

こんにちは。SCSKの岡尾です。
皆さん、S3 Tablesについてご存じでしょうか。
AWS re:Invent 2024で発表され、話題を呼んだ新機能「Amazon S3 Tables」。データレイクの構築・運用を根本から変えるポテンシャルを秘めたこのサービスについて、「実際にどう使えるの?」「既存のS3バケットと何が違うの?」と気になっている方も多いのではないでしょうか。
本記事では、S3 Tablesの基本的な概要を紹介しつつ、実際にS3 Tablesへのデータ連携(ETL処理)を実装する中で「これは便利だ!」と感じた機能について、これから利用を検討している方向けに解説します。
1. S3 Tablesとは
Amazon S3 Tablesは、オープンテーブルフォーマットであるApache Iceberg形式のテーブルを、S3上でネイティブに保存・管理できるフルマネージド機能です。
これまでデータレイクを構築する際は、S3バケットにParquet形式などのファイルを配置し、AWS Glue Data Catalogでメタデータを管理してテーブルとして扱うのが一般的でした。S3 Tablesは、これをS3自身の機能として統合し、AWS Glue Data Catalogとのシームレスな連携や、テーブルのメンテナンス作業を自動化してくれます。
S3(Parquet)との比較
従来の「S3にParquetファイルを直置きする方式」と比較すると、S3 Tablesにはデータエンジニアを悩ませてきた課題を解決する強力なメリットがあります。
| S3 Tables | 従来のS3(Parquet) | |
| ACIDトランザクションのサポート | 複数のETLジョブやユーザーが同時に読み書きを行っても、データの整合性が完全に保証される. | ファイルベースのため、データの書き込み中に別の分析クエリが走ると、不完全なデータが読み取られるリスクがある. |
| ファイル管理・メンテナンスの自動化 | S3側で自動的にファイルのコンパクション(最適化)や、不要になった古いスナップショットの削除を行ってくれるため、チューニングや運用保守の手間が省ける. | ストリーミング処理などで小さなファイルが大量に発生する(スモールファイル問題)とクエリ性能が劣化するため、定期的にファイルを結合するバッチ処理を自前で組む必要がある. |
| レコードレベルの更新・削除 | レコード単位での更新(UPDATE)や削除(DELETE)が、通常のデータベースのようにSQLで簡単に実行可能. |
特定のレコードを含む対象のParquetファイル全体を読み込み、除外・置換して書き直す必要がある. |
2. S3 Tablesの機能紹介
ここからは、実際に外部システムからS3 Tablesへデータを連携するETL処理を実装した際に、有用だと実感した機能をご紹介します。
Upsert処理
データ連携において「新規レコードは追加(INSERT)し、既存レコードで変更があったものは更新(UPDATE)する」というUpsert処理は頻出要件です。
従来のS3(Parquet)環境でUpsertを実現しようとすると、対象データの全量読み込み、IDベースでの差分結合、そして新しいファイルの再生成という泥臭く重い処理を書く必要がありました。
しかしS3 Tablesを利用することで、Amazon AthenaやAWS Glue(Apache Spark)などから**MERGE INTO構文を使ってシンプルにUpsert処理を記述できる**ようになります。
<サンプルコード>
spark.sql(f"""
MERGE INTO glue_catalog.{S3_DATABASE_NAME}.{S3TABLE_NAME} AS t
USING staging AS s
ON {" and ".join(join_phrase_list)}
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
タイムトラベル
ETL運用における落とし穴として、「誤って本番データのテーブルを上書きしてしまったり、削除してしまうこと」があります。従来のS3では、オブジェクトのバージョン管理を有効にしてスクリプトを書いて復元するなど、が必要でレコード単位ではさらに労力がかかっていました。
S3 Tablesは、データが更新されるたびにスナップショットを自動的に保持しています。この仕組みを利用したタイムトラベル機能により、過去の任意の時点のデータをクエリしたり、障害発生前の状態にテーブルを瞬時にロールバックしたりすることが可能です。
ETLのジョブ性能の検証で同じデータを用いて条件を変えながら検証する場面でこの機能を利用しました。これにより、簡単にデータが連携される前の状態にロールバックすることができ、非常に便利だと思いました。
簡単にAthenaからスナップショットの一覧を確認できます。
SELECT * FROM "<テーブル名>$snapshots"
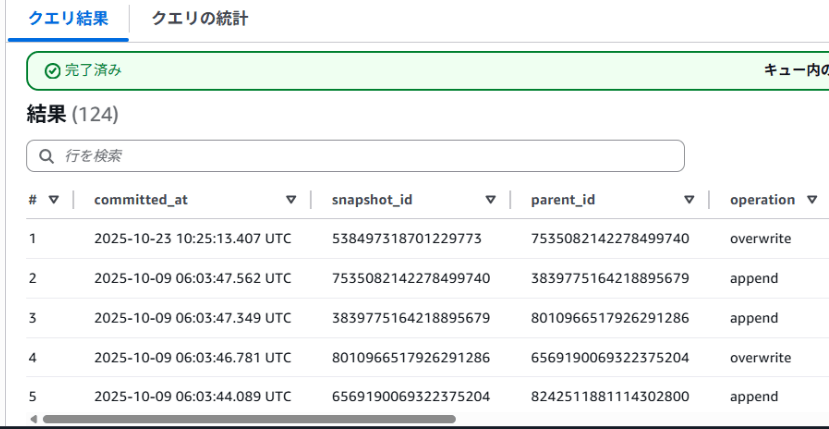
また、スナップショットからの復元は、一度データを削除してから以下のように過去の時点のデータを挿入することで可能です。
INSERT INTO "<テーブル名>" SELECT * FROM "<テーブル名>" FOR TIMESTAMP AS OF TIMESTAMP '2026-03-23 09:00:00 UTC';
障害時はさらに重宝しそうな機能だなと思いました。
3. まとめ
今回S3 Tablesを触ってみて、単なる「S3の新しい保存領域」ではなく、上手に活用することでデータレイクの課題(トランザクション管理、ファイル最適化、レコード更新など)を解決してくれるソリューションだと感じました。
これからデータ基盤の新規構築や、既存のデータレイクの刷新を検討している方は、ぜひS3 Tablesを選択肢に入れてみてください。運用負荷を大きく下げ、よりデータ活用そのものに注力できる環境が手に入るはずです。