

こんにちは!SCSKの野口です。
別の記事で、LangChainを利用したチャンキングのデモを行いました。
その際に、日本語のチャンキング結果が文字化けしてしまうという事象が発生したので、後学のためのに記事にまとめます。
事象
記事内で行った3つのデモの中で、デモ2(分割アルゴリズムの比較)では固定長分割のためにLangChainの「TokenTextSplitter」を利用してチャンキングを行おうとしていました。具体的なコードは下記となります。
from langchain_text_splitters import TokenTextSplitter
# TokenTextSplitterを利用したチャンキングメソッド
def token_splitter(chunk_size: int, chunk_overlap: int):
return TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
# テキスト作成メソッド
def make_doc(noise_repeat: int) -> str:
return (
"背景説明。" * noise_repeat
+ "A部品の設定方針は次の通り。基本はX=ONとする。"
+ "ただしBモード時のみ例外でX=OFFとする。"
)
# チャンキング対象テキスト作成
noise_repeat = 20
doc = make_doc(noise_repeat)
# チャンキング設定
chunk_size = 25
chunk_overlap = 0
# チャンキング
chunks = token_splitter(chunk_size, chunk_overlap).split_text(doc)
# 表示
for i, chunk in enumerate(chunks, 1):
print(f"Chunk {i}:\n{chunk}\n---")
上記コードを実行してみると、一部文字化けが発生していることに気が付きました。
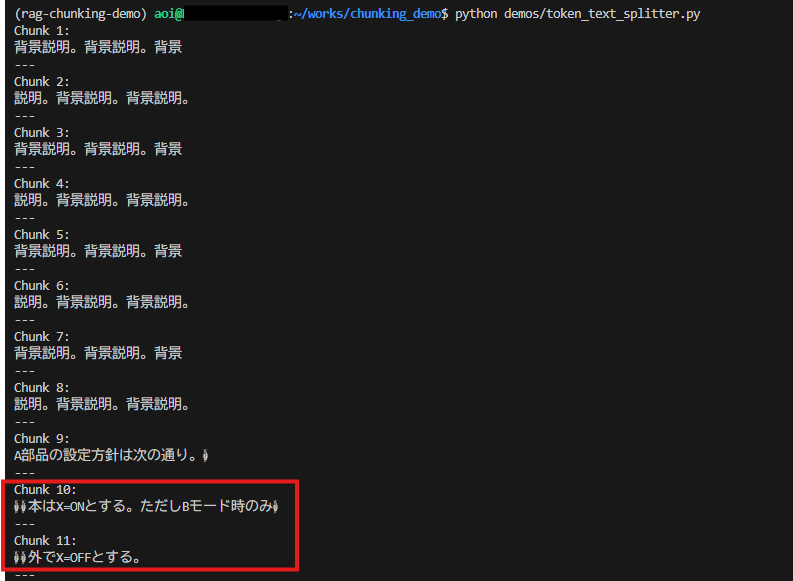
原因
なぜ文字化けが発生したのか?それは、TokenTextSplitterの仕様が原因でした。
「TokenTextSplitter」 はトークン境界を優先して分割しますが、日本語や中国語などのマルチバイト文字を含む文字列では、分割後の文字列再構成時に文字境界が崩れるケースがあるようです。
その結果として、UTF-8 として無効な並びが `�` として崩れて表示されるようです。
LangChainの公式ドキュメントにも、「TokenTextSplitter」を使用すると不正なUnicode文字が発生する可能性があると記載されています。
(原文)Some written languages (e.g. Chinese and Japanese) have characters which encode to two or more tokens. Using theTokenTextSplitterdirectly can split the tokens for a character between two chunks causing malformed Unicode characters. UseRecursiveCharacterTextSplitter.from_tiktoken_encoderorCharacterTextSplitter.from_tiktoken_encoderto ensure chunks contain valid Unicode strings.——————————————–(日本語訳)一部の表記言語(中国語や日本語など)には、2つ以上のトークンにエンコードされる文字があります。 をTokenTextSplitter直接使用すると、文字のトークンが2つのチャンクに分割され、不正なUnicode文字が発生する可能性があります。RecursiveCharacterTextSplitter.from_tiktoken_encoderまたはを使用するCharacterTextSplitter.from_tiktoken_encoderことで、チャンクに有効なUnicode文字列が含まれるようにすることができます。
対応方法
公式ドキュメントに記載がある通り、TokenTextSplitterを下記のいずれかに置き換えます。
(修正前)
- TokenTextSplitter
(修正後)
- RecursiveCharacterTextSplitter.from_tiktoken_encoder
- CharacterTextSplitter.from_tiktoken_encoder
先ほど文字化けが発生していたコードを書き換えて確認してみましょう。
RecursiveCharacterTextSplitterへの置き換え
from langchain_text_splitters import RecursiveCharacterTextSplitter
# RecursiveCharacterTextSplitterを利用したチャンキングメソッド
def token_splitter(chunk_size: int, chunk_overlap: int):
return RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
# テキスト作成メソッド
def make_doc(noise_repeat: int) -> str:
return (
"背景説明。" * noise_repeat
+ "A部品の設定方針は次の通り。基本はX=ONとする。"
+ "ただしBモード時のみ例外でX=OFFとする。"
)
# チャンキング対象テキスト作成
noise_repeat = 20
doc = make_doc(noise_repeat)
# チャンキング設定
chunk_size = 25
chunk_overlap = 0
chunks = token_splitter(chunk_size, chunk_overlap).split_text(doc)
for i, chunk in enumerate(chunks, 1):
print(f"Chunk {i}:\n{chunk}\n---")
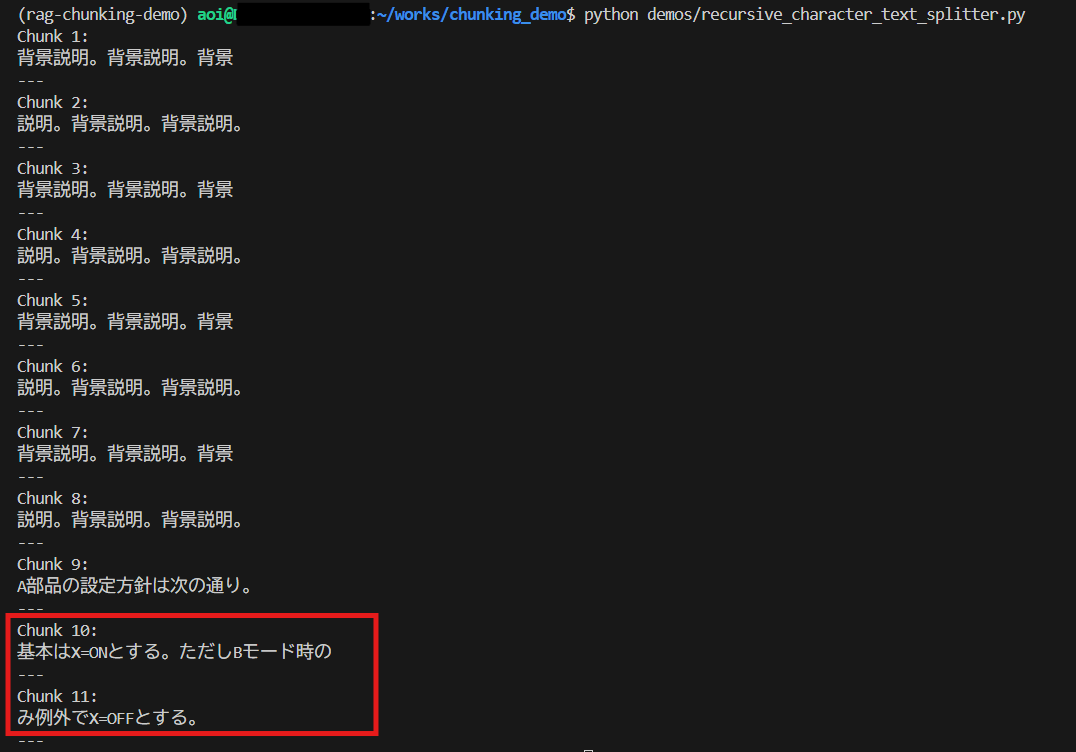
実行結果: 文字化けしていない ⇒ 改善された!
CharacterTextSplitterへの置き換え
from langchain_text_splitters import CharacterTextSplitter
# CharacterTextSplitterを利用したチャンキングメソッド
def token_splitter(chunk_size: int, chunk_overlap: int):
return CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator="",
)
# テキスト作成メソッド
def make_doc(noise_repeat: int) -> str:
return (
"背景説明。" * noise_repeat
+ "A部品の設定方針は次の通り。基本はX=ONとする。"
+ "ただしBモード時のみ例外でX=OFFとする。"
)
# チャンキング対象テキスト作成
noise_repeat = 20
doc = make_doc(noise_repeat)
# チャンキング設定
chunk_size = 25
chunk_overlap = 0
chunks = token_splitter(chunk_size, chunk_overlap).split_text(doc)
for i, chunk in enumerate(chunks, 1):
print(f"Chunk {i}:\n{chunk}\n---")
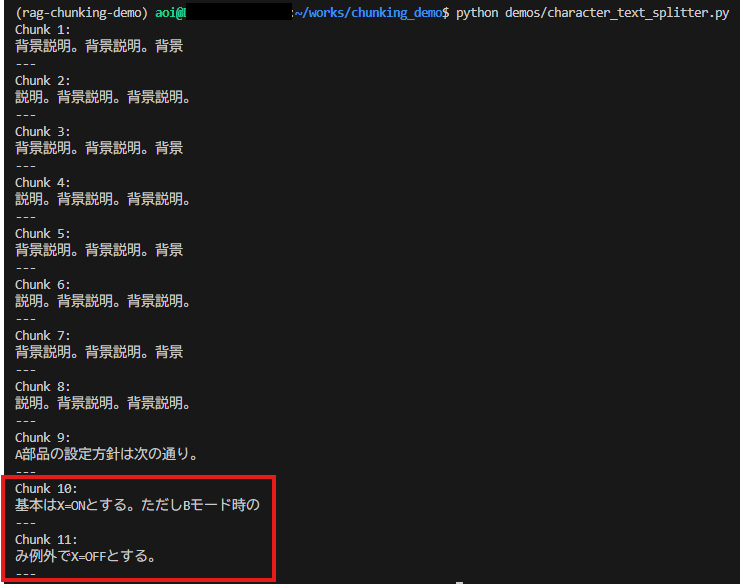
実行結果: 文字化けしていない ⇒ 改善された!
まとめ
意外と気にせず「TokenTextSplitter」を利用している人もいらっしゃるかと思います。
文字化けが発生している場合の原因がわからない場合、日本語ドキュメントに「TokenTextSplitter」を利用してチャンキングしていないかを確認してみると良いかもしれません。

