

こんにちは。SCSKの山口です。
今回は、BigQueryのドライランを実際にやってみたブログです。
業務で非常にお世話になり、便利すぎて感動したのでブログ化しちゃいました。皆さんも是非ご活用ください。
BigQueryドライラン概要
ドライランとは、クエリの検証、料金/データ見積もりを ”クエリを実際に実行することなく” 把握する事ができるモードです。
クエリを実際に実行しない(クエリスロットを使用しない)ため、課金なしで実行できるという何ともありがたい機能になっています。
公式のドキュメントには以下の通り記載されています。
BigQueryのドライランモードでは、次の情報が提供されます。
・オンデマンドモードでの料金見積もり
・クエリの検証
・キャパシティモードでのクエリのおおよそのサイズと複雑さ
ドライランはクエリスロットを使用しないため、ドライランの実行に対しては課金されません。 ドライランによって返された見積もりを料金計算ツールで使用すると、クエリの費用を計算できます。
引用元:https://cloud.google.com/bigquery/docs/running-queries?hl=ja#perform_dry_runs
今回の活用方法
以前投稿したBigQuery Migration Serviceを使用することで大量のSQLをGoogleSQLの構文に変換しました。
しかし、SQL変換を用いたとしても、必ずしも完璧な(そのまま使用できる)SQLが生成されるわけではありません。
そんなこんなでSQLの修正作業が必要になったのですが、どのSQLが修正対象なのか一つひとつ開いて確認するのがまあメンドクサイ、、、
そんな時に、「ドライランを活用すれば修正が必要なSQLとそうでないものを簡単に分けることができる。」と思いつき実践したところ大変簡単で便利だったので紹介します。
実践:ドライランを使ってエラーを吐くSQLを特定する
準備:テーブル
以下のテーブルを準備します
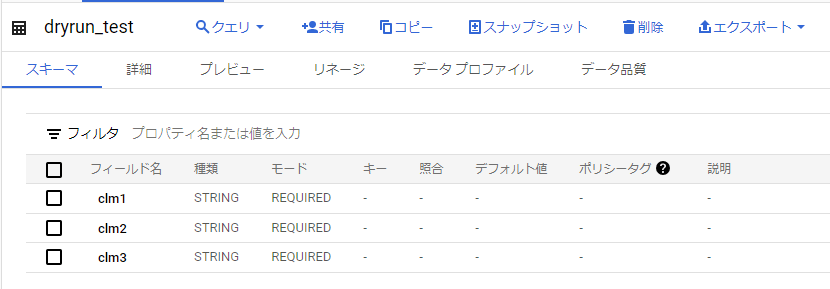
データも入れておきます
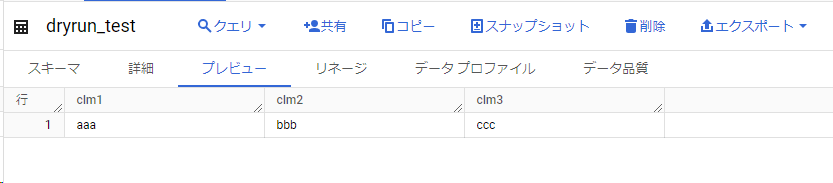
準備:SQLファイル
今回は以下の5つの簡単なSQLファイルを用意します。(奇数番目が成功、偶数番目が失敗するSQL例です。)
-- testSQL1.sql SELECT * FROM `evocative-entry-277709.yamaguchi_test.dryrun_test` ;
-- testSQL2.sql せれくとあすたぁふろむ`evocative-entry-277709.yamaguchi_test.dryrun_test`
-- testSQL3.sql
INSERT
`evocative-entry-277709.yamaguchi_test.dryrun_test` (clm1,
clm2,
clm3)
VALUES
('test', 'test', 'test')
;
-- testSQL4.sql いんさあといんとぅ`evocative-entry-277709.yamaguchi_test.dryrun_test`
「あすたぁ」と「いんとぅ」が気になりますね。
準備:Pythonスクリプト
今回はPythonコード内でbqコマンドを叩くという形にします。
「–dry_run」オプションをつけることでドライランを実行することができます。
| dryrun.py |
''' dryrun.py'''import osfrom subprocess import Popen, PIPE# プロジェクトIDproject_id = "evocative-entry-277709"# ドライラン結果テキストファイルresult_path = "/home/sho_yamaguchi/Blog/DryRun/result.txt"# SQLファイルのディレクトリSQLs_path = "/home/sho_yamaguchi/Blog/DryRun/SQLs"# SQLファイルのリストを取得sql_files = [f for f in os.listdir(SQLs_path) if f.endswith(".sql")]# 結果ファイルを開くwith open(result_path, "w") as result_file: for sql_file in sql_files: # SQLファイルのパス sqlfile_path = os.path.join(SQLs_path, sql_file) # SQLファイルの内容を取り込む →query_job with open (sqlfile_path, "r") as f: query_job = f.read() # ドライランコマンド dryrun_command = ["bq", "query", "--use_legacy_sql=false", "--dry_run", "--project_id", project_id, query_job] # ドライラン実行 process = Popen(dryrun_command, stdout=PIPE, stderr=PIPE) stdout, stderr = process.communicate() # 結果をファイルに書き出す result_file.write(f"--- {sql_file} ---\n") result_file.write(stdout.decode("utf-8")) if stderr: result_file.write(f"エラー:{stderr.decode('utf-8')}") |
準備は以上です。後はPythonスクリプトを実行するのみです。
実行結果
実行結果のテキストファイルは以下の通りです。
--- testSQL4.sql --- Error in query string: Syntax error: Illegal input character "\343" at [1:1] --- testSQL2.sql --- Error in query string: Syntax error: Illegal input character "\343" at [1:1] --- testSQL5.sql --- Query successfully validated. Assuming the tables are not modified, running this query will process 0 bytes of data. --- testSQL3.sql --- Query successfully validated. Assuming the tables are not modified, running this query will process 0 bytes of data. --- testSQL1.sql --- Query successfully validated. Assuming the tables are not modified, running this query will process 15 bytes of data.
いい感じ!!
「Error in query string: 」が吐かれている「testSQL2.sql」と「testSQL4.sql」が今回の修正対象だと一目でわかりますね。
クエリがエラーを吐かない場合、それぞれのクエリ実行に消費するバイト数も出力してくれています。
大規模なデータを扱う際や、大量のSQLを使用する際に、「課金額を把握する術」としても有効活用できます。
クエリ対象のテーブルの方はというと
狙い通り、何も起こっていません。
今回のテストSQLが実際に実行されると、テストデータがINSERTされ、最終的にDROPされてしまうはずですが無傷です。
実際のテーブルに影響を与えることなくクエリが成功するか失敗するかを判断してくれています。
まとめ
今回はBigQuery のドライラン機能をbqコマンドで実行してエラーが吐かれるSQLを特定してみました。
Pythonスクリプトに条件分岐を増やして、shutilで自動的にエラーSQLを他ディレクトリに移動させたりするとより便利ですね。
メンドクサイと思ったそこのあなた、
Geminiさんに書いてもらいましょう!