
Amazon Athena と AWS Glue を使用して、Amazon S3 上にある CSV データに対してクエリを実行してみたので、その手順をまとめます。
AWS Glue とは
AWS Glueは、Amazon Web Servicesが提供するフルマネージドのETL(抽出、変換、ロード)サービスです。このサービスは、大量のデータを効率的に準備し、変換し、異なるデータストア間で移動させることを目的としています。
Glueを利用するにあたり、登場する用語について簡単に説明します。
- ETL(Extract, Transform, Load):
データを抽出(Extract)し、変換(Transform)し、ロード(Load)するプロセスを指します。AWS GlueはこのETLプロセスを自動化および簡素化するためのサービスです。 - AWS Glue Data Catalog:
AWS Glue Data Catalogは、メタデータを管理するための中心的なサービスです。データストアのスキーマ情報、データの場所、その他のメタデータを保持し、データの整理と管理をサポートします。 - AWS Glue データベース:
AWS Glueデータベースは、Data Catalog内でテーブルをグループ化するための論理的なコンテナです。データベースはスキーマを含んでおり、データの整理とスキーマの一貫性を保つために使用されます。 - AWS Glue テーブル:
AWS Glueテーブルは、データとその構造に関するメタデータを表します。通常は特定のデータセットのスキーマ情報を含み、データドリブンなアプリケーションで使用されます。 - クローラー:
クローラーは、自動的にデータソースを探索し、データカタログにメタデータを登録するためのコンポーネントです。クローラーはデータの構造を解析し、テーブル定義を生成または更新します。 - AWS Glue ジョブ:
AWS Glueジョブは、ETL(抽出、変換、ロード)プロセスを実行するための基本単位です。ジョブを作成して、データを変換し、必要な出力先にロードすることができます。 - AWS Glue 接続:
AWS Glue接続は、Glueがデータストアにアクセスする際の接続情報を保存します。ホスト名、ポート番号、認証情報などが含まれ、データアクセスを安全かつ効率的に行えます。
Amazon Athena とは
Amazon Athenaは、Amazon Web Services(AWS)が提供するサーバーレスのインタラクティブクエリサービスです。Athenaを使用すると、Amazon S3に保存されているデータに対して直接SQLクエリを実行し、複雑なETLプロセスを必要とせずにデータを分析できます。
Amazon Athenaには、以下の特徴があります。:
- サーバーレス: Athenaは完全にサーバーレスであるため、インフラストラクチャの管理が不要です。ユーザーはクエリの実行に対してのみ料金を支払います。
- SQLサポート: Athenaは標準SQLを使用してクエリを記述できるため、SQLに精通したユーザーが簡単に利用できます。
- データソースのサポート: 主にAmazon S3に保存されたデータに対してクエリを実行しますが、Athenaを他のデータソースに接続することも可能です。
- 使いやすさ: ノードやクラスタの管理が不要で、クエリを書くだけでデータ分析を始められます。
- 統合機能: Amazon QuickSightなどの他のAWSサービスと統合しやすく、ダッシュボードを通じたビジュアル分析が可能です。
- データ形式のサポート: AthenaはCSV、JSON、ORC、Avro、Parquetなど、さまざまなデータ形式に対応しています。
これらの特徴により、Amazon Athenaはデータアナリストやデータサイエンティストにとって、スピーディーで効果的なデータ分析ツールとなっています。
やってみた
AWS Glue
1.データベースの作成
まずはクローラの出力先となるデータベースを作成します。
ここでは名前のみ指定しました。

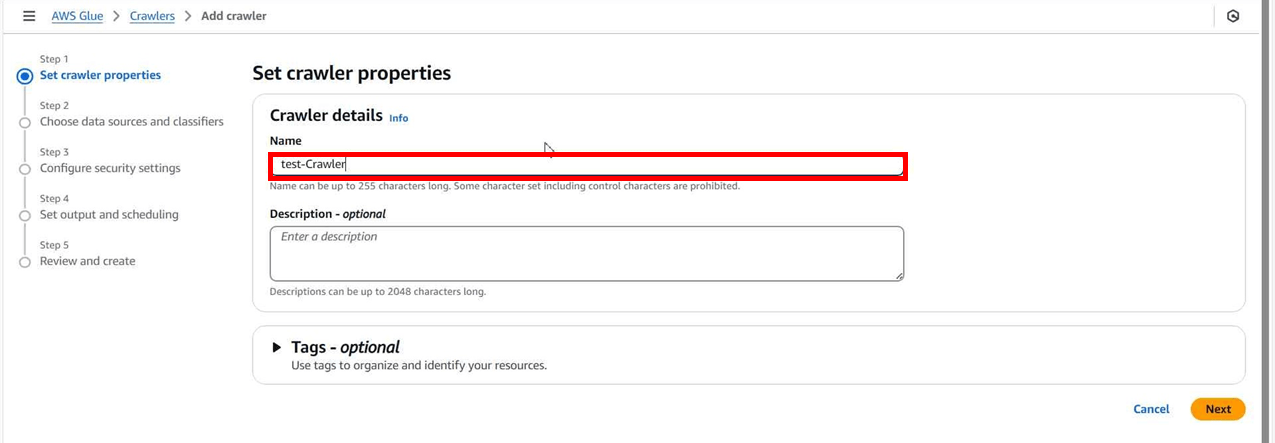
2.クローラーの作成
クローラーの名前を入力します。
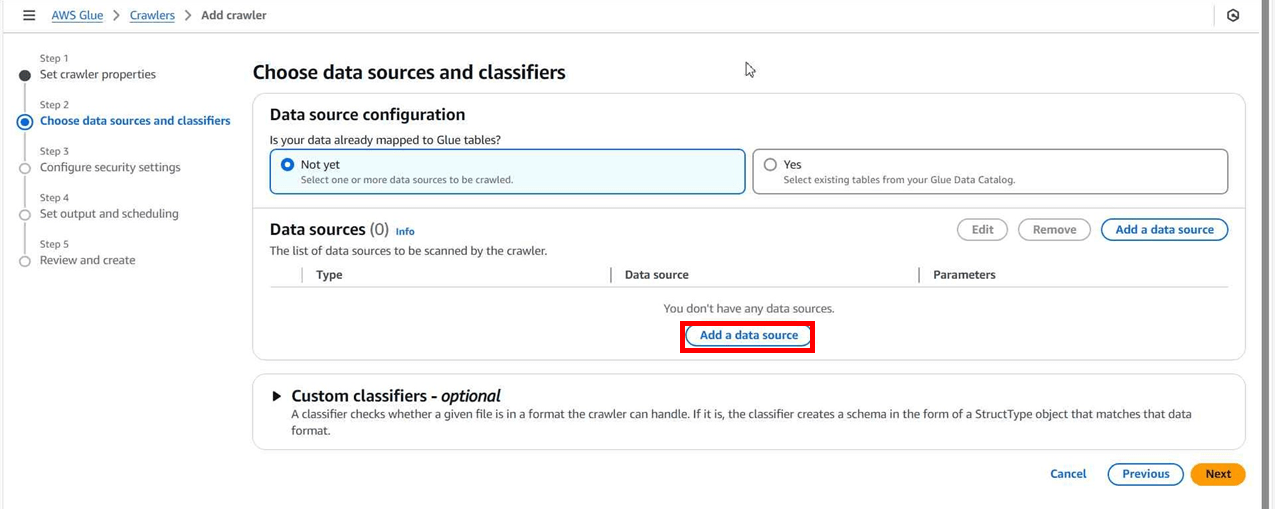
「Add a data source」からデータソースを指定します。
今回はS3のデータを利用したいので、データを配置したS3のパスを指定します。
また、「Subsequent crawler runs」では、クローラーの再実行時にどのフォルダをクロールするかを選択できます。
今回は、全て再クロールする「Crawl all folders」を選択しました。
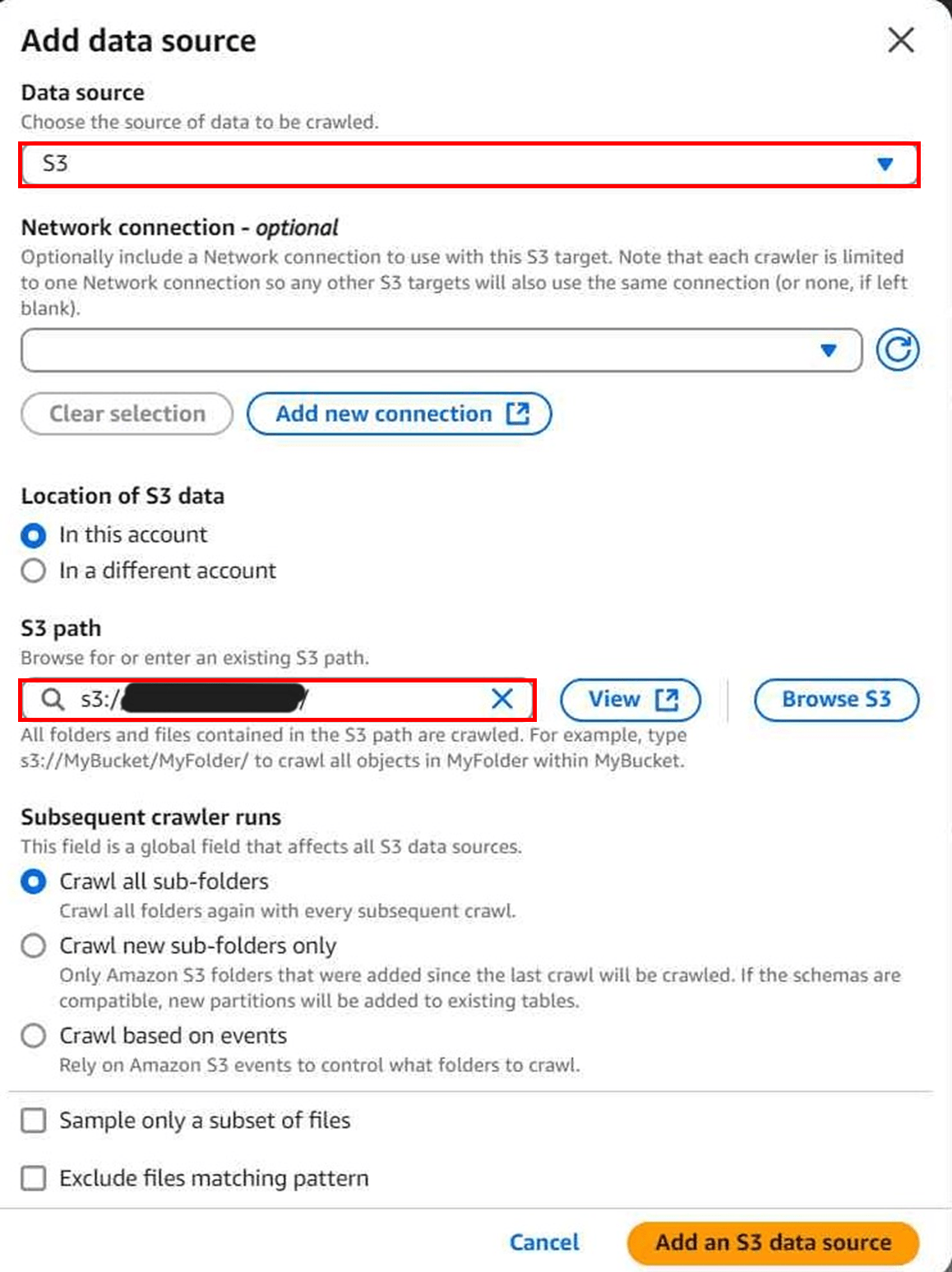
データソースを指定できたら「Next」へ進みます。
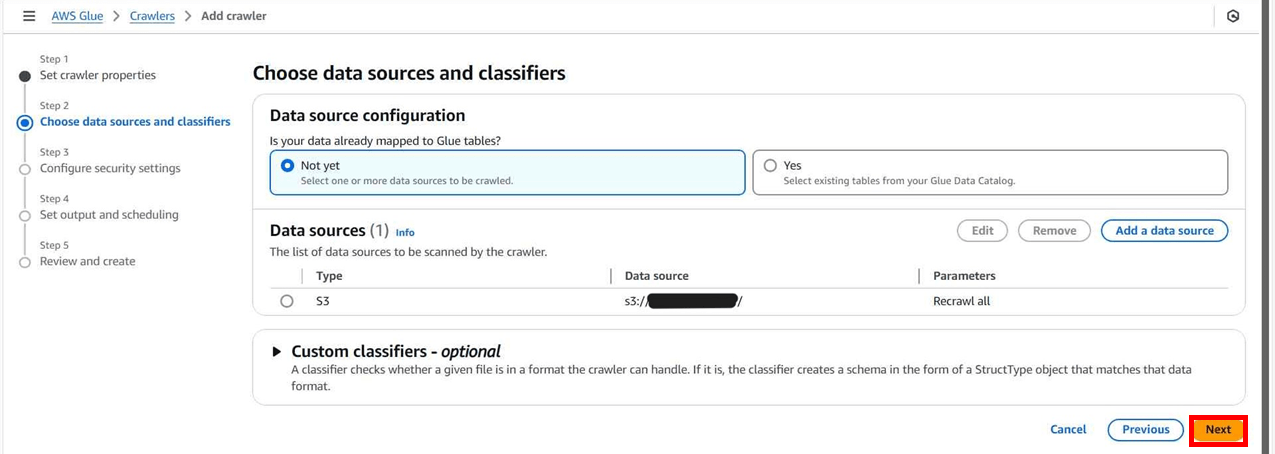
IAMロールを選択します。
今回は「AWSGlueServiceRole」およびソースデータを配置したS3へのアクセス権限を付与しました。
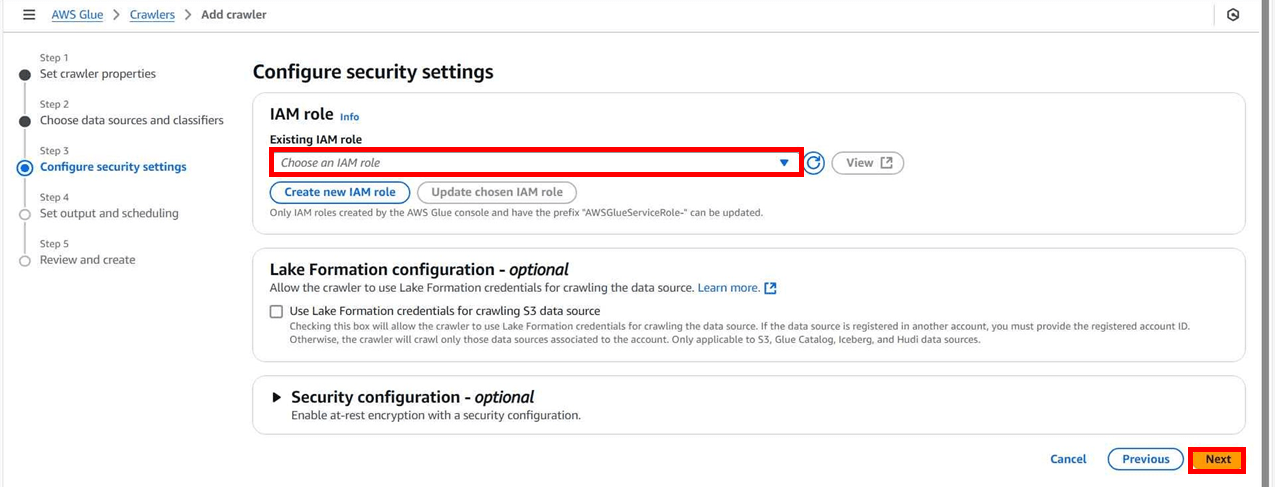
クローラの出力先を指定します。
「1.データベースの作成」で事前に作成したデータベースを指定します。
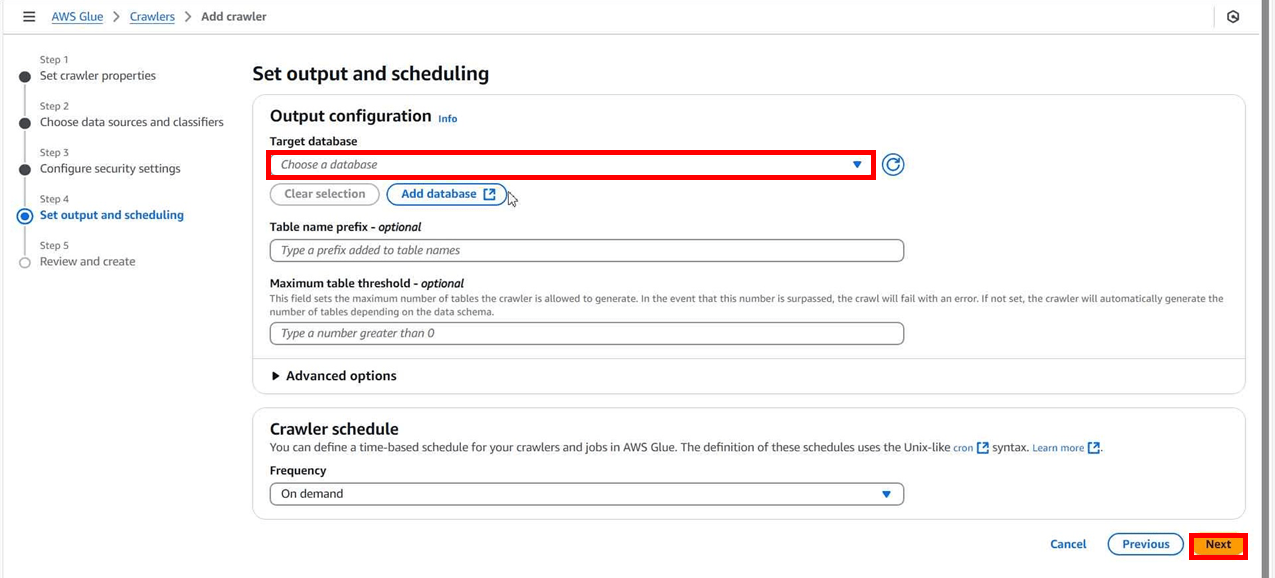
設定に問題がなければ「Create crawler」をクリックします。
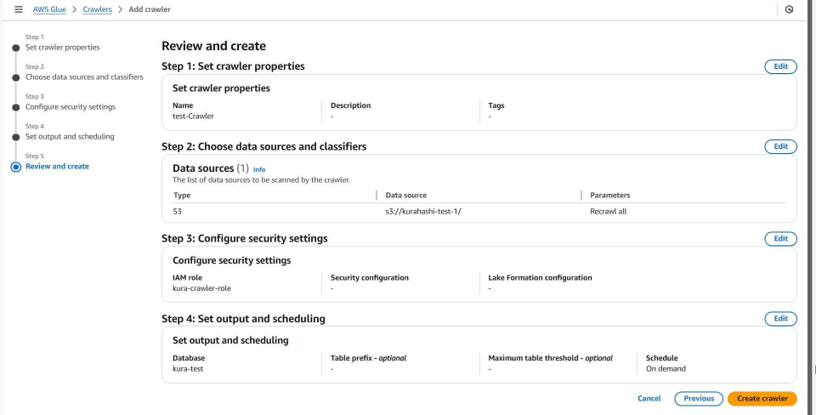
以上でクローラの作成は完了です!
3.クローラの実行
早速クローラを実行してみます。
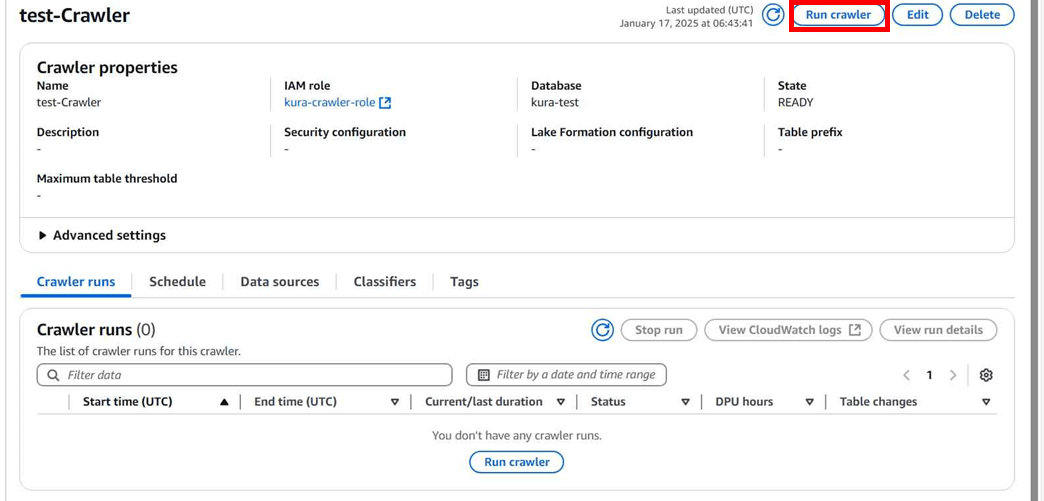
作成したクローラの詳細画面から「Run crawler」クリックします。
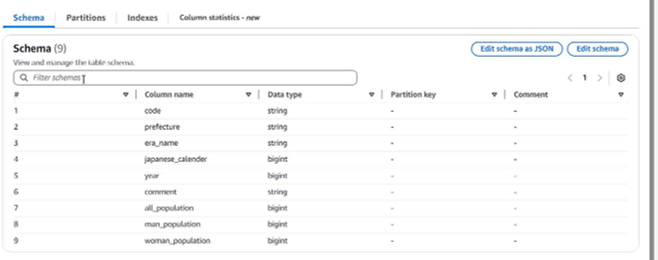
出力先に設定したデータベースを確認すると、クローラによりS3上のデータが自動で読み取られ、構造化されたインデックスがカタログ(Glue Data Catalog)として保存されています。
Amazon Athena
クエリの実行
Athenaでクエリを実行してみます。
Athenaでのクエリ実行時に、データベースにGlue Data Catalogのデータベースを指定することで、データベース内のテーブルやテーブル内の項目名を使うことができます。
データソース欄で「AWSDataCatalog」を指定すると、データベース欄からGlueで作成したデータカタログ内のデータベースが選択できます。
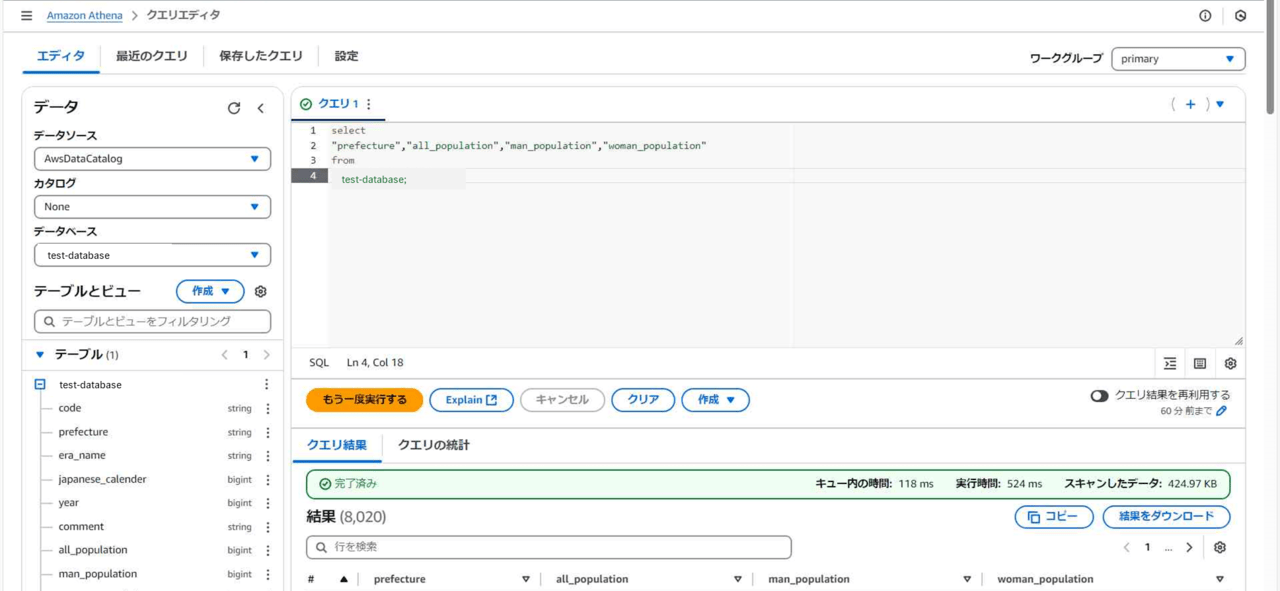
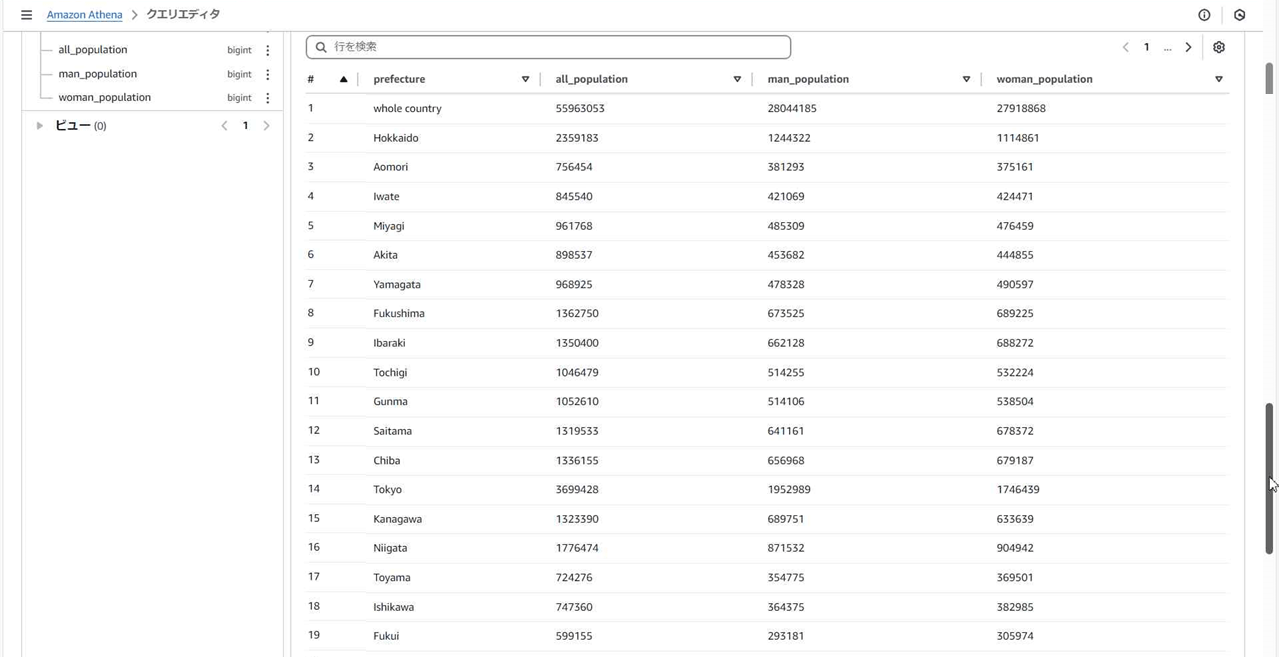
クエリを実行してみました。
select文を実行して、テーブル内の項目を抽出することができました!
さいごに
S3のデータをGlueでデータベースに格納して、Athena で必要なデータを取得するまでの手順をまとめました。Glueを利用することで簡単にS3上のデータを構造化し、容易に必要な値を取得することができました。
次回はAthenaのデータをQuickSightに連携し、可視化してみたいと思います。