
こんにちは、SCSKの松岡です📊
今回は、データの可視化・分析において、Amazon Redshiftを用いて事前集計アーキテクチャの見直しを行った際の試行錯誤を整理しました。
また、データマネジメントの観点で、Amazon Sagemaker (Amazon Datazone) を用いて改善できるポイントについてもご紹介します。
背景

データ活用基盤を構築するにあたり、データの可視化・分析のために、「データマートとして、どこでデータを加工・集約するか」は重要な設計ポイントの1つです。
BIツールは可視化や分析に優れる一方で、データ量の増加や分析要求の高度化に伴い、複雑な結合や集計処理を担わせた場合、処理時間やレスポンスに影響が出る可能性があります。そのため、データの加工・集約処理をどのレイヤーで実施するかは、性能と運用性の両面から慎重に設計する必要があります。
- Qlik Cloudを用いたデータ可視化を実現したい
- 複数システムから収集したデータを統合した分析がしたい
- データ量が大きく、結合・集計処理が複雑
- レスポンス性能が重要
- ソースシステムのデータ品質にばらつきがある
このような前提のもと、PoCにてデータマートの実現方法と構成の妥当性を検証しました。
構成と選定理由
Why Amazon Redshift ?
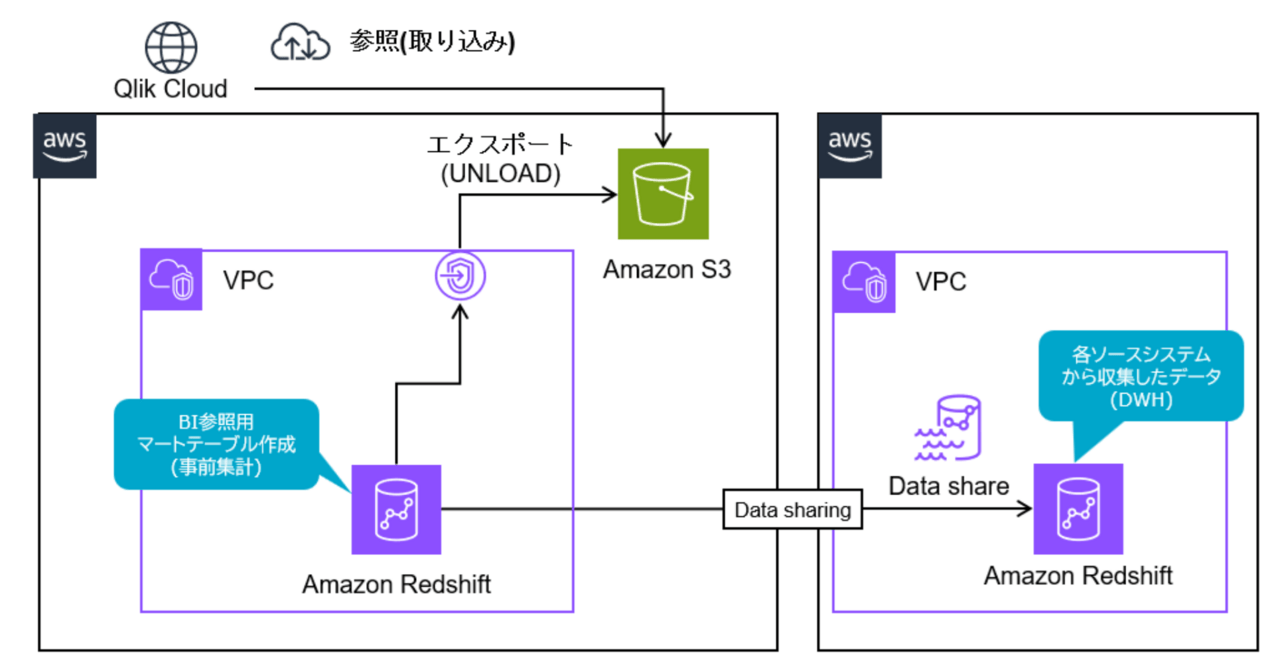
データマートの構築および事前集計の実行基盤としてAmazon Redshiftを採用しました。
BIツールに集計処理を寄せる構成はシンプルである一方、データ量の増加や複雑な結合処理を伴う場合、レスポンスや安定性に影響が出る可能性があります。そのため、本構成ではデータマート側で集計処理を実施し、BIツールは可視化に特化させる方針としました。
具体的には、Redshift上でデータマートテーブルを構築し、事前集計を行うことで、Qlik Cloud側の処理負荷を軽減しています。
また、複数AWSアカウントにデータが分散していたため、Redshiftのデータ共有(Data Sharing)機能を活用し、各アカウントのDWHデータを横断的に参照しています。
この機能により、データをコピーすることなく他アカウントのデータを参照可能であり、参照元クラスターのコンピューティングリソースに影響を与えない形でデータ統合を実現できます。
さらに、Redshift上で構築したマートテーブルは、日次バッチ処理により洗い替えで再生成し、Amazon S3へ出力しています。マート構築時には、ソースデータのばらつきを考慮したクレンジング処理も併せて実施しています。
出力されたS3上のデータは、Qlik Cloudから参照・取り込みを行うことで、BIツール側では軽量なデータセットとして扱うことが可能となります。
気にしたポイント
本PoCにおいては、データマートテーブルを設計・実装するにあたり、特に以下の観点を重視して構築を行いました。
前提として、本設計はデータオーナーやデータアナリストとは異なる立場から、データマートの構造および処理方法を定義する役割として実施しています。
データ品質の観点
複数のソースシステムからデータを取得し結合処理を行う場合、同一名称のカラムであってもコード体系や採番ルールが異なるケースが存在します。そのため、キー結合を実装する前に、結合率の検証やコード分布の確認を実施し、不整合の有無を定量的に把握しました。
また、システム仕様だけでは判断できない部分については、データオーナーへのヒアリングを通じて業務上の意味を確認し、結合条件の妥当性を担保しています。
加えて、個々のデータ値レベルでのクレンジングも重要なポイントです。実データには、日付フォーマットの不整合や、「00000000」のようなテストデータ・異常値が混在しているケースが確認されました。これらをそのままマートに取り込むと分析結果に影響を与えるため、検知・除外・補正のいずれかの対応が必要となります。
これらのクレンジングについては、ソースシステム側で修正するのか、データマート作成時に補正するのか、あるいはフィルタリングにより分析対象から除外するのかといった複数の選択肢が存在します。そのため、一律のルールとはせず、データの特性や業務影響を踏まえて個別に方針を整理し、データオーナーおよびデータアナリストと合意の上でクレンジングルールを設計しました。
データモデルの観点
データモデルおよびテーブル間のリレーションについて、テーブル構造はER図として整理し、結合対象のテーブル間の関係性(カーディナリティ)が1対1または1対多で成立しているかを事前に確認しました。
特に注意が必要なのが、多対多の関係を持つテーブル同士の結合です。結合キーに対して双方のテーブルに複数レコードが存在する場合、結合処理ではそれらの組み合わせがすべて生成されます。例えば、片方に200件、もう片方に400件のレコードが存在すると、結果は単純な加算ではなく200×400=80,000件となり、元データ以上にレコード数が増加します。このように、結合はカーディナリティに応じてレコード数が掛け算的に増加する性質を持つため、多対多のまま結合するとデータ量の爆発的増加や集計値の歪み、処理性能の劣化を引き起こす懸念があります。
そのため、設計時には各テーブルのデータ粒度を明確に定義しました。また、多対多の関係を避けられない場合には、中間テーブルを別途設計して関係性を分解することで、データの整合性と可読性を担保することも検討しています。
改善ポイント
今回のように複数システムのデータを統合してデータマートを設計する場合、事前に各テーブルのコード体系やデータ品質上の注意点を把握することが重要となります。こうした課題に対する改善策として有効なのが、データカタログの活用です。
近年では、Amazon Web Servicesが提供するAmazon DataZoneをベースとしたカタログ機能が、Amazon SageMaker上の「SageMaker Catalog」として統合的に利用可能となっています。この仕組みを用いることで、複数AWSアカウントに分散したデータ資産(例:Redshiftのテーブル)を横断的にカタログ化し、一元的に可視化することができます。
データオーナーやデータ基盤管理者は、自身が管理するテーブルに対して、コード体系やカラム定義、利用上の注意点といったメタデータをカタログ上に登録します。これにより、利用者は事前にデータの意味や制約を把握した上で利用することが可能となり、結合条件の誤りやデータ解釈のズレを未然に防ぐことができます。
このように、データカタログを活用することで、今回のように個別に確認していたデータ品質や仕様の把握を仕組みとして標準化することができ、データマート設計の効率化と品質向上の両立が期待できます。
「SageMaker Catalog」では、生成AIを活用したメタデータの自動補完やセマンティック検索により、データの発見性が大幅に向上します。また、ビジネス用語集やメタデータ管理機能により、データの意味や利用上の注意点を業務文脈で整理することが可能です。さらに、データのリネージ(データの流れ)を可視化することで、どのような加工を経て生成されたデータかを追跡でき、分析結果の信頼性向上につながります。加えて、データ品質のモニタリング機能により、欠損率や異常値などの品質指標を継続的に把握することも可能です。
まとめ
本記事では、データマートをどのレイヤーで構築するかという設計判断に対し、Amazon Redshiftを用いた事前集計アーキテクチャを採用することで、BIツールの負荷軽減と安定した分析基盤の実現を目指しました。集計処理をデータマート側に寄せることで、レスポンス性能を確保しつつ、可視化ツールの役割を明確に分離することができました。
一方で、データマート設計においては、単なるデータ加工ではなく、データ品質やカーディナリティ、データ粒度といった観点を踏まえた設計が不可欠でした。特に、多対多の関係によるデータ増幅や、コード体系の不整合といった問題は、事前の検証と関係者間での調整が重要でした。
さらに、こうした設計・確認のプロセスは、データカタログを活用することで効率化・高度化が可能です。メタデータや業務知識をカタログとして蓄積・共有することで、データの理解と活用を組織的に支援でき、データマート設計の品質向上にもつながります!
(宣伝) クラウドデータ活用サービス
今回ご紹介した内容は、SCSKで提供しているクラウドデータ活用サービスの中で扱っているテーマの一部になります。
お客様のデータ活用状況に応じて、基盤構築から可視化、データ連携、データマネジメント、高度データ活用までを段階的にご支援しています!
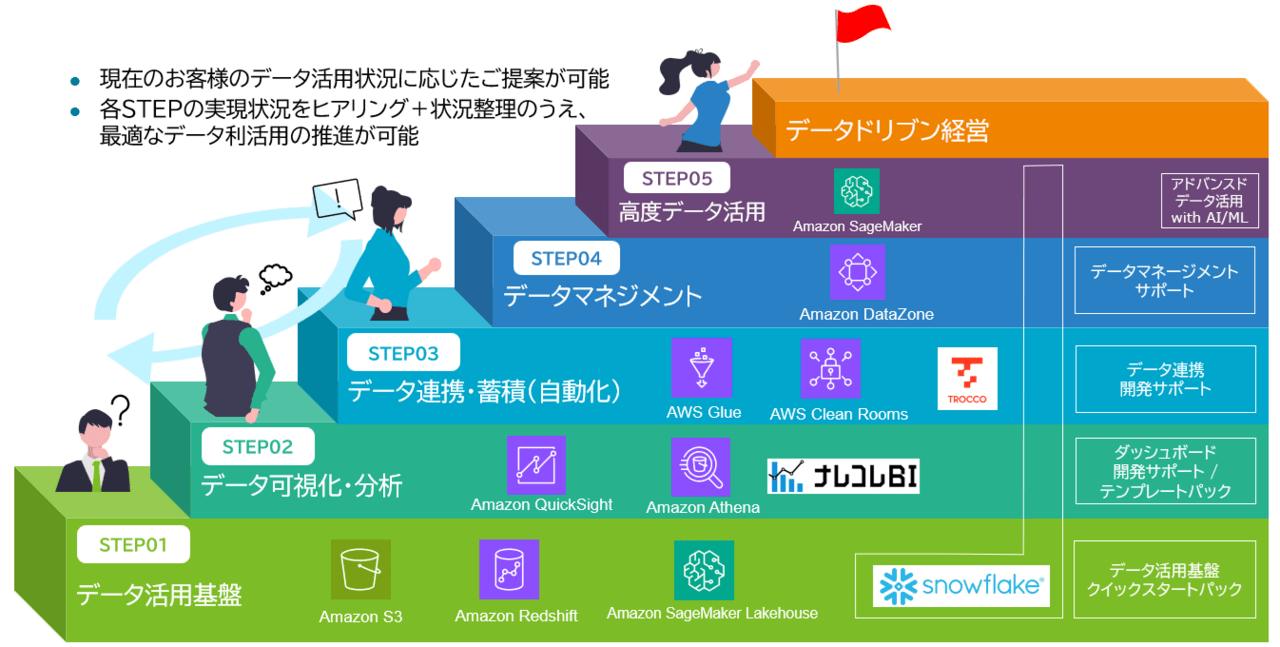
ご関心あれば、以下のサービスページもご参照ください。
