

こんにちは、広野です。
本記事は、以前公開した記事の続編です。つくった RAG の概要は以下の記事をご覧下さい。

本記事では、Agents for Amazon Bedrock から Amazon Bedrock の Anthropic Claude Foundation Model に問い合わせる構成をメインに紹介します。
アーキテクチャ
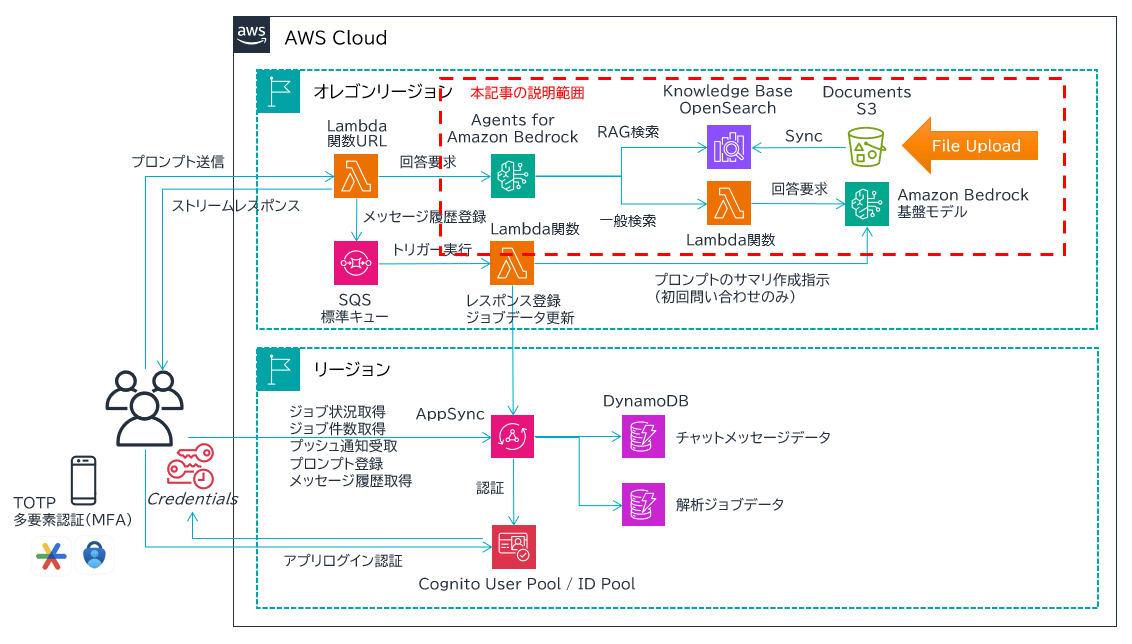
- RAG 用の Knowledge Base (ベクトルデータ) には、Agents for Amazon Bedrock が自動作成してくれる Amazon OpenSearch Service Serverless を使用しています。別途 Amazon S3 バケットを作成し、そこに当社公式ホームページの情報を PDF 化したファイルを格納し、OpenSearch に Sync させます。
- 一般的な回答をするために使用する生成系 AI の基盤モデルには、Amazon Bedrock の Anthropic Claude 2.1 を使用しています。
- ユーザからの問い合わせ内容が当社 (SCSK 株式会社) に関連するものであれば Agents for Amazon Bedrock が自動的に OpenSearch 内の情報を取得します。それ以外の内容であれば AWS Lambda 関数経由で Claude 2.1 モデルに問い合わせます。
この分岐を司る部分を中心に設定情報など紹介していきます。
つくったもの
RAG 検索用 Knowledge Base
Agents for Amazon Bedrock により RAG 用の Knowledge Base を作成する方法については、以下の記事を参考にしました。

一般検索用 AWS Lambda 関数
以下の関数コードを書きました。
Amazon Bedrock の Claude モデルに問い合わせるコードは既に世の中に溢れているコードサンプルと同じです。ただし、今回の構成ではこの AWS Lambda 関数の呼び出し元が Agents for Amazon Bedrock なので、その仕様に基づき event[‘inputText’] をプロンプトに入れています。
また、Agents for Amazon Bedrock に戻すレスポンスも所定のフォーマットにしないといけないので、その仕様に合わせています。
import boto3
import json
bedrock = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
enclosed_prompt = "\n\nHuman: " + "以下の質問文に対して適切な回答をしてください。\n" + event['inputText'] + "\n\nAssistant:";
body = {
"prompt": enclosed_prompt,
"max_tokens_to_sample": 3000,
"temperature": 0.5,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["\n\nHuman:"],
"anthropic_version": "bedrock-2023-05-31"
};
res = bedrock.invoke_model(
body=json.dumps(body),
contentType='application/json',
accept='application/json',
modelId='anthropic.claude-v2:1'
)
responsebody = json.loads(res['body'].read()).get('completion', '適切な回答が見つかりませんでした。')
return {
"messageVersion": "1.0",
"response": {
"actionGroup": event["actionGroup"],
"apiPath": event["apiPath"],
"httpMethod": event["httpMethod"],
"httpStatusCode": 200,
"responseBody": {
"application/json": {
"body": responsebody
}
}
},
"sessionAttributes": event["sessionAttributes"],
"promptSessionAttributes": event["promptSessionAttributes"]
}
Agents for Amazon Bedrock の設定
RAG 検索用 Knowledge Base および 一般検索用 AWS Lambda 関数が完成したら、それらをオーケストレートする Agents for Amazon Bedrock の設定をします。順に AWS マネジメントコンソールの画面スクリーンショットを追って説明します。
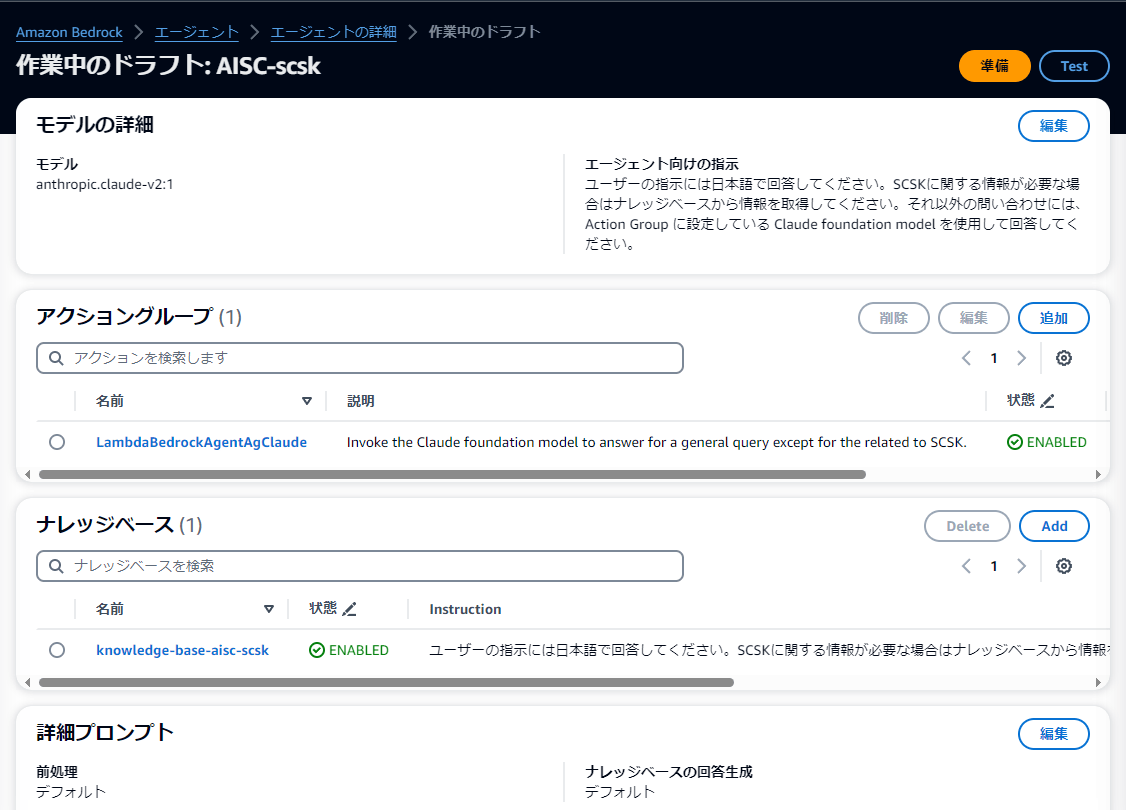
アクショングループには、一般検索用 AWS Lambda 関数を登録します。複数登録可能なので、決まった用途ごとに作成した Lambda 関数があれば登録し、それぞれに適切な説明を記入します。その説明内容をもとに、Agents for Amazon Bedrock が使用するアクショングループを選択することになるので説明は重要です。今回のケースでは、SCSK に関する問い合わせ以外には Claude に問い合わせるということを記載しています。たまたま英語で書きましたが、日本語でも大丈夫と思います。
ナレッジベースには、RAG 検索用ナレッジベースを登録します。複数登録可能です。こちらも同様に、用途ごとに説明を書きます。今回のケースでは、SCSK に関する情報が必要な場合はナレッジベースからデータを取得するよう指示しています。
モデルの詳細欄では、Agents for Amazon Bedrock 全体に指示する内容を書きます。1つは言語モデルで、執筆時点では Claude しか選択できませんでしたのでそれを選択しています。最重要なのはエージェントへの指示で、ここで RAG 検索と一般検索の使い分けルールを自然言語で記述します。プログラマティックな記法ではありません。今回のケースでは、日本語で回答することと、SCSK に関する情報はナレッジベースから、それ以外はアクショングループから情報を取得するよう指示しています。分岐の設定はこれだけで OK です。
アクショングループ設定時の注意点
アクショングループを設定するときには、以下 2 つの注意点があります。
- AWS Lambda 関数を実行するための権限
- OpenAPI の設定
AWS Lambda 関数を実行するための権限
Agents for Amazon Bedrock から AWS Lambda 関数を呼び出すには、一般的な Lambda 関数実行時と同様、呼び出し側に呼び出す権限を与える必要があります。なじみのない方もいらっしゃるかもしれませんが、Lambda 関数にリソースベースのポリシーを設定します。
AWS 公式ドキュメントのまま設定すれば OK です。

OpenAPI の設定
アクショングループを登録するときに、1 アクショングループにつき 1 つの OpenAPI スキーマを登録する必要があります。
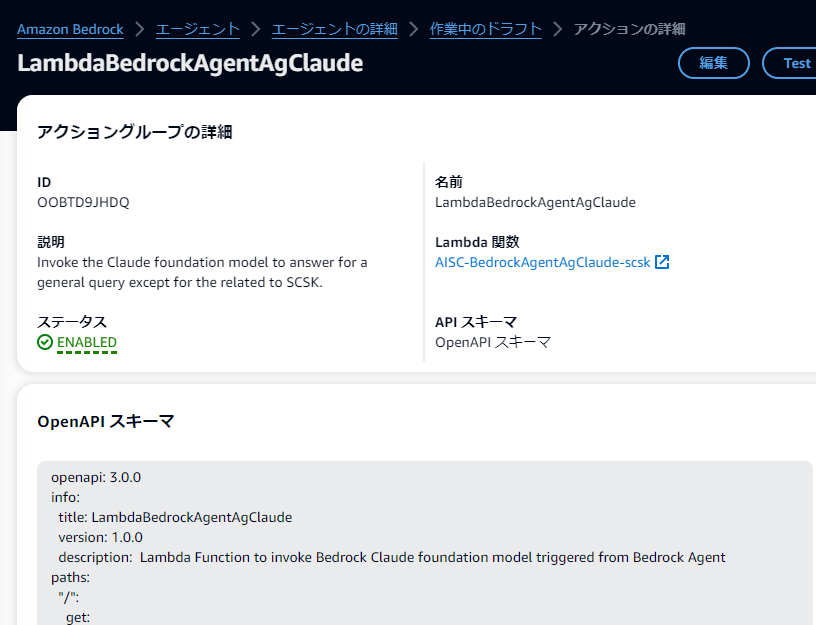
上記スクリーンショットは途中で切れていますので、実際に使ったスキーマを以下に貼り付けます。
openapi: 3.0.0
info:
title: LambdaBedrockAgentAgClaude
version: 1.0.0
description: Lambda Function to invoke Bedrock Claude foundation model triggered from Bedrock Agent
paths:
"/":
get:
summary: Invoke Claude foundation model
description: Invoke the Claude foundation model to answer for a general query except for the related to SCSK.
responses:
"200":
description: response
content:
application/json:
schema:
type: object
properties:
body:
type: string
decription はおそらく Agents for Amazon Bedrock がこのアクショングループを使用するか否かを判断するのに重要だと思うので、目的を書いておきます。
paths の部分ですが、正直ここの記述は Lambda 関数を実行する上では使用しないので、適当に書いておきました。get とか書いてありますが、全く使用しません。一応定義はしないといけないので書いている感じです。これで動きました。
まとめ
いかがでしたでしょうか。
Agents for Amazon Bedrock の設定は AWS マネジメントコンソールでノーコードでできます。分岐が増えた場合でも、応用してつくれると思います。
本記事が皆様のお役に立てれば幸いです。