
こんにちは。新人のtknです。最近、急にめっきり寒くなりましたね。
今年が明けてからでしょうか、冠婚葬祭イベントが急に発生し、装備一式を急遽用意することになりお財布もすっかり寂しくなってしまいました。昔は全て制服で済んでいたのに……大人になるってこういうことでしょうか……。
さて本日は、私の配属部署で取り扱っている、InfoWeaveという製品のRAGサービスにおいて扱える3つのベクトルデータベース(Pinecone, Amazon Bedrock Knowledge Bases, Amazon Kendra)の違いについて調査していこうと思います。
はじめに
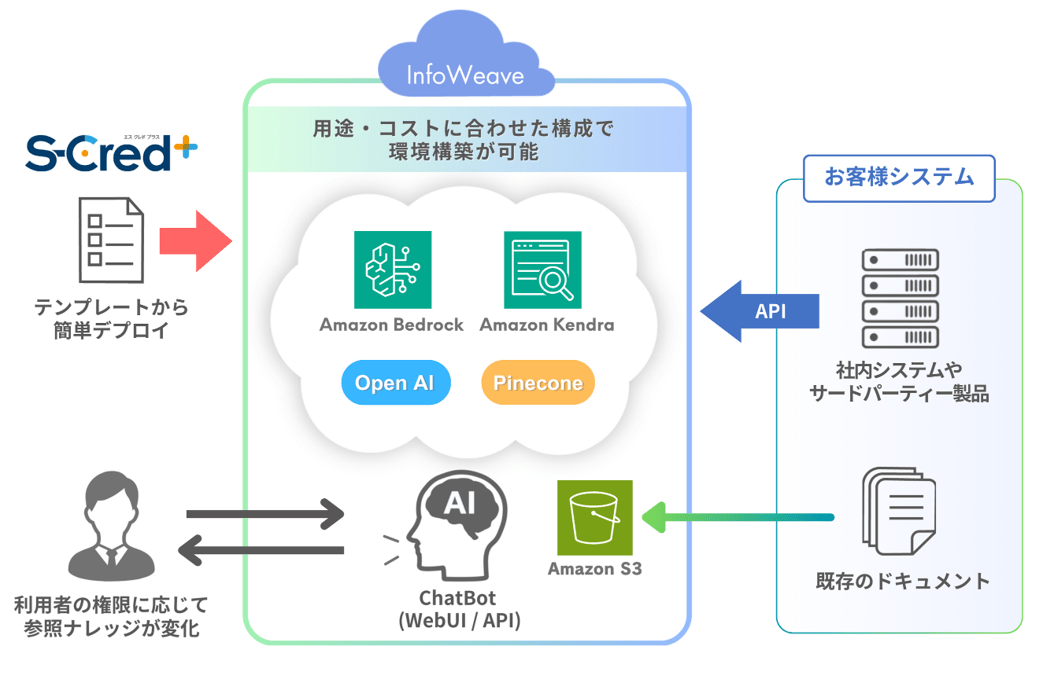
InfoWeaveとは「RAGやAIエージェントなどを利用できる環境をお客様のAWSアカウントに素早く・簡単に構築できるサービス」です。InfoWeaveのRAGサービスの詳細については、以下のサイトやブログ記事をご参照いただけますと幸いです。
生成AI RAG構築ソリューション – InfoWeave
かんたんRAG環境構築 S-Cred+ InfoWeaveをリリースしました
InfoWeave RAG構築ソリューションのアーキテクチャについて
かんたんRAG環境構築 S-Cred+ InfoWeaveをリリースしました
InfoWeave RAG構築ソリューションのアーキテクチャについて
InfoWeaveでは、RAG検索用のベクトルデータベースとしてPinecone, Knowlege Bases (Amazon OpenSearch Serverless), Amazon Kendraを選択可能としており、以下のように目的に応じてお客様に最適なLLMとベクトルデータベース組み合わせを選んでいただけることが魅力の1つとなっています。
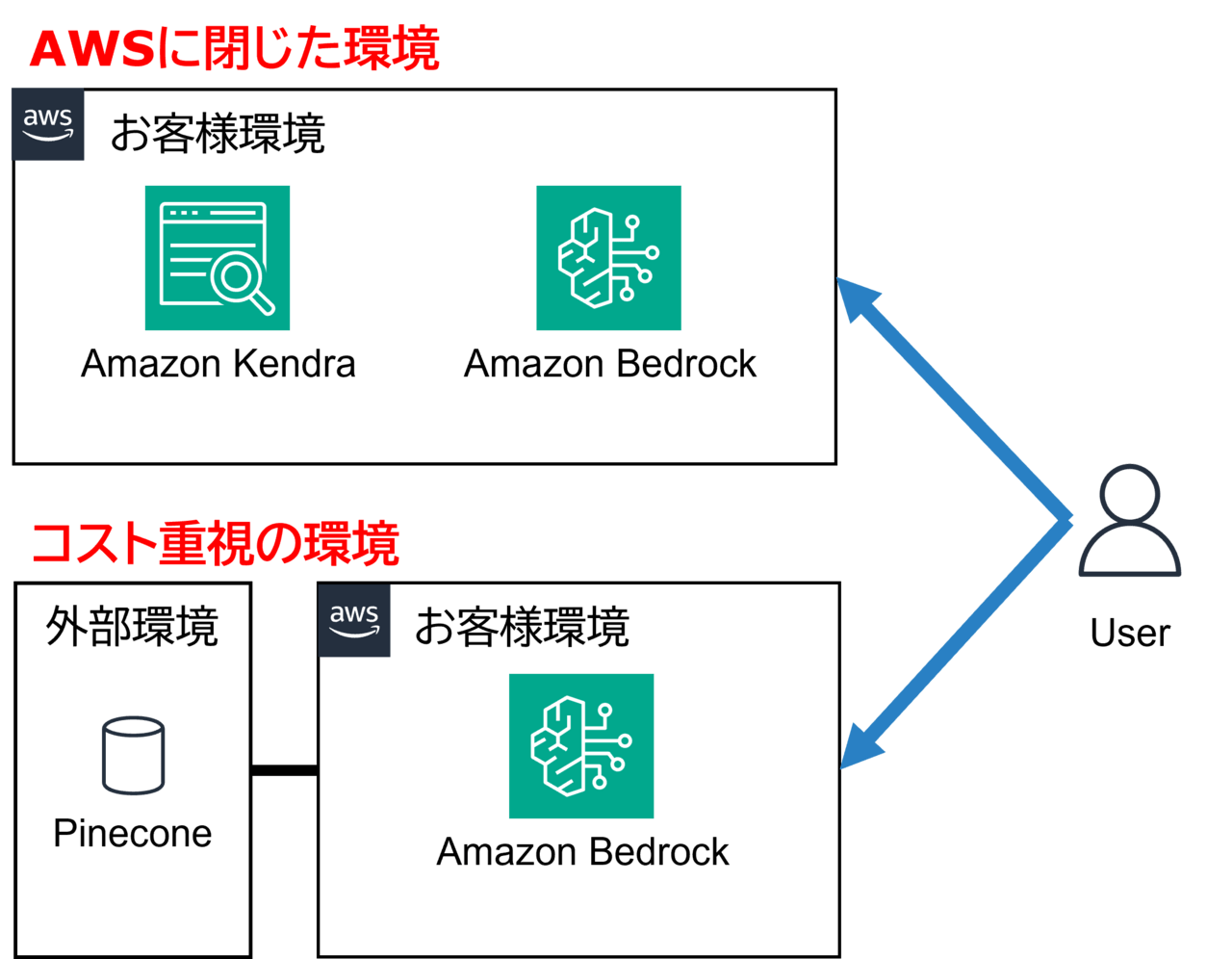
この選択肢の多さを初めて知ったとき、AWS初心者の私は「実際に金額や精度などにおいてどれくらい差があるものなのだろう?」と疑問に思いました。 そのため今回は、金銭面や精度面などから3つのベクトルデータベースについて調査、比較した結果をお届けしたいと思います。 この記事がInfoWeaveの導入を検討しているお客様の参考になりましたら幸いです!
調査結果
早速、3つのベクトルデータベースの比較結果を以下に示します。
| Pinecone | Knowledge Bases (OpenSearch Serverless) |
Amazon Kendra | |
| 最低利用金額 | 0円/月または 50ドル (7,785円) / 月 |
172.8ドル (26,905円) / 月 | 230.4ドル (35,874円) / 月 |
| 基本的な従量課金要素 | プランに応じた月額制 | ベクトルデータベースの 起動時間 |
Indexの起動秒数, コネクタでの同期秒数 |
| 規定値を超過した場合の 従量課金要素 |
データの読み込み/書き込み量, 保存量 | OpenSearch Compute Units (OCU) の増加数 | 実行クエリ数, データ保存量 |
| Indexにかかる料金 | Index自体への課金無し | 0.24ドル (38円) / 時 | 0.32ドル (50円) / 時 |
| 検索アルゴリズム | ANN検索 (近似最近傍法) | k-NN検索(k近傍法) | 自然言語処理&機械学習 |
| 検索精度 | やや高い | 高い | 最も高い |
| 連携可能なAWSサービス | S3, Secrets Manager, Knowledge Bases, Sage Makerなど | S3, Aurora, Neptune Analytics, Amazon Kendraなど | S3, Aurora, RDS, DynamoDB, FSx, Bedrockなど |
いかがでしょうか?同じベクトルデータベースでも、課金要素から検索アルゴリズムまでちゃんと違いがあるように見えますね。
それでは、これから各ベクトルデータベースの具体的な違いについてご説明したいと思います。
Pinecone
Pineconeとは、高次元のベクトルデータの扱いに優れた、クラウドネイティブなフルマネージド型のベクトルデータベースサービスです。特長として以下の4つが挙げられています。
- 高性能:低レイテンシーのクエリにより、新しいデータを即座にベクトルデータ化して格納できる
- サーバーレス:需要に応じてスケーリングできる
- 高信頼性:稼働率99.95%のSLAを備えている
- 安全性:データは保存・転送時に暗号化され、ロールと権限管理によりアクセス制御も可能

(出典:Pinecone 「Pincone Database」)
1000万レコードに対する処理速度の図(p50は約半数の割合、p90は約9割の処理速度平均を示す)
特に速度については、1000万レコードのクエリに対して処理時間がおよそ最短16msととても速いです。
そして、Pineconeの最も嬉しいところは無料のStarterプランがあることです!!(参考:Pricing | Pinecone)
Index(ベクトルデータの管理単位、データベース)を最大5つまでしか作れないことや、格納できるデータが2GBまでであるなどの制約はありますが、RAGサービスのPoC利用や小規模でのRAGサービス展開などに非常に有用です。
Index(ベクトルデータの管理単位、データベース)を最大5つまでしか作れないことや、格納できるデータが2GBまでであるなどの制約はありますが、RAGサービスのPoC利用や小規模でのRAGサービス展開などに非常に有用です。
また、Standard以上の有料プランについても、Pineconeではデータの読み込み/書き込み・保存量への従量課金のため比較的安価に導入することが可能です。
一方で、Pineconeは検索アプローチにANN(近似最近傍)検索を行っており、データの中から総当たりで似ているものを見つけるのではなく、関連していそうなグループの中だけを見るため、完全一致のデータではなく十分に近い一致データの発見を目標としています。 簡単に言うと、「時間をかけて100点満点の回答よりも、高速に95点くらいの回答を目指す」という感じでしょうか。 どこかのビジネス本のタイトルにありそうですね。
Knowledge Bases
Knowledge Basesとは、Amazon Bedrockの機能の1つであり、RAGワークフロー全体の実装に役立つ機能を提供するフルマネージド型サービスです。具体的には、参照したいデータを格納したデータソース、ベクトル化したデータを保存するベクトルデータベース、回答を生成する基盤モデル間の連携を自動で行ってくれるため、RAG構築時のユーザの負担をぐっと軽減してくれます。
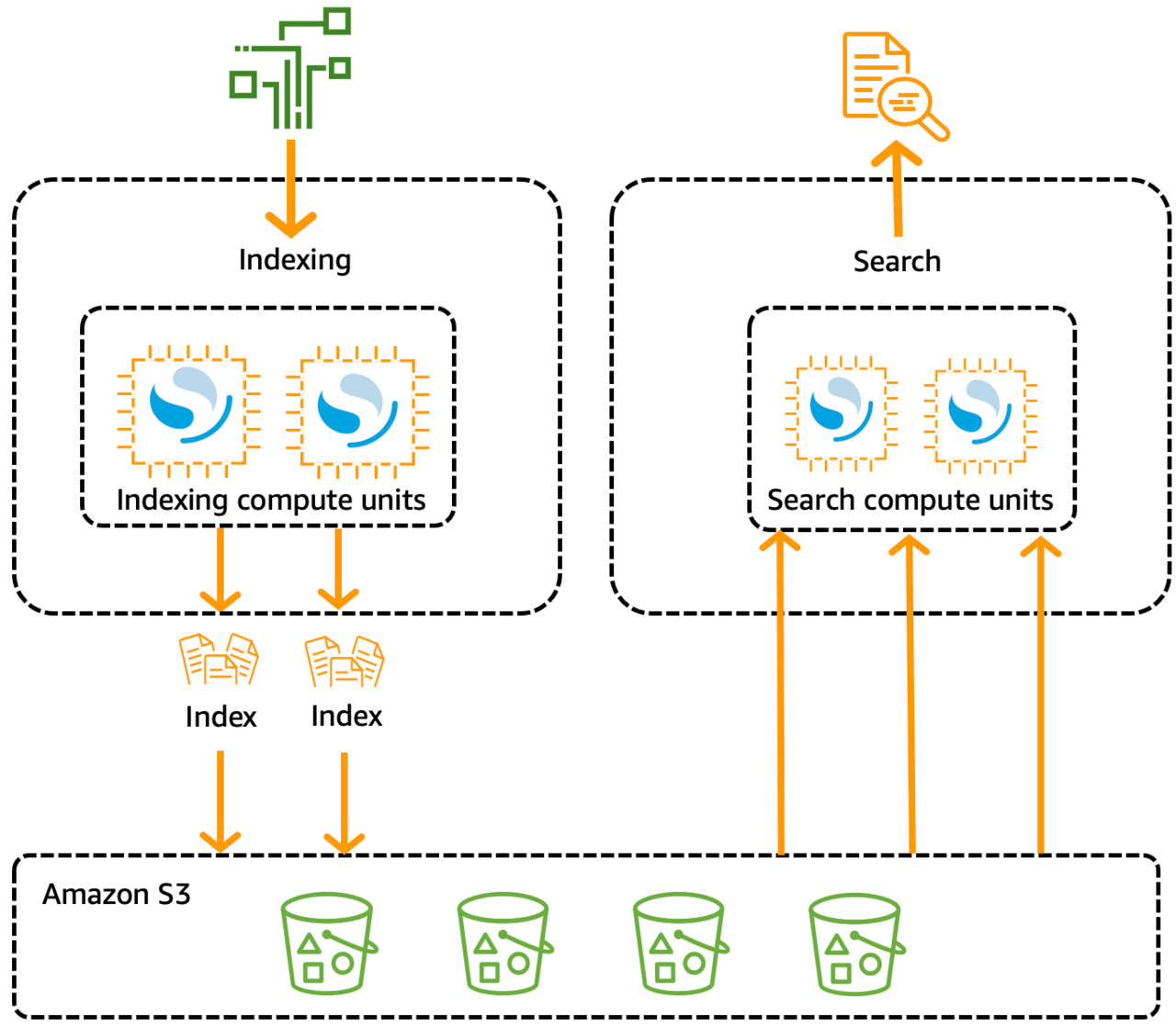
(出典:Amazon Web Services 「Amazon OpenSearch Serverless とは」)
また、Knowledge BasesはAWSのサービスであることから、ベクトルデータベースとしてAmazon Aurora、Amazon Opensearch Serverless、Amazon Neptune Analyticsを選ぶことができ、他にもMongoDB、Pinecone、Redis Enterprise Cloudなど幅広い選択肢から選ぶことが可能です。
ちなみにInfoWeaveでKnowledge Basesを利用する際には、ベクトルデータベースにOpensearch Serverlessが設定されています。Opensearch Serverlessは使用状況に合わせてコンピューティング容量が自動的にスケーリングされるため、低頻度でのサービスの利用や、利用状況の予測が難しい方にとってお得になるそうです!
(参考:Amazon OpenSearch Serverless – Amazon OpenSearch Service)
(参考:Amazon OpenSearch Serverless – Amazon OpenSearch Service)
さて、お得というキーワードが出たところで、皆さんが気になっているであろうKnowledge Basesの利用料金についてですが、Knowledge Bases自体ではなく、使用するベクトルデータベースに対して料金がかかります。InfoWeaveで利用しているOpensearch Serverlessでは、ベクトルデータベース利用時に作成されるOpenSearch Compute Units (OCU) の起動時間に対して課金……つまり、作成から削除までの間に1秒単位で課金されるため、ご利用時には長期に渡るリソースの削除忘れにご注意ください。
(参考:Amazon OpenSearch Service – 料金)
(参考:Amazon OpenSearch Service – 料金)
またOpensearch Serverlessのベクトル検索では、k-NN(k近傍法)を用いており、ベクトルデータベースの中からクエリとの距離が近い=類似しているものを上位からk個探しだす手法を取っています。k-NN検索は、95点を目指すPineconeのANN検索と反対に、全てのデータの中から100点満点の回答を探します。 また、ベクトルエンジンには様々なオプションがあり、条件に応じたフィルタリングなども可能なため、ユーザの利用目的に応じて検索法を調整できるのも魅力かもしれませんね!
(参考:Vector search API – OpenSearch Documentation)
(参考:Vector search API – OpenSearch Documentation)
Amazon Kendra
Amazon Kendraとは、高度な機械学習を利用したエンタープライズ向けのインテリジェント検索サービスです。
「インテリジェントとは?」と私同様に思った方もいらっしゃるかもしれませんが、それは自然言語処理と機械学習の併用により、ユーザの入力クエリから文章の”意図”を汲み取り、最適な検索結果を返すことにあります。 ただのテキスト一致検索ではなく、意図を理解して探してくれるというのは非常に強力なパートナーを得た気分ですね。
(参考:ML 駆動の検索エンジンで企業の情報管理を革新 ! Amazon Kendra をグラレコで解説)
(参考:ML 駆動の検索エンジンで企業の情報管理を革新 ! Amazon Kendra をグラレコで解説)
またAmazon Kendraでは、その豊富なコネクタによりAWS/SaaS/オンプレミスなどの多様なデータソース、構造化/非構造化データなどの多様なデータ形式、36の言語でのキーワード検索など幅広い検索要素に対応しています。 自然言語での検索には、英語、日本語、スペイン語、フランス語、ドイツ語、ポルトガル語、韓国語、中国語の8言語が対応しており、1つのデータソースの中に複数言語の資料があっても検索可能である優秀さです。
そんなに優秀ってことは…
はい、高性能納得のお値段です
Amazon Kendraを利用する際にはIndexという高性能なデータベースを作成する必要がありますが、こちらはKnowledge Basesと同様に作成から削除まで1秒単位で料金が発生します。加えて、Amazon Kendraはその優秀さにつき、Knowledge Basesよりも時間当たりの料金が高くなっています。問い合わせなどの利用した時間ではなく、削除までの”存在時間”に課金されるため、「うっかり削除忘れてた!」なんて時には緊急会議が開かれるかもしれませんので、ご利用にはご注意ください……。
(参考:Amazon Kendra の料金 – Amazon Web Services)
(参考:Amazon Kendra の料金 – Amazon Web Services)
まとめ
いかがでしたでしょうか。 こうして見ると「InfoWeaveはコスト・検索精度においてバランスの良いラインナップを揃えているんだなぁ」と、製品担当者の1人として思いました。検索ロジックに大きな違いがあるというのもとても興味深い点でした。
3つの選択肢のうち中心のものが選ばれやすいというゴルディロックス効果に基づくと、Knowledge Basesが選ばれやすい……なんてことは企業様向けですので無いかもしれませんね。
今回も最後までお付き合いいただきありがとうございました。
暦の上では大寒になりました。一年で一番冷え込む季節、皆さま体調に気を付けてお過ごしください。
暦の上では大寒になりました。一年で一番冷え込む季節、皆さま体調に気を付けてお過ごしください。