

こんにちは。SCSKの松渕です。
Google Cloud Data & AI Summit ’25 Springに参加してきたので、イベントの内容と感想を投稿します。
セッションはピックアップしてお届けいたします!
Google Cloud Data & AI Summit ’25 Springとは
このイベントは、Google Cloudが主催するデータ分析と人工知能に関するイベントです。最新のGoogle CloudのデータおよびAIテクノロジーの発表、成功事例の共有、専門家によるセッション、そして参加者間のネットワーキング(懇親会)が提供されます。
会場は渋谷ストリームにあるGoogleオフィスで、活気に満ち溢れ、最新技術への期待感と熱気が充満していました。
イベントレポート
Opening セッション
タイトル:生成 AI はデータドリブン経営の救世主か? ~ Google Cloud が考える Data x AI、ビジネス プロセスの融合
発表者:GoogleCloud
内容
日本のデータドリブン経営は64か国中64位というショッキングな数字のスライドから発表スタート。

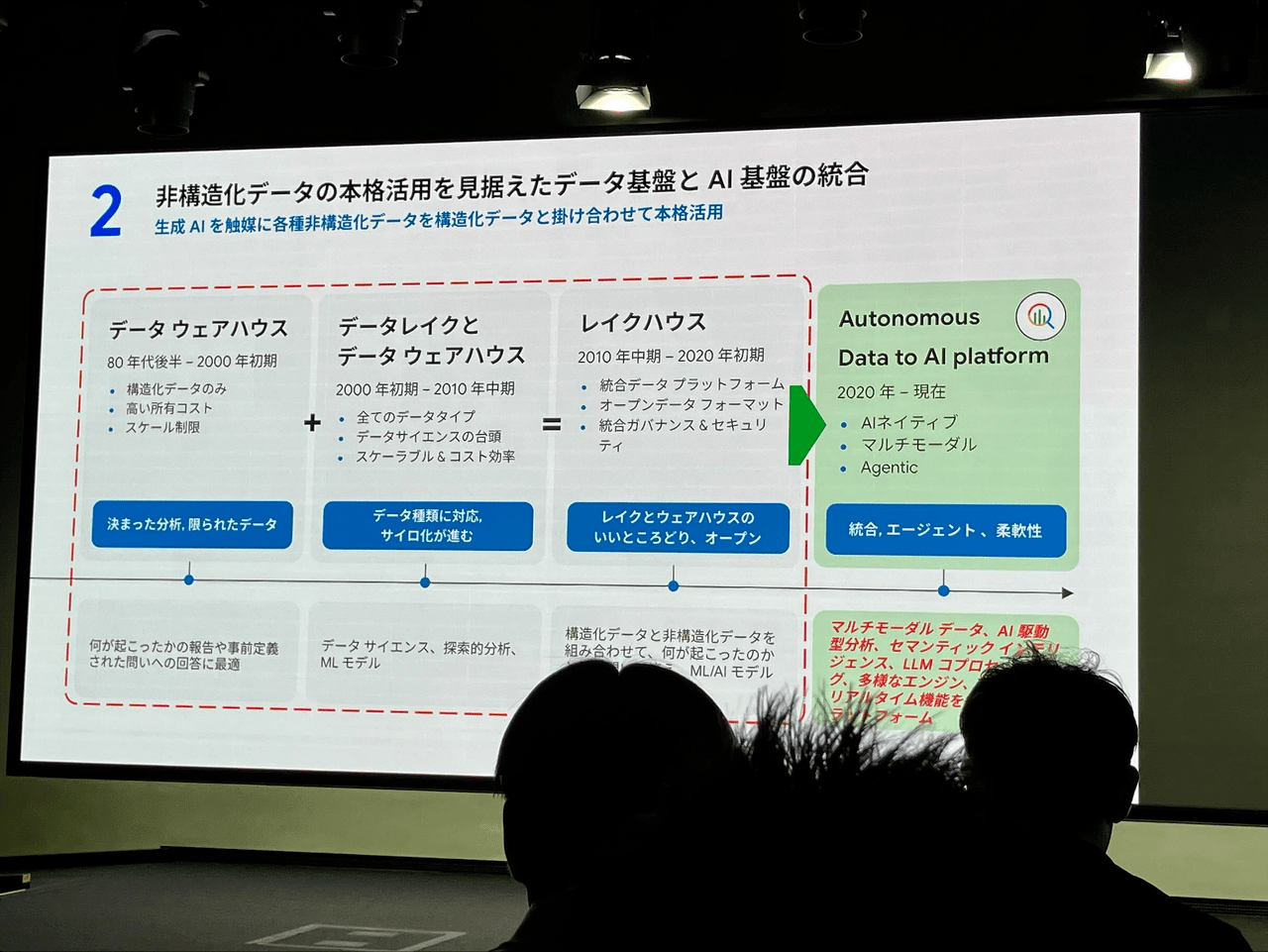
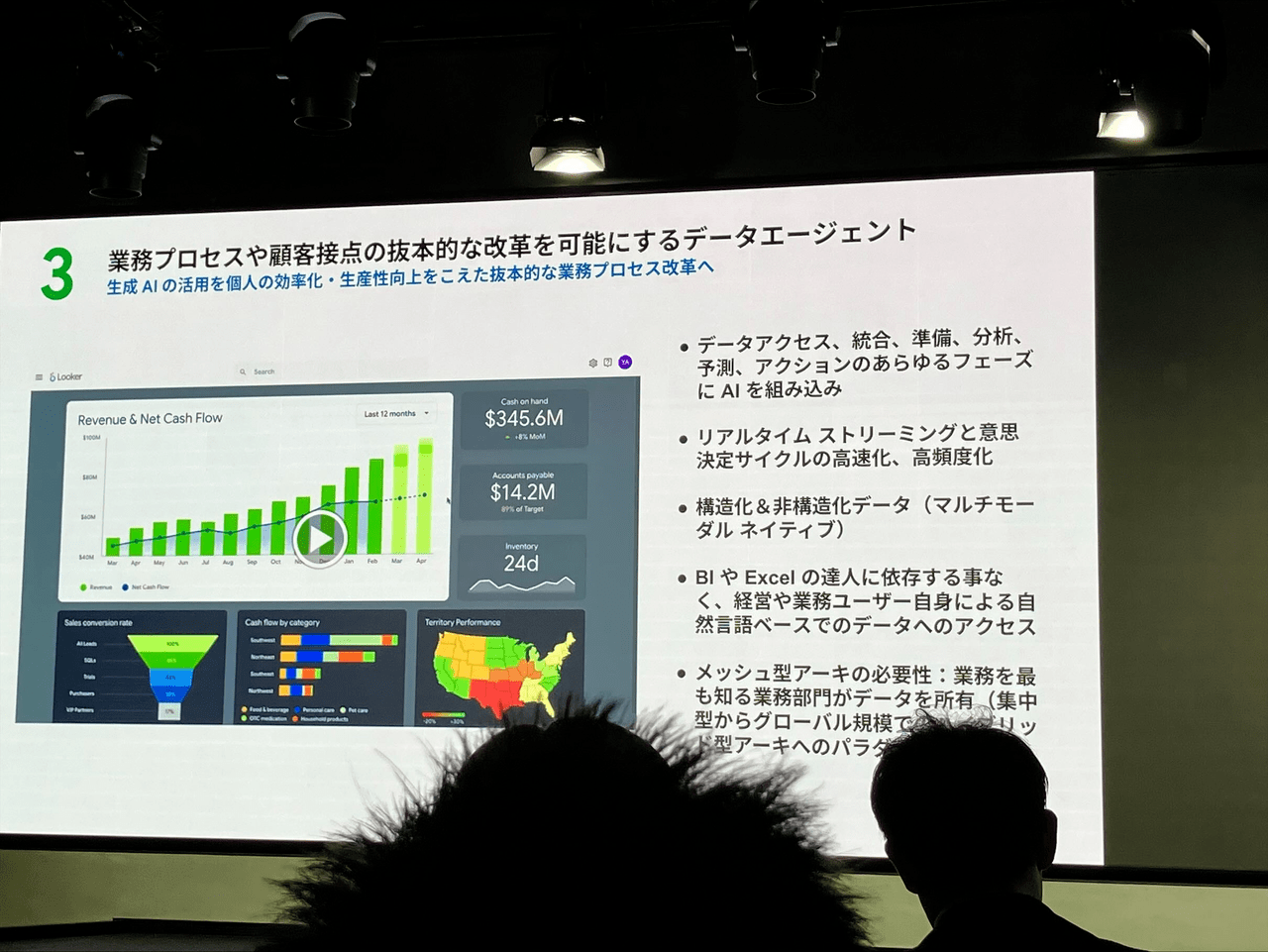
LLMがコモディティ化する中で、鍵となるのは強固なデータ基盤であり、各企業のデータがビジネスの源泉となることが強調されました。生成AIを個人の業務効率化に留まらず、抜本的な業務プロセス改善に繋げるためには、以下の3つの要素が重要であると提言されました。
① Real-Time (リアルタイム性): VUCA(変動性、不確実性、複雑性、曖昧性)の時代において、最新データに基づいたタイムリーな判断が必要不可欠であり、Googleはそのため多数のツール/サービスを提供していることが紹介されました。
② MultiModal (マルチモーダル対応): 企業活動において生成されるデータの約80%が非構造化データであるという現状が示され、そのためマルチモーダルに最初期から対応しているGeminiと、それとシームレスに連結できるGoogle Cloudに大きなメリットがあることが説明されました。
③ Agentic (エージェント性): 多数のインプット箇所からのデータ統合、データのクレンジングや複雑なデータ分析、将来のデータ予測などをAI Agentを活用して自然言語で実施できる体験がデモを通じて紹介されました。


セッションの感想
80%を占める非構造化データをビジネス活用するとき、GoogleCloudのBigQuery及びGeminiを筆頭とする関連サービス群が非常に強力だと感じた。
セッション1: 生成 AI が拓くデータ活用の新境地:Google Cloud の「データ エージェント」とは?
発表者:GoogleCloud
内容
Openingセッションの内容を技術的かつ具体的に踏み込んだ内容でした。AIエージェントは以下の3つから成り立っているとのこと。
- Model(基盤モデル)
- Tools(他APIやサービスとの連携)
- Orchestration(フロント部分。Toolsとモデルの橋渡しや、プロンプトの理解と応答)

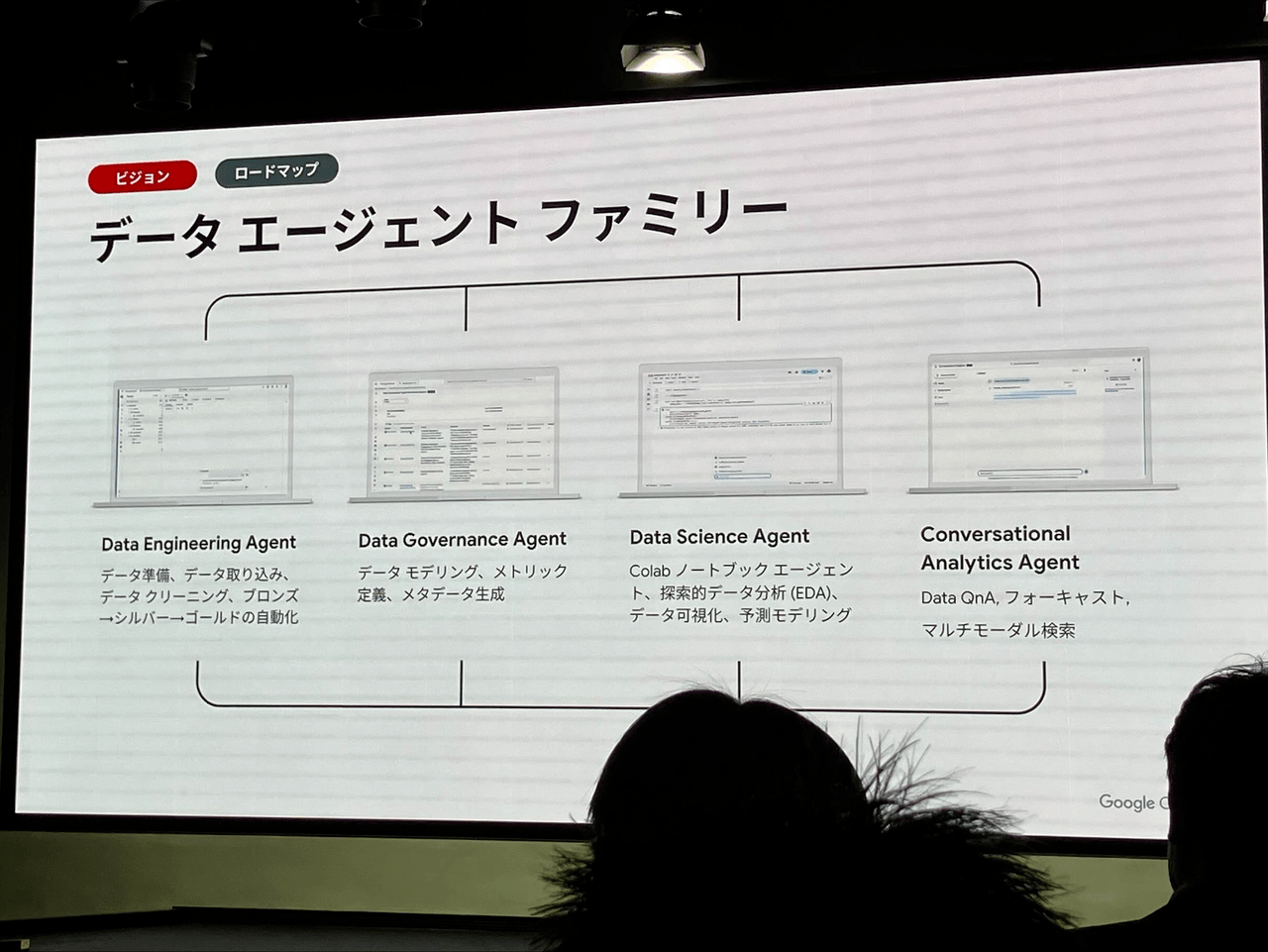
また、エージェントは複数が組み合わさってタスクが実行されるようになっていくとのことです。その中で、GoogleCloudはデータ関連エージェントとして以下の4つのエージェントを発表済もしくは今後発表予定であることが示されました。
- DataEngineeringAgent: データパイプラインの作成、データキュレーション、データクレンジングなどを自動化します。
- DataGovernanceAgent: 信頼できる唯一の情報源を作成し、メタデータの自動作成、自動異常値検出、データリネージ追跡などを可能にします。
- DataScienceAgent: ノートブック上でデータラングリングやデータ探索、モデル作成などを支援します。
- ConversationalAnalyticsAgent: Looker Studio Proで利用可能で、対話型でのデータ分析および可視化を実現します(APIでの提供も予定)。

独自Agentを構築する場合、Agent部分はADKというフレームワークを、MCP部分はOSSであるMCP Toolbox for Databaseというフレームワークを使うと効率的な開発が可能であると紹介されました。
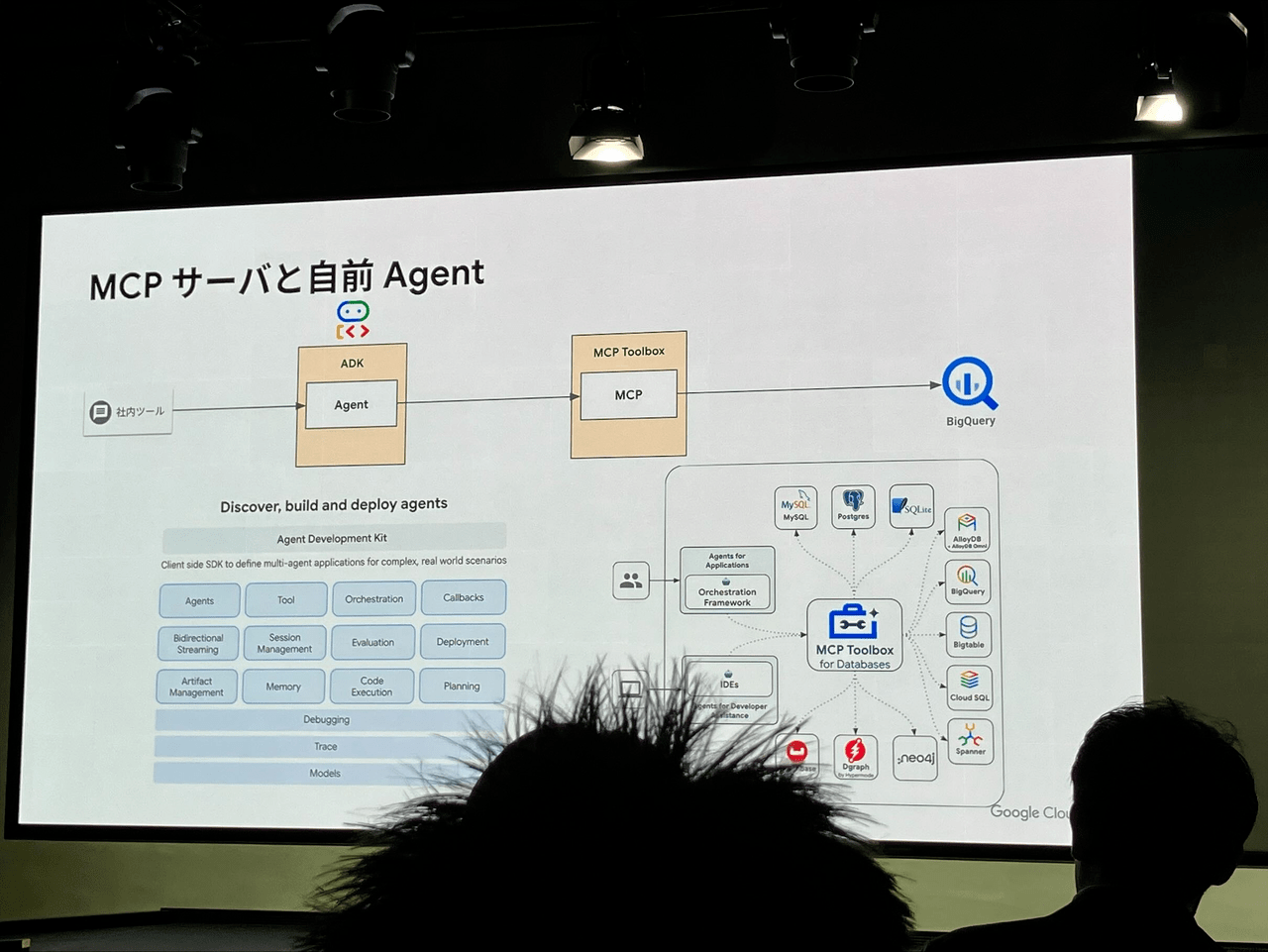
アーキテクチャへの影響とビジネスへの変革については、各種データエージェントは、いわゆるメダリオンアーキテクチャを大きく変えることはなく、全ての階層で効率化がなされるだけのため、現状のアーキテクチャは利用可能であると説明されました。これにより、データ発生から価値を出すまでの期間が圧倒的に短くなるとのことでした
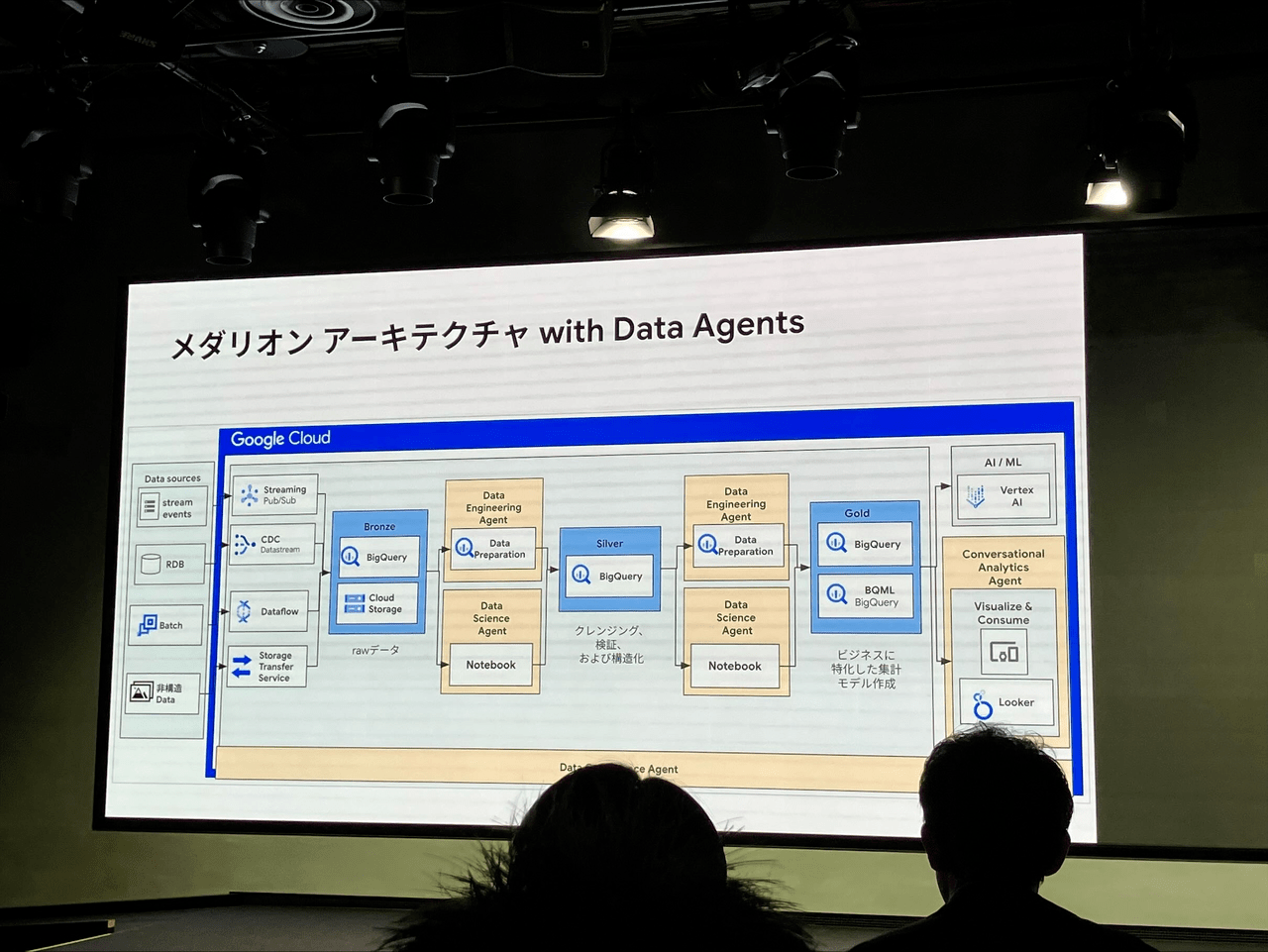
セッション感想
自然言語でここまでデータ分析が可能になる未来が楽しみになりました。
特に、DataGovernanceAgentのメタデータの自動作成は非常に魅力的でした。メタデータをしっかり作っていくのはデータ活用において非常に重要と理解しつつも、手間がかかることや、ルール統一・周知徹底が難しく現実的ではないケースがあると考えていました。それをAIが補完してくれることで、効率的なデータ分析に大きく寄与すると感じました。
セッション2:データが拓く、新たなロッテ:BigQuery を中心としたデータドリブン変革
発表者: 株式会社ロッテ
内容
内製化によるデータ分析の実績とその課題、今後の展望について詳細に語られました。
特に、DX寺子屋を定義して人材育成に力を入れ一定の成果を収めたものの、それがゆえにプロジェクトが増加。また、管理面のスキル不足による人材不足に陥ったとのことでした。
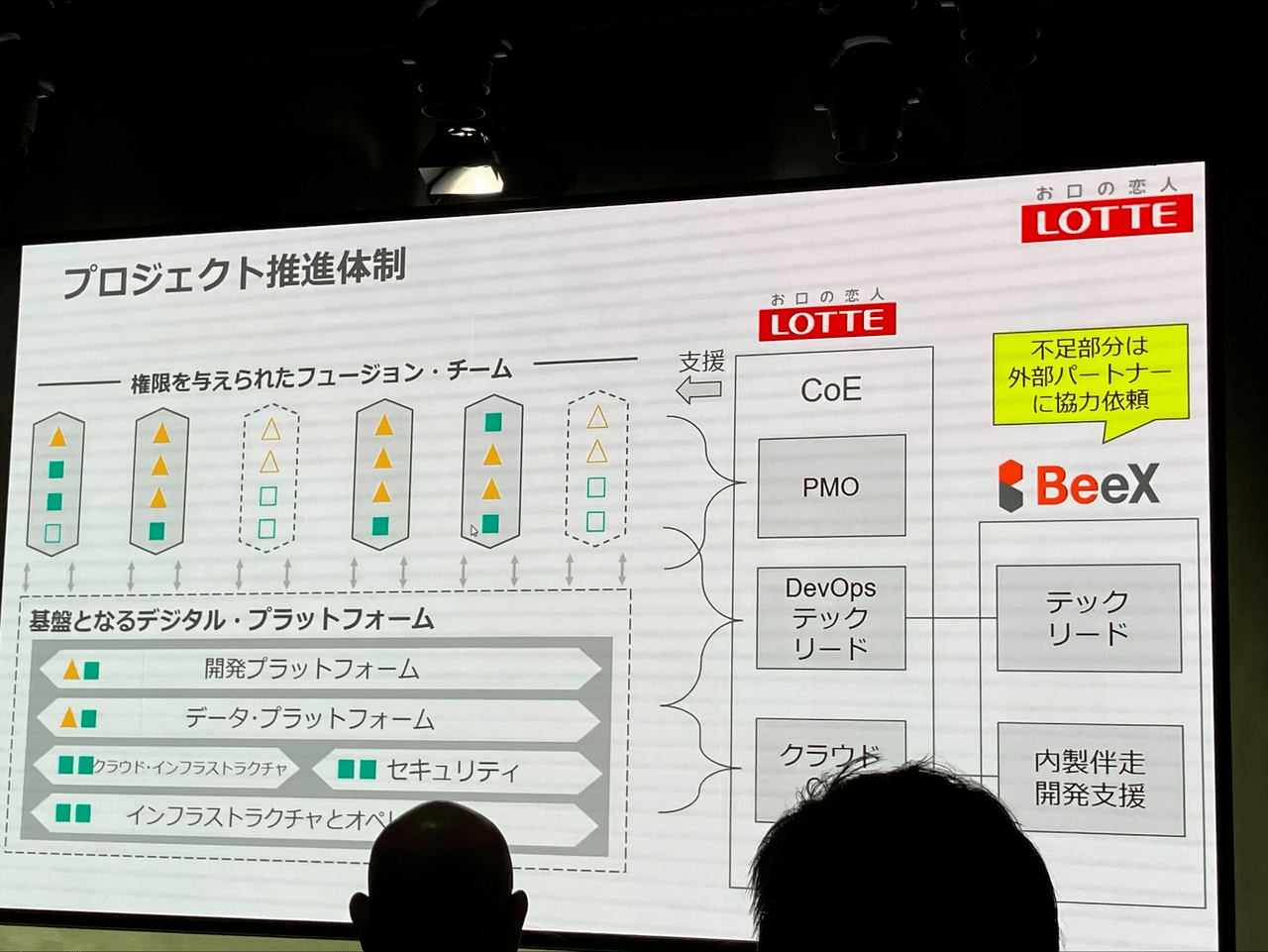
それらの課題解決のため、管理コスト削減やCI/CD環境構築といったアーキテクチャの改修を行ったとのことです。
興味深かったのは、DWHはBigQueryに統一しつつも、BIツールはあえてロックインされないよう乱立状態を維持しているという点でした。
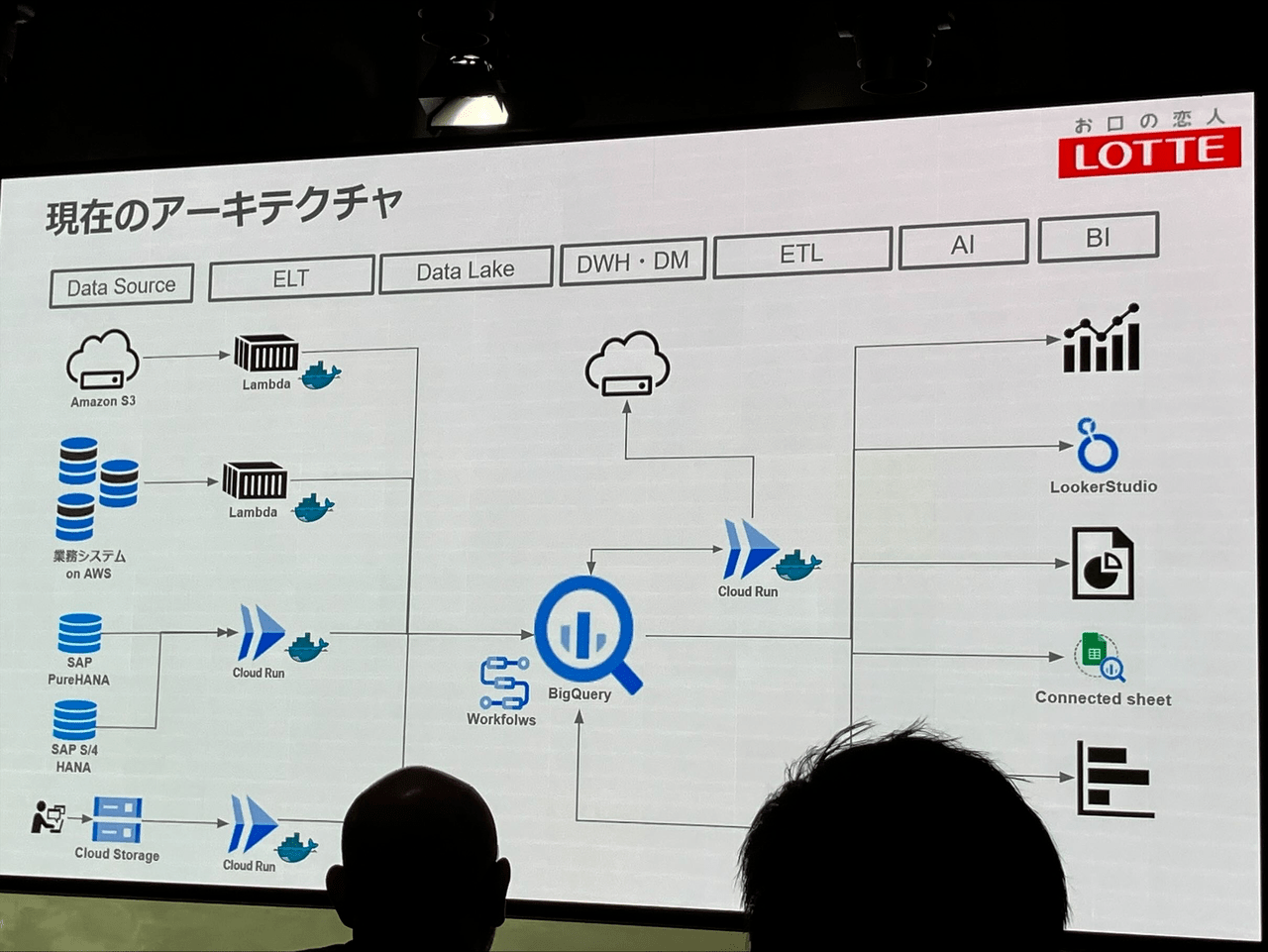
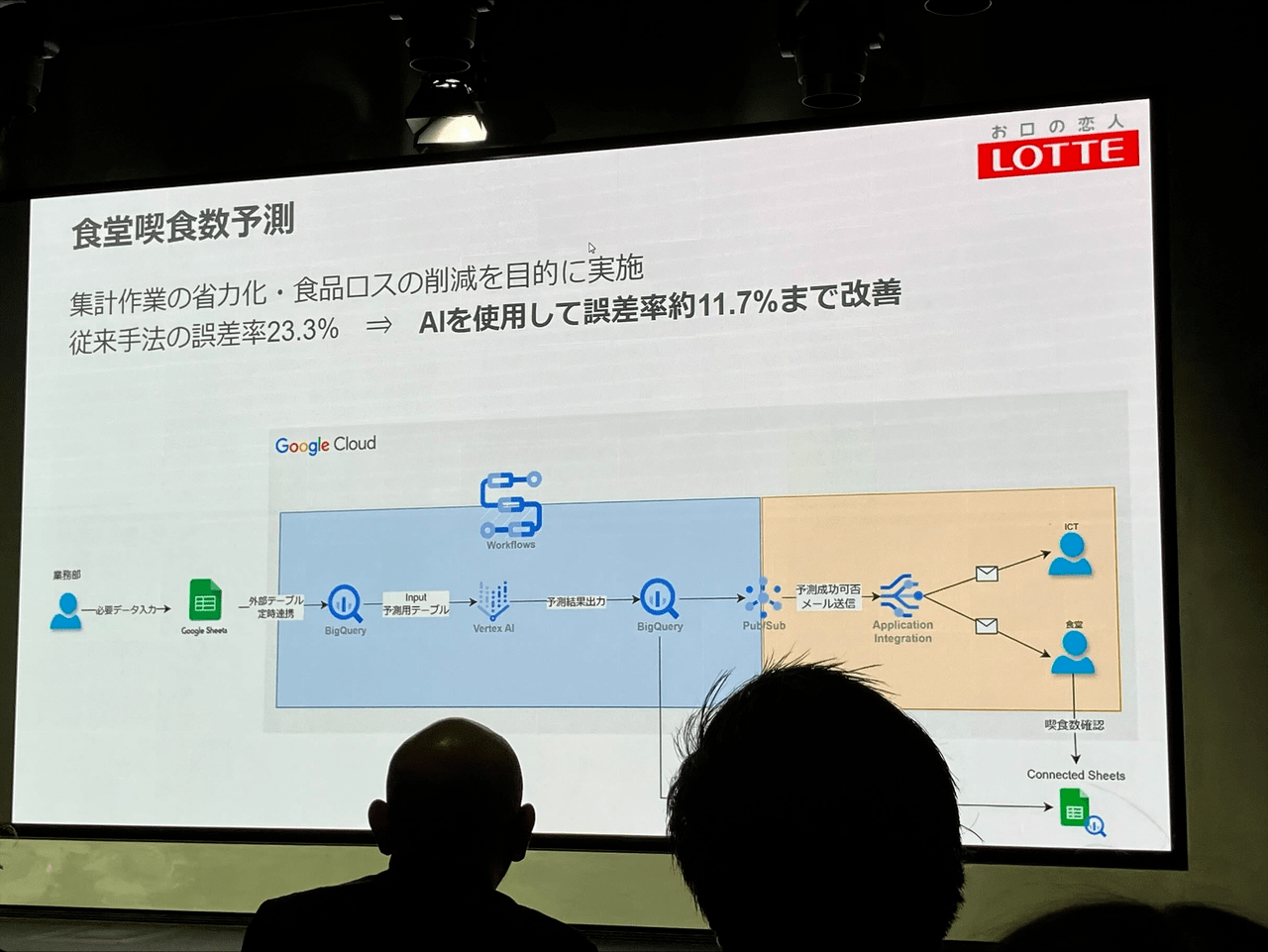
内製化の例として、食堂の喫食数予測。このシステムはなんと1年目の社員の方が内製で作ったそうです!素晴らしいです。
今後は非構造化データをビジネス活用するため、AI Agent時代を見据えて非構造化データの収集の仕組みを構築しているようです。
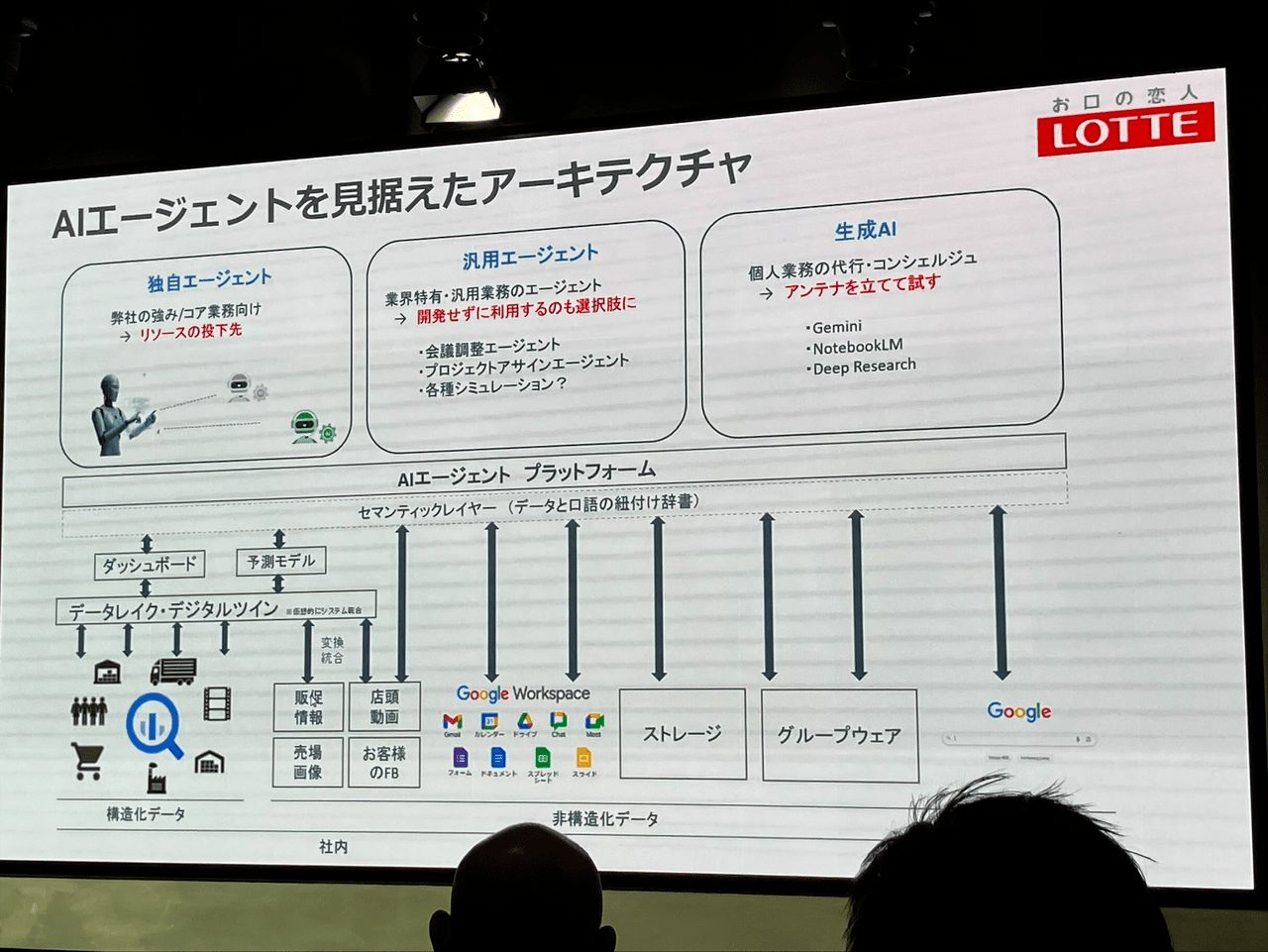
セッション感想
内製化推進に成功した結果、プロジェクトが増加し、逆に人材不足に陥り外部ベンダーへの委託も増えたという話は、非常にリアルで考えさせられました。
ビジネス部門から「業務を理解し、考えて仮説立ててから話もってこい」というお叱りを受けたというエピソードは、自身の仕事を振り返る上で心に刺さるものがありました。
懇親会の様子
イベント終了後の懇親会では、ビールやチューハイなどのドリンク、そして美味しい食事が提供され、参加者間の交流を深める良い機会となりました。
「Ask the Speaker」コーナーやGoogle Cloud社のエキスパートと直接会話できるコーナーも設けられており、セッションでは聞けなかった疑問を解消したり、より深い議論を交わしたりすることができました。
開始30分ほどで徐々に人が減り始めたため、最初は難しかったエキスパートとの会話も、食事をしながら時間を置くことでじっくりと話すことができ、貴重な情報交換の場となりました。

まとめ
今イベントを通して感じた Google Cloud の展望について
Google Cloudとしては、非構造化データのビジネス活用を強力に推進していく意思を強く感じました。
マルチモーダル対応かつ自社開発でBigQueryとのシームレスな連携が可能なGeminiとGoogle Cloudの組み合わせは、非構造化データの利活用という意味では強力な武器であり、GoogleCloudは推していくと感じました。
また、Geminiの優位性は、コストとマルチモーダルという点も再認識しました。
LLMの進化は日進月歩であり、他LLMとの性能比較は日々変化すると思いますが、Geminiはコストパフォーマンスという点とマルチモーダルという観点では一貫して優位性があるという印象を受けました。マルチモーダルは多くのLLMでも対応していますが、200万トークンという入力トークンサイズによりマルチモーダルなデータインプットへ幅広く対応できると感じました。
最後に
データエージェントはまだロードマップ段階のものが多いですが、リリースされた際にはすぐにでも使ってみたい機能ばかりでした。特に自然言語でデータパイプラインを構築できる機能は非常に魅力的であり、実務への導入を積極的に検討していきたいと考えています。
また、今回のイベントを通じて、非構造化データのビジネス活用が今後ますます重要になってくると強く感じました。今後も学習とアウトプットを続けていきたいと思います!