

こんにちは。SCSKの松渕です。
今回は、ある歌手の歌詞をベクトル化&簡易的なデータ分析してみました。
3/10に発表されたばかりのGemini Embedding 2 モデルを利用してみました!
はじめに
組み込みモデル(Embedding Model)とは?
一言で言うと、「言葉や画像の意味を、コンピューターが計算できる『座標(ベクトル)』に変換する技術」のことです。これまでのキーワード検索(完全一致)とは異なり、データの「文脈」や「ニュアンス」を数値化します。
なぜ「ベクトル」にするのか?
例えば、「ネコ」と「子猫」という言葉は、文字で見れば一字も重なりませんが、意味は非常に近いです。組み込みモデルを通すと、これらは多次元空間上で「非常に近い距離にある点」として配置されます。
-
キーワード検索: 「文字」が同じものを探す。
-
セマンティック検索(Embedding): 「意味」が似ているものを探す。
Gemini Embedding 2 とは?
2026年3月にプレビューが開始された gemini-embedding-2-previewは、これまでのテキスト専用モデルから大きく進化を遂げました。
1. 待望の「マルチモーダル」対応
何といっても最大の特徴はネイティブマルチモーダル対応です。テキストだけでなく画像や動画も同じベクトル空間にマッピングできます。 「この動画の、このシーンに似た画像を、テキストで検索する」といった、メディアを跨いだ検索が極めて高い精度で実現可能になりました。
テキスト、画像、動画、音声、およびPDFの5つの異なるモダリティが、モデルの中間層(隠れ層)において動的に相互作用し、深いレベルでの「セマンティック・フュージョン(意味的融合)」が実現されます。例えば、動画内の特定の動きと添えられた説明テキストが、単一の3,072次元ベクトル空間内に矛盾なく配置されるのである。
もちろん今までも実現できてはいたんですが、いったんテキスト化してベクトル化が必要だったのが不要になったようです。
2. マトリョーシカ・エンベディング(次元の柔軟性)
通常、ベクトルの次元数(1536次元など)は固定ですが、gemini-embedding-2では次元を削っても精度が落ちにくい」設計が採用されています。マトリョーシカ人形のように、大きなベクトル(3072次元)の中に、小さなベクトル(768次元や256次元)が綺麗に入れ子になって入っています。
-
高精度が必要な時: 1536次元でフルパワー解析。
-
コストや検索速度を優先する時: 256次元に圧縮してインデックス容量を削減。
といったように、用途に応じてインフラのコスト最適化とパフォーマンスのバランスを柔軟に取れるようになっています。
次元数は検索速度とのトレードオフにもなっているため、1次検索は低次元で素早く、2次検索は高次元で品質高く、といった使い分けもできます。
3. 長文対応とコンテキスト理解の深化
従来モデルよりも一度に処理できるトークン数(入力できる文章量)が拡大し、ドキュメント全体の一貫性をより深く理解したベクトル生成が可能になりました。これにより、RAGにおける「情報の取りこぼし」が劇的に減少しています。
うれしい点としては、細かいチャンクに刻む必要がなくなったため、「文章の前後関係(文脈)がぶった切れる」という今までのRAG特有の悩みが一定解消されます。8kあれば、一般的な章立て一つ分や、中規模なPDFなら丸ごと一つのベクトルとして取り込めるため、検索の精度(セマンティックな一致度)が劇的に向上します。
| 機能 | Gemini Embedding(従来) | Gemini Embedding 2 |
| 対応データ | テキストのみ | テキスト・画像・動画 |
| 次元数 | 固定 | 可変(マトリョーシカ対応) |
| 検索精度 | 高い | 極めて高い(最新MTEB基準) |
| 主な用途 | テキストRAG | マルチモーダルRAG / 高度な検索 |
今回やってみたこと
ある有名歌手(2026/3/28現在、288曲リリースされていました)の歌詞をベクトル化して、クラスタリングしてみたいと思います。
いずれ、画像や映像と絡めて分析だとか検索できるようにしていきたいなと思います。
事前準備
データ準備
ブログの本質じゃないのでさらっとしますが、めっちゃくちゃ大変でした。今回一番時間かかりました。
以下のような、CD名と歌詞のリストです。今回は歌詞しか使わないですが、いずれ発売年ごとに傾向分析とかしてみたいと思って付与してます。
ベクトル化とBigquery格納とクラスタリング
まずはエクセルからBigQueryへ
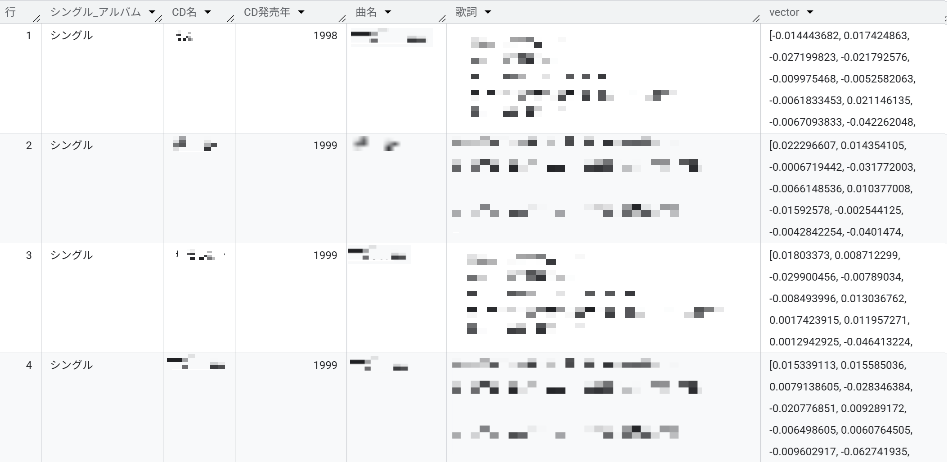
先ほどのエクセル歌詞の部分をベクトル化しますが、処理しやすいようにまずBigQueryへ投入します。
なお、Antigravityですべて機能開発してもらいました。Antigravityのブログは以前に書いたので今回は割愛します。
日本語で依頼すればこのレベルの処理はすぐ実装してくれるかと思います。

ベクトル化してBigQuery投入
Vertex AIでGemini呼び出して、各曲ごとのベクトルを作成してもらいます。
この際、google-genai SDKを使用し、gemini-embedding-2-preview モデルを利用して数値ベクトルに変換します。
gemini-embedding-001では設定できていたユースケースの設定(task_type)はgemini-embedding-2-previewでは使用できなくなっております。プロンプトにタスクの指示を追加する必要があります。
今回でいえばベクトル化する際の指示プロンプトに以下のような入力をします。
task: clustering |query: {content}
ユースケースの設定の前提として、情報検索や埋め込みベクトルの世界で「対称的(Symmetric)」と「非対称的(Asymmetric)」という分類があります。
対称的な検索(Symmetric Search):「似たもの同士」を探すパターンです。クエリ(入力)とターゲット(対象)の長さや情報の密度がほぼ同じ場合を指します。
非対称的な検索(Asymmetric Search):「短い問い」から「長い答え(あるいは詳細な情報)」を探すパターンです。現代の検索エンジンやAIチャット(RAG)の多くはこの形です。
今回のようなクラスタリング用のベクトルは対称的な検索になります!
エンベディング(Google Cloud ドキュメント)
ベクトル化無事できました
クラスタリング
ベクトル化の次はクラスタリングします。
エルボー法を用いて、クラスタリングする適切な数を探し出します。
※私自身、ちゃんとエルボー法を理解していないのですが、Antigravityによくわからないまま依頼したら作ってくれましたし動きました。
ざっくり以下のような動きをしているようです。
- 候補となるクラスタ数(k)のループ
「何グループに分けるのが適切か?」を判断するために、2から最大10までで、力技で全てのパターンを計算します。
k=2, 3, 4, …, 10 のそれぞれで K-Means を実行します。 - エルボー法による「曲がり角」の特定
「グループを増やしても、もう劇的には誤差(クラスタ中心点から各要素の距離の二乗和(SSE))が減らなくなった地点」が、そのデータセットにとって最も自然なグループ数(最適な k)であると判断します。 - KneeLocator による自動判定
通常、エルボー法は人間がグラフを見て判断しますが、このコードではプログラムで自動判定しています。
プロットされた曲線の「曲率」が最大になるポイントを数学的に算出しています。 - 最終的なクラスタリングの実行
決定された「最適な k」を用いて、もう一度 K-Means を実行し、各歌詞に cluster_id(0, 1, 2…)を割り振ります。
今回は288曲を4クラスタに分類されました。

Vertex AI(Gemini)で、クラスタの特性を分析
ベクトル化してのクラスタリングは、ブラックボックス的な数学的分類となります。
そのため、そのままでは説明性(Interpretability)を持ちません。
そのため、Geminiへ各クラスタの意味の説明を求めました。以下、Geminiの分類への説明です。
以下の説明でどの歌手かわかった人はジャンキーかもしれません・・・!
クラスター1:【生理現象・身体感覚系】(Biometric Cluster) このクラスターは、恋愛感情を直接的な形容詞ではなく、心拍数の変化、皮膚の温度、体調の違和感として描写する楽曲群である。感情が脳ではなく「肉体」に宿っていることを強調する。 クラスター2:【生活空間・日常痕跡系】(Domestic Trace Cluster) このクラスターは、洗面所、台所、廊下といった生活空間の中に、相手の「不在の在」や「共有の証拠」を見出す楽曲群である。大きな愛を語るのではなく、小さな生活雑貨に愛を託すのが特徴である。 クラスター3:【執着・不可逆的痕跡系】(Obedient / "Curse" Cluster) ファンの間で「呪い」と称されることもある、非常に重厚で執着心の強い楽曲群である。 クラスター4:【季節・比喩描写系】(Ephemeral Cluster) 季節の移ろいや気象現象に、感情のゆらぎや「戻れない時間」を投影する楽曲群である。
母数が多く、後付けでの説明が困難な際には採用検討するとよいかと思います
多段階クラスタリング: 全データをLLMに見せるのではなく、数学的に仕分けした「中心」だけをAIに解釈させる手法。
特徴量抽出(トピックモデル)を介した分類: 高次元のベクトル(3072次元など)を、人間が理解しやすい2次元や3次元に圧縮して、「地図」を作る手法。
「LLM蒸留」による分類器の構築 (Distillation): LLMの知能を、より軽量で高速な「分類専用モデル」に移植する手法。
まとめ
最新のGemini Embedding 2を使って、一見「データ化」とは対極にあるような情念の世界を可視化してみました。
数学的に導き出された4つのクラスタは、驚くほど正確に彼女の楽曲が持つ「多面性」を捉えていました。特に、特定の生活雑貨に宿る記憶や、身体感覚で語られる恋、あの歌詞特有の重さみたいなものまでもが、3,072次元の空間において明確な座標として存在していたことには、一人の技術者として、そして一人のファンとして震えるものがありました。
技術は、時に「意味」を冷徹に分解しますが、今回のように「言葉にできない魅力」を再発見する手助けもしてくれます。次は、マルチモーダルモデルの真骨頂である画像や動画(MV)を組み合わせ、彼女の表現する世界をより多角的に、深く、ベクトル空間の中に再現してみたいと思います。