

こんにちは。SCSKの井上です。
この記事では、New RelicのInfrastructure エージェント導入後に、インフラ基盤を監視するための画面の見方を解説します。CPU、メモリ、ネットワークトラフィックなどの観測方法を理解することで、インフラ基盤のボトルネックを把握できるようになります。
はじめに
アプリケーションを安定して動作させるためには、インフラ基盤を正常に稼働させることが不可欠です。ハードウェア性能に関するデータを観測し、インフラ関連の情報を一元管理することで、システム全体を把握し、健全性を高めることが安定したサービス提供につながります。この記事を読んで、Infrastructure機能を少しでも理解いただけると幸いです。
Infrastructureエージェントの導入方法については、過去の記事からご確認いただけます。

InfrastructureのUI構成
この画面でInfrastructureの見方を解説します。サーバーやコンテナ、といった基盤全体の状態を俯瞰できます。アプリケーションのパフォーマンスを追うだけでは見えない、ホストレベルのリソース状況やイベント履歴、インベントリ変化などを統合的にチェックできるため、日々の運用監視やトラブルシューティングに欠かせないUIです。
主要部分UI
Infrastructureの機能は主要3セクションに分かれています。Hostsはリソース監視、Inventoryは構成管理、Eventsはトラブルシューティングに活用など、それぞれインフラ基盤を観測する上での必要な機能が備わっています。
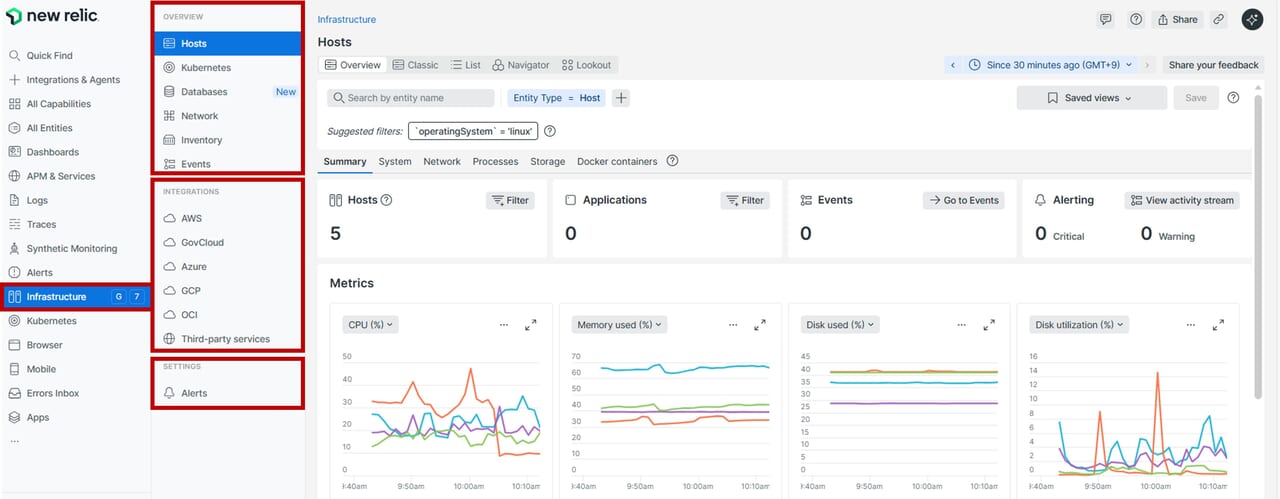
| セクション | 概要 |
| Overview | インフラUIの主要ページ。 ・Hosts:ホストの状態を一覧表示 ・Kubernetes:K8sインテグレーションのデータ ・Network:ネットワークパフォーマンス監視 ・Inventory:構成情報の確認(アップグレードや設定ドリフト) ・Events:重要なシステムアクティビティのタイムライン |
| Integrations | インフラ統合のテレメトリを表示。 ・クラウドサービス(AWS、Azure、GCP、OCI) ・サードパーティサービス(Apache、Cassandra、RabbitMQなど) |
| Settings | システム設定関連。 ・Alerts:アクティブなインシデントを含むアラート概要 |

全ホストのサマリを確認したい場合
この画面ではInfrastructure エージェントが導入されたホストのメトリクスデータを確認することができます。
| 対象画面 | 利用シーン |
サマリ情報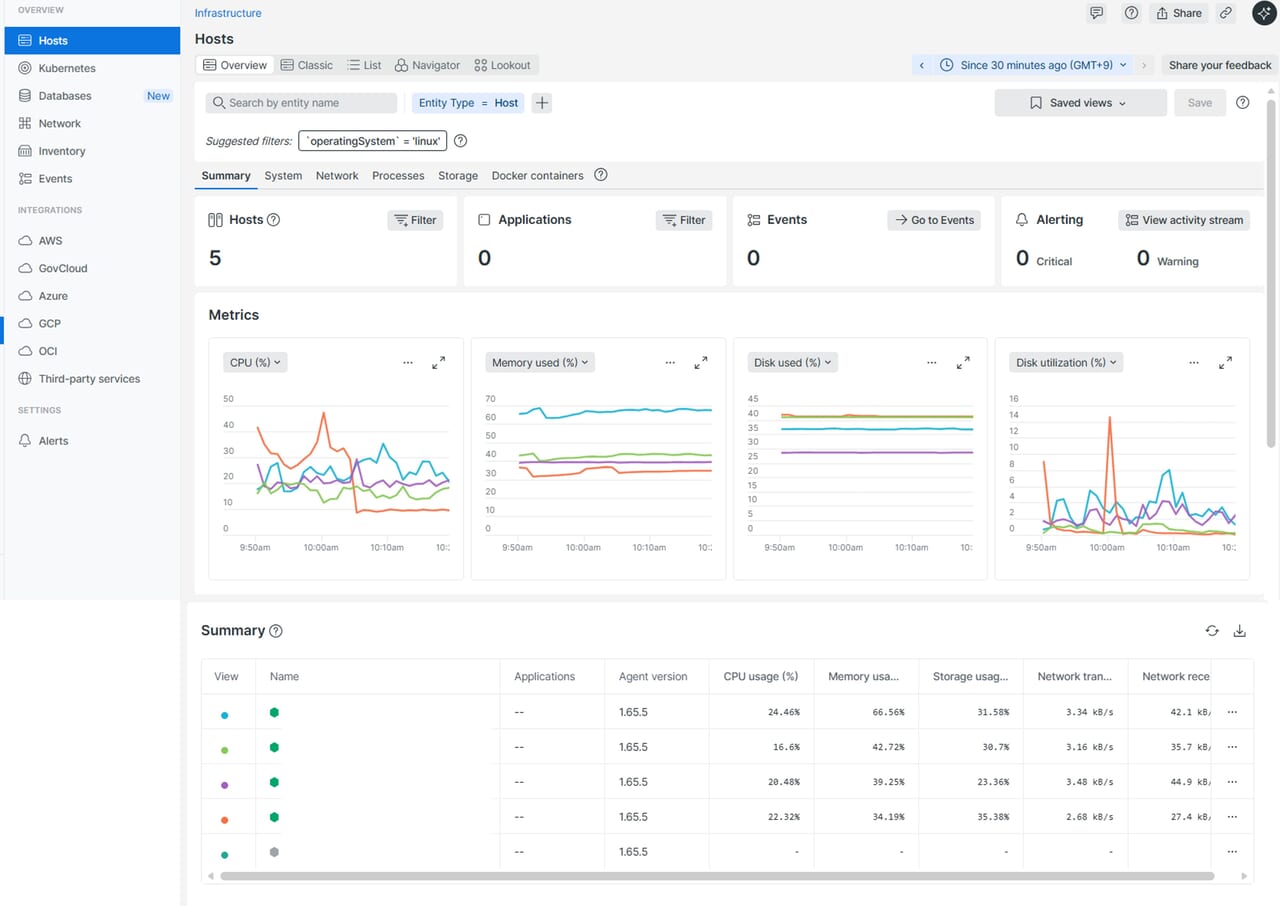 |
最近の負荷変動や異常をすばやく確認したいとき |
システム情報(CPU/メモリ等)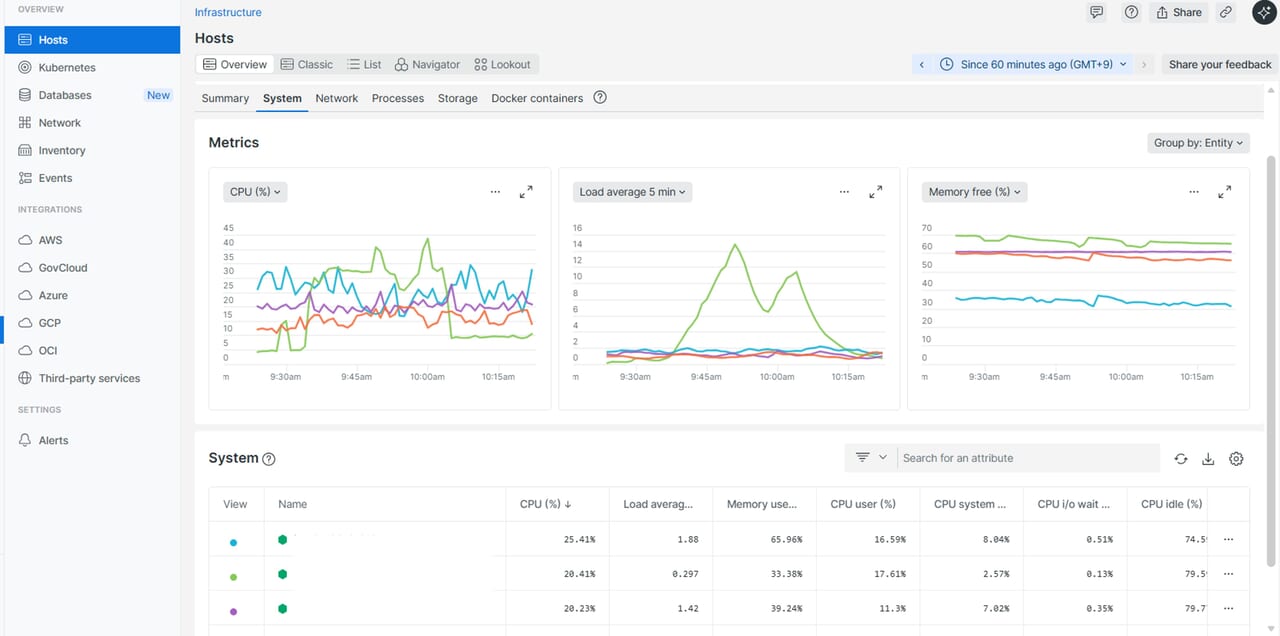 |
長期的な傾向や履歴を分析したいとき |
Network情報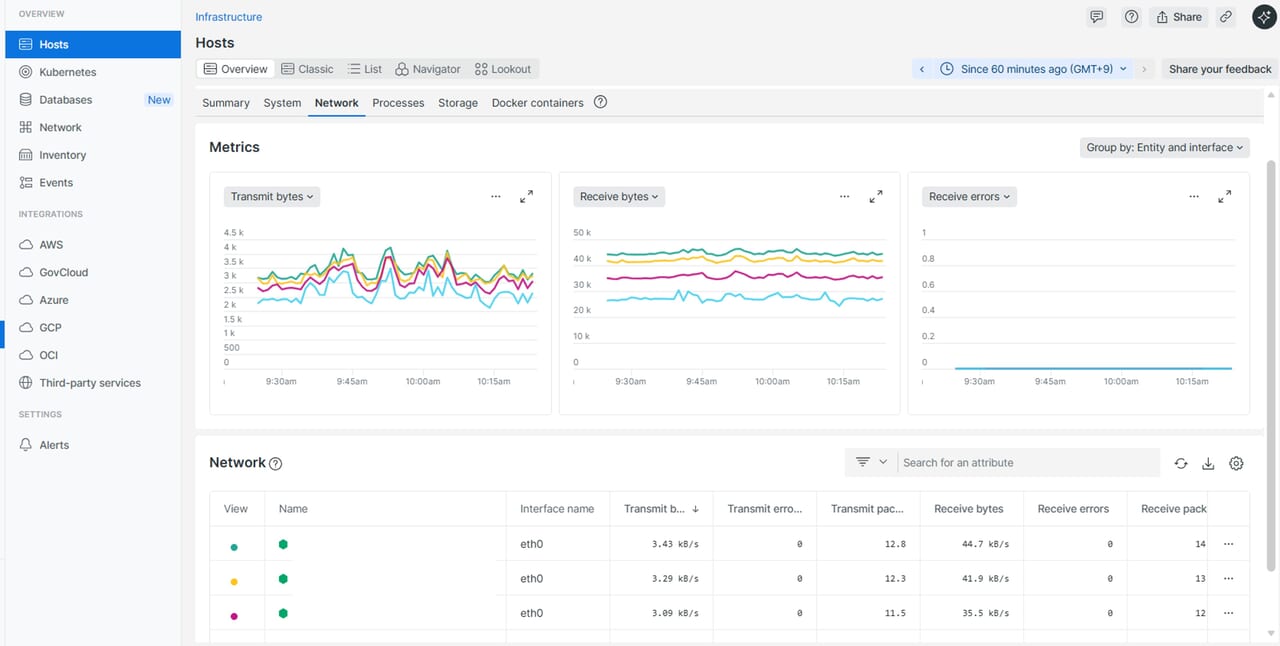 |
ネットワークのボトルネックや負荷分散の必要性を判断したいとき |
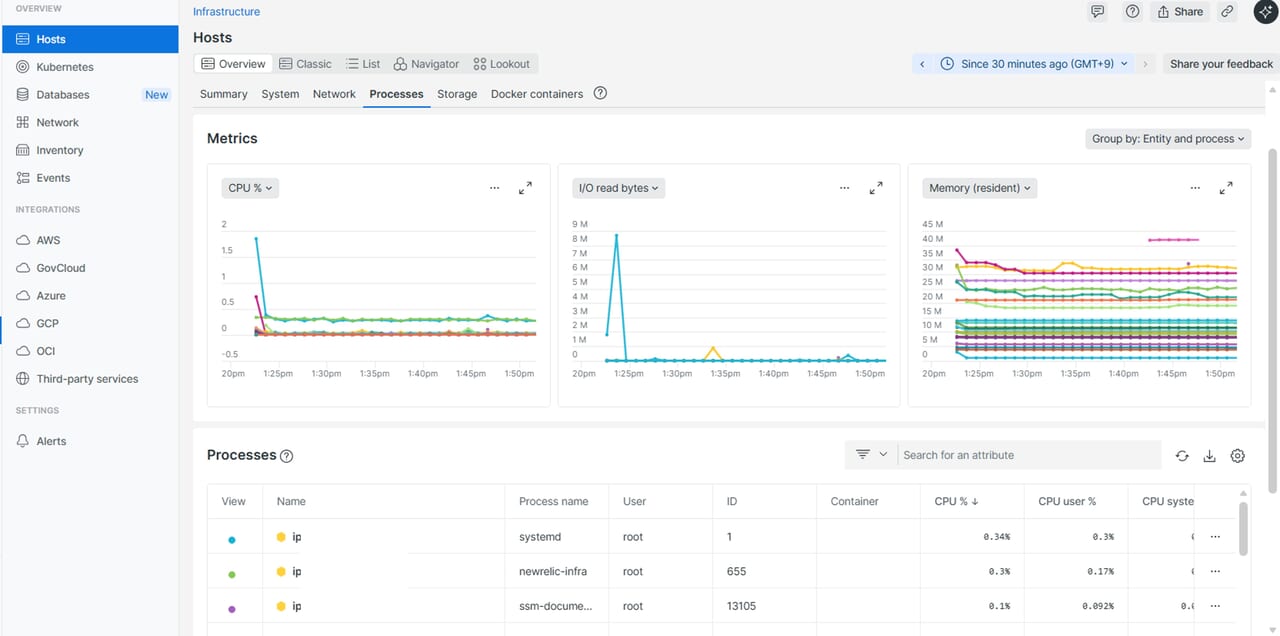
| プロセス情報
|
高負荷プロセスや異常な動作を特定したいとき |
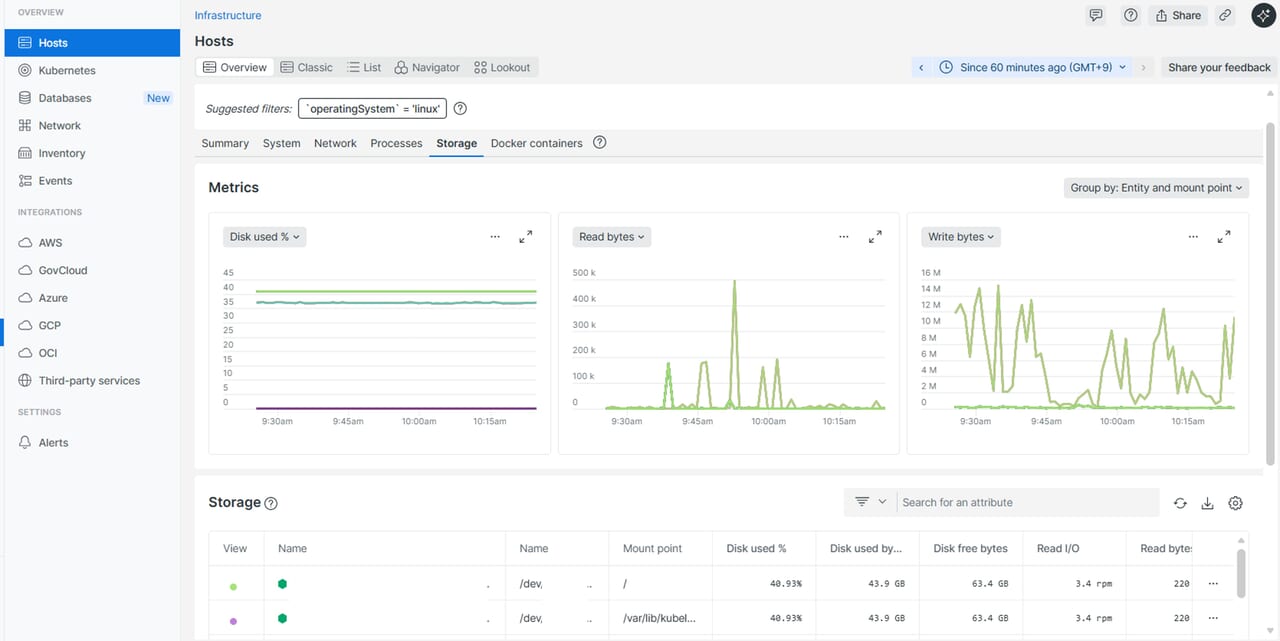
| ディスク情報
|
ディスク容量不足やI/O異常を早期に検知したいとき |
他のメトリクスを確認したい場合
New Relicでは、調査に必要なさまざまなメトリクスを収集しています。その他のメトリクスを確認したい場合は、画面の赤枠で示したプルダウンメニューから選択できます。執筆時点で確認可能なメトリクス一覧も参考として表で記載します。
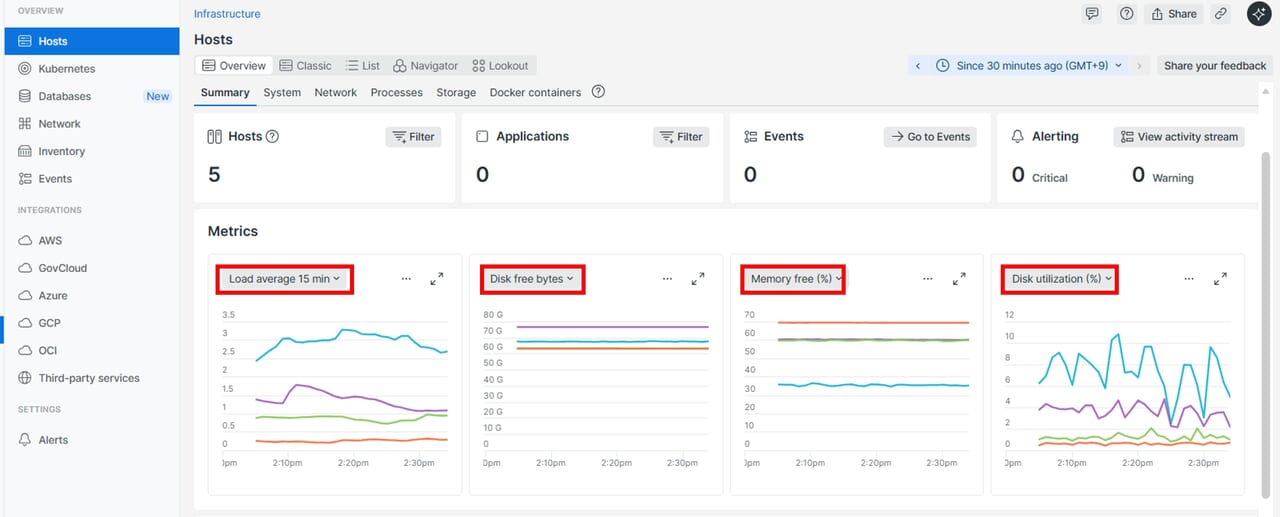
New Relicで観測できるメトリクス情報一覧
| カテゴリ | メトリクス名 | 説明 |
| CPU | CPU (%) | CPU全体の使用率 |
| CPU user (%) | ユーザープロセスによるCPU使用率 | |
| CPU system (%) | システムプロセスによるCPU使用率 | |
| CPU i/o wait (%) | I/O待ちによるCPU使用率 | |
| CPU idle (%) | CPUアイドル時間の割合 | |
| CPU steal (%) | 順番待ちしているCPU時間の割合 | |
| ロードアベレージ | Load average 1 min | 直近1分間の平均負荷 |
| Load average 5 min | 直近5分間の平均負荷 | |
| Load average 15 min | 直近15分間の平均負荷 | |
| メモリ | Memory used (%) | メモリ使用率 |
| Memory free (%) | メモリ空き率 | |
| Memory free bytes | 空きメモリ容量 | |
| Memory total bytes | メモリ総容量 | |
| Memory used bytes | 使用メモリ容量 | |
| スワップ | Swap free bytes | 空きスワップ容量 |
| Swap total bytes | スワップ総容量 | |
| Swap used bytes | 使用スワップ容量 | |
| ディスク | Disk free bytes | 空きディスク容量 |
| Disk free (%) | 空きディスク率 | |
| Disk total bytes | ディスク総容量 | |
| Disk used bytes | 使用ディスク容量 | |
| Disk used (%) | ディスク使用率 | |
| Disk utilization (%) | ディスク全体利用率 | |
| Disk read utilization (%) | 読み取り時のディスク利用率 | |
| Disk write utilization (%) | 書き込み時のディスク利用率 | |
| Disk reads per second | 1秒あたりのディスク読み取り回数 | |
| Disk writes per second | 1秒あたりのディスク書き込み回数 | |
| アプリケーション | Application response time | アプリケーション応答時間(APM有効時のみ) |
| Application throughput | アプリケーションのスループット(APM有効時のみ) | |
| Application error rate | アプリケーションのエラー率(APM有効時のみ) |
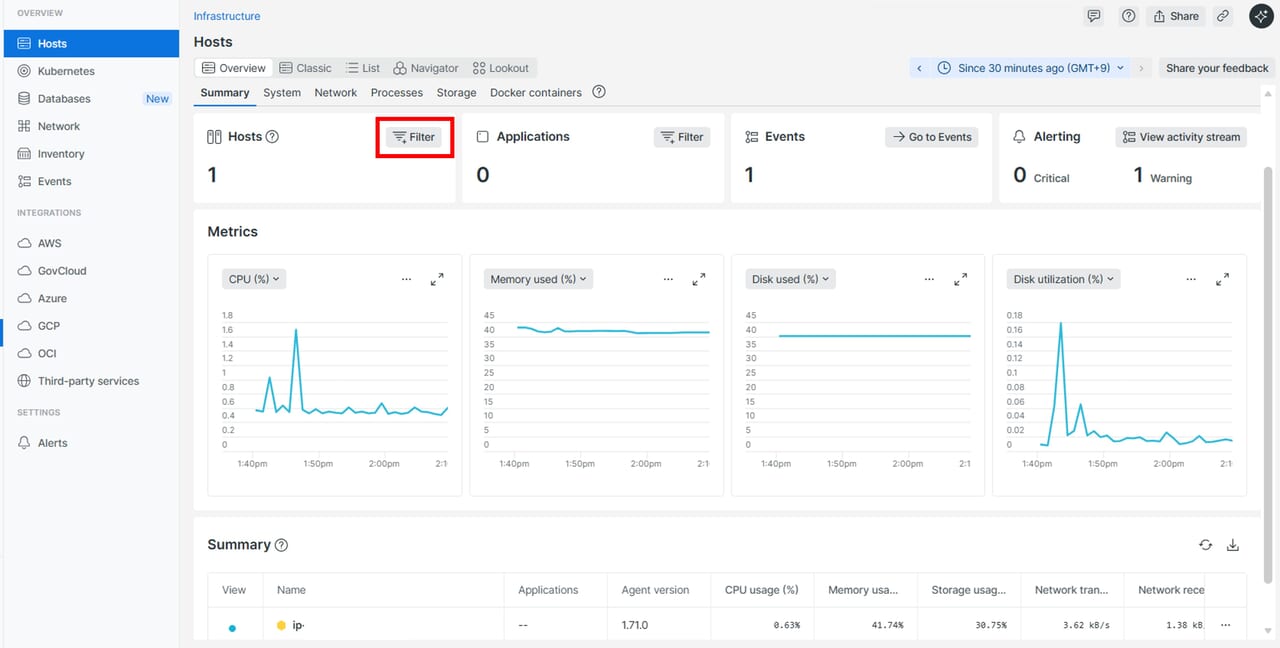
個々のホストを確認したい場合
全ホストを一覧で確認し、特定のホストだけリソース使用率が高いことがわかったため、ホスト数を絞りたい場合などは、画面右上の 「Filter」 をクリックして対象ホストを絞り込むことができます。
個々のホストを1つの画面で確認したい場合
特定の1つのホストだけを確認したい場合は、Summary欄より該当のホストをクリックすることで、そのホストに関する観測データを確認することができます。
| 1.画面下部「Summary」欄にホスト情報が表示されています。表示したいホストをクリックします。 | 2.該当のホスト情報が表示されます。この画面でメトリクスや、ログなどを確認することができます。 |
|
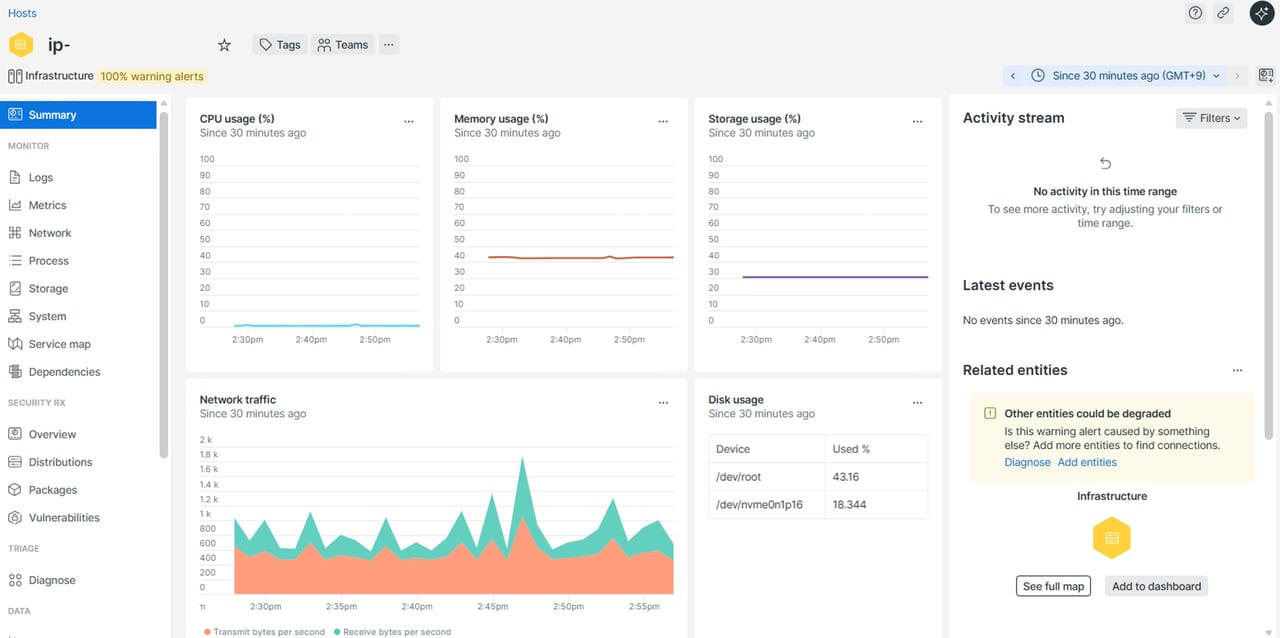 |

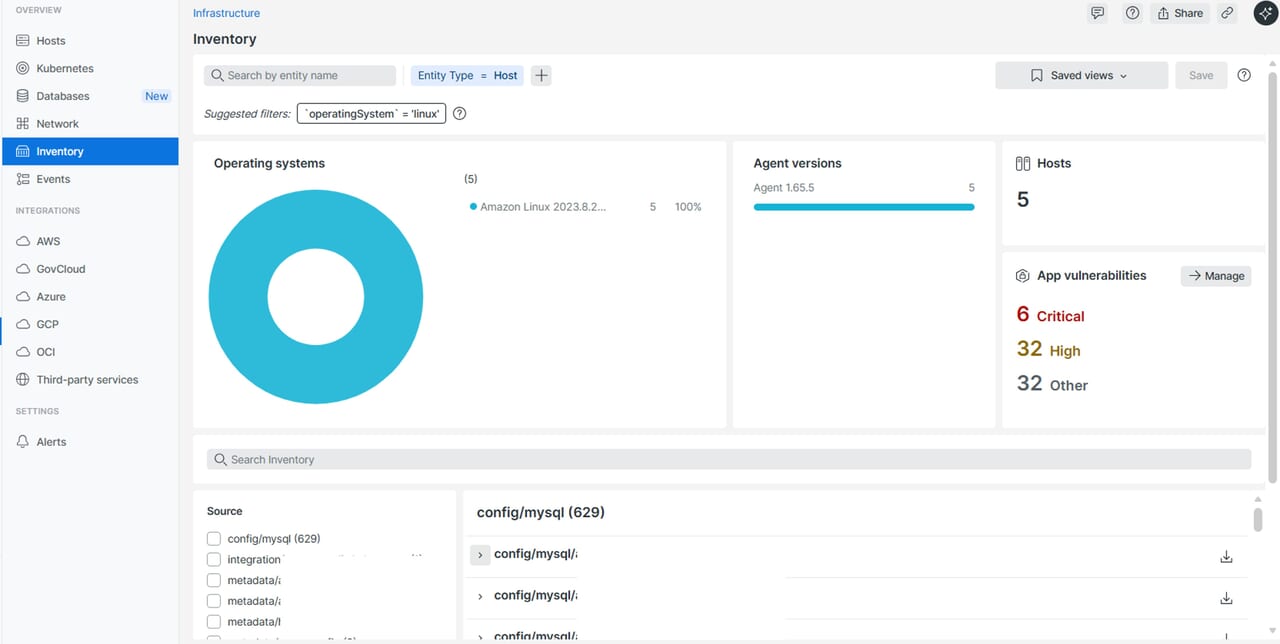
インベントリUI
この画面では、Infrastructureエージェントがインストールされたホスト内のOSやアプリケーションの構成要素、インストールされているパッケージなどを、ホストにログインせずに確認できます。構成情報はホストから送信される最新データが即座にUIに反映されます。ホストがシャットダウンしたりエージェントが停止してNew Relicへのデータ送信ができなくなった場合でも、最後に報告されたインベントリ情報は最大24時間UIに保持されます。
利用シーンとしては以下の例が挙げられます。
・セキュリティ対策:脆弱性対応後、古いパッケージが残っていないか
・バージョン比較 :本番環境とテスト環境のパッケージや設定ファイルの差異を比較
・構成管理 :ミドルウェアやサービスのインストール状況を把握

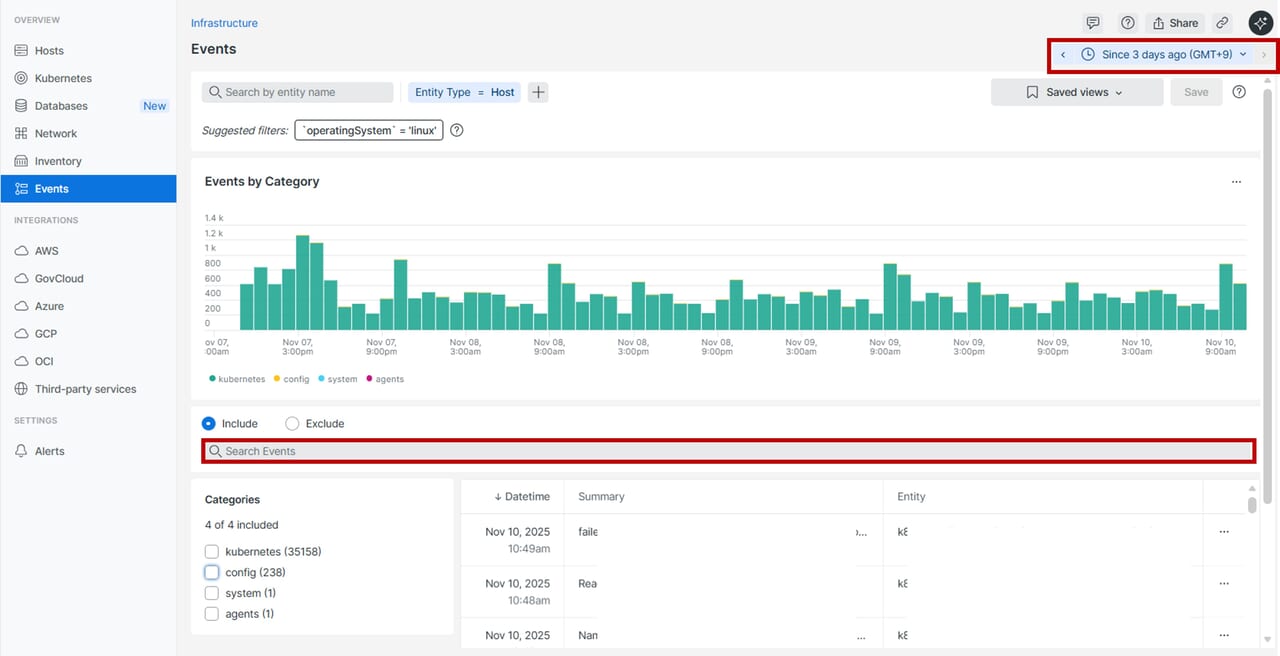
イベントUI
システムやホストの重要なアクティビティをリアルタイムで確認できます。インフラストラクチャーの変更やアクティビティを時系列で表示し、特定の時間に発生したイベントを一元管理できます。ホストごとにイベントを検索できますが、画面右上で指定した時間範囲内のイベントのみが表示されます。広範囲を調べたい場合は、時間範囲を拡大する必要がありますのでご注意ください。
利用シーンとしては以下の例が挙げられます。
・障害の原因特定 :スパイクや異常値が発生した時間帯に、どんなイベントがあったかを確認
・変更履歴の監査 :インベントリ(Kernel、Metadata、Packages、Services、Sessions)の変更履歴を記録
・ユーザーセッションの監視:ユーザーの接続・切断イベントを記録し、セキュリティや運用状況を把握
・構成変更の影響分析 :設定変更やパッケージ更新などのイベントと、CPUやメモリなどのメトリクスを比較

日常監視と障害対応におけるInfrastructureエージェントの活用方法
ここまではInfrastructureエージェントの機能について説明してきました。ここからは、実際の運用においてどのように活用できるのか、日常監視と障害対応の観点から一例をご紹介します。なお、運用方法は環境や体制によって異なるため、必ずしもこの記事の内容がすべての環境に当てはまるものではありません。
日常監視において
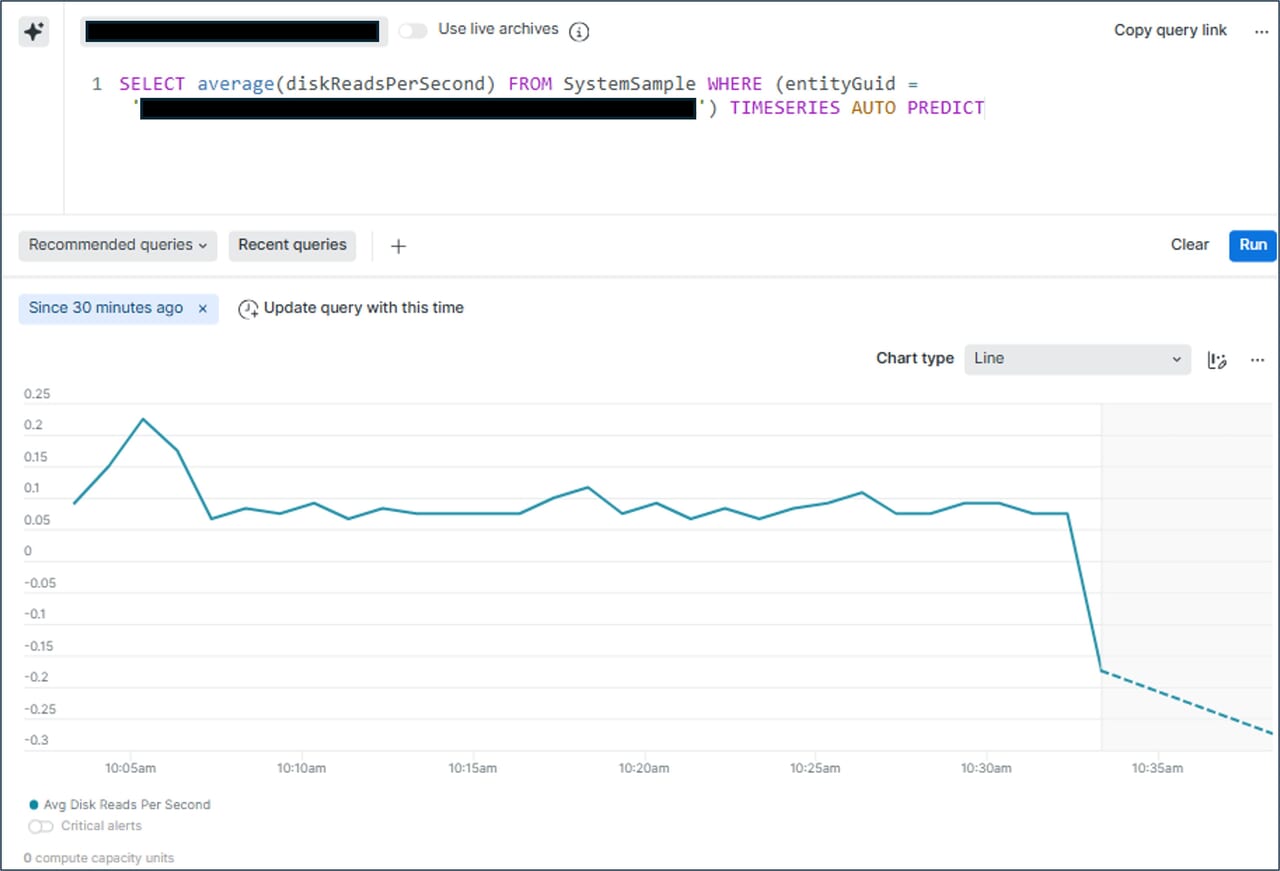
障害の発生を未然に防ぐためには、日常的な監視が重要になります。平常時には、CPUやメモリ使用率、ディスク使用量、ネットワークトラフィックといったメトリクスを継続的に観測することで、リソース使用状況のベースラインを把握できます。通常時の傾向を理解しておくことで、平常とは異なる挙動や、徐々に蓄積していく負荷にも早期に気づくことが可能です。
また、New Relicの機能の一つとして、過去のデータパターンをもとに将来の傾向を予測する機能が備わっています。将来的にリソースが閾値に到達しそうか、安定した稼働が見込めるかといった傾向を事前に把握できます。この機能を利用する場合は、CCUライセンスが必要となり、既存のユーザーライセンスやデータ量とは別に、追加の契約が必要となります(執筆時点)。

障害対応において
障害が発生した際には、まず対象ホストのCPU、メモリ、ディスク、ネットワークといった主要リソースに急激な変動や異常値が発生していないかを確認します。New RelicのInfrastructureエージェントが導入されていれば、対象ホストへログインすることなく状態を把握できるため、障害対応の初動を迅速に進めることが可能です。CPUやメモリ使用率だけでなく、Load Average やディスク使用率、ディスクI/Oの増加などもあわせて確認することで、一時的な負荷によるものか、恒常的なリソース枯渇によるものかを判断しやすくなります。
リソースに異常が見られた場合は、Events UI を活用し、障害発生前後にどのような変更作業が行われていたかを確認します。パッケージ更新、サービス再起動、構成変更、ユーザー操作などのイベントを時系列で把握することで、障害のトリガーとなった要因を切り分けやすくなります。
Infrastructure機能を使いこなすために
大規模かつ動的に変化する環境を監視するために、すべてのホスト(DB・Webサーバーなど)へエージェントをインストールし、単一のダッシュボードでデータを一元的に確認することで、チーム間で情報を共有しやすくなります。また、アラート条件の設定やクラウドインテグレーションの有効化といったベストプラクティスにより、オブザーバビリティを迅速に向上させることができます。継続的に改善を繰り返すことで、障害発生時の原因特定や復旧までの時間(MTTR)を大幅に短縮し、クラウド・オンプレミスに関わらず、運用データを統合的に管理できるよう、以下指針がまとめられています。
| 項目 | 概要 |
| 1. Infrastructureエージェントを環境全体にインストール | すべてのホスト(DB、Webサーバーなど)にエージェントを導入し、タグやカスタム属性で分類。 |
| 2. EC2インテグレーションを設定 | AWSタグとメタデータを自動インポートし、タグでフィルタリングやアラート設定を実現。新しいインスタンスも自動追加。 |
| 3. インテグレーションを有効化 | AWSサービスやホスト上のアプリを監視。事前設定されたダッシュボードを利用可能。 |
| 4. ホストグループビューの作成 | エンティティフィルターでグループ化し、稼働ステータスを色分け表示し、問題箇所を迅速に特定。 |
| 5. アラート条件を作成 | タグベースで条件を作成し、新しいホストにも自動適用。 |
| 6. InfrastructureデータをAPMデータと統合 | Application Performance Monitoring(APM)とInfrastructureを並べて表示し、根本原因を迅速に特定。サービスマップでアプリとインフラの関連性を可視化。 |
| 7. メトリクスとイベントを活用 | カスタムダッシュボードを作成。チームで共有し、インフラとアプリの健全性を一元管理。 |
| 8. エージェントを定期的に更新 | 新機能や改善を活用するため、最新バージョンへの更新を推奨。 |

さいごに
この記事では、New Relic Infrastructure の主要な機能について解説しました。New Relic は多機能なプラットフォームであり、インフラ監視ひとつをとっても観測できるデータは多いです。そのため、まだ取り上げきれていない機能や、より深く掘り下げられるトピックも数多く存在します。今後は、実際の運用シナリオで役立つ設定例や、ダッシュボード活用方法、アラートチューニング、クラウドサービスとの統合など、実践的な情報も解説していきます。
SCSKはNew Relicのライセンス販売だけではなく、導入から導入後のサポートまで伴走的に導入支援を実施しています。くわしくは以下をご参照のほどよろしくお願いいたします。
