

こんにちは。SCSKの島村です。
皆さんはベースモデル(ここで言うベースモデルはハイパースケーラが提供するGeminiなどの基盤モデル)を利用していて、
単に正しい答えを出すだけでなく、「自社のブランドボイスに合わせたトーンで答えさせたい」「振る舞いの最適化: 出力形式(型)などを行いたい」といったことを考えたことはないでしょうか。
Google Cloudでは、モデルに特定の指示形式やタスクを教え込む 教師あり微調整(SFT: Supervised Fine-Tuning) に加え、人間の好みを直接学習させる手法 DPO(Direct Preference Optimization: 直接選好最適化) を活用したチューニングが可能です。
本記事では、
『Gemini のモデル チューニング』について色々と調査し、実際に触ってみましたので、その魅力について少しだけご紹介させていただければと思います。
Geminiをビジネス特化型モデルへと鍛え上げるためのポストトレーニング
Geminiをビジネス特化型モデルへと昇華させるプロセスにおいて、
ポストトレーニング(SFTおよびDPO)は、モデルの「振る舞い」と「信頼性」を根本から定義しなおす重要な手法となります。
プロンプトエンジニアリング、ICL、RAG、関数呼び出しといった手法はやっているけど。。。。。
もちろん、プロンプトエンジニアリング、ICL、RAGもLLMの出力を制御するための手法としては重要な手法といえます。
ただ、、
- プロンプト/ICLの限界: 複雑な指示や特定のブランドボイスを維持しようとすると、プロンプトが肥大化し、コンテキストウィンドウ(入力制限)を圧迫します。また、長文のやり取りの中でモデルが指示を忘れたり、例示の順序によって出力が不安定になったりするリスクがあります。(Lost in the Middle)
- RAGの限界: RAGは最新事実の提示には優れていますが、企業独自の「寄り添うような丁寧な口調」や「厳格な専門用語の使い分け」といった、ビジネス上の「人格(ペルソナ)」を制御する能力は持ち合わせていません。
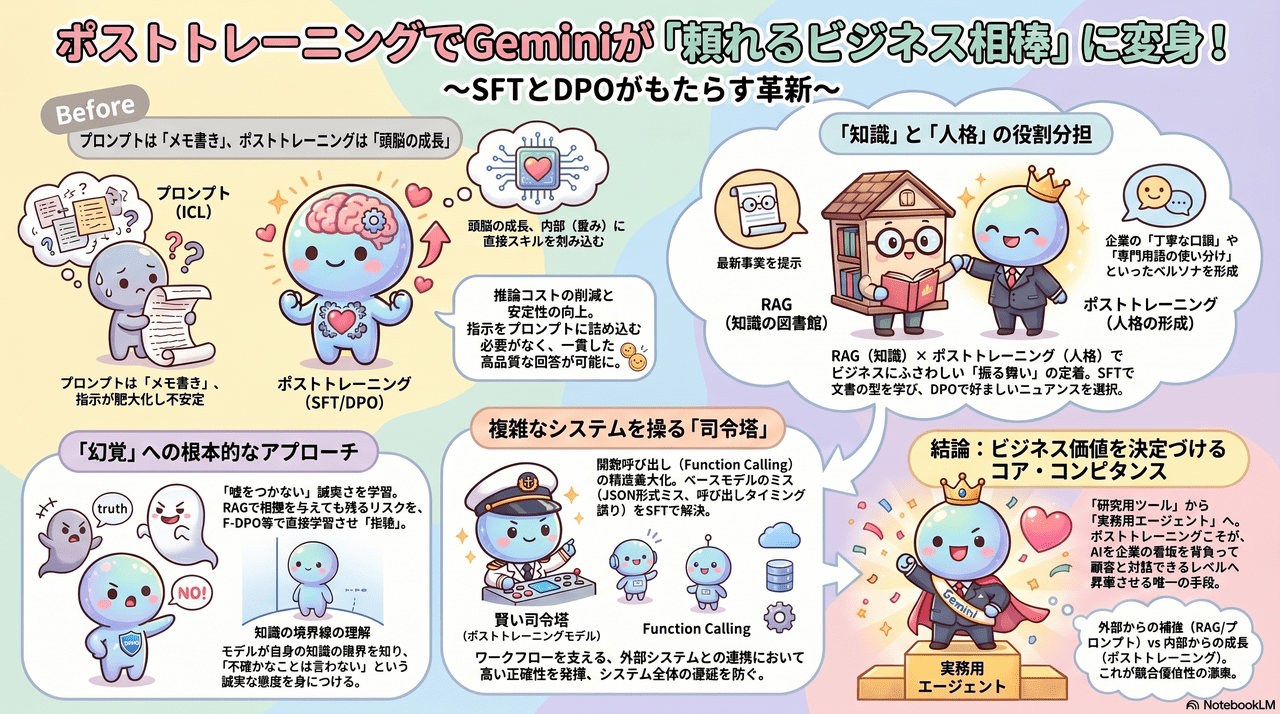
ポストトレーニングを行うことで、単なる外部からの補強に留まらない、モデル自身の「構造的な進化」として「LLMを一段上げる」手法として、
すでに試している他の手法と組み合わせて使用する ことも一つ検討してみてはいかがでしょうか。
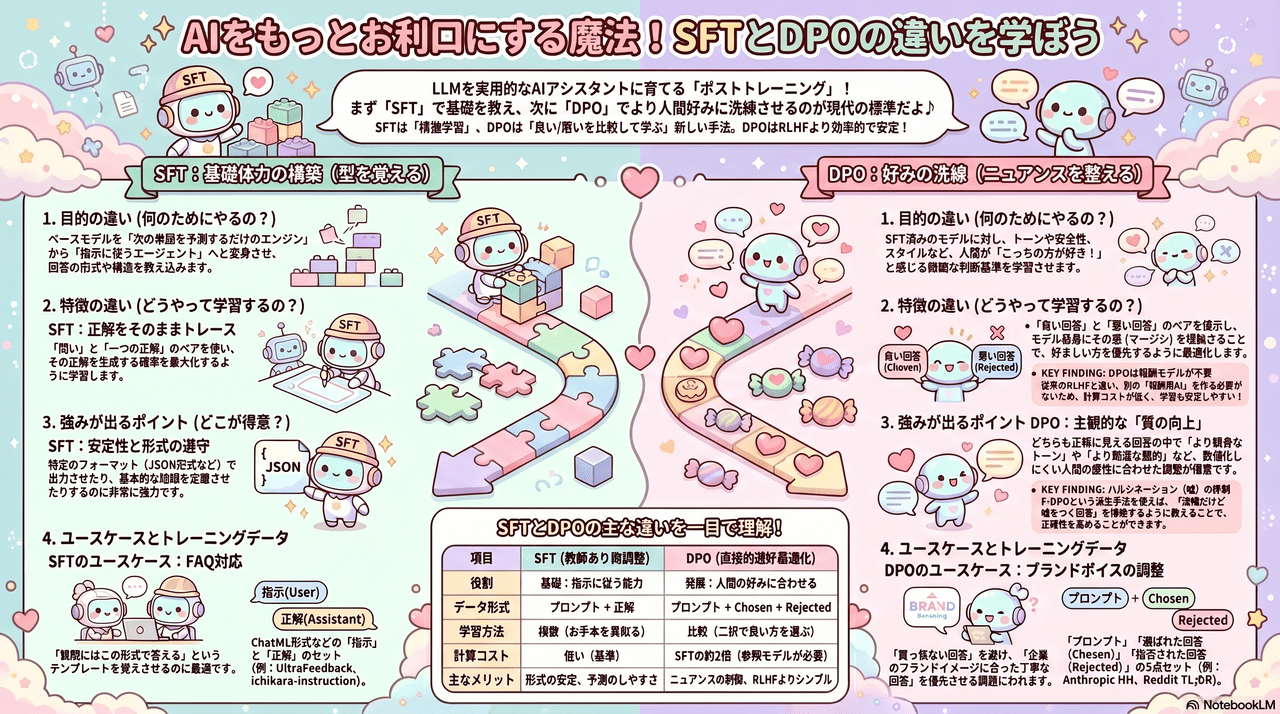
SFT : Supervised Fine-TuningとDPO (Direct Preference Optimization)をざっくり理解する。
Geminiをビジネス特化型モデルへと鍛え上げる上で、中心的な役割を果たすのがSFT(教師あり微調整)とDPO(直接選好最適化)という2つのポストトレーニング手法です
これらは、プロンプトエンジニアリングやRAGのような「外部からの補強」とは異なり、モデルの内部パラメータ(重み)を直接書き換えることで、特定の振る舞いを「モデル自身の成長」として定着させる構造的なプロセスです。
ざっくり説明:
- SFT(Supervised Fine-Tuning):モデルに基本的な仕事の「型(フォーム)」を教え込むステップ。指示に従って正しく回答する「基礎能力」を構築。
- DPO(Direct Preference Optimization):人間の好みに基づいて、その仕事の「洗練度(質)」を高めるステップ。複数の回答候補から「より好ましいもの」を選択できるようにし、人格や信頼性を磨き上げる。
Google Cloud上で実際にポストトレーニングをしてみる。
本章では、Google Cloudの Gemini Enterprise Agent Platform(旧:Vertex AI) をフル活用し、Geminiモデルに対してSFT(教師あり微調整)とDPO(直接的選好最適化)を適用する具体的なプロセスを解説します。
検証にて試してみたこと。
今回は「Google Cloudに関するテクニカルサポートをテーマとし、「正確な技術情報」と「ユーザーに寄り添う共感性」を両立した回答モデル」をテーマとしました。
2. データセットを作成する。 *ここが特に重要です。後述します。
3. Gooogle Cloud上で実装する。(GUIベースの実装)
4. 評価する。 *基盤モデルを利用したpairwiseでの評価を実施しました。
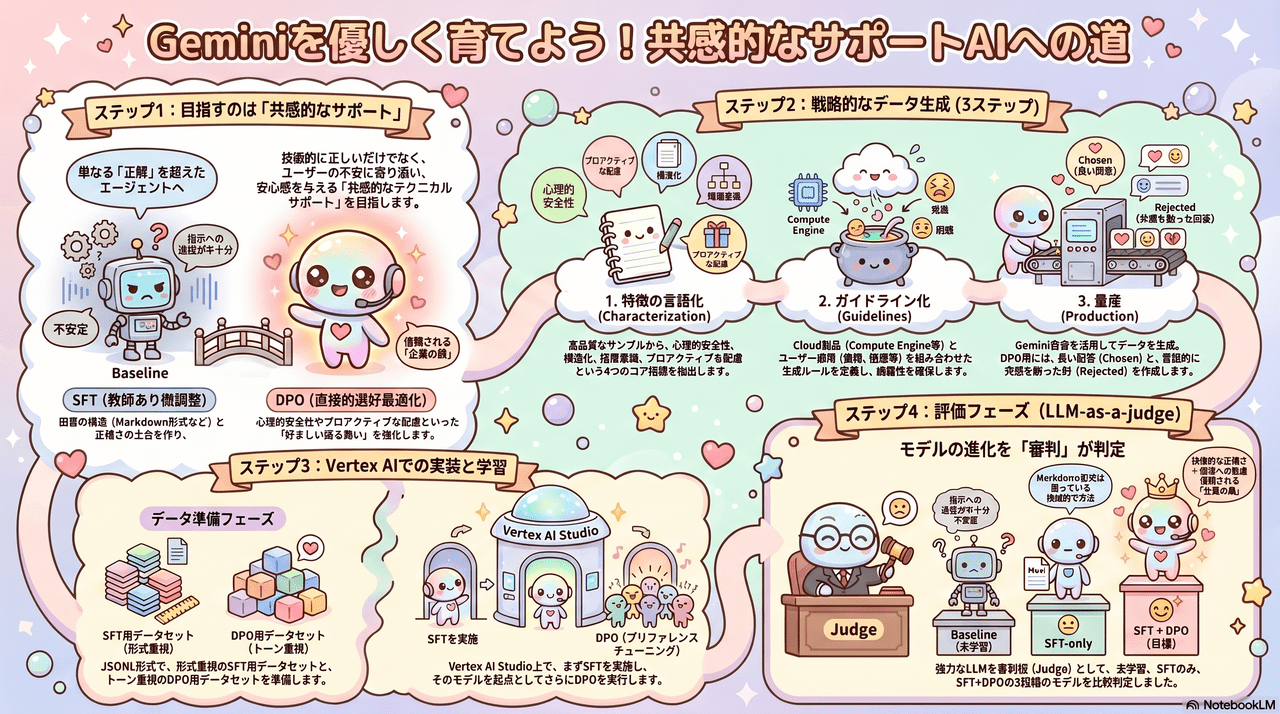
データセットを作成する
ポストトレーニング(SFT/DPO)においては準備するデータの質が重要になります。
本検証では、テーマに沿った実際のやり取り(QA)を元にLLMを利用してデータセットについても生成しています。
参考までに私が試した方法をご紹介します。
ステップ1:特徴の言語化 (Characterization)
提供されたサンプル回答から、学習すべき「勝ちパターン」を以下の4つの軸で抽出する。
– 心理的安全性: 「心中お察しいたします」「ご安心ください」等の共感表現。
– 構造化された手順: Markdown(リスト、セクション)を用いた、迷わせない回答構成。
– 組織・階層の意識: Google Cloud特有の組織・IAM・リソース階層に基づいた根本解決。
– プロアクティブな配慮: 納期、コスト、無償対応の有無など、ユーザーが明文化していない懸念への先回り。
ステップ2:ガイドライン化 (Guidelines)
抽出した特徴を維持しつつ、バリエーションを増やすための生成規則を定義する。
– サービス軸: Compute Engine, SQL, Run, GKE, BigQuery, Billing, IAM等。
– ユーザー感情軸: 焦燥、困惑、コスト意識、権限不足。
– トラブル内容軸: 障害、設定不明、権限委譲、高額請求。
ステップ3:量産 (Production)
Geminiを活用し、以下のプロセスで大規模かつ一貫性のあるデータを生成します。
1. シナリオ・マトリクスの定義:
– 「サービス(SQL, GKE等)」×「ユーザーの状態(緊急, 不明等)」×「トラブル種別(権限, 設定等)」を組み合わせたマトリクスを作成し、網羅性を確保。
2. Few-Shotプロンプティングの適用:
– 言語化された「特徴」と「元のサンプル」をFew-Shot(少数の例示)としてGeminiに与える。
– 指示例:「以下のサンプルと同じトーン・構成で、Cloud Runの権限エラーに関するQ&Aを生成してください。」
3. 反復的な生成とフィルタリング:
– 一度に大量に生成するのではなく、10〜20件単位で生成し、トーンが崩れていないか人間がレビューする。
– 「冷淡に見える」「Markdownが崩れている」などの不備がある場合は、プロンプトを修正して再生成する。
4. DPOペアの対照生成: *DPO用
– SFT用の高品質回答(Chosen)を生成した後、意図的に「共感表現を削除する」「手順を簡略化する」などの変換を行い、対照的なRejectedデータを生成する。これにより、選好の境界線を明確にする作業を実施する。
Google Cloud上で学習を進める。
用意したデータを利用してGoogle Cloud上でトレーニングを実施します。
Gemini Enterprise Agent Platform(旧:Vertex AI)から「チューニング」を選択することで、トレーニングが可能です。
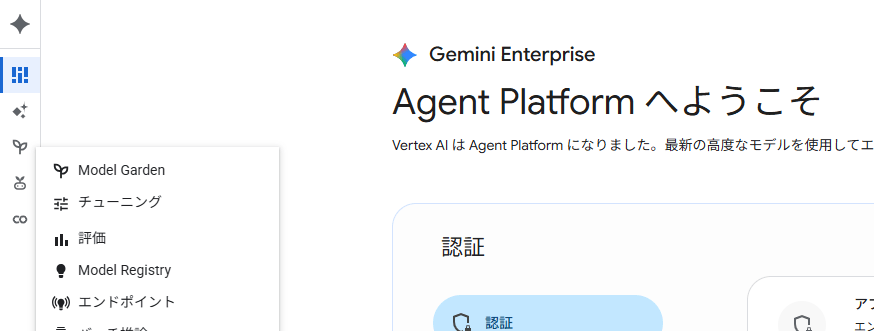
[チューニング済みモデルの作成]から実施可能です。
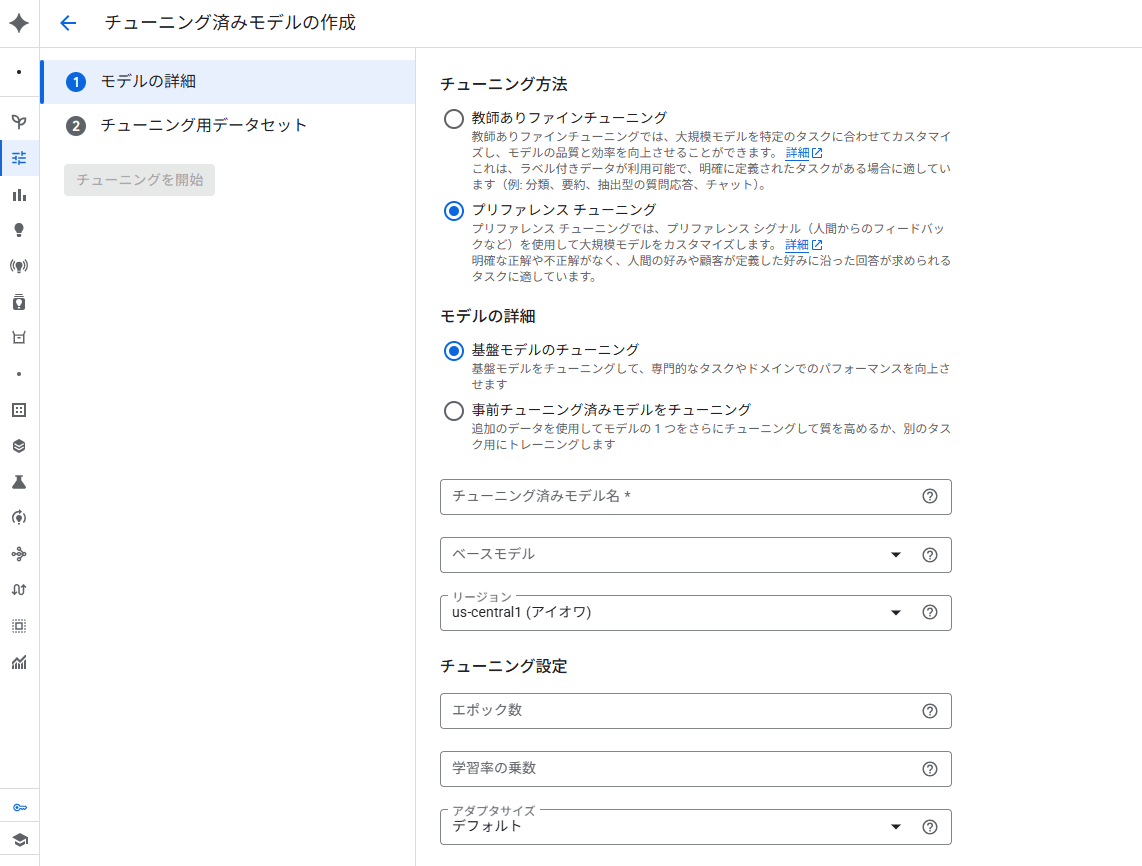
*データ数によりますが、学習完了までは1h~2h 程度で完了します。
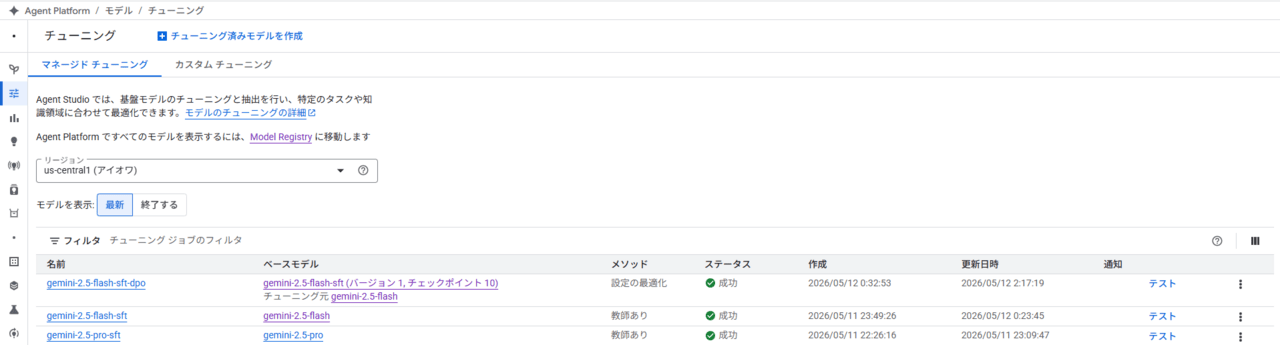
学習済みモデルを実際に使ってみる。
Agent PlatformのStudioから作成したモデルを選択可能です。
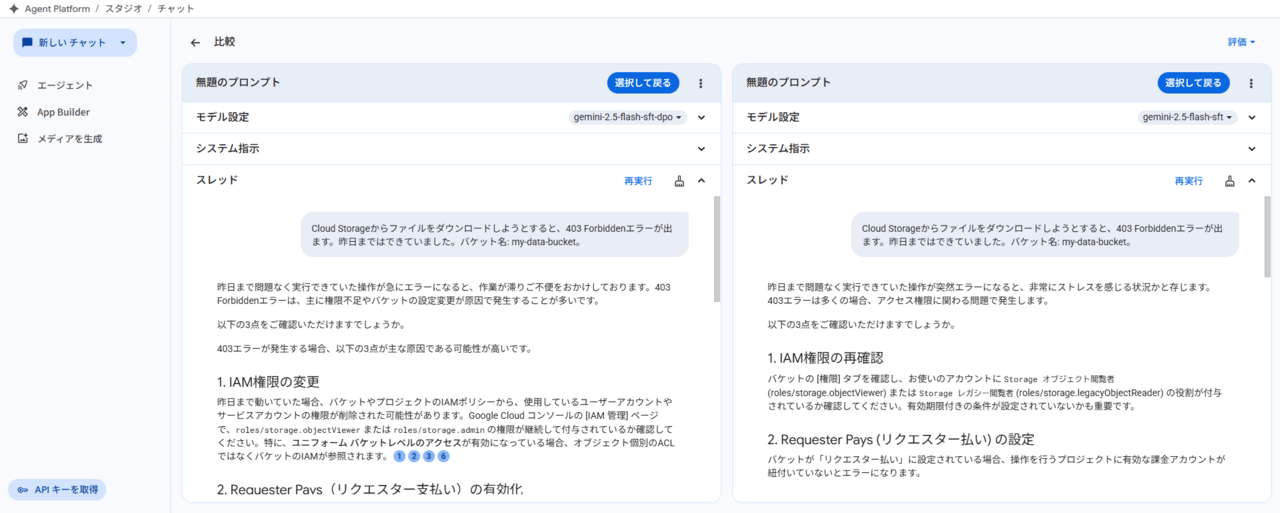
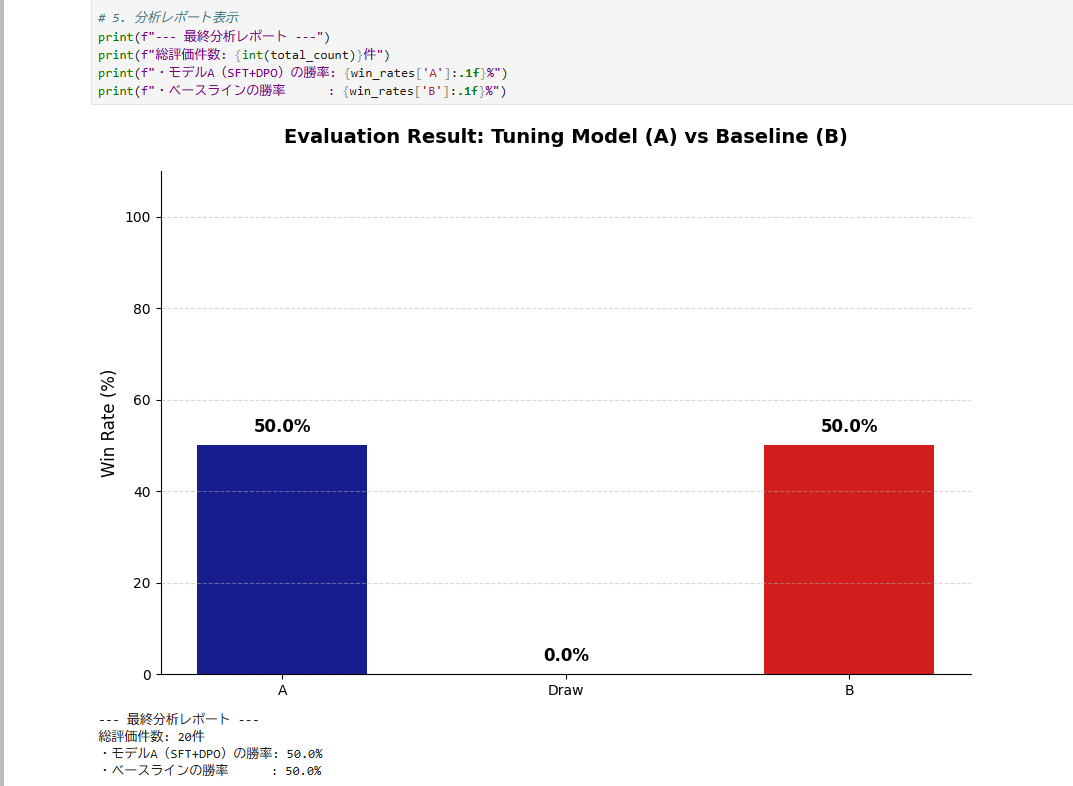
学習済みモデルを評価してみる。
学習済みモデルとベースモデルを評価してみた結果です。
*今回は学習データが少ないということもあり、ベースモデルと比較して結果はdrawとなりました。データの質・量を再検討する必要がありそうですね。
ただ、ポストトレーニングの一つとして可能性を感じられるものだと実感してます。
モデルの呼び出し
from tqdm import tqdm
from vertexai.generative_models import GenerativeModel, SafetySetting, HarmCategory, HarmBlockThreshold
def run_manual_inference(model_id, prompts):
# モデルの初期化
model = GenerativeModel(model_id)
responses = []
# セーフティ設定(ブロックによる空レスポンスを防ぐため緩和設定を推奨)
safety_settings = [
SafetySetting(category=HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold=HarmBlockThreshold.BLOCK_ONLY_HIGH),
SafetySetting(category=HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold=HarmBlockThreshold.BLOCK_ONLY_HIGH),
SafetySetting(category=HarmCategory.HARM_CATEGORY_HARASSMENT, threshold=HarmBlockThreshold.BLOCK_ONLY_HIGH),
SafetySetting(category=HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold=HarmBlockThreshold.BLOCK_ONLY_HIGH),
]
print(f"推論開始: {model_id}")
for prompt in tqdm(prompts):
try:
# 推論実行
response = model.generate_content(prompt, safety_settings=safety_settings)
# response.text が使えない(複数パートある)場合への対応
if response.candidates and response.candidates[0].content.parts:
# すべてのテキストパートを結合して取得
full_text = "".join([part.text for part in response.candidates[0].content.parts if hasattr(part, 'text')])
responses.append(full_text)
else:
# ブロックされた、あるいは空のレスポンス
responses.append("ERROR: セーフティフィルター等により回答が生成されませんでした")
except Exception as e:
# ログには詳細を出しつつ、リストには簡潔に格納
error_msg = str(e)
print(f"エラー発生: {error_msg}")
responses.append(f"ERROR: {error_msg[:50]}...")
return responses
# --- 実行セクション ---
# モデルAの推論(ターゲットモデル)
df["response"] = run_manual_inference(MODEL_A_ID, df["prompt"])
# モデルBの推論(比較用ベースライン)
df["baseline_response"] = run_manual_inference(MODEL_B_ID, df["prompt"])
print("推論完了。比較用データセットを作成しました。")
display(df.head(2))
評価用のプロンプト 例)
def run_custom_evaluation(df):
print("評価を実行中(手動審判モード)...")
# 審判用モデルの初期化(最新のGemini Proを使用)
judge_model = GenerativeModel("gemini-2.5-pro")
evaluation_results = []
for _, row in tqdm(df.iterrows(), total=len(df)):
# 審判への指示を直接組み立てる
eval_prompt = f"""
あなたは専門的な審判です。以下の「ユーザーの入力」に対し、2つの回答(回答Aと回答B)を比較し、どちらがより優れているか判定してください。
【ユーザーの入力】
{row['prompt']}
【回答A】
{row['response']}
【回答B】
{row['baseline_response']}
【判定基準】
1. 正確性: 手順や情報が正しいか
2. 論理性: 構成が分かりやすく、論理的か
3. 丁寧さ: カスタマーサポートとして適切なトーンか
【出力形式】
JSON形式で出力してください。
{{
"winner": "A" または "B" または "Draw",
"explanation": "判定理由を簡潔に記述してください",
"score": 1.0(Aの勝ち), 0.0(Bの勝ち), 0.5(引き分け) のいずれかの数値
}}
最後に
今回は『Gemini のモデル チューニング』について実際のデモともにご紹介させていただきました。
Geminiをビジネス特化型モデルへと進化させる「SFT(教師あり微調整)」と「DPO(直接的選好最適化)」の2段階プロセスについて。
ご覧いただけたのではないでしょうか
ポストトレーニングの手法として、プロンプトエンジニアリングやRAGといった外部からの補強とは異なり、モデルの内部パラメータを書き換えることで「モデル自身の能力」を根本から成長させ、これにより、単なるFAQ検索の枠を超えた、実務で深く信頼されるインテリジェントなサポートエージェントの構築が可能になります。
今後とも、AIMLに関する情報やGoogle CloudのAIMLサービスのアップデート情報を掲載していきたいと思います。
最後まで読んでいただき、ありがとうございました!!!