

こんにちは。SCSK石原です。
2022年5月に発表された「Informatica Data Loader for Google BigQuery」を利用して、Amazon S3からBigQueryにデータをロードする方法です。
リリース情報は下記の通り


Informatica Data Loader for Google BigQueryとは
Informatica製品を利用して、無料でBigQueryにデータを取り込むことができます。
データソースのコネクタが用意されており、フィルターなどを適用しながら必要なデータをターゲット(BigQuery)にロードすることができます。Informaticaにてクラウド上にエージェントを用意いただけるので、難しい設定をすることなく利用を始めることができます。
無料で利用できるということもあり、データをロードするという機能しかありませんが、機能がシンプルなので直感的に操作できるものと思います。
対応データソース
AWS/Azure/Google CloudのオブジェクトストレージやDB、その他DB、SalesforceやSAPなどのコネクタ提供がありました。
接続設定画面では、下記のコネクタが選択可能です。(2022年10月現在)
- Amazon Aurora
- Amazon S3 v2
- Box
- Cvent
- Google Analytics
- Google Big Query V2
- Google Cloud Spanner
- Google Cloud Storage V2
- Jira
- Marketo V3
- Microsoft CDM Folders V2
- Microsoft Dynamics 365 for Operations
- Microsoft Dynamics 365 for Sales
- MongoDB
- OData
- Oracle NetSuite
- PostgreSQL
- Salesforce Marketing Cloud
- Shopify
- Stripe
- SuccessFactors OData
- Zendesk V2
- Coupa
- Eloqua Bulk API
- Xactly
- ZuoraAQuA
- ServiceNow
- FTP/SFTP
- MS Access
- MySQL
- ODBC
- Oracle
- Salesforce
- SAP
- SQL Server
- Webサービス
- フラットファイル
データロード時の処理
ターゲットとなるBigQueryへデータをロードする前に、データソースの定義や必要なデータを抽出するためのフィルタリングができます。
Amazon S3をデータソースにした場合の設定箇所は5項目ありました。
データソースのフォーマット
CSVやParquet,Avro,Orc,Jsonなどが選択可能です。
CSVの場合だと、ヘッダー行をスキップすることや、区切り文字などの設定項目があります。
ソースフィールドの除外
ロードしなくてもいい列を省くことができます。
フィルタの定義
ロードしなくてもいい行を省くことができます。
フィルタは複数定義することができ、例えば日本在住の30歳以上という条件であれば「age >= 30」かつ「country = japan」のように定義できます。
プライマリキーの定義
プライマリキーを手動で定義することができます。
ウォーターマークフィールドの定義
こちらの用途について解説されているドキュメントを見つけることができませんでした。
恐らく、ストリーム系データの完全性を担保するための列を指定することができるものかと思います。
今回のデータソースはAmazon S3です。基本的にはバッチ系のデータが対象となりますので、こちらの機能は利用しませんでした。
利用開始方法(初回登録)
Informatica Data Loaderには、BigQueryからアクセスできます。こちらをクリックします。
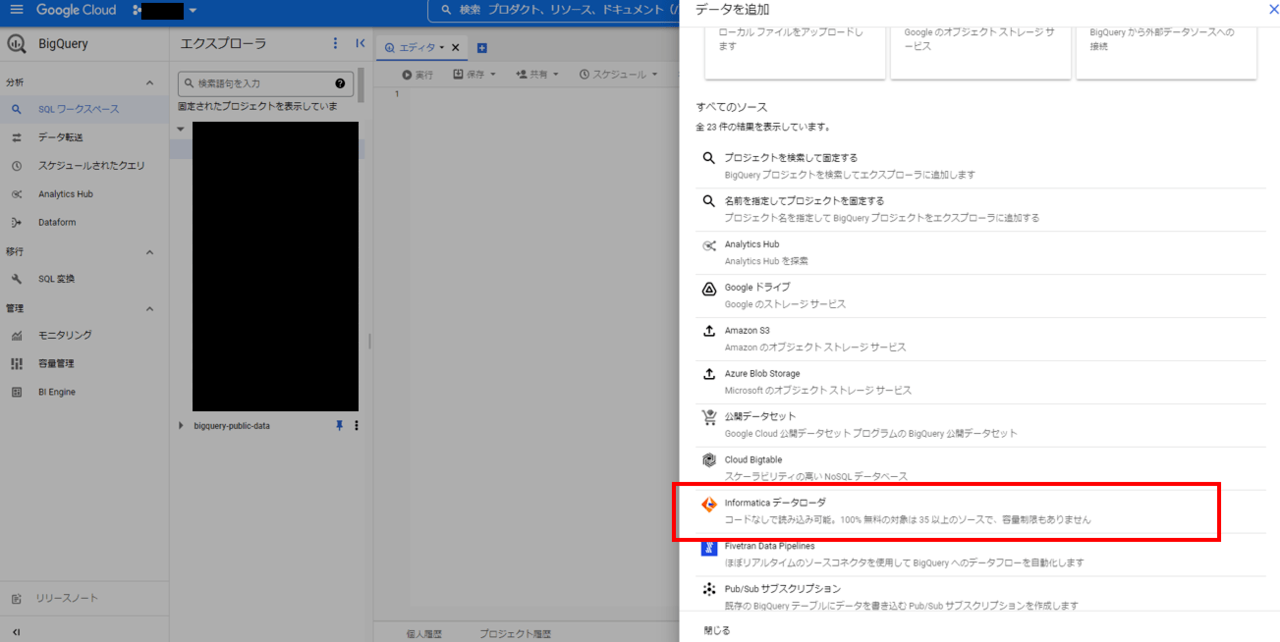
クリックすると、サインアップが求められますので指示に従ってユーザアカウントを作成します。
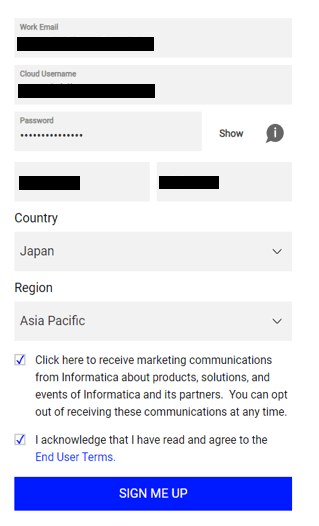
その後、メールにワンタイムパスワードが飛んできますので、そちらを入力すればユーザ登録の完了です。
正常にログインできた場合は下記の画面が表示されます。

ユーザ登録が完了したら、Informatica Data Loader for BigQueryを使う準備は完了です。
Amazon S3からBigQueryにデータをロード
データをロードするための設定を行います。次の順で設定します。
- データソースであるAWSの設定
- ターゲットであるGoogle Cloudの設定
- データロード用途のInformaticaの設定
なお、AWSやGoogle Cloudの権限設定は検証用途であったため、広めに設定しています。業務データを利用する場合は要件を確認して権限を絞ることをお勧めします。
AWSの設定
データソースとAWS認証情報の設定をします。
Amazon S3バケットの作成&データ配置
今回は検証用途のため、新規でバケットを作成します。下記のテンプレートを利用して作成しました。
データはKaggleのものを利用させていただきました。
House Prices – Advanced Regression Techniques | Kaggle
IAMユーザ作成
S3からInformaticaにデータを吸い出すための認証情報を作成します。
コンソールアクセス無し、アクセスキー有で「AmazonS3FullAccess」のポリシーを持つユーザを作成します。
アクセスキーはInformatica Data Loaderの設定で利用しますので、安全な場所に保存してください。

Google Cloudの設定
ターゲットとGoogle Cloud認証情報の設定をします。
BigQueryデータセットの作成
データをロードする宛先となるBigQueryのデータセットを作成します。利用可能なデータセットがすでにある場合は、そちらを利用いただいて構いません。
データセットの作成 | BigQuery | Google Cloud
サービスアカウントの作成
InformaticaからBigQueryへデータをロードするための認証情報を作成します。下記のロールを付与したサービスアカウントを作成しました。
- BigQuery管理者
- Storageオブジェクト管理者
![]()
このサービスアカウントもInformaticaで利用しますので、Json形式で鍵ファイルをダウンロードして安全な場所に保管しておいてください。
※前述で記載していますが、検証用途のため広めに権限を設定しています。
Informatica Data Loaderの設定
接続定義をしたのち、BigQueryへデータをロードするジョブを作成します。
接続定義
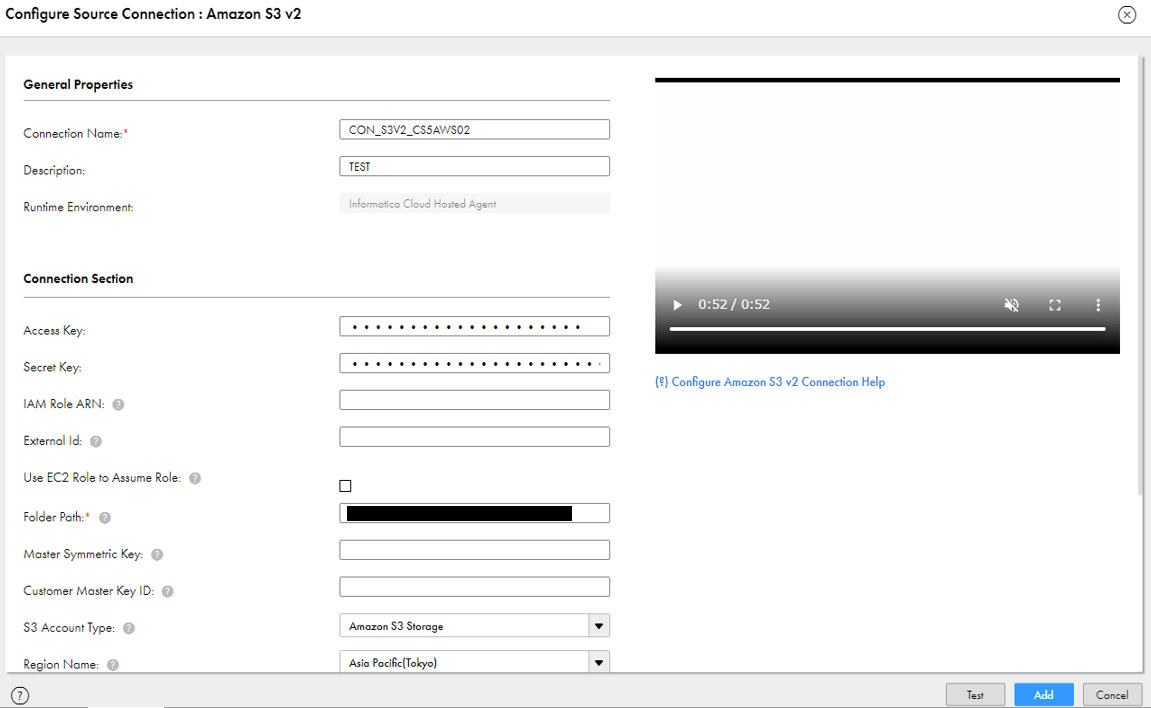
データソースとなる接続情報を定義します。
Informatica Cloudにログインしたのち、「管理者」>「接続」の順でクリックして、「新しい接続」をクリックします。事前に取得したAWSの認証情報やバケットの情報を入力してテスト接続が出来ることを確認します。
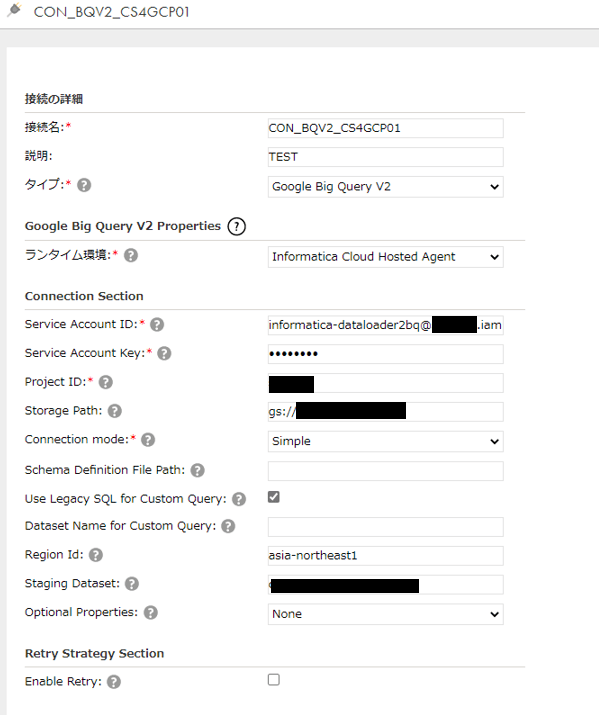
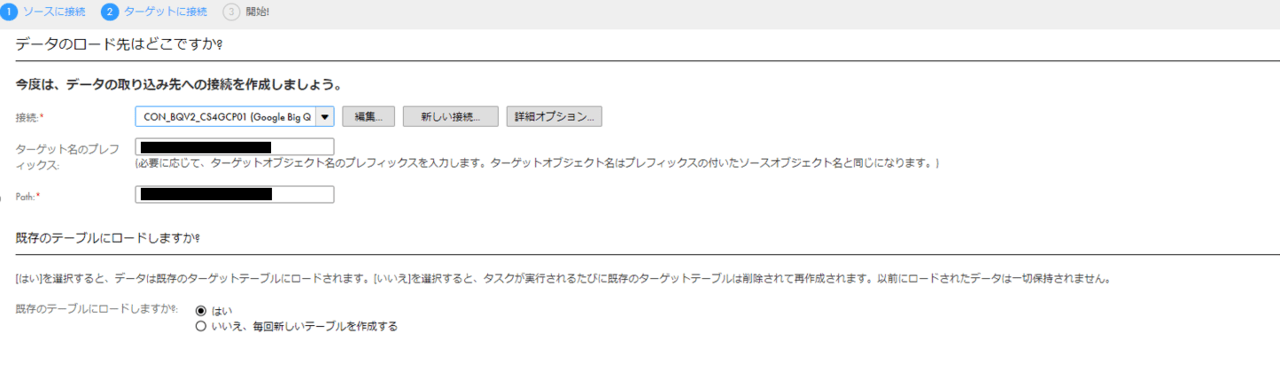
ターゲットとなるBigQueryの接続定義も同様に行います。
ジョブ作成
「データ統合」>「新規」の順でクリックしてジョブの作成を始めます。
データソースはS3用に作成した「接続」を利用します。
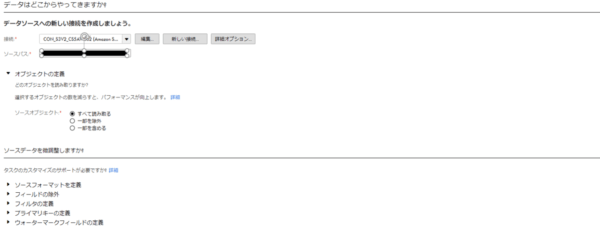
フィルタやフィールド除外などを利用して、不要なデータの連携をしないことも可能です。
次にターゲットの設定をします。こちらはBigQueryしか選べませんので、先ほど作成したBigQuery用の接続を利用します。
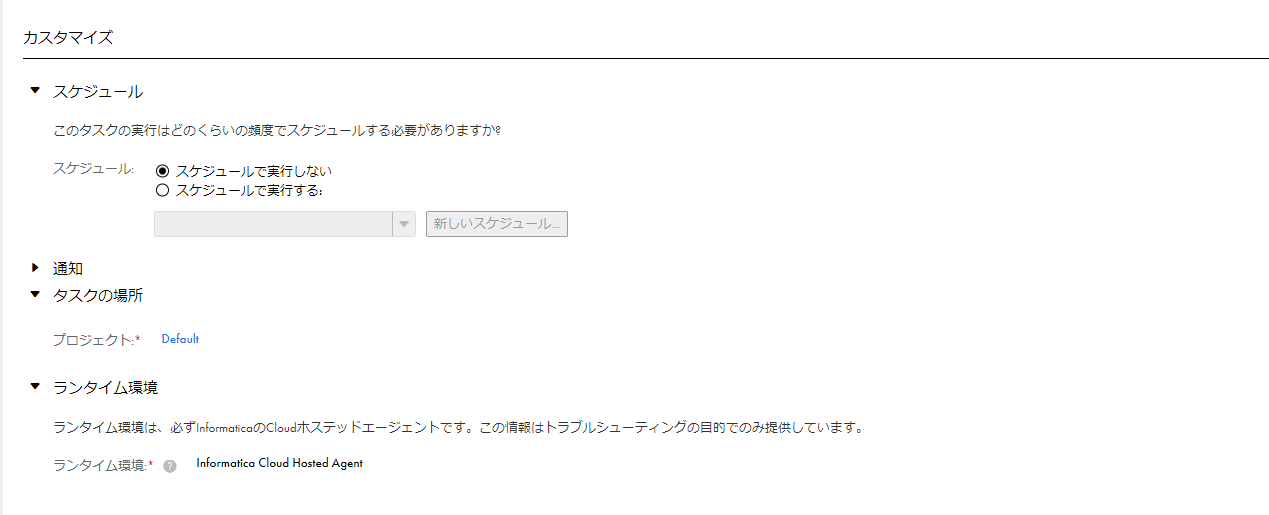
最後にタスクの名称を決め、実行時の挙動やスケジュールを定義します。定期的な実行やメール通知などの設定が可能です。今回は一度で全量読み込みますので、こちらの設定はスキップします。
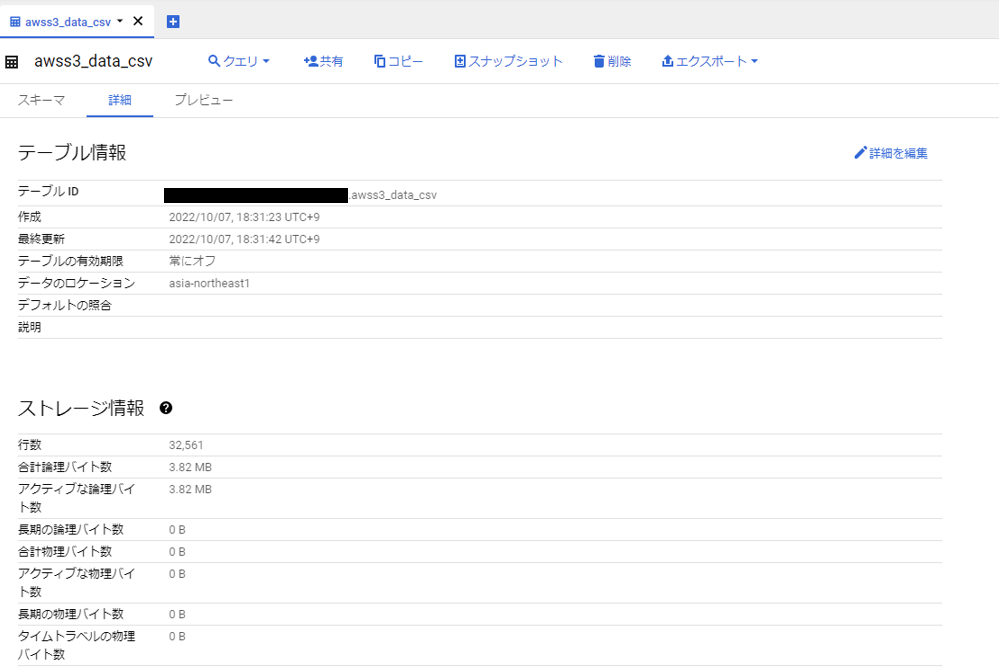
実行結果
ファイルサイズが小さいので、処理はすぐ完了しました。

BigQueryを確認して、表示されている件数が読み込まれていることが確認できました。
終わりに
直観的に操作できて、簡単でした。
今回試したAmazon S3→BigQueryへデータのロード方法は様々あります。一例は下記の通りです。
| BigQuery Omni | Amazon S3 からのクラウド間転送 | BigQuery | Google Cloud |
| BigQuery Data Transfer | Amazon S3 転送の概要 | BigQuery | Google Cloud |
| S3からGCSにデータをコピーしてBigQueryにロード | Amazon S3からGoogle Cloud Storageにアクセスキーを使わずデータコピーする – TechHarmony (usize-tech.com) |
ハイパースケーラーの機能を利用して実装を考えることも、3rdParty製品を利用して実装するパターンどちらも手札として知っておくとイイかなと思いました。
使い勝手がよくて、中規模・大規模に活用と思いましたら、ぜひInformatica製品をご検討ください。そういう入り口なのかなと個人的に思いました。