

SCSKの畑です。期せずして昨年と同じく年明けからの投稿となりますがよろしくお願いします。
まずは昨年度の投稿で主に言及していた Redshift データメンテナンス用の Web アプリケーションについて、今年度も引き続き携わっている中で主に実施していた取り組みについて数回に渡って記載していきたいと思います。
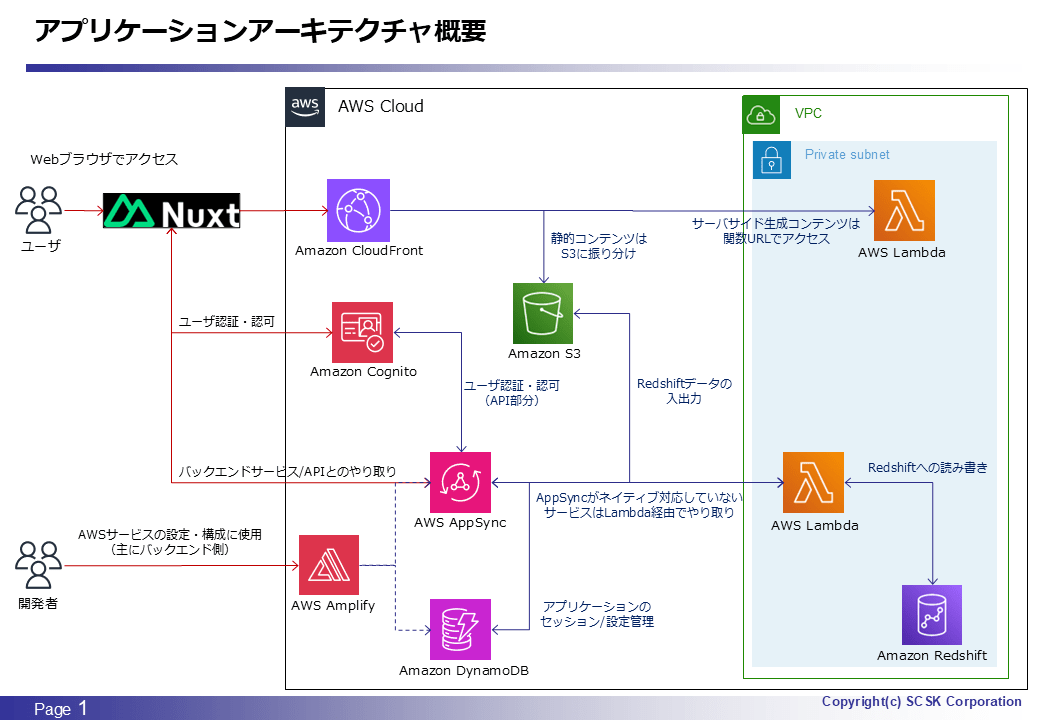
アーキテクチャ概要
一年ぶりの投稿となるので載せておきます。今回はアーキテクチャの変更や改修を伴う内容ではないのですが、AppSync や Lambda が関連する話題となります。要するにバックエンド API の部分ですね。
背景
昨年度本アプリケーションをリリースしてお客さんに使い始めてもらったのですが、細かい不具合などはありつつも有難いことに全体的には好評頂き、それに伴いアプリケーションの機能拡張や他アプリケーションでカバーしている機能も移管・集約することで、より本アプリケーションを活用していきたいという主旨のご要望を頂いていました。もちろんその方向性自体は大変ありがたい話で、今年度はそれらの要望への対応を中心に取り組んでいました。
一方で、アプリケーションの機能拡張や他機能の移管・集約に伴い、本アプリケーション実装時点での要件からの変更も当然起こり得ます。その中で今回特にネックとなったのが本アプリケーションで扱うデータサイズの長大化です。
元々、過去の投稿で言及している通り、本アプリケーションでは主にマスタテーブルのデータ参照や更新をターゲットにしていました。もちろん同じマスタテーブルでもサイズの大小はありますが、こちらも以下のエントリで言及している通りちょっとした工夫もしつつ最終的にこのアーキテクチャで十分に捌けると判断しました。

ところが、今回の機能拡張に伴いより大きなデータサイズを持つテーブルを本アプリケーションで扱う必要が出てきてしまいました。具体的には以下のような内容です。
- 履歴管理テーブル
- 特定マスタ(機種情報など)の履歴や、ETL/ELT 処理失敗時のエラー履歴を蓄積。
- 後者は最終的に ETL/ELT 処理時のデータ変換マスタとしても活用。
- 今年度における ETL/ELT 処理改善取り組みの一環として実装。
- 特定マスタ(機種情報など)の履歴や、ETL/ELT 処理失敗時のエラー履歴を蓄積。
- ダッシュボード/レポート表示結果検算用テーブル
- 最終的なダッシュボード/レポートの表示結果が正しいかどうかをエンドユーザ側でチェックするための補足情報。
- 元々は BI ツール上で暫定的に表示していたが、合わせてマスタの確認・修正が必要になることが多いため機能移管したいという要望より実装。
もちろん、トランザクションテーブルやマートテーブルなどより巨大なデータを持つテーブルと比較すると十分現実的なラインではあるのですが、本アプリケーションのアーキテクチャやアプリケーションの作りを踏まえて考えるとやはり厳しい部分が出てきてしまいます。それが、先述した過去の投稿でも言及している AppSync のレスポンスタイム及びペイロードサイズに関する以下の制約です。
- ペイロードサイズ:5MB
- レスポンスタイム:30秒
言わずもがな、扱うデータサイズが増大することによりどちらの制約にも抵触する可能性が高まりますが、実際に上記種類のテーブルを本アプリケーションから扱えるか試してみたところ見事に引っ掛かってしまったため、いよいよ腰を据えての対策が必要となりました。
対策として実施したアプリケーションの設計・実装変更
大きく以下2点の変更を実施することで、AppSync の制約を回避することができました。なお、これらの変更を具体的にどう実装に落とし込んだかについては次回以降でかいつまんで説明していこうと思います。
「密結合かつ同期処理」から「疎結合かつ非同期処理」への変更
さて、対策が必要と書いたのですが厳密にはちょっと語弊がありまして、本アプリケーションのバックエンド API が AppSync の上記制約に引っ掛かるような作りをしているために対策が必要になった、というのが正確な表現となります。例えば、以前の投稿で取り上げたテーブルの更新差分を導出する処理では、AppSync のデータソースとして Lambda を使用の上、以下のような実装としていました。

- アプリケーションから更新差分取得用の AppSync API を実行
- AppSync のデータソースである Lambda 内で更新差分を計算し、計算結果を AppSync に返す
- AppSync API の返り値として差分計算結果を取得
これだけ見ると特に違和感ないというか普通の処理の流れだと思うのですが、その一方で対象テーブルのデータサイズや更新量が増大した場合は、2.の処理により時間を要したり、3.でアプリケーションに返す差分計算結果のサイズが大きくなることで、結果的に AppSync の上記制約に抵触してしまいます。つまり、この更新差分導出の実装が密結合かつ同期処理前提になっていたことが、今回対策が必要となってしまった要因でした。よって、この処理を AppSync の上記制約をなるべく受けないようにするには
- 差分計算処理と差分取得処理をそれぞれ別の AppSync API(Lambda)として実装する
- 本アプリケーションにおいて差分取得処理は最終的に AppSync API(Lambda)を使用する必要性がなくなったため削除(理由は後述)
- 差分計算処理は非同期処理で実行することを前提とする
- この変更により AppSync のレスポンスタイム制約を回避可能
- 非同期処理となる以上、AppSync API の返り値として差分計算結果は取得できないため、DynamoDB や S3 上などアプリケーションからアクセスできる別の領域に結果を出力
- 差分計算処理の完了待機や、処理完了後の差分取得処理はアプリケーションのロジックとして実装
のように、疎結合かつ非同期処理前提に変更する必要がありました。他のバックエンド API も概ね似たような実装となっていたため、結果的にバックエンド API におけるテーブル関連の各処理(Redshift からテーブルデータを取得/Redshift へ更新/更新差分計算など)は一律で上記のような変更が必要となり、最終的に結構な工数を要してしまうことになりました。。。
特に、テーブルデータを取得する処理についてはアプリケーションにおけるテーブルの状態遷移管理との兼ね合いもありロジックが複雑で、「アプリケーションから読取/書込するテーブルデータの更新処理(アプリケーション上のバージョン管理含む)」と、「アプリケーション上で表示するためのテーブルデータの取得処理」を分割すること自体が大変でした。複雑なあまり実装時点で疎結合で実装することも考えていただけに、そのまま踏み切っていれば今回の一連の対応に要する工数がもう少し低減できたかもしれません。
S3 上にアプリケーション上で扱うデータを保持し、S3 署名付き URL を通して読み書きする方式に変更
上記対応により AppSync のレスポンスタイム制約は回避することができましたが、ペイロードの制約については回避できません。先程の更新差分の導出処理に例えると、計算処理を非同期化しても計算結果を取得する処理は同期処理でないと意味を成さない(=AppSync API の返り値として計算結果を取得できる必要がある)からです。つまりここに AppSync や Lambda を介するような作りにしてしまうと、その時点でペイロードの制約がついて回ることになります。
この対策としてはシンプルで、S3 上にアプリケーション上で扱う諸情報(例えばテーブルデータや更新差分情報など)を保持・永続化するようにした上で、アプリケーションからは S3 署名付き URL を介して読み書きするような方式に変更することで解決しました。AppSync や Lambda などのペイロードの制約を回避する方法としてはメジャーなものの一つかと思います。
実装上も Nuxt(Vue)の場合は fetch を使って S3 署名付き URL を叩けば良かったので変更難易度は総じて低かったです。S3 上で保持していなかったデータの配置場所の設計や、S3 署名付き URL 自体をフロントエンド/バックエンドどちら側で生成するのか、フロントエンド側の場合は対象の S3 URL をどのように導出するのかなどの細かな課題はありましたが、いずれも特に問題なく解決することができました。
まとめ・所感
本件について一応補足すると、実質的にアプリケーションの要件が昨年度のリリース時点から変更されたのが大元の原因であるため、そもそもの実装が極端に間違っていたとは考えていません。疎結合・同期処理前提とすることで、アプリケーション側のロジックが相対的にシンプルになるというメリットもありますし、昨年度のアプリケーション開発においては工数・期間の問題との兼ね合いもありました。
また、StepFunctions のステートマシンで作成している ETL ジョブを本アプリケーションから実行する機能も昨年度時点でリリースしていましたが、こちらについてはその性質上非同期処理として最初から実装していました。よって(相当に言い訳がましいですが)非同期処理として実装するという選択肢自体も昨年度の開発時から持てていたかなとは思います。
一方で、AppSync/Lambda のペイロードやレスポンスタイムへの制約の懸念が開発時点であったことも確かで、今回のようにその懸念が再燃した場合を考慮して事前に以下のような手を打てなかったのか、という点は大いに反省すべきところと感じました。
- バックエンドAPIの機能単位としては疎結合ベースで実装すべきだった
- 疎結合で実装した機能単位の一部を非同期化すること自体は、AppSync の機能(subscription)も相まってそこまで難しくないため
- S3 署名付き URL を介したデータのやり取りについては最初から実装すべきだった
- 先述の通り大して難しくなかった上、ペイロード制約を回避するメジャーな方法であったため(事前調査不足)
そのあたりの設計・実装の勘所についてはまだまだ未熟であると今回の対応を通して痛感したところで、今後も引き続き精進していければと感じました。本記事がどなたかの役に立てば幸いです。