
SCSKの畑です。7回目の投稿です。
今回は小ネタ・・のつもりだったのですがいくつか加筆していたらそれなりの分量になってしまいました。内容は正直タイトルから大体想像付くところだとは思うのですが、ご了承ください。
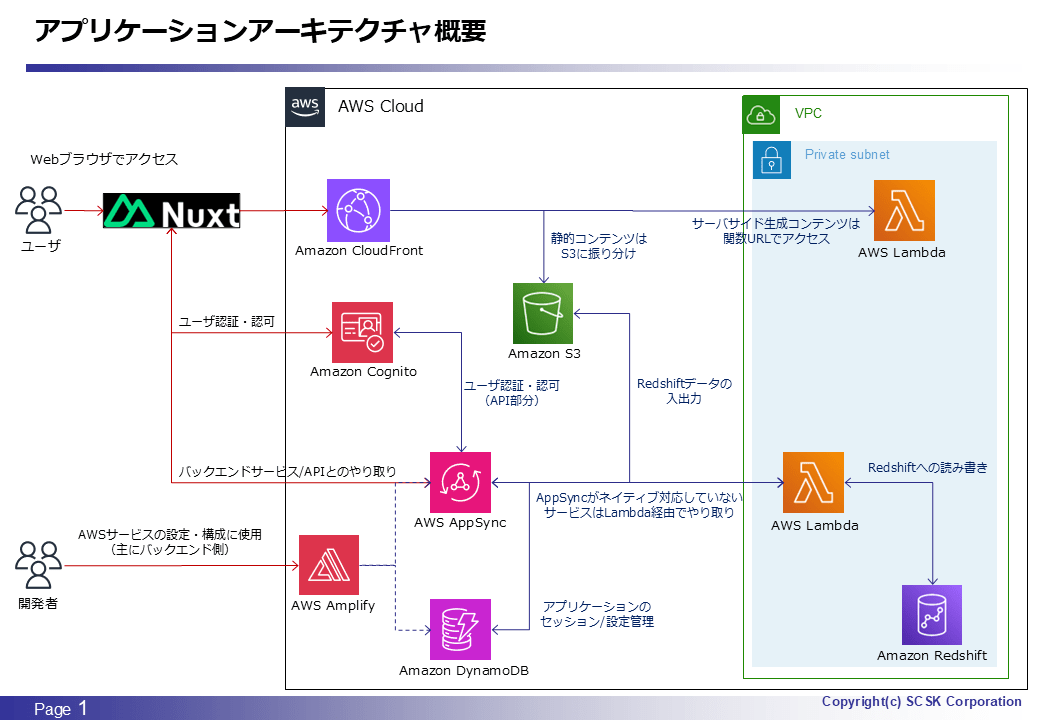
アーキテクチャ概要
今回はタイトル通り AWS AppSync と AWS Lambda がメインですが、少しだけ Amazon Redshift も話に出てきます。
背景
ほぼ毎回説明しているかもしれませんが、本アプリケーションの主目的(機能)はデータベース/DWH のテーブルデータメンテナンスです。本アーキテクチャ構成上、アプリケーションと Redshift の間でテーブルデータの読み書きをする場合は AppSync 及び Lambda を介するため、対象テーブルのデータサイズ次第で AppSync もしくは Lambda のペイロードサイズに制約を受ける可能性があります。
AppSync は、レスポンス/レスポンス共に最大ペイロードサイズが 5MB です。

Lambda は、同期呼び出しにおける最大ペイロードサイズはリクエスト/レスポンス共に 6MB です。

よって、今回のアーキテクチャにおいて、AppSync API 実行時の入出力データサイズはいずれも 5MB 未満に抑える必要があります。
なお、ダイレクト Lambda リゾルバを使用した場合は、最大ペイロードサイズが Lambda の値に準拠するようです。(=最大 6MB)ただ、Amplify で @function ディレクティブを使用して Lambda を query なり mutation に紐付けた場合は、マッピングテンプレートを使用する通常の Lambda リゾルバになるようです。gen2 であればオプション等で対応していたりするんでしょうか・・?
今回はダイレクト Lambda リゾルバの使用が必須となるような要件はなかったため、使用していません。

もちろん、アーキテクチャ設計時にはこの点は考慮に入れており、以下2点より当面は特に対策しなくても大丈夫だろうと考えていました。
- 本アプリケーションにおけるメンテナンス対象はいわゆる「マスタテーブル」であるため、データサイズが小さい
- 「トランザクションテーブル」のようなデータサイズの多いテーブルではない
- 現時点で一番データ量の大きいテーブルのデータサイズが CSV ファイル形式で約 800KB である
- かつ、今後データサイズが爆発的に増大する可能性が少ない
ところが、開発中に同テーブルに対するリクエスト/レスポンスのデータサイズを計測してみたところ、3MB 程度になってしまっていることが判明しました。上記の通りまだ最大サイズ内ではあるものの、既に半分を超えてしまっていることになるため、慌てて原因を調べることになりました。
データサイズ差異の原因
何故このようなデータサイズの差異が生じてしまったのかですが、原因は AppSync 及び Lambda の入出力におけるテーブルデータのフォーマットにありました。当初、AppSync のスキーマにおけるテーブルデータは、以下のように文字列の配列として定義しており、この形式でAppSync/Lambda で入出力を行っていました。
table_data: [String]!
具体的には、以下のような JSON Lines 形式のデータを行単位でリストに格納していました。
{"id":"001","value":"sample_data_1","create_day":"2025-01-01 00:00:00","update_day":null,"creater_name":"admin","updater_name":"","delete_flg":"N"}
{"id":"002","value":"sample_data_2","create_day":"2025-01-02 00:00:00","update_day":null,"creater_name":"admin","updater_name":"","delete_flg":"N"}
{"id":"003","value":"sample_data_3","create_day":"2025-01-03 00:00:00","update_day":null,"creater_name":"admin","updater_name":"","delete_flg":"N"}
以下理由よりトータルで一番楽に実装できると判断したため、このようなフォーマットでデータを保持していた訳ですが・・
- Redshift ⇔ Lambda 間のデータ読み書きに COPY / UNLOAD 文を使用しており、そのSQL文からそのまま使用できるフォーマットであるため
- COPY / UNLOAD 文でサポートされているフォーマットは JSON 含めて複数存在するが、JSON にしておけば後述するようにアプリケーションからも容易に使用できる
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/copy-parameters-data-format.html#copy-json
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_UNLOAD.html
- COPY / UNLOAD 文でサポートされているフォーマットは JSON 含めて複数存在するが、JSON にしておけば後述するようにアプリケーションからも容易に使用できる
- アプリケーション側で使用しているテーブル表示用のライブラリにおいて、テーブルのデータを JSON 形式で保持する必要がある
- JSON Lines形式から変換する必要はあるものの、最小限の対応で済む
さて、もう既にお分かりかと思いますが、ここまで黄色アンダーラインでマークした通り、テーブルデータのフォーマットを JSON Lines 形式で持つようにしたことがデータ量増大の原因となっていました。テーブルデータを同形式で持つということは、当然ながら実データだけでなく JSON フォーマットで付加される情報(列名、中括弧、ダブルクォートなど)のデータも各行ごとに含まれます。つまり、テーブルのデータ量が大きいほど、JSON フォーマットで付加される情報が占めるデータサイズも相対的に大きくなってしまうことになります。
そこで、改めて対象テーブルにおける実データ以外のデータサイズを改めて計算したところ、
- 行数:約 10000 行
- 1行あたりの JSON フォーマット分のデータサイズ:約 220Byte
- 計算結果:210 B * 10000 ≒ 2.2MB
ということで、当然ですがデータサイズの差異分とほぼ一致する結果となり、裏付けが取れてしまった格好になりました。。というか、実データの約 2.5 倍のサイズとなってしまっているんですよね。どう考えてもサイズ効率は劣悪ですし、他のメンテナンス対象テーブルについても同様の傾向にあることが見て取れましたので、根本的な対策を行うこととしました。
解決策
一方で、JSON (Lines) 形式そのものは実装面から変えたくなかったのでちょっと悩んだのですが、今回のように「とりあえずサイズを小さくできればよい」ケースで最も良く使用される手法を用いてあっさり解決しました。そう、圧縮です。
ということで、まずスキーマ定義を文字列の配列から文字列に変更しました。
table_data: String!
後は、Lambda と テーブルデータをやり取りする時に、JSON 形式のデータをダンプしてから圧縮/展開してしまえば OK です。以下、Lambda側 で圧縮したテーブルデータを Typescript 側で展開する場合の実装例を示します。
Lambda
JSON 形式のテーブルデータを Lambda 側で圧縮する例です。
table_data_json_base64 = base64.b64encode(gzip.compress(json.dumps(table_data_json).encode('utf-8'))).decode('utf-8')
圧縮する以上、lambda コード内でテーブルデータを JSON Lines 形式で扱う必要性がなくなったため、通常の JSON 配列として扱っています。table_data_json が対象の変数です。
Typescript
Lambda / AppSync から受け取った圧縮されたテーブルデータを展開して、JSON 配列に変換する例です。
const table_datas = JSON.parse(pako.ungzip(Base64.toUint8Array(table_data_json_base64), { to: 'string' }))
table_data_json_base64 変数に圧縮データが格納されている想定です。また、下記サイト様の情報より、gzip/ungzip 用のモジュールとして pako を使用しています。

これらの対応により、対象テーブルデータのサイズを約 160KB に低減することができました。最大サイズ 5MB と比較しても十分に小さいため、この方式を採用して解決と相成りました。JSON 形式のデータフォーマットである以上はある程度圧縮が効くものと見込んでいましたが、データそのものの特性もあり想定以上の圧縮率となりました。
まとめ
言い訳がましいのですが、CSV 形式より JSON 形式の方がトータルでデータサイズが増大すること自体は認識していました。ただ、実データに基づく試算などの定量的な裏取りはしておらず、何となく大丈夫だろう程度の感覚で実装を優先してしまっていたのが今回の根本原因であり、反省点です。。。特に今回は事前に試算することも容易なデータサイズ/データフォーマットであったため、尚更ですね。
なお、本記事を書き終わった後に初めて知ったのですが、実は AppSync 側で API レスポンスの圧縮を行う機能もあることに気づきました。本アプリケーションの実装は変更しない予定ですが、別の機会で試してみても良いかもしれないですね。

ただ、実アプリケーションで採用する場合、以下一文が気になるところではありますが・・
AWS AppSync はベストエフォートベースでオブジェクトを圧縮します。まれに、AWS AppSync が現在の容量を含むさまざまな要因に基づいて、圧縮をスキップすることがあります。
本記事がどなたかの役に立てば幸いです。