
 本記事は TechHarmony Advent Calendar 2025 12/25付の記事です。 本記事は TechHarmony Advent Calendar 2025 12/25付の記事です。 |
クリスマスマーケットでプレッツェルにハマりました
皆さんどうもこんにちは。いとさんです。
メリークリスマス!……と言いたいところですが、実は今日12月25日は、世界で初めて「Webサイト」が公開された記念すべき日でもあるそうです。
1990年の12月25日、イギリスの計算機科学者ティム・バーナーズ=リーが、世界で初めてのWebブラウザとサーバ間の通信に成功しました。 つまり、今こうして皆さんがブログを読めている環境の「誕生日」とも言える日なんです。ネットの歴史が動いたのがクリスマス当日だったというのは、なんだかロマンチックですよね。


さて今回はタイトルにもありますように
Amazon Bedrock AgentCore & Strands Agentsを使用したAWS構築支援エージェントの構築方法についてご紹介したいと思います!
AWS環境運用支援エージェント構築手順
🎯 エージェントの目標
AWS公式ドキュメントを使用した、開発・運用チーム向けのAWS運用支援エージェントを構築します。
チャットボットとの違いとして、自ら考え、道具を使い、経験を蓄積する「AIエージェント」としての機能を備えています。
チャットボットと「AIエージェント」の違いとは?
一般的なチャットボットは、あらかじめ学習した知識の範囲内でユーザーの問いに「反応」するだけですが、今回構築するAIエージェントには決定的な3つの違いがあります。
-
「知識」ではなく「道具」を使いこなす (Tools)
通常のチャットボットは古い知識で答えることがありますが、このエージェントは MCPClientというツールを使い、外部にある「最新のAWS公式ドキュメント」へ自らアクセスして情報を取得します。 -
「会話」ではなく「経験」を記憶する (Memory)
ブラウザを閉じれば忘れてしまうチャットボットと違い、AgentCore Memory を通じて「過去のトラブル対応事例」などを長期記憶(LTM)として蓄積します。これにより、使えば使うほど使用する環境に詳しい状態へと成長します。 -
「思考」の方向を制御できる安全性 (Steering)
自由奔放なAIとは異なり、LLMSteeringHandler によって「破壊的な操作の提案を禁止する」といった運用のガードレールを思考プロセスそのものに組み込んでいます。
このように、最新の公式情報(MCP)と経験(LTM)を、安全なルール(ステアリング)の上で統合して提供できるのが「AWS運用支援エージェント」なのです。
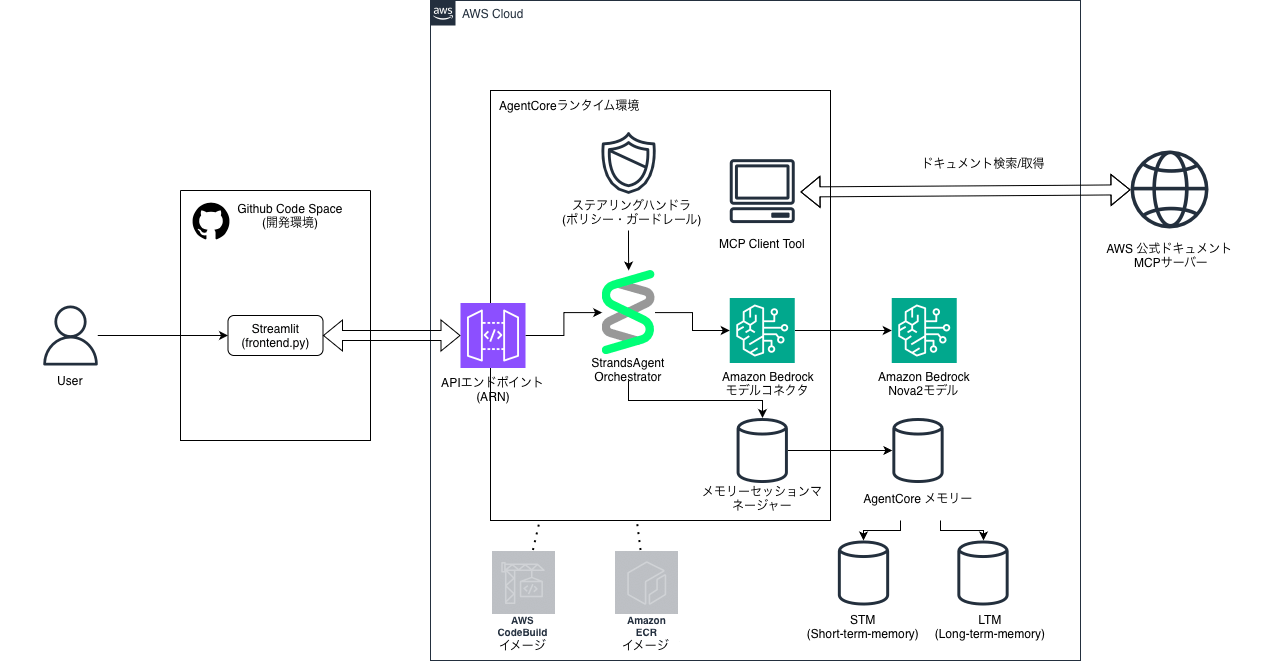
構成図
⚠️構築前提条件
- AWSアカウントを所有していること。
- GitHubアカウントを所有していること。
- AWSリージョンはバージニア北部 (
us-east-1) を利用します。(StrandsAgent使用可能リージョンのため) -
Administrator Access相当、もしくは以下のポリシーを適用したIAMユーザーで作業すること。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "BedrockAccess", "Effect": "Allow", "Action": [ "bedrock:InvokeModel", "bedrock:ListFoundationModels", "bedrock:ListCustomModels" ], "Resource": "*" }, { "Sid": "AgentCoreFullAccess", "Effect": "Allow", "Action": "bedrock-agentcore:*", "Resource": "*" }, { "Sid": "S3AndECRForDeployment", "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:PutObject", "s3:GetObject", "s3:DeleteObject", "s3:ListBucket", "ecr:GetAuthorizationToken", "ecr:CreateRepository", "ecr:DeleteRepository", "ecr:BatchCheckLayerAvailability", "ecr:PutImage" ], "Resource": "*" }, { "Sid": "CodeBuildAndIAMManagement", "Effect": "Allow", "Action": [ "codebuild:*", "iam:CreateServiceLinkedRole", "iam:CreateRole", "iam:PutRolePolicy", "iam:DeleteRole", "iam:DeleteRolePolicy" ], "Resource": "*" }, { "Sid": "CloudWatchAndBoto3Access", "Effect": "Allow", "Action": [ "logs:*", "cloudwatch:*" ], "Resource": "*" } ] }
ステップ 1: 環境準備(CodeSpaceの利用)
まず、開発環境としてGitHub CodeSpacesをセットアップします。
- GitHubリポジトリの作成
GitHubで新しいプライベートリポジトリを作成します(例:aws-ops-agent)。 - CodeSpacesの起動
作成したリポジトリの画面左上「<> Code」ボタンから「Codespaces」タブを開き、「Create codespace on main」を選択して起動します。ターミナルが自動的に開きます。 -
AWS CLIのインストールと認証
ターミナルで以下のコマンドを実行し、AWS CLIをインストールします。# ダウンロード curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" # 解凍 unzip awscliv2.zip # インストール sudo ./aws/install
AWSアカウントへの認証を設定します(ブラウザでの検証コード入力が必要です)
aws login --remote
デフォルトリージョンが
us-east-1でいいか聞かれたら Enter を押します。
ステップ 2: AgentCoreメモリの作成(短期・エピソード記憶の準備)
エージェントが会話履歴と社内ナレッジを記憶するためのAgentCore Memoryを作成します。
- AgentCoreサービスへアクセス
AWSマネジメントコンソールで「AgentCore」を検索してアクセスします。
左メニューから「メモリー」>「メモリを作成」をクリックします。 - メモリ設定
すべてデフォルトのまま「メモリを作成」をクリックします。 -
エピソード記憶の有効化 (LTM)
作成したメモリの詳細画面を開き、「編集」をクリックします。
組み込み戦略の「Episodes」にチェックを入れ、「変更を保存」します。
重要: 作成されたメモリの Memory ID と、エピソード記憶戦略の 戦略ID を控えておきます。(エージェント本体の作成の際に使用します)
ステップ 3: エージェント本体の作成(backend.py)
エージェントの処理ロジックと、必要なツール、記憶、ステアリングを設定したAPIサーバーのコードを作成します。
-
ディレクトリとファイルの作成
以下のコードをコピーし、memory_XXXXX-XXXXXXXXXX(Memory ID) とepisodic_builtin_XXXXX-XXXXXXXXXX(戦略ID) のプレースホルダーを、ステップ2で控えた実際のIDに置き換えて貼り付けます。
mkdir agentcore cd agentcore touch backend.py -
# 必要なライブラリをインポート from strands import Agent from strands.tools.mcp import MCPClient from strands.models import BedrockModel from strands.experimental.steering import LLMSteeringHandler # ステアリング用 from bedrock_agentcore.runtime import BedrockAgentCoreApp from mcp.client.streamable_http import streamablehttp_client from bedrock_agentcore.memory.integrations.strands.config import AgentCoreMemoryConfig, RetrievalConfig from bedrock_agentcore.memory.integrations.strands.session_manager import AgentCoreMemorySessionManager # 1. モデル設定 model = BedrockModel( model_id="us.amazon.nova-2-lite-v1:0", max_tokens=4096 ) # 2. メモリー設定(STM/LTM) memory_config = AgentCoreMemoryConfig( memory_id="memory_XXXXX-XXXXXXXXXX", # ここをあなたのMemory IDに置き換える session_id="aws_ops_handson", actor_id="ops_engineer", retrieval_config={ # エピソード記憶(LTM)の検索設定 "/strategies/episodic_builtin_XXXXX-XXXXXXXXXX/actors/ops_engineer/sessions/aws_ops_handson": RetrievalConfig() # ここをあなたの戦略IDに置き換える } ) session_manager = AgentCoreMemorySessionManager( agentcore_memory_config=memory_config ) # 3. ツール設定 (MCPClient) mcp_client = MCPClient( lambda: streamablehttp_client( "https://knowledge-mcp.global.api.aws" ) ) # 4. ステアリング設定(ポリシーの強制) # 例: 破壊的な操作の推奨を禁止し、公式ドキュメント参照を強制 handler = LLMSteeringHandler( system_prompt="設定変更やリソース削除につながる操作は絶対に推奨しないでください。また、回答には必ず公式ドキュメントの参照URLを含めるようにしてください。" ) # AgentCoreランタイム用のAPIサーバーを作成 app = BedrockAgentCoreApp() # エージェント呼び出し関数を、APIサーバーのエントリーポイントに設定 @app.entrypoint async def invoke_agent(payload, context): # リクエストごとにエージェントを作成し、設定を適用 agent = Agent( model=model, tools=[mcp_client], # MCPClientをツールとして組み込む session_manager=session_manager, # 記憶(STM/LTM)を組み込む hooks=[handler] # ステアリング(ポリシー)を組み込む ) # エージェントをストリーミング呼び出し stream = agent.stream_async( payload.get("prompt") ) # ストリーミングレスポンスをフロントに返却 async for event in stream: yield event # APIサーバーを起動 app.run() -
touch requirements.txtrequirements.txtに以下をコピー&ペーストします。strands-agents strands-agents-tools strands-agents[otel] bedrock-agentcore bedrock-agentcore[strands-agents]依存関係のファイル(requirements.txt)の目的
ファイルを作成する具体的な理由
ステップ 4: AgentCoreランタイムへのデプロイ
作成したエージェントコードをAWS上で動作するAPIサーバーとしてデプロイします。
-
AgentCoreスターターキットのインストール
pip install bedrock-agentcore-starter-toolkit==0.2.2Amazon Bedrock AgentCore スターターキットとは
Amazon Bedrock AgentCore スターターキットは、AWS上で高性能なAIエージェントを「安全に」「速く」「大規模に」構築・運用するために必要なすべてが詰まった、開発者向けの公式ツールセット(CLIおよびライブラリ)です。
これを使用することで、インフラの知識が少なくても、数行のコードでプロ仕様のエージェントをクラウド上に公開できます。スターターキットに含まれる主な内容
このキットは主に以下の3つの要素で構成されています。要素 内容と役割
AgentCore CLI agentcore launch コマンドなどで、AWS上のサーバー(Runtime)やメモリ、セキュリティ設定を自動で構築・デプロイします。Strands Agents SDK エージェントの「脳」を動かすためのオープンソースSDK。Claude 3.5やNovaなどのLLMを使い、ツール呼び出しや推論を制御します。
サンプルテンプレート backend.py や requirements.txt の雛形。これを書き換えるだけで、自分の用途に合わせたエージェントがすぐに作れます。通常と使用した場合での比較
「通常(すべて自前)の開発」と「AgentCoreスターターキット + Strands」を使用した場合の比較解説します。
一言でいうと、通常の開発は「材料集めとキッチン作りから始める料理」ですが、スターターキットは「最新設備の整った厨房で、レシピ通りに作る料理」のような違いがあります。① 開発スピードと手間の比較
通常の開発では、AIの「脳」を作る前に「箱(インフラ)」を作る作業が膨大です。項目 通常の開発(自前) スターターキット使用 環境構築 Docker、サーバー、権限設定を個別に構築。 agentcore launch 一発で最適環境が完成。 ライブラリ管理 各ツールの互換性を自分で検証・修正。 公式SDKが最初から最適化されている。 デプロイ 数日~数週間(インフラ知識が必要)。 数分~数時間(Pythonの知識だけでOK)。 ② 運用性能と安全性の比較
個人開発外で使う場合、この「運用面」の差がリスクの違いになります項目 通常の開発(自前) スターターキット使用 実行時間制限 Lambda等だと15分で強制終了。 最大8時間の長時間処理が可能。 セッション分離 ユーザー間のデータ混入対策を自前実装。 セッションごとに完全隔離された安全な環境。 監視(デバッグ) ログを自前で集計・解析。 思考プロセスが自動で可視化される。 認証管理 APIキーの管理を暗号化して自作。 AgentCore Identity でセキュアに一元管理。 ③ 機能(賢さ)の拡張性の比較
エージェントに「新しい道具(ツール)」を持たせたい時の柔軟性が違います。
・通常の開発: 新しいツールを増やすたびに、プロンプトを調整し、API接続コードを書き、例外処理を手動で追加します。
・スターターキット: 世界標準の MCP (Model Context Protocol) に対応。Notion、Slack、GitHubなどの公式プラグインを、コードをほぼ書かずに「差し込むだけ」でエージェントが使いこなせます。通常開発が向いている人:
・AWSを使わない、または完全に独自のサーバー構成にこだわりがある。
・AIの推論ロジック自体を一から研究・開発したい。スターターキットが向いている人:
・「動くもの」を最速で作って業務に導入したい。
・セキュリティやスケーラビリティ(大人数での利用)を重視する。
・最新のClaude 3.5やAmazon Novaなどの高性能モデルを、最高の環境で使いこなしたい。 -
設定ファイルの自動生成
以下のコマンドを実行し、設定プロセスを開始します。agentcore configure対話形式で質問されますが、以下以外はすべて Enter で OK です。
Entrypoint:backend.pyと入力。-
Existing memory resources found:ステップ2で作成したメモリーの番号(例:[1]など)を入力。
-
ランタイムのデプロイ
以下のコマンドで、ECR、CodeBuild、AgentCoreランタイムなどのAWSリソースが自動で作成され、デプロイが開始されます。
agentcore launchデプロイ完了まで数分かかります。完了後、Runtime ARN が出力されるので、これを控えておきます。
ステップ 5: 動作確認用フロントエンドの作成と実行
デプロイされたAPIサーバーをテストするための簡単なWebインターフェース(Streamlitを利用)を作成します。
-
元の階層に戻る
cd ../ -
frontend.pyの作成
frontend.py を作成し、以下のコードをコピー&ペーストします。
touch frontend.pyfrontend.pyの内容:# 必要なライブラリをインポート import os, boto3, json import streamlit as st # サイドバーを描画 with st.sidebar: # デプロイ後に得られたAgentCoreランタイムのARNを入力 agent_runtime_arn = st.text_input("AgentCoreランタイムのARN") # タイトルを描画 st.title("AWS環境運用支援エージェント") st.write("Strands AgentsがMCP(AWSドキュメント)とLTM(社内ナレッジ)を使って運用を支援します!") # チャットボックスを描画 if prompt := st.chat_input("質問を入力してください(例:IAMポリシーの最小権限原則のベストプラクティスを教えて)"): # ユーザーのプロンプトを表示 with st.chat_message("user"): st.markdown(prompt) # エージェントの回答を表示 with st.chat_message("assistant"): try: # AgentCoreランタイムを呼び出し agentcore = boto3.client('bedrock-agentcore') payload = json.dumps({"prompt": prompt}) response = agentcore.invoke_agent_runtime( agentRuntimeArn=agent_runtime_arn, payload=payload.encode() ) # ストリーミングレスポンスの処理 container = st.container() text_holder = container.empty() buffer = "" for line in response["response"].iter_lines(): if line and line.decode("utf-8").startswith("data: "): data = line.decode("utf-8")[6:] # 文字列コンテンツの場合は無視 if data.startswith('"') or data.startswith("'"): continue # 読み込んだ行をJSONに変換 event = json.loads(data) # ツール利用を検出 if "event" in event and "contentBlockStart" in event["event"]: if "toolUse" in event["event"]["contentBlockStart"].get("start", {}): # 現在のテキストを確定 if buffer: text_holder.markdown(buffer) buffer = "" # ツールステータスを表示 tool_name = event["event"]["contentBlockStart"]["start"]["toolUse"].get("name", "unknown") container.info(f"🔍 {tool_name} ツールを利用しています") text_holder = container.empty() # テキストコンテンツを検出 if "data" in event and isinstance(event["data"], str): buffer += event["data"] text_holder.markdown(buffer) elif "event" in event and "contentBlockDelta" in event["event"]: buffer += event["event"]["contentBlockDelta"]["delta"].get("text", "") text_holder.markdown(buffer) # 最後に残ったテキストを表示 text_holder.markdown(buffer) except Exception as e: st.error(f"エラーが発生しました: {e}") -
Streamlitの実行
StreamlitはPythonだけでデータ分析アプリやAIアプリのフロントエンド(画面)を爆速で構築できるオープンソースのフレームワークです。
今回はAIエージェントの仕様を簡単に確認・実行するために使用します。(本番実装向きではありません)pip install streamlit streamlit run frontend.pyCodeSpacesのポップアップに従ってブラウザでアプリを開くか、ターミナルに表示されたURLにアクセスします。
-
動作確認
アプリのサイドバーに、ステップ4で控えたRuntime ARNを貼り付けます。
以下の質問をして、MCPClientの利用(AWSドキュメント検索)とステアリングが効いているか確認します。
ちゃんと危険と記述してくれていますね。
ステップ 6: エピソード記憶(LTM)へのナレッジの投入
デプロイ後、LTMに社内固有のナレッジを「記憶」させることで、提案されたLTMの役割(過去の障害対応検索)を実現します。
-
LTMにナレッジを投入
Streamlitのチャットで、具体的な過去の事例をエージェントに教え込みます。例: 「先月、NATゲートウェイの誤った設定でコストが急増した。解決策は、夜間はAWS Lambdaで停止する仕組みを導入したことだ。」

-
LTMの検索テスト
ナレッジ投入後、LTMが検索される質問をします。例: 「私が以前話したNATゲートウェイのコスト問題について、解決策はなんだったか?」
(LTMが有効になっていれば、過去のエピソードを踏まえた回答が得られるはずです。)


エピソード記憶がちゃんと実装できている事も確認できましたね。
これで、AWSの公式ドキュメントとナレッジの両方を活用し、ポリシーで制御された「AWS環境運用支援エージェント」が完成します。
所感・まとめ
開発経験はまだ浅いですが、メモリー機能を備えた簡易的なエージェントを構築することができました。
難しい言語での作業が少なく約1時間と短い時間で構築でき、今後の開発速度効率化にとても期待できました。
今後は環境操作などの機能を追加して、完全自動化を実現する「ローカル版Kiro」のような仕組みを作ってみたり、 これまではPythonで実装してきましたが、アップデートによりTypeScriptでも実装可能になったため、複数言語での開発にも挑戦してみたいなーって思います。
年末に向けてPCもお部屋も大掃除しなくてはです。
それでは皆さん良いお年を〜