
こんにちは!SCSKの野口です。
前回のプロローグでは、AP基盤ドキュメントに「必要な情報へたどり着きにくい」という課題があり、RAGで“探すコスト”を下げられないか、という問題意識を共有しました(連載の背景は前回のプロローグ記事をご覧ください)

本連載は4シリーズ構成で、今回から始まるシリーズ1では、RAGを実装手順ではなく「構成要素と設計判断」として理解するための基礎を整理します(RAG/チャンキング/評価/ベクトルDB/ハイブリッド検索/課題)。
第1回の本記事では、RAGの定義、必要性、基本フロー(Indexing / Retrieval / Augmentation / Generation)を俯瞰し、次回以降の議論の土台を作ります。
それでは早速、RAGとは何かから見ていきましょう。
RAGとは
RAG(検索拡張生成:Retrieval-Augmented Generation)とは、LLMが回答を生成する直前に、信頼できる外部データソースから関連情報を検索(Retrieval)し、その結果をコンテキストとして付与(Augmentation)したうえで回答を生成(Generation)させるアーキテクチャです。これはモデルの重みを更新する「ファインチューニング」とは異なり、推論時に動的なコンテキストを提供する「検索」と「生成」のハイブリッドソリューションとなります。
図解してみると下記のようになります。
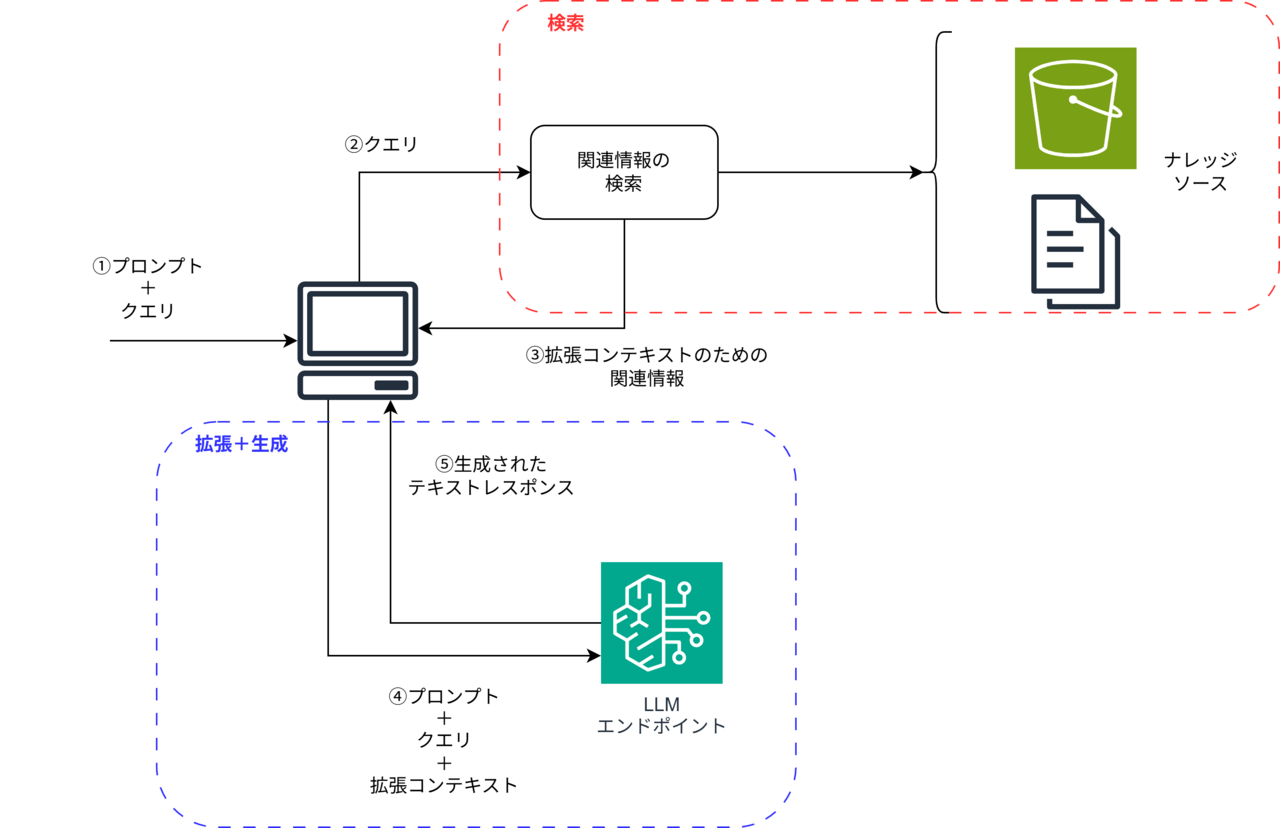
要点は、LLMのパラメータに内蔵された知識だけに依存せず、推論時に必要な情報を動的に取り込む点にあります。AWSブログでも、RAGについて下記のように説明されています。
(原文)
It allows LLMs to reference authoritative knowledge bases or internal repositories before generating responses, producing output tailored to specific domains or contexts while providing relevance, accuracy, and efficiency.(日本語訳)
RAGにより、LLMは応答を生成する前に信頼できる知識ベースや内部リポジトリを参照できるようになり、関連性、精度、効率性を維持しながら、特定のドメインやコンテキストに合わせた出力を生成します。
なぜRAGが必要か?
LLMは非常に汎用的ですが、業務適用で問題になりやすい制約があります。
いくつかの例を挙げてみましょう。
- 答えがないにも関わらず、虚偽の情報を提示すること
- ユーザーが最新の応答を期待しているにも関わらず、古い情報を提示する
- ユーザーが社内規約などの特定の情報に関する応答を期待しているにも関わらず、一般的な情報を提示する
上記の例はつまるところ、下記のような問題が発生しているということです。
- ナレッジカットオフ:モデルが学習した時点以降の出来事や、更新された規定・仕様をそのまま反映できない
- ハルシネーション:根拠がない内容でも、それらしく断定してしまう
- 社内固有情報の欠如:社内情報・手順書・契約・設計資料など、非公開データを参照できない
RAGはこれらの課題を解決するための1つのアプローチです。信頼できるドキュメント等をナレッジソースとして保存しておき、LLMへの問い合わせを行う前にこれらのナレッジソースから関連情報を取得します。ユーザーは信頼できるドキュメントから得られた情報に基づいて生成された回答を受け取ることができます。
RAGの基本フロー
RAGは大きく4つの工程に分解することができます。
インデックス作成(Indexing)
文書を検索しやすい単位に分割し(チャンキング)、埋め込み(Embeddings)に変換して保存します。
文書の分割粒度(どの程度のチャンクサイズとするか?)、文書構造の扱い(階層構造に意味を持たせるか等)、メタデータ付与など、ここでの設計が後続の検索品質に大きく影響します。
チャンキング手法・Amazon Bedrock Knowledge Basesで利用できるチャンキング戦略などについては別記事で詳しくまとめる予定ですので、そちらを参照いただければ幸いです。
検索(Retrieval)
ユーザーの質問(クエリ)も埋め込みに変換し、意味的に近いチャンクを取得します。
このときにどの程度のチャンクを取得するかも回答品質に影響を与えます。単純に多くのチャンクを取得すればよいというわけではありません。取得したチャンクが全てユーザーのクエリに強く関連するものであれば問題ありませんが、そこまで関連性がないチャンクを取得してしまい、ユーザーが求めていた回答が得られない可能性もあります。
そのため、何件のチャンクを取得するかも重要な設計項目となります。
なお、「あえてRAGからの取得時は多くのチャンクを取得しておき、リランキングによって絞り込む」といった設計も可能となります。
こちらの詳細は下記ブログに書かれているので、一度目を通してみてください。

コンテキスト構築(Augmentation)
取得したチャンクから、重複除去・整形・並べ替えなどを行い、LLMに渡すコンテキストを組み立てます。
生成(Generation)
コンテキストと質問(クエリ)に基づき、LLMが回答を生成します。
重要なのは、回答がコンテキストに接地(Grounding)していることです。
詳しくはAmazon Bedrockの下記ユーザーガイドでご確認ください。

RAGと似た概念とその違い
RAGと似た概念として、「ファインチューニング」があります。
- ファインチューニング:モデルの重み(パラメータ)を更新し、出力スタイル・形式・判断の癖を学習させる
- RAG:外部知識(ナレッジソース)を検索し、推論時に動的に与えて正確性・最新性・組織固有性を補う
上記からも分かる通り、ファインチューニングには学習させるための計算コストがかかりますが、RAGは外部知識をつなげるだけなので、ファインチューニングよりもコストが低くなります。
IBMの記事では、RAGとファインチューニングの比較を料理人に例えて比較しています。
(RAG)
RAGを概念化するために、AIモデルをアマチュアの家庭料理人と想像してみてください。彼らは料理の基礎は知っていますが、特定の料理の訓練を受けたシェフの専門知識(組織独自のデータベース)が欠けています。RAGは、家庭料理人にその料理のレシピ本を提供するようなものです。料理に関する一般的な知識と料理本のレシピを組み合わせることで、家庭料理人は自分の好きな料理に特化した料理を簡単に作ることができます。(ファインチューニング)
もう一度、生成AIモデルを家庭料理人に例えると、ファイン・チューニングは特定の料理を作るためのコースとなります。コースを受講する前に、家庭料理人は料理の基礎について大まかな理解をしておく必要があります。しかし、料理の訓練を受けて分野特有の知識を習得すれば、その種類の料理をもっと上手に作れるようになるでしょう。引用元:https://www.ibm.com/jp-ja/think/topics/rag-vs-fine-tuning
RAGとファインチューニングの比較表です。
| 比較項目 | RAG | ファインチューニング |
|---|---|---|
| 主な目的 | 最新知識・情報の補強 | 回答スタイル・形式の習得 |
| コスト | 低い(既存モデルをそのまま活用) | 極めて高い(再学習に莫大な計算資源が必要) |
| 情報の更新頻度 | リアルタイム(外部データを差し替えるだけ) | 遅い(再学習に数日〜数週間かかる) |
| 根拠(出典)の提示 | 明確に提示可能(引用へのリンクをつけるなど) | 困難(モデルの記憶に依存するため) |
| 専門性 | 特定のドキュメントに強い | 専門的な口調や特定形式の出力に強い |
RAGで重要な設計論点(どこで品質が決まるか)
RAGで難しいのは、LLMの性能ではなく、取り込み・分割・検索・コンテキスト設計など“前段”で品質が大きく変わる点です。特に次の観点はRAGにおいて非常に重要です。
- データ取り込み(Parsing / 整形)
表やPDF構造が崩れると、正しい情報が検索に乗りません - チャンキング(チャンク化)
チャンキングが大きすぎても小さすぎてもだめです。ユースケースに応じて適切なチャンキング戦略を考える必要があります - 検索(Retrieval)
top-kの取り方(いくつのチャンクを検索するか)、ハイブリッド検索、リランキングで適切な情報を「拾える / 拾えない」が変わります - コンテキスト構築(Augmentation)
重複除去・並び順・引用の付け方で、LLMが参照できる根拠が変わります - 生成制御(Generation)
接地(Grounding)と棄却(わからないときは答えない)を設計しないと、もっともらしい誤答(ハルシネーション)が残ります - 評価(Evaluation)
改善できているかを定量的に評価しなければ、主観的な評価のみとなってしまいます
次回記事では、上記の「チャンキング(チャンク化)」を取り上げ、チャンク化戦略と選択方法を整理します。
まとめ
本記事では、RAG(検索拡張生成)を「外部データソースを検索し、その結果をコンテキストとして付与して回答を生成する」仕組みとして整理しました。LLM単体では難しい、最新性・正確性・社内固有情報の参照を補ううえで有効なアプローチです。
また、RAGの品質はLLMの性能だけではなく、データ取り込み・チャンキング・検索・コンテキスト構築・生成制御・評価といった設計要素の組み合わせで決まります。
次回は、この中でも影響が大きい「チャンキング(チャンク化)」を取り上げ、チャンク化戦略と選択方法を整理します。
次回もぜひご覧ください。