

こんにちは。SCSKの山口です。
今回は、Cloud Functions とData Fusionを組み合わせて、下記のパイプラインを構築してみたいと思います。
- Cloud Functions のEventarc トリガーでGCSバケットへのファイル配置・更新を検知する
- Cloud Functions からDataFusionパイプラインを起動し、データ加工とBigQuery へのデータ格納を行う
特定のバケットにファイルが置かれた際に、それを検知してData Fusion起動→BigQuery テーブルへデータ格納。といった流れです。
Data Fusion パイプライン作成
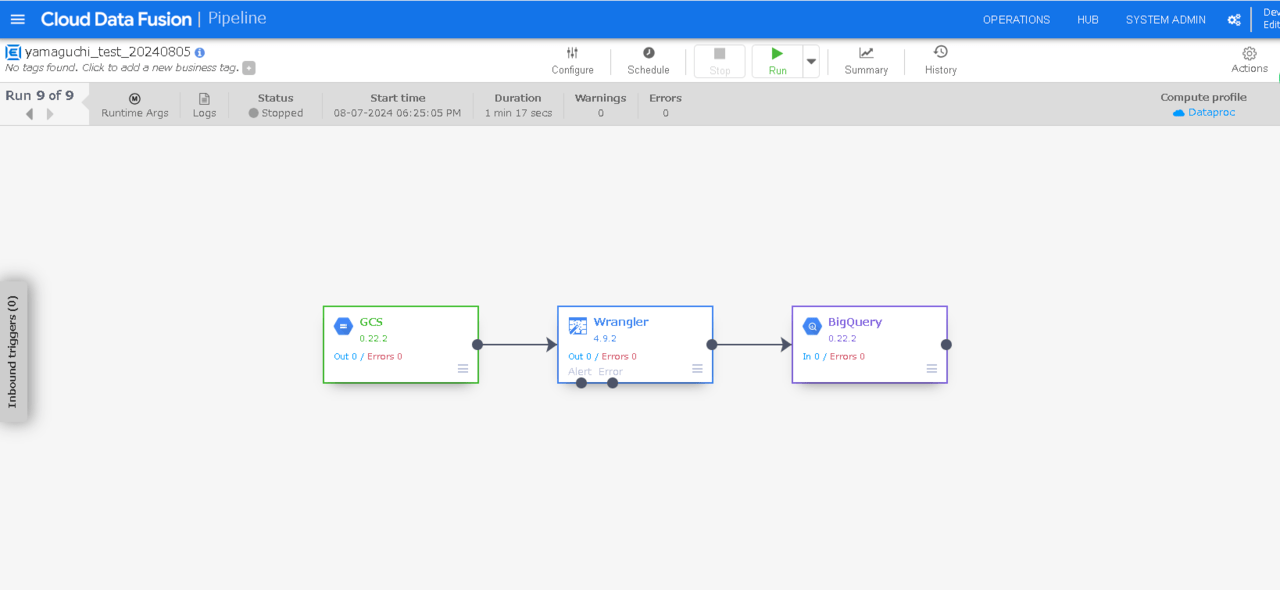
今回は、下記のブログで作成したパイプラインを再利用します。

CSVファイル内のハイフン付きの電話番号からハイフンを取り除き、BigQuery テーブルへ格納するパイプラインです。
Wranglerプラグインを直感的に操作する方法を紹介しています。本ブログのメインではないので詳細は省きます。気になる方はぜひご覧ください。
Cloud Functions ファンクション作成
次にファンクションを作成し、デプロイします。
構成
下記構成で作成します。
- 基本
- 環境:第2世代
- 関数名:yamaguchi-test-datafusionkick
- リージョン:asia-northeast1(東京)
- トリガー
- トリガーのタイプ:Cloud Storage
- イベントタイプ:google.cloud.storage.object.v1.finalized
- バケット:yamaguchi_test_20240806

イベントタイプの「google.cloud.storage.object.v1.finalized」については、下記ブログの「Cloud Storageトリガーとは?」で紹介してあるのでこちらをご覧ください。
今回は、「yamaguchi_test_20240806」バケットを対象とし、バケットレベルで更新を検知する設定とします。
コード
今回作成したコードは下記のとおりです。
| main.py |
import functions_framework
import os
import requests
from google.cloud import data_fusion_v1
from google.auth import compute_engine
from google.auth.transport.requests import Request
@functions_framework.cloud_event
def call_datafusion(cloud_event):
# Data Fusionクライアント生成
DataFusion_client = data_fusion_v1.DataFusionClient()
# アクセストークン取得 →{access_token}
credentials = compute_engine.Credentials()
credentials.refresh(Request())
access_token = credentials.token
# Data Fusionパイプライン呼び出し用の認証ヘッダ設定 →{auth_header_fusion}
auth_header_fusion = {'Authorization': f'Bearer {access_token}'}
#パラメータ設定
namespace = 'default'
app_name = 'yamaguchi_test_20240805'
workflow_name = 'DataPipelineWorkflow'
#CDAPのエンドポイントを取得(gcloudコマンド無し) →{cdap_endpoint}
set_request = data_fusion_v1.GetInstanceRequest(
name="projects/scsksdv-dev-XXXXXXXXX/locations/asia-northeast1/instances/test-df-02",
)
get_prm = DataFusion_client.get_instance(request=set_request)
cdap_endpoint = get_prm.api_endpoint
# CDAP APIにリクエストを送信
url = f'{cdap_endpoint}/v3/namespaces/{namespace}/apps/{app_name}/workflows/{workflow_name}/start'
response = requests.post(url, headers=auth_header_fusion)
# レスポンスを確認
if response.ok:
print(f'パイプライン呼び出しは正常に処理されました。ステータスコード: {response.content.decode()}')
print(f'IDトークン: {ID_token}')
print(f'アクセストークン: {access_token}')
else:
print(f'パイプライン呼び出しでエラーが発生しました。ステータスコード: {response.content.decode()}')
return ("END")
|
| requirements.txt |
functions-framework==3.* google-cloud-storage google-auth google-cloud-data-fusion pandas requests |
以上でファンクションは完成です。
ファンクションのコードに関しての備忘(※読み飛ばしても問題ないです)
コードを作成するにあたっていくつかの壁に当たったので備忘として残しておきます。
今回パイプラインを起動するコードの作成にあたって、下記の方法(コマンド実行)でパイプラインが起動できることをはじめに確認しました。
POST -H "Authorization: Bearer ${AUTH_TOKEN}" "${CDAP_ENDPOINT}/v3/namespaces/namespace-id/apps/pipeline-name/workflows/DataPipelineWorkflow/start"
上記コマンドでは、認証とパイプライン起動のために「AUTH_TOKEN」、「CDAP_ENDPOINT」を必要とします。
この「2つのトークンの取得 → CDAP APIへリクエスト送信」のコードをCloud Functions で実行したところ、下記のエラーにあたりました。
| errorとなる部分 |
 |
| error内容 |
| 500 Internal Server Error: The server encountered an initial error and was unable to complete your request. |
詳細を調べたところ、Cloud Functions内で「gcloud」のコマンドが実行できず、「CDAP_ENDPOINT」が正常に取得できていないことが原因でした。
対応策
上記の対応策として、「gcloudコマンドを使わないコードに置き換える」手段を取りました。
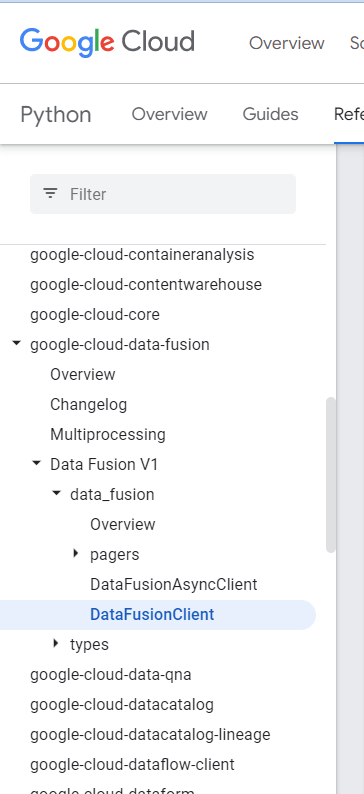
下記ライブラリリファレンスから代替ライブラリを探し、「CDAP_ENDPOINT」を正しい形で取得できるようコードを修正しました。
| →CDAP_ENDPOINTの欲しい形は「https://…」 |
 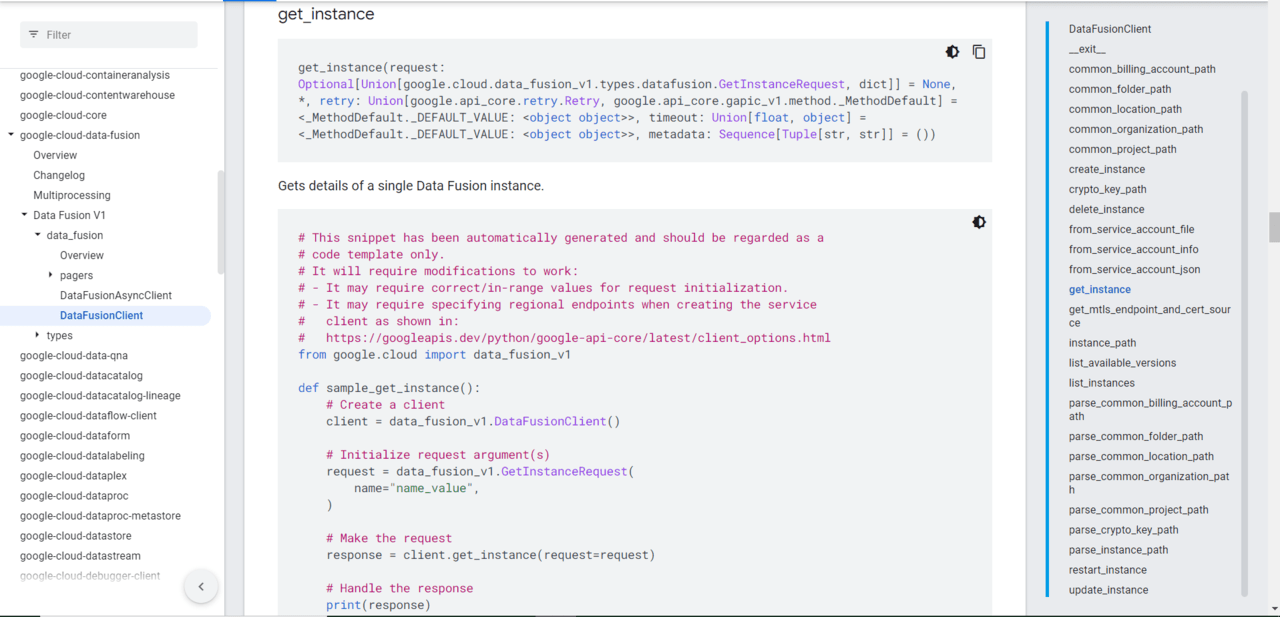 |
| →怪しいライブラリを発見 |
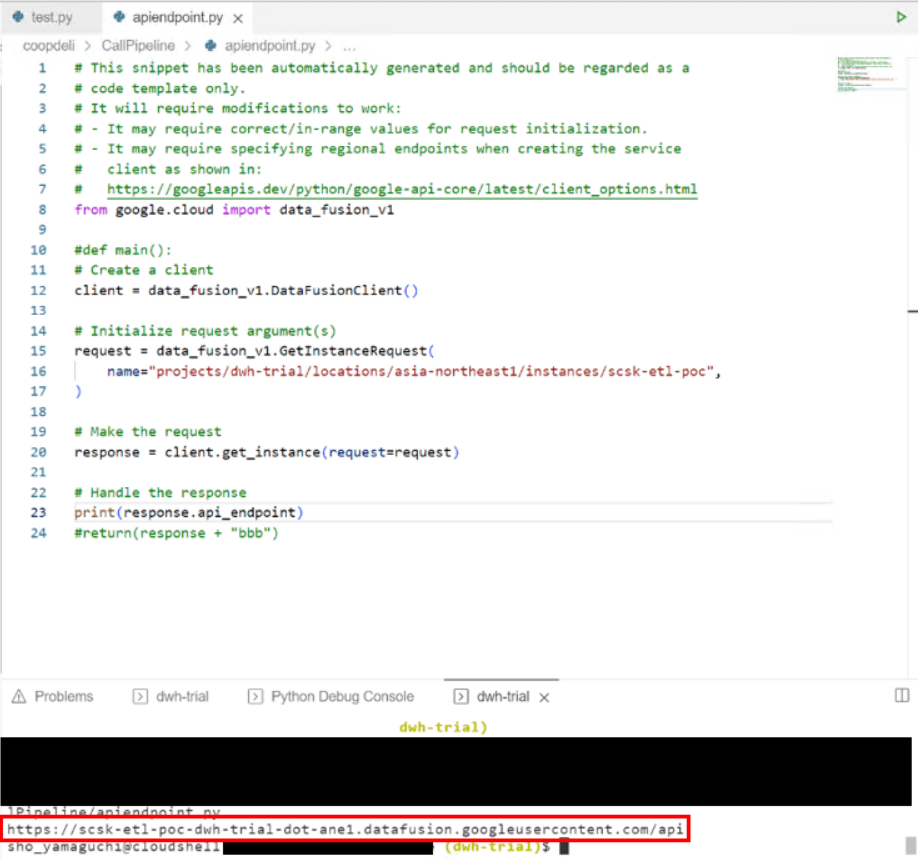 |
| →コピペして実行してみると、欲しい形「https://…」でCDAP_ENDPOINTが取得できた |
実践
ファンクションとパイプラインが準備できたので、ここから実践に入ります。
まず、今回やりたいことをおさらいします。
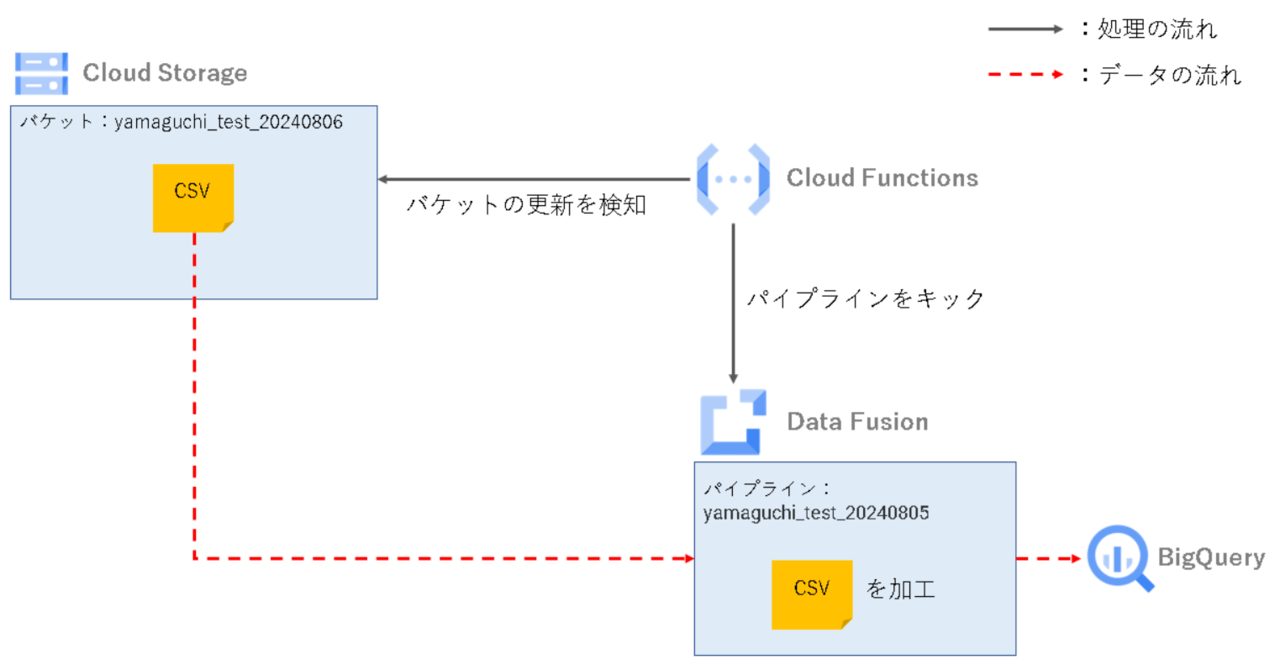
- Cloud Storageバケットの変更、更新をCloud FunctionsのCloud Storageトリガー出検知
- Cloud FunctionsからData Fusionのパイプラインをキック
- Cloud Storage上のファイルをBigQueryテーブルに取り込む
仰々しく図式化しましたが、やりたいことはシンプルです。
今回使用する、データ取り込み先のテーブルは下記です。
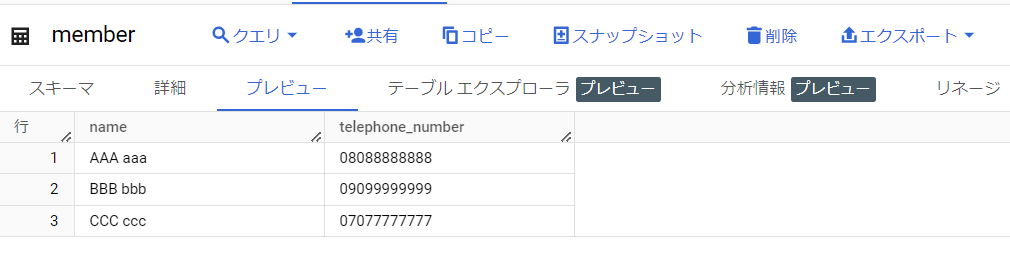
また、GSCに配置する(テーブルに取り込む)CSVファイルの中身はこんな感じになっています。

それではファイルをバケットに配置してみます。
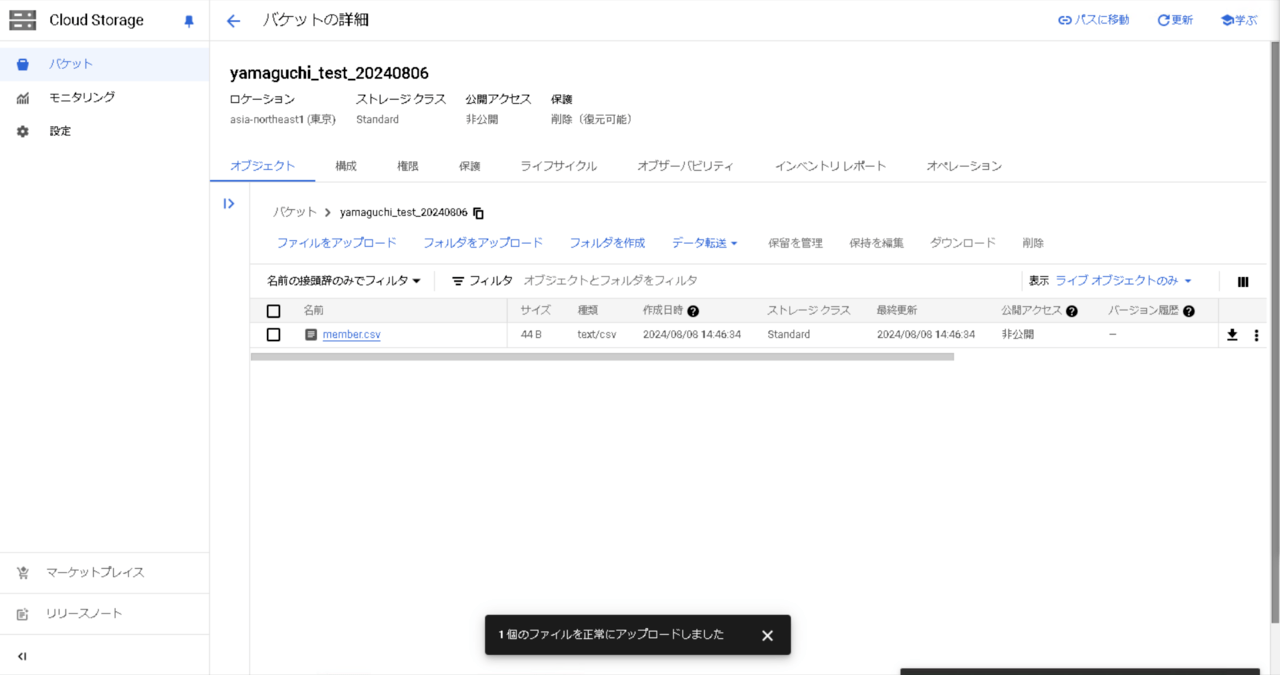
バケットにファイルを配置すると、
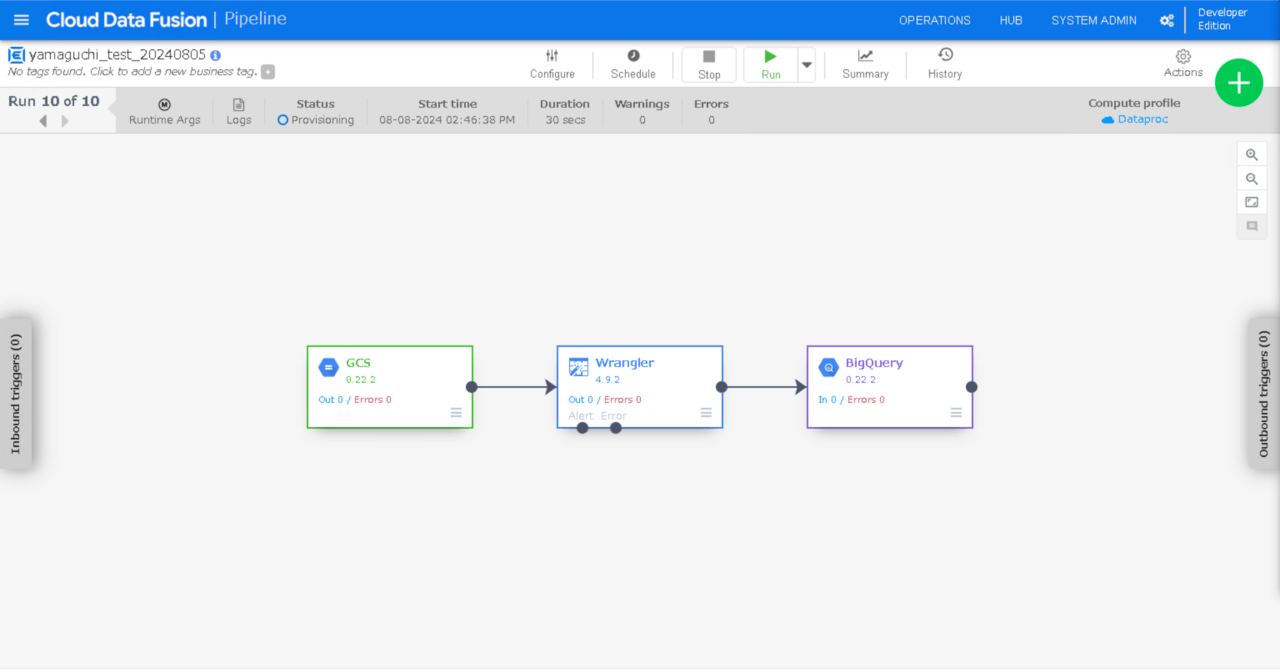
パイプラインが起動されました。(Provisioning状態)
しばらく待つと、
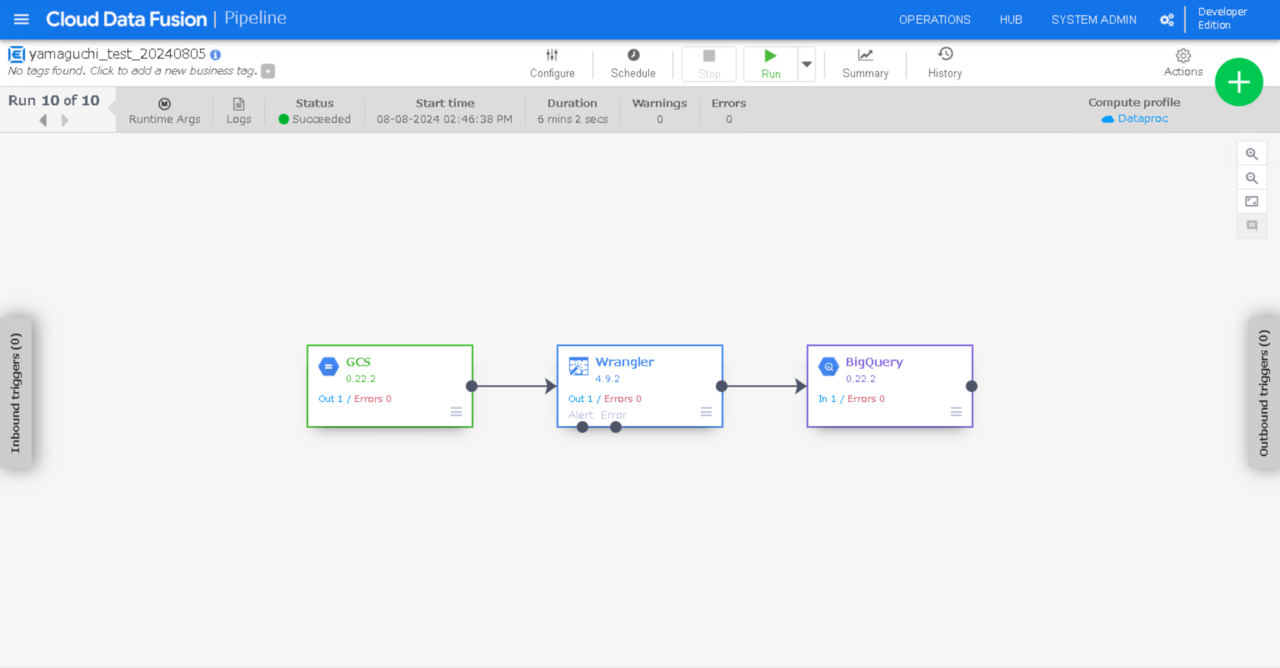
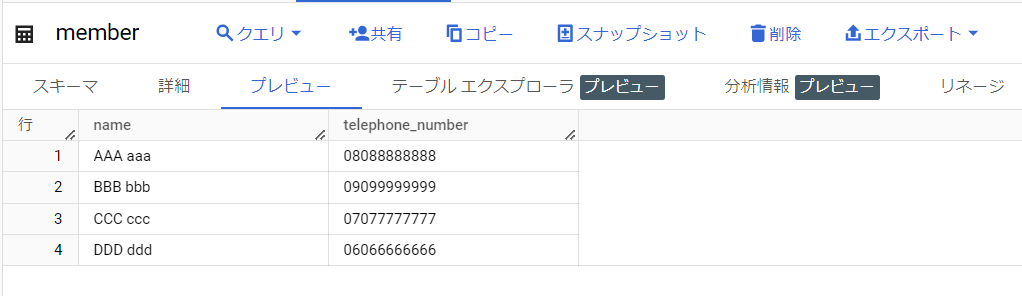
パイプライン処理が完了し、BigQueryテーブルにレコードが追加されました。大成功です。
最後に
今回はCloud FunctionsのCloud Storageトリガーでバケットの変更を検知し、Data Fusionパイプラインを起動してみました。
バケット単位での変更検知ができるとなると、次にやりたいのは「フォルダ・ファイル単位」の変更検知ですよね。
実は、フォルダ・ファイル単位の検知トリガーはまだ実装されていません。(なんてことだ・・・)
しかし、Cloud Functions内のコードに処理を寄せることで、疑似的に実現することは可能です。
こちらについては下記ブログで詳細な方法が紹介されているのでぜひご覧ください。(先を越されてた・・・)