
SCSKの畑です。
前回エントリの後編として今回はバックエンド側のサービスを対象に解説します。
前回の記事はこちら

アーキテクチャ図
いつものやつです。図内に注釈もあるので、各サービスの役割は何となくご理解いただけるものかと思います。
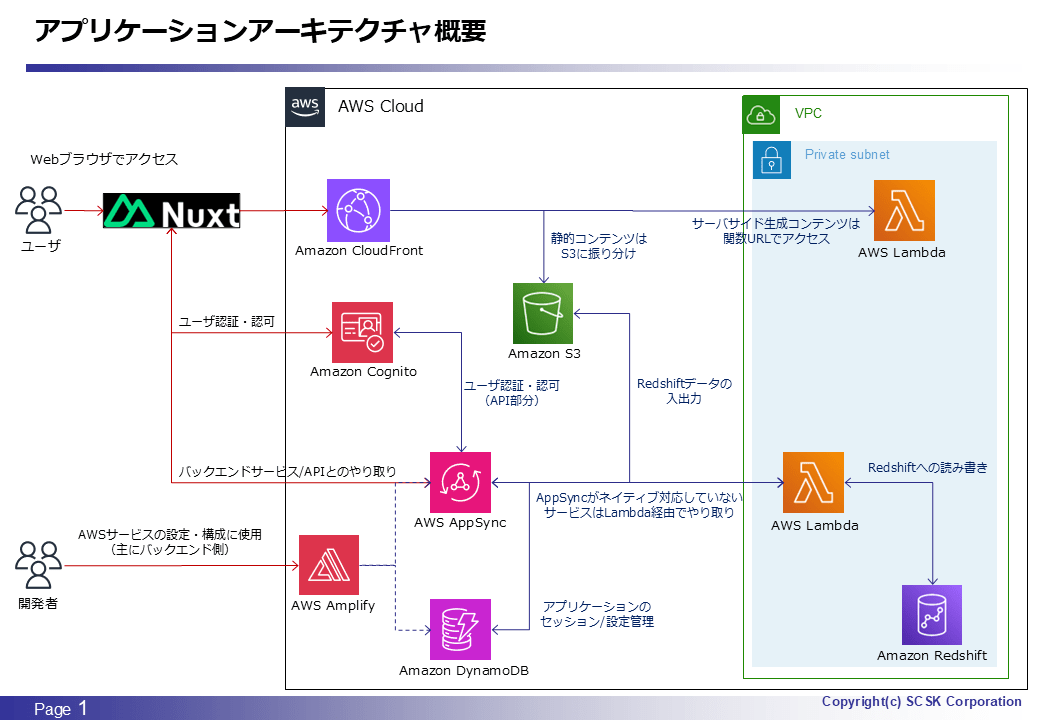
バックエンド側のサービス
以下の項目がバックエンド側のサービスになります。Lambda/S3 についてはバックエンド側でも活用しているので両方に出てきます。また、Redshift については本アプリケーションでの管理対象という位置づけのため、本エントリでは直接的には触れません。Redshift に関するネタは幾つかありそうなので、またその際に。
- AWS Amplify
- AWS AppSync
- Amazon Cognito
- Amazon DynamoDB
- AWS Lambda
- Amazon S3
なお、AppSync/Amplify/Cognito あたりは他のエントリでも色々な内容を取り上げていることもあり、重複するような内容は適宜割愛しています。このため、全般的に本アプリケーションにおけるサービスの使用理由や所感などが中心の内容となっており、前編とは若干様相が異なりますがご了承ください。(詳細な内容に踏み込むと分量が多くなってしまい、バランスが悪くなるので・・)
AWS Amplify
これまでのエントリで何回もメイントピックとして取り上げていますが、具体的な構成管理対象は10回目のエントリに記載した通り AppSync と DynamoDB の2つです。実質的にはほぼ GraphQL Transformer を使って AppSync を構成・デプロイするためだけに使用したと言ってよく、その用途だと自然にこの2つが対象になりました。Lambda や Cognito を管理対象としていないのも同エントリの通り、細かい設定ができない&お客さん環境で Amplify を使用できないためです。
正直なところ、今回のような使用方法だと、GraphQL Transformer なり codegen で Javascript/Typescript 用のクライアント SDK を生成する機能がローカルから使用できれば十分だったのですが、調べた限りはそのように使用できそうにはありませんでした。普通は CI/CD 機能までセットで使用することになるというか、それをメリットと感じて使用するケースが多いと思うので、上記のように使いたいというモチベーション自体が珍しいのだとは思いますが・・
AWS AppSync
こちらに至ってはほぼ毎回のエントリで何かしら取り上げていますが、一部ビジネスロジックを含むアプリケーションのバックエンド処理をほぼ全て任せるような使い方をしています。概要図の通り、DynamoDB は 一部処理を除いて(Amplify によって構成した)AppSync のリゾルバにより直接やり取りしていますが、それ以外のサービス(S3/Redshift)については全て Lambda 経由でやり取りしています。
理由は単純で、AppSync が対応していないデータソースであり、自前でそれらの HTTP エンドポイントとやり取りするようなリゾルバを実装するのは、開発時点でのスキルやコストを鑑みるとハードルが高いと感じたためです。今振り返っても、Lambda 上で実装している処理の内容的に、AppSync のリゾルバ側に移管できる内容は数割程度かなと思います。例えば、Cognito からユーザ/グループ情報を取得してくるような処理などは実装できると思いますが、Redshift とのデータやり取りになってくると Lambda レイヤー経由で様々なライブラリを使用していたりするので、おそらく実装は無理だろうなと。機能的に AppSync JS がもっと充足してくればあるいはという感じでしょうか。

というか、RDS に対応してるなら Redshift にも対応してくれてもいいのにと思わなくもない・・のですが、DWH (Redshift) とのやり取りとなると一般論としてデータ量が大きくなることが想定されることを考えると、AppSync の特徴や用途に適さないために対応していないということなのかなと。。
Amazon Cognito
本アプリケーションのユーザ/グループを管理するために使用しています。詳細は2回目のエントリで説明していますが、本アプリケーションを使用するためには Cognito によるユーザ認証・認可が必要であり、ユーザプールに紐付けた ID プールの「認証されたアクセス」経由で付与される IAM ロールの権限を以ってアプリケーションを使用します。
こちらは正直あまり書くことがないので余談寄りの話題になりますが、当初はユーザ/グループのメンテナンスに際してアプリケーション側に管理画面を作る想定はありませんでした。ただ、思ったより AWS マネジメントコンソールの画面が使いづらいところがあり、手順に落としてもやや冗長な内容になってしまうことから、お客さんからの要望もあってアプリケーション側で管理画面を作ることになりました。設定手順自体はさておき、運用管理を考えるとユーザ一覧における任意項目でのソートとか、ユーザ一覧のエクスポートくらいはできても良いんじゃないかと思ったりします。(検索はできますが・・)
Amazon DynamoDB
アプリケーション用のデータベースとして使用しています。概要図にも記載がありますが、具体的な用途としては以下3つです。前者2つの用途は、本アプリケーションにおけるメンテナンス対象の Redshift テーブル、及び実行対象の ETL/ELT ジョブネット(ステートマシン)をターゲットとしています。
- セッション/ステータス管理
- オペレーションログ出力
- アプリケーションマスタ(設定)
排他制御に関するエントリでも少し言及した通り、DynamoDB 自体を積極的に採用したというよりは、Amplify/AppSync と連携して容易に開発ができ、かつ一般的に RDBMS で備えているような機能性を持つサーバレスサービスである、という特徴から選んだような感じです。もちろん DynamoDB は本質的に KVS (Key Value Store) であり、Oracle や PostgreSQL などの RDBMS とは色々な相違点がありますが、上記のような用途においては KVS で十分でした。
最も今振り返ると、結果的にそうだった部分もあるのは否めないところです。特にテーブルの論理設計については、広野さん執筆の以下エントリなどを事前に読んでおくべきだったかもしれません。このあたりは開発時の経緯などもあるのですが、実装しながら設計を拡張していけるのが KVS/スキーマレスの良いところでも悪いところでもあると実感できました。幸いにも、本アプリケーションの実装においては良いところを享受できた割合の方が大きかったと思っています。

一方、初めて本格的に扱ったサービスであるということもありちょこちょこ躓いた点もあったため、以下にまとめてみました。本当に大した内容ではないというか、本当に初学者のような内容ですが・・
- パーティションキーの定義変更は不可能であり、変更するためにはテーブルの再作成が必要なこと
- パーティションキーに指定している列の名前を変更したかったのですが、それもパーティションキーの定義に当然ながら含まれるということで再作成が必要となりました。今考えると DynamoDB のテーブル作成時にパーティションキーを指定する必要がある時点で、何となくそういう仕様になっていることは察せられた気もします。
- 1項目あたりの最大データ量が 400KB であること
- 実装最初期はメンテナンス対象のテーブルデータ自体を DynamoDB の項目として保持するような設計としていたのですが、この制限に引っかかったため断念しました。今振り返るとあまり筋の良い設計ではなかったので、早々に方針を転換できたことは良かったと思っています。仮に数 MB 程度だった場合はそのまま進めていたかもしれません・・
AWS Lambda
AppSync の項目で記載した通り、主に Redshift/Cognito とのやり取りする機能の開発に使用しています。ランタイムは実装コストを重視して慣れている Python としました。特に Redshift とのやり取りにおいて Pandas ライブラリを使用したかったというのも理由の一つです。
詳細な内容については Lamdba ごとの各論になってしまう部分がありますが、今回の構成のように AppSync のデータソースとしての用途では思ったより大分扱いやすかったです。AppSync からの入力がどのように event に入ってくるかを調べるのが少し手間だった程度で、出力については GraphQL のスキーマ定義通りに入れてあげればそのまま AppSync 側で受け取ってくれるのでラクでした。Lambda 側での例外発生時も、例外をそのまま AppSync に渡すだけであれば特別な工夫は不要でした。(Lambda から例外を raise すれば、それをそのままフロントエンド側にも渡してくれる)
逆に、Lambda をオンライン機能のバックエンド処理用として扱う場合によく問題として挙げられる、コールドスタート発生時のレスポンス悪化も実感したところです。本アプリケーションの用途を鑑みると大きな問題ではありませんが、回避策が実質的な常時起動 (Provisioned Concurrency) となってしまうのはサーバレスの思想/メリットから遠ざかってしまうという点で悩ましいですね。。

もし別案件で Amplify を使用しない方針とした場合は、ダイレクト Lambda リゾルバについても試してみたいところです。
Amazon S3
バックエンド側では、Redshift ⇔ アプリケーション間のテーブルデータのやり取りにおけるデータの(一時)保管場所として使用しています。つまり、実質的にアプリケーションが読み書きするのは S3 上のデータとなり、7回目のエントリでも触れたように AppSync/Lambda を通してアプリケーション ⇔ S3 ⇔ Redshift 間でデータのやり取りをするようなアーキテクチャとなっています。
当初は S3 を間に挟む予定はなかったのですが、以下の理由によりこのような構成としました。
- 前編で記載した以下のアプリケーション機能を実装するにあたり、テーブルデータを保持しておく場所が必要だったため
- アプリケーションのメンテナンス対象テーブルの(データ)バージョン管理機能
- アプリケーション経由でテーブルデータを更新する際の簡易ワークフロー機能
- Redshift のテーブルデータを COPY 文で更新するにあたり(厳密には truncate -> insert)、COPY 対象のデータを S3 などの外部データストアに配置する必要があったため
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_COPY.html#r_COPY-syntax-overview-data-source
もちろん、上記理由のみだと他の選択肢も取れたのですが、全体としての扱いやすさやお客さん環境での作成におけるハードルの低さも鑑みて S3 を使用することにしました。結論としては良い選択ができたと思っています。
まとめ
バックエンド側の話は別エントリのネタとして適宜消化していることもあり、そんなに書けることないかなと思っていたのですが思っていた以上に捻り出せました。アーキテクチャとしては最初からある程度固まっていたように思えていたのですが、振り返ってみると色々あったなあというのが正直な感想です。
本記事がどなたかの役に立てば幸いです。