

こんにちは、SCSK坂木です。
Amazon FSx for Windows File Serverには、ストレージ効率を高めるデータ重複除去機能が搭載されています。 これは、ファイル内の重複セグメントを抽出して効率的に保存する機能です。削減率はデータの種類に依存しますが、一般的な共有サーバーではコスト削減の有効な手段となります。
今回は、FSxを構築した後の仕上げとして、重複排除の有効化からスケジュール設定、そして実際にジョブが動作することを確認するまでの流れをまとめました。
また、本記事はFSxが構築されていることを前提にしておりますので、構築はこちらの記事を参考にしてください。
FSxのマウント方法
設定を行う前に、作業用インスタンスからFSxに接続できることを確認します。
今回はコマンドプロンプトからネットワークドライブとしてマウントしました。ユーザはFSx構築時に指定したADの管理者ユーザです。
# Dドライブとしてマウント C:\Users\Administrator>net use D: \\10.0.2.148\D$ Enter the user name for '10.0.2.148': Administrator@test.local Enter the password for 10.0.2.148:<パスワード入力> The command completed successfully.
重複排除設定
FSxの管理操作は、リモートPowerShell経由で行います。
FSxへのリモート接続
#FSxのエンドポイントを指定(amznfsxXXXXXXXX.test.localは、FSxのマネジメントコンソールより参照) $FSxEndpoint = "amznfsxXXXXXXXX.test.local" # 資格情報の入力プロンプトが表示 $cred = Get-Credential # 資格情報を指定してFSxに接続 Enter-PSSession -ComputerName $FSxEndpoint -ConfigurationName FSxRemoteAdmin -Credential $cred
重複排除の有効化
接続後、以下のコマンドを実行して機能を有効化します。
#重複排除の有効化 [amznfsxXXXXXXXX.test.local]: PS>Enable-FSxDedup
Get-FSxDedupConfiguration を実行すると、現在の設定値を確認できます。主なパラメータの意味は以下の通りです。
- Enabled: 重複排除が有効かどうか(True)
- MinimumFileAgeDays: 重複排除の対象とする「作成後の経過日数」
- SavedSpace: 節約された容量
#設定状況の確認 [amznfsxXXXXXXXX.test.local]: PS>Get-FSxDedupConfiguration Enabled : True <--ここがTrueなら有効 MinimumFileAgeDays : 3 MinimumFileSize : 32768 SavedSpace : 0 Volume : D: ...
Enabled: True になっていることが確認できればOKです。
今回は検証のため、作成から時間が経っていないファイルも対象になるよう日数を変更しました。
# 対象となる日数を1日に変更 Set-FSxDedupConfiguration -MinimumFileAgeDays 1
スケジュールの変更
次にスケジュールを確認します。ここで表示されるTypeには3つの役割があります。
[amznfsxXXXXXXXX.test.local]: PS>Get-FSxDedupSchedule Enabled Type StartTime Days Name ------- ---- --------- ---- ---- True Optimization BackgroundOptimization True GarbageCollection 2:45 Saturday WeeklyGarbageCollection True Scrubbing 3:45 Saturday WeeklyScrubbing
各ジョブ(Type)の役割
- Optimization
実際に重複データを探してディスク容量を削減するメインの処理です。(バックグラウンドで動作します) - GarbageCollection
ファイル削除等で不要になった古いデータを整理し、空き容量として解放する役割です。 - Scrubbing
重複排除されたデータが壊れていないか整合性をチェックする役割です。
今回は、メンテナンスジョブが日曜日に実行されるよう以下の通り設定を変更しました。
# ガベージコレクション:日曜 02:00 Set-FSxDedupSchedule -Name "WeeklyGarbageCollection" -Type GarbageCollection -Start 02:00 -Days Sunday # スクラビング:日曜 22:00 Set-FSxDedupSchedule -Name "WeeklyScrubbing" -Type Scrubbing -Start 22:00 -Days Sunday
検証:動作確認
設定が正しく反映され、スケジュールに基づいてジョブが実行されるかを確認します。
動作確認の手順:
- testfileをFSxのフォルダに配置
- 同じファイルをFSx上に100個コピー
- ジョブが完了した後、ステータスを確認
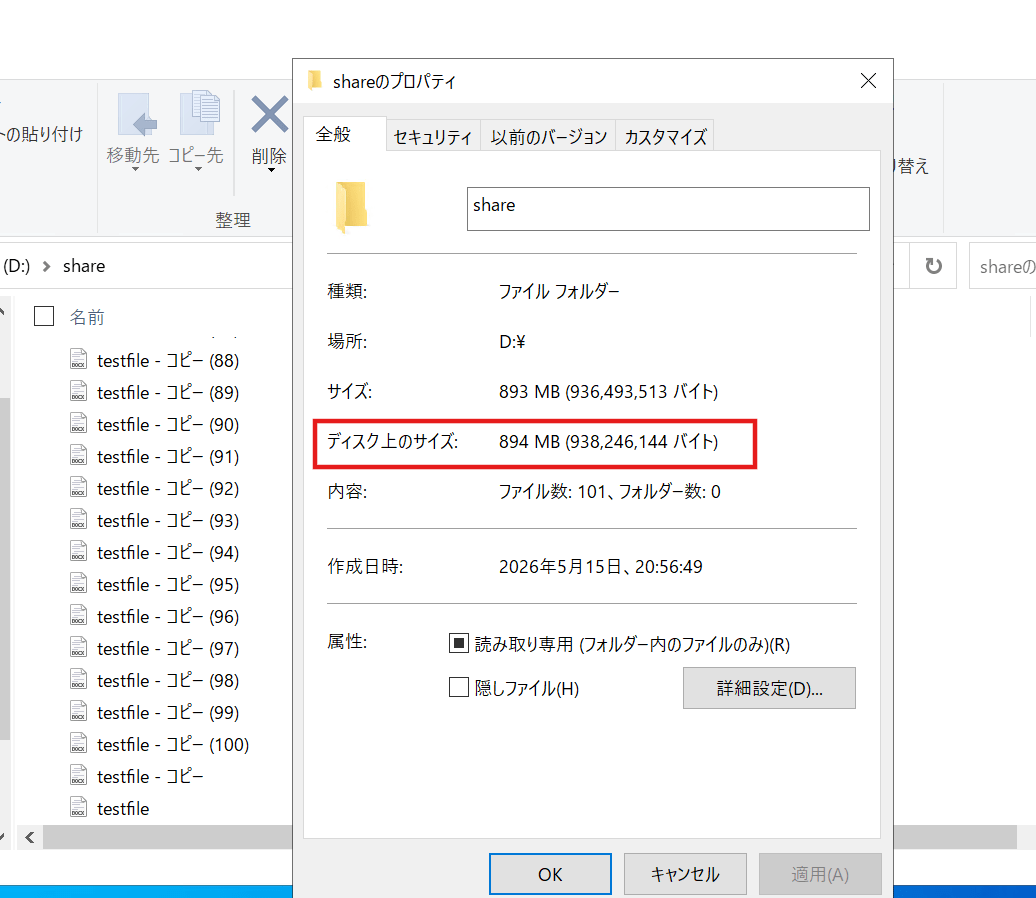
結果の確認
スケジュールで決めた時間が経過した後に、Get-FSxDedupStatus を実行し、ジョブの実行結果を確認します。
[amznfsxXXXXXXXX.test.local]: PS>Get-FSxDedupStatus InPolicyFilesCount : 101 OptimizedFilesCount : 101 LastOptimizationResultMessage : The operation completed successfully. SavedSpace : 918386116
コマンドの実行結果から、以下の 4つのポイント が確認できました。
-
ジョブの正常終了 (
LastOptimizationResultMessage)
The operation completed successfully.と表示されており、重複排除エンジンがエラーなく、最後まで正常に処理を完遂したことがわかります。 -
ポリシーの適用状況 (
InPolicyFilesCount)
今回テスト用に配置した101個のファイルが、設定した条件(経過日数など)に正しく合致し、スキャン対象として認識されています。 -
処理の網羅性 (
OptimizedFilesCount)
最適化されたファイル数が101となっており、対象となったすべてのファイルに対して漏れなく重複排除処理が実行されました。 -
削減された容量 (
SavedSpace)
今回の検証の最終成果です。918,386,116バイト(約875MB)のディスク容量が節約されました。 これは、重複していたデータが物理ディスク上から整理され、実際にFSxの空き容量として還元された数値を示しています。
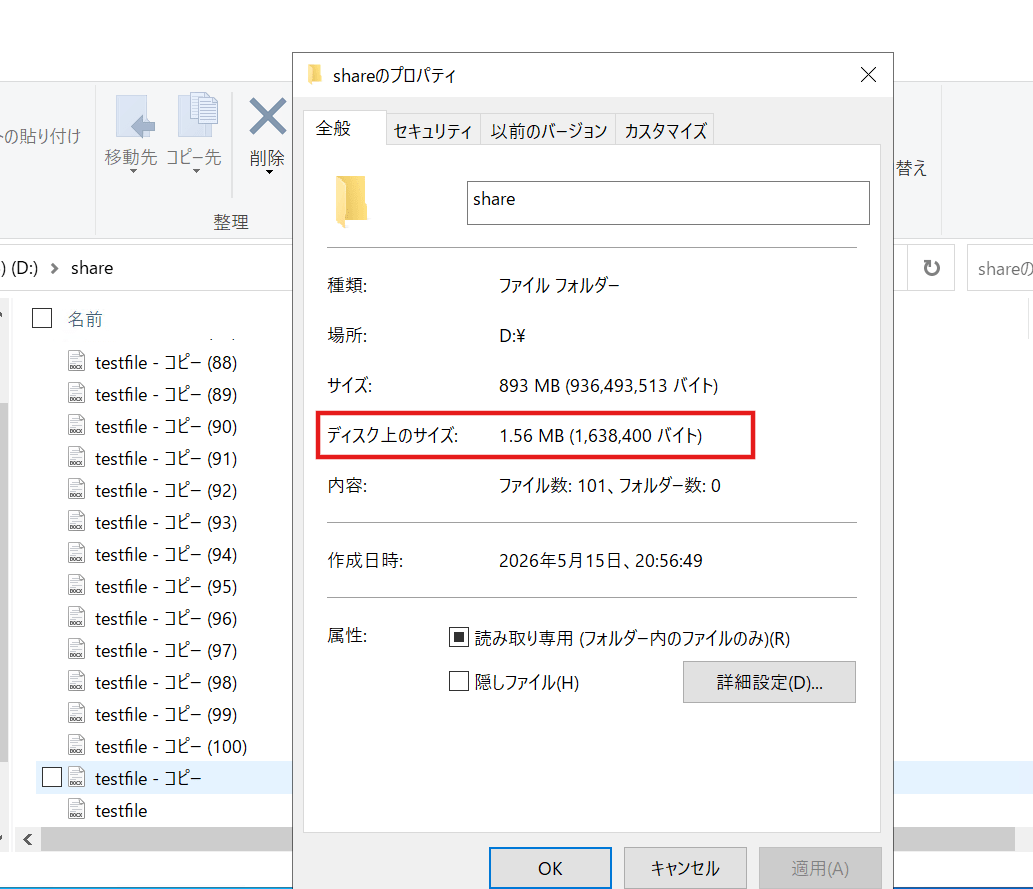
まとめ
本記事では、Amazon FSx for Windows File Serverにおけるデータ重複除去(重複排除)の設定手順について、ネットワークドライブのマウントから機能の有効化、運用に合わせたスケジュール設定、そして最終的な動作確認までの一連の流れを解説しました。
実際の運用でどの程度の削減効果が得られるかは扱うデータに依存しますが、AWS Pricing Calculator では以下のような指標が示されています。
- ユーザードキュメントの場合: 30~50% 削減
- 一般ファイルの場合: 50~60% 削減
- ソフトウェア開発共有の場合: 70~80% 削減
FSxのストレージコストを最適化し、限られたリソースを最大限に活用するために、ぜひ本記事を参考に重複排除機能を導入してみてください。
▼ AWSに関するおすすめ記事


