

初めまして。SCSKの芦川です。
AWS上で大規模な会員向けアプリケーションの構築・運用に携わっています。
業務の中で、既存のOpenSearchにカスタムAIモデルを連携する構成を検討する機会がありました。
本記事では、OpenSearchとSageMakerを組み合わせたセマンティック検索基盤の構築事例について、検討の過程を交えながらご紹介します。
1. 現状の検索構成
先日、アプリケーション開発チームより、次のような相談を受けました。
「クーポン検索機能を高度化するカスタムAIモデル(DistilUSE)を作ったので、こちらをAWS上にデプロイして既存のOpenSearchと連携してほしい」
当時の検索機能は、OpenSearchを中心とした比較的シンプルな構成でした。
アプリケーションユーザーからのクーポン検索リクエストは、まずECS上で稼働しているアプリケーション(コンテンツ取得API)に送信されます。このAPIが検索条件を受け取り、OpenSearch Serviceの検索APIを呼び出すことで検索を実行します。
OpenSearch側ではクーポン情報をインデックスとして保持しており、検索は主にキーワード検索(完全一致・部分一致)によって行われていました。検索結果はAPIを経由してアプリケーションに返却され、最終的にユーザー画面へ表示されます。
また、OpenSearch ServiceおよびECSは同一VPC内に配置されており、通信はALBを介して行われる構成です。
この構成では、検索に関する処理はOpenSearchに集約されており、検索クエリの解釈や意味的な理解といった処理は実装していませんでした。
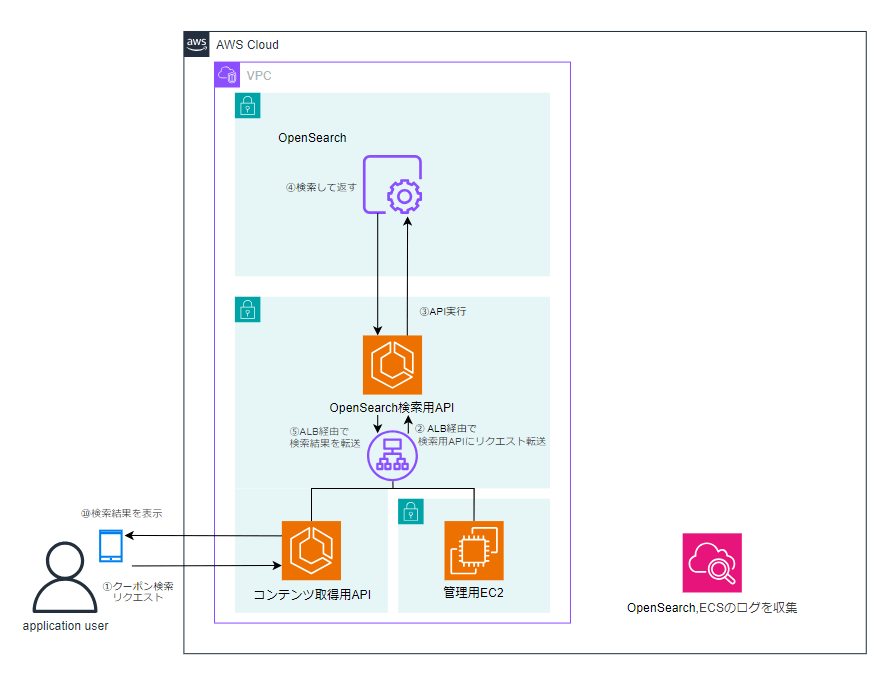
図1:ECS上のAPIからOpenSearchを直接呼び出し、検索結果を返す構成
2. 構成検討の過程
アプリケーションチームから依頼を受け、まずは既存の構成を大きく変えずにカスタムAIモデルを組み込めないかを検討しました。
その選択肢の一つとして、OpenSearchが提供する ML Commons 機能の利用を検討しました。
ML Commonsでは、S3に配置したモデルをOpenSearch側でロードし、検索処理の中で推論を実行する仕組みが提供されています。
この仕組みを利用すれば、推論用のサーバーを新たに用意する必要がなく、アーキテクチャを比較的シンプルに保てると考えました。
そこで、アプリケーション開発チームから受領したカスタムAIモデル(DistilUSE / tar.gz) をS3に配置し、OpenSearch Serviceからモデルのロードを試みました。
しかし、結果としてこの構成は実現できませんでした。
今回受領したカスタムモデルは、OpenSearch Service(マネージド環境)におけるML Commonsの制約により、そのまま有効化することができない仕様だったからです。
このため、OpenSearch内部でモデルを実行する構成は断念し、別のアーキテクチャを検討することにしました。
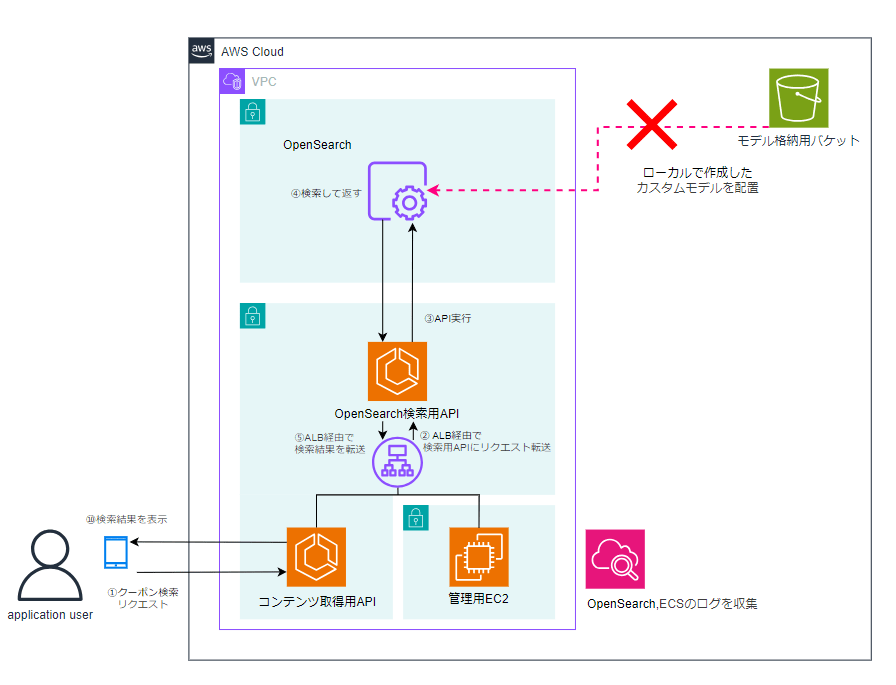 図2:S3に配置したモデルをOpenSearch内部で実行する構成(検討時)
図2:S3に配置したモデルをOpenSearch内部で実行する構成(検討時)
ML Commons を利用できなかった理由
ML Commons の利用を見送った理由は、主に実行環境とマネージドサービスとしての制約にあります。
受領したカスタムAIモデルはPython(PyTorch)ベースで構築されていましたが、OpenSearch Service の ML Commons はJavaベースの実行環境を前提としています。そのため、モデルをそのまま実行することが難しく、形式変換などの追加対応が必要となりました。
これらの対応は工数や運用面の負荷が大きく、今回は現実的ではないと判断しました。
また、OpenSearch Service はマネージドサービスであるため、外部から持ち込んだカスタムモデルを柔軟に実行すること自体に制約があります。
以上の検討を通じて、OpenSearch内部で計算処理を行う構成は適切ではないと判断し、別の実行基盤を用いた構成を検討することにしました。
次章では、その検討結果として採用したSageMakerを用いた構成について説明します。
3. 最終アーキテクチャ
検討の結果、計算処理は計算専用のリソースに切り出すべきと判断し、カスタムAIモデルの実行基盤として Amazon SageMaker を採用しました。
最終的に採用したアーキテクチャを図3に示します。
本構成では、検索機能そのものは引き続きOpenSearchが担い、検索クエリやドキュメントのベクトル化といった計算負荷の高い処理をSageMakerの推論エンドポイントに委譲しています。
これにより、OpenSearchに過度な処理を持たせることなく、役割を明確に分離した構成とすることができました。
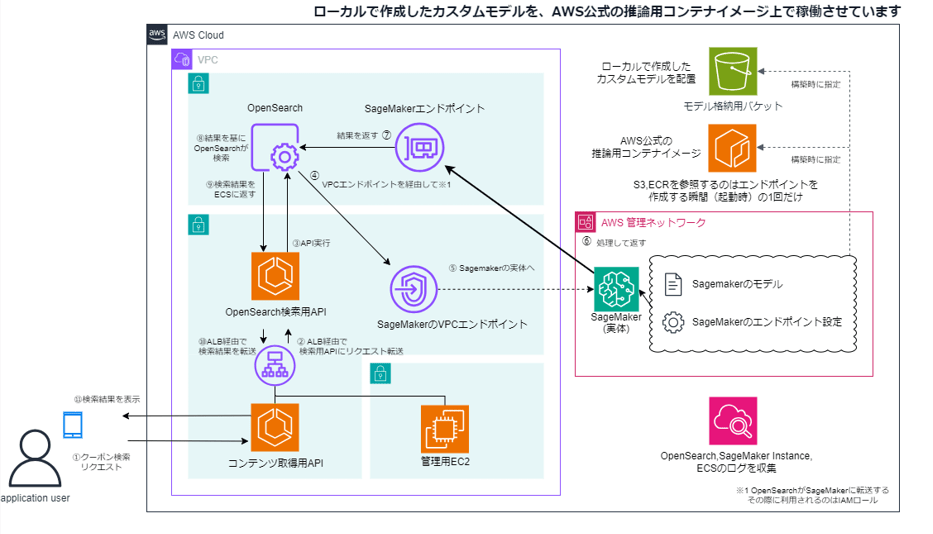
図3:SageMaker推論エンドポイントと連携した最終構成
4. SageMaker採用の背景
以降では、SageMakerを採用した理由について説明します。
「Amazon Bedrock(サーバーレス)を利用すれば、より簡単に実装できたのではないか」という選択肢もありましたが、最終的には SageMakerを用いた自前構築が最適と判断しました。
理由は大きく2点あります。
理由1:カスタムモデルの利用要件
Amazon Bedrockは、あらかじめ用意された基盤モデルをAPI経由で利用できるサービスです。一方で、利用できるモデルはBedrock側で提供されているものに限定されます。今回のケースでは、アプリケーション開発チームより特定のカスタムモデル(DistilUSE)を利用したいという明確な要件がありました。
この要件を満たすには、モデルや実行環境を自由に構成できるSageMakerを採用する必要がありました。
理由2:スケールとコストの観点
今回対象としたシステムは、全国規模で利用される会員向けアプリケーションであり、検索リクエストが高頻度かつ継続的に発生することが想定されます。
BedrockのようなAPIベースのサービスは従量課金であるため、
- リクエスト数の増加に伴うコストの増大
- レート制限(スロットリング)による影響
といった点が懸念されました。
一方、SageMakerの推論エンドポイントは、インスタンスをプロビジョニングすることで、一定のコストで安定した処理能力を確保できます。大規模なトラフィックを前提とした場合、コストの見通しやすさと安定性の面でSageMakerの方が適していると判断しました。
5. 構築時のポイント
構築にあたっては、以下の点を重視しました。
-
役割の分離
検索処理はOpenSearch、ベクトル化などの計算処理はSageMakerとし、各コンポーネントの責務を明確に分離しました。 -
閉域網でのセキュリティ確保
SageMakerの推論エンドポイントはVPC内に配置し、OpenSearchとはVPCエンドポイント経由で通信させています。
データがインターネットを経由しない構成としました。 -
アプリケーション側の変更を最小限に抑える構成
検索処理はOpenSearch側で完結する構成とすることで、アプリケーション(ECS)側はSageMakerの存在を意識することなく、従来通り検索リクエストを送信するだけで利用可能としました。
なお、AIモデルのデプロイにはAWS公式の推論用コンテナイメージ(DLC)を使用し、アプリケーションチームから受領した model.tar.gz(モデル本体・設定・辞書)をそのまま推論環境として利用しています。
6. まとめ
本構成により、コストや運用リスクを抑えつつ、柔軟な検索機能を実現できるアーキテクチャを構築することができました。
また、補足として、S3に配置したシノニム辞書をOpenSearchと連携させることで、検索精度の底上げも行っています。
今回の取り組みを通じて、AI機能の実装においては用途や規模に応じたサービスの使い分けが重要であると改めて感じました。
-
Amazon Bedrock
手軽に始めたい場合や、小〜中規模でモデルに強い制約がないケース -
Amazon SageMaker
特定のモデルを利用したい場合や、大規模アクセスを前提とするケース
単に動作する仕組みを作るだけでなく、将来的なスケールや運用まで見据えた設計を行うことの重要性を学ぶ良い機会となりました。