数クリックで実行でき、あらかじめテストフェイルオーバーを実施することで、本番障害を想定した事前検証を容易に行えます。実際の切替手順を事前に確認できるため、障害発生時にも落ち着いて対応できる運用体制を構築しやすいと感じました。
また、DR専用のサーバや外部製品を常時用意する必要がなく、複雑なスクリプトや自動化処理を事前に組み込むことなくDR環境を構築できる点も大きな利点です。その結果、運用担当者に求められるスキルや習熟コストを抑えることができ、属人化しにくい運用が実現できます。
これらの点から、AWS DRS は 「DR を導入したいが、運用負荷や複雑さはできるだけ抑えたい」 というケースにおいて、非常に有効な選択肢であると感じました。