
こんにちは、SCSKの嶋谷です。
サーバを監視する際には、監視項目と検知条件を決定する必要があります。
監視項目はCPUやメモリ、ログといったように監視項目のイメージが湧きやすいと思います。
これら監視項目に対する検知条件を皆さんは即座に決定することができるでしょうか。
長年サーバ監視の業務に携わっている方であれば、経験則から一般的な設定値を理解しているでしょう。
しかし、経験が浅い方は「CPUはどれくらいになれば異常と判断すればよいのだろう」と即座に判断することが難しいと思います。
Mackerelには、正常時の状態を学習し、異常を検知した際にアラートを発生させる「ロール内異常検知」という機能があります。
今回、この機能が検知条件を決める際の手助けになると考え、実際にロール内異常検知の挙動を確認しました。
ロール内異常検知とは
ロール内異常検知は、機械学習を用いて学習した正常なパターンから外れたメトリックの経過を異常と判断し、アラートを発生させる機能です。指定されたロールに含まれるサーバの過去のメトリックを学習し、正常な動きのパターンを認識します。
ロールに属するサーバのメトリック(CPU、メモリ、ディスク)を過去数十日分学習し、混合ガウス分布を用いて正常/異常の判定を行います。混合ガウス分布を用いることで、昼夜・平日・週末のように「負荷の波があるパターン」でも対応が可能です。
ロール内異常検知のメリットを下記に記載します。
- 複雑な監視ルールの設定が不要
ロール内のメトリックデータを機械学習で自動的に学習して正常時の状態を把握するため、ユーザ自身で細かな閾値を設定する必要がありません。 - 閾値の調整やメンテナンスの手間が少ない
サーバの特性変化に応じて手作業で検知条件を更新する必要がなく、学習モデルは日々更新される仕様となっています。
そのため、メンテナンスの頻度が減少します。 -
サーバ監視の初心者でも導入しやすい
専門知識が無くても、簡単な設定で異常検知を実装することが可能です。
詳細は下記をご参照ください。
混合ガウス分布(GMM)の意味と役立つ例 – 具体例で学ぶ数学
ロール内異常検知による監視をおこなう – Mackerel ヘルプ
設定手順
構成
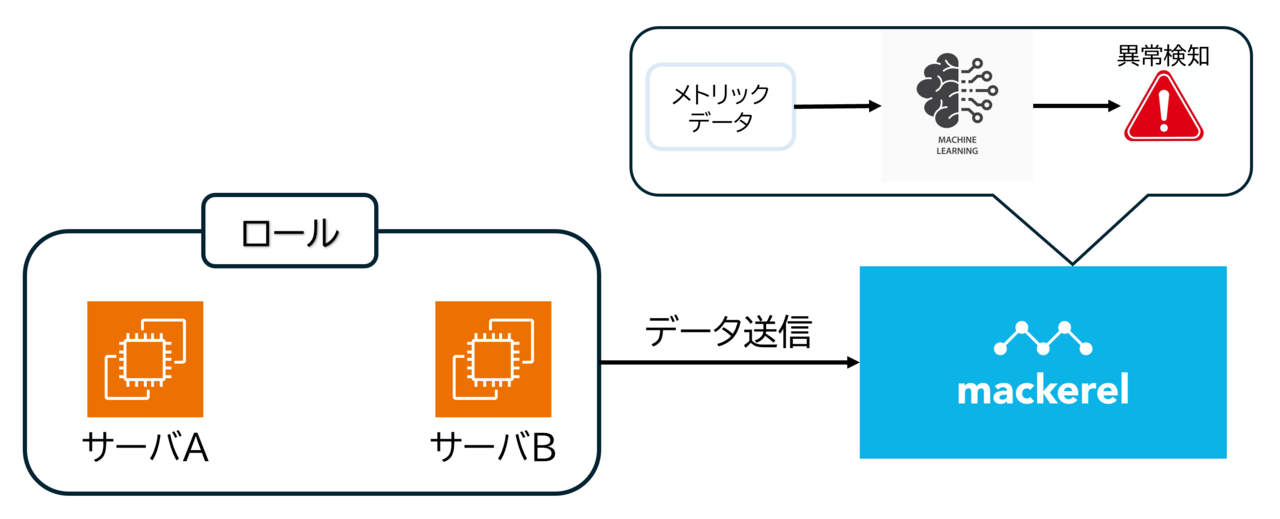
今回の記事ではAWSのEC2を2台を作成して、同じロールに含めて検証を実施しました。
ロール内に含まれるサーバのメトリックデータをMackerelに送信し、Mackerelでロール内異常検知の設定を組み込みことで簡単に異常検知を実装することができます。
設定方法
- Mackerelコンソールの監視ルールタブを選択し、「監視ルール追加」をクリック
- ロール内異常検知をクリック
- 下記情報を入力
・対象のロール:監視するロールを選択
・センシティビティ:検知する変化の粒度を選択(sensitive、normal、insensitiveから選択)
・最大試行回数:アラート発生条件の異常状態継続回数 - 「作成」をクリック
今回私が作成した設定の一例を下記に示します。
今回は小さな変化も検知できるようにセンシティビティを「sensitive」に設定しています。
※ロール内異常検知では、エージェントが収集するシステムメトリック全体を学習の対象としているため、学習対象を個別のメトリックに絞り込むことはできません。メトリックについては下記をご参照ください。
メトリック仕様 – Mackerel ヘルプ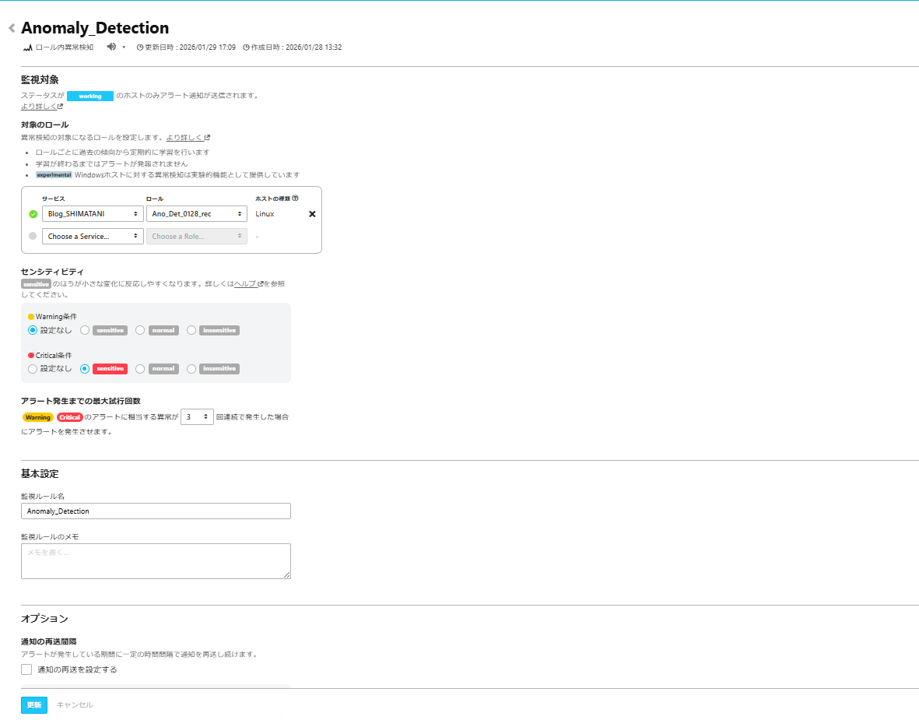
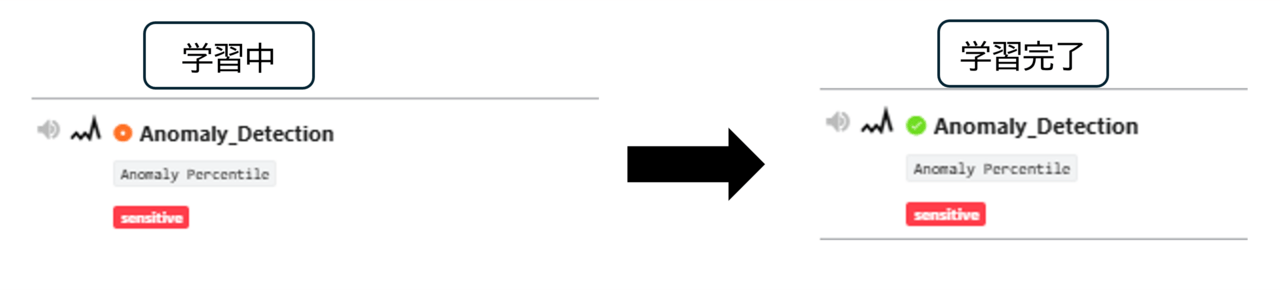
監視ルールが作成されると、機械学習による学習が開始されます。
学習中は作成した監視ルールに赤いチェックマークが表示され、完了すると緑のチェックマークが表示されます。
これにより、設定が完了し異常検知を実施することができます。
異常検知検証
今回はCPU、Memory、Diskにそれぞれ負荷を与え、ロール内異常検知の挙動を確認しました。
検証に用いたサーバは検証用に作成したため、サーバ上にアプリケーションなどは構築していません。そのため、CPUやMemoryは常時低負荷の状態で推移しています。
CPU
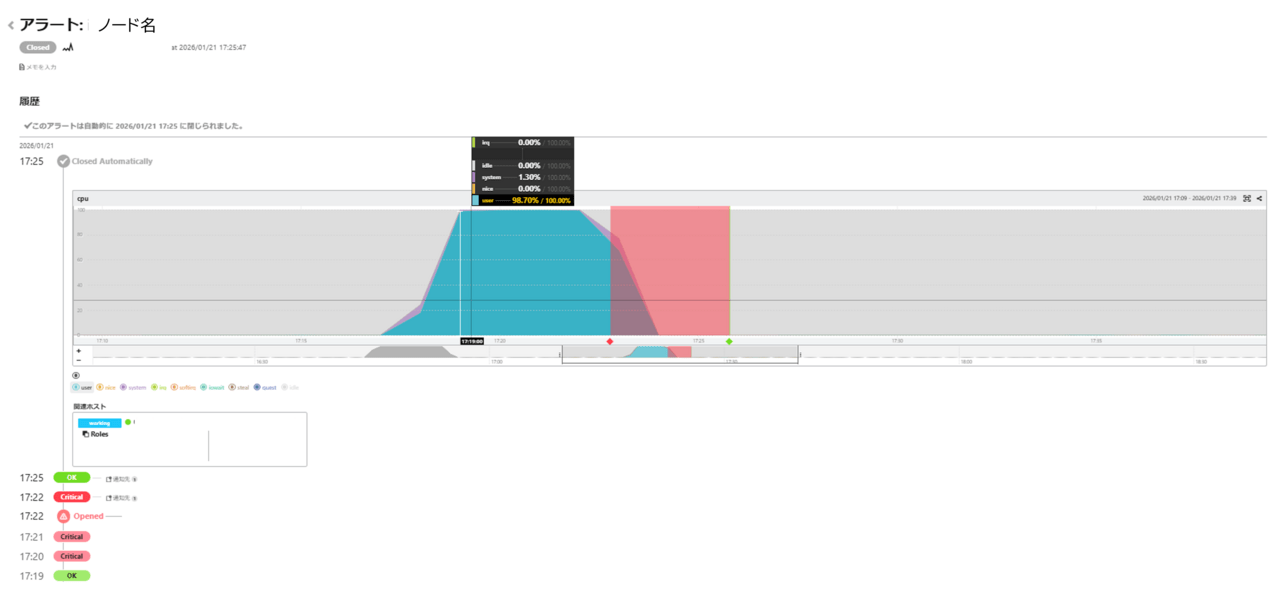
下記コマンドでサーバ1台に対して、CPU使用率が100%で5分間推移するように負荷を与えてみるとアラートが発生しました。
stress-ng --cpu 0 --cpu-load 100 --timeout 5m
発生したアラート内容は以下となります。常時0%の状態から負荷を与えることで通常時とは異なると判断してアラートが発生しました。
掲載している図は100%で負荷を与えた場合ですが、60%や80%の負荷を与えた場合でも同様にアラートが発生しました。
CPUの中でもcpu.user.percentage(アプリケーションがCPUを利用した割合)が高騰しています。
Memory
下記コマンドでサーバ1台に対して、Memory使用率が60%で5分間推移するように負荷を与えてみるとアラートが発生しました。
stress-ng --vm 1 --vm-bytes 60% --timeout 5m
発生したアラート内容は以下で、Memory使用率ではなくCPU使用率でのアラートが発生しました。

疑問に思い、ヘルプページを確認してみると以下の記載がありました。
「ロール内異常検知によるアラートでは、該当ホストで普段と最も様子が異なるメトリックのグラフを表示します。各種通知でもこのグラフが表示されるので、障害の初期対応に活用できます(必ずしも障害の根本原因を表わしているというわけではありません)。」
Disk
下記コマンドでサーバ1台に対して、Disk使用率が60%で5分間推移するように負荷を与えてみるとアラートが発生しました。
stress-ng -d 1 --hdd-bytes 4G --temp-path パス --timeout 5m
発生したアラート内容は以下で、CPU使用率の高騰でした。こちらもMemoryでの検証と同様にDisk使用率の高騰と共にCPU使用率も高騰してしまい、CPU使用率の高騰が通常と最も異なると判定されています。
また、CPUの中でもCPU・Memoryの検証で高騰していたcpu.user.percentageとは異なり、cpu.iowait.percentage(ディスク・ネットワーク I/Oの完了待ちでアイドル状態になっている割合)が高騰しています。
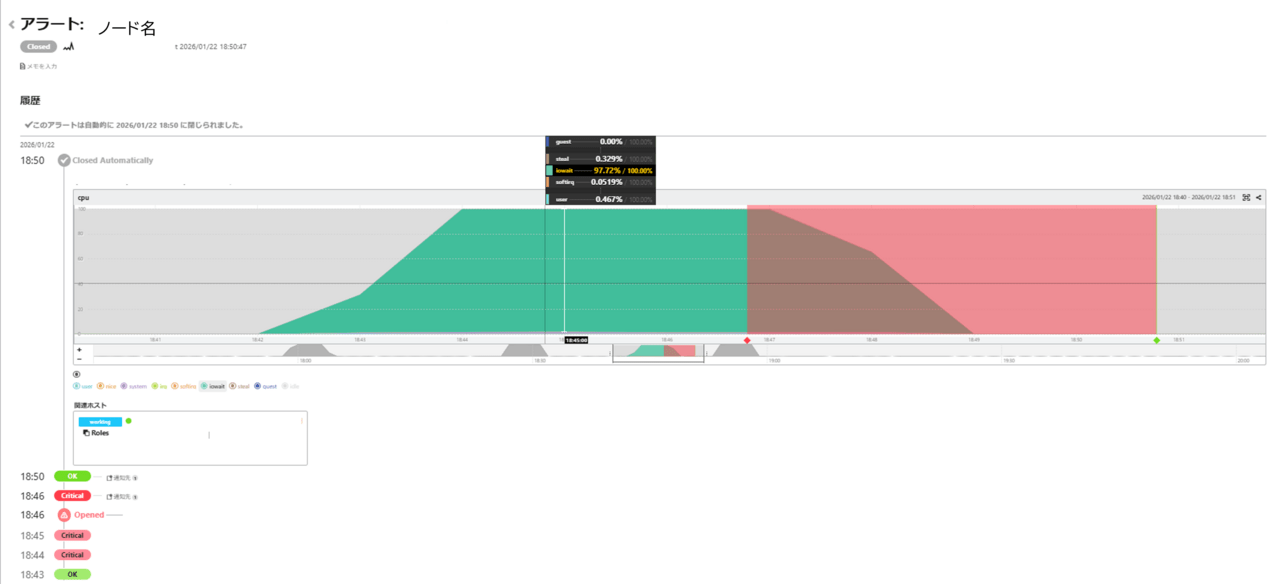
CPU・Memory・DiskでCPUアラートが発生しましたが、具体的に高騰している値は異なるものでした。
2台同時に負荷をかけた場合
構成図で示した通り、今回はロール内に2つのサーバを含めています。
これまでは1台のみに負荷を与えることで検証実施しましたが、ここでは2台同時に負荷をかけた場合の挙動について確認します。
下記のコマンドで、1台のみで検証したDiskとは異なるDiskに負荷を与えました。
stress-ng -d 1 --hdd-bytes 8M --temp-path パス --timeout 5m
結果としては、異なるアラートとして2台それぞれでアラートが発生しました。メトリックのグラフ推移としては同様の推移となっております。
ただ、今回高騰しているCPUのメトリックはcpu.system.percentage(カーネルが使用している割合)で、負荷を与えるDsikによっても挙動が変わることに驚きました。ホスト単位でアラートが発生することで、異常状態のホストを見逃すことはないと感じました。
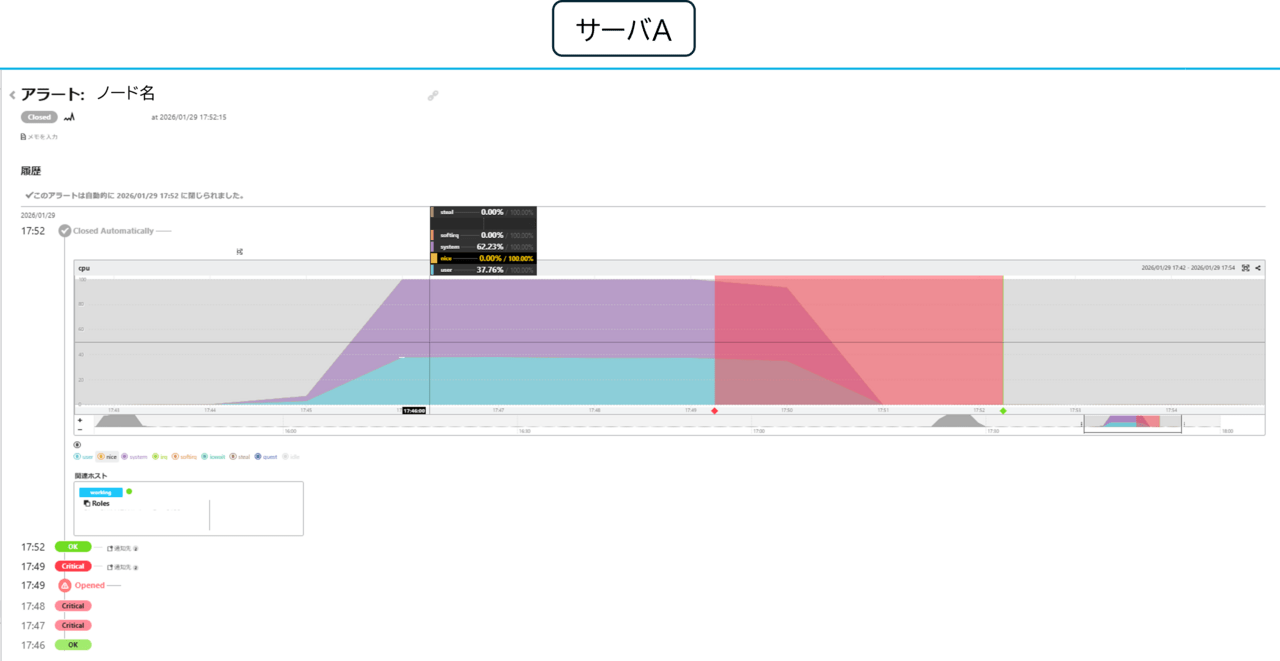
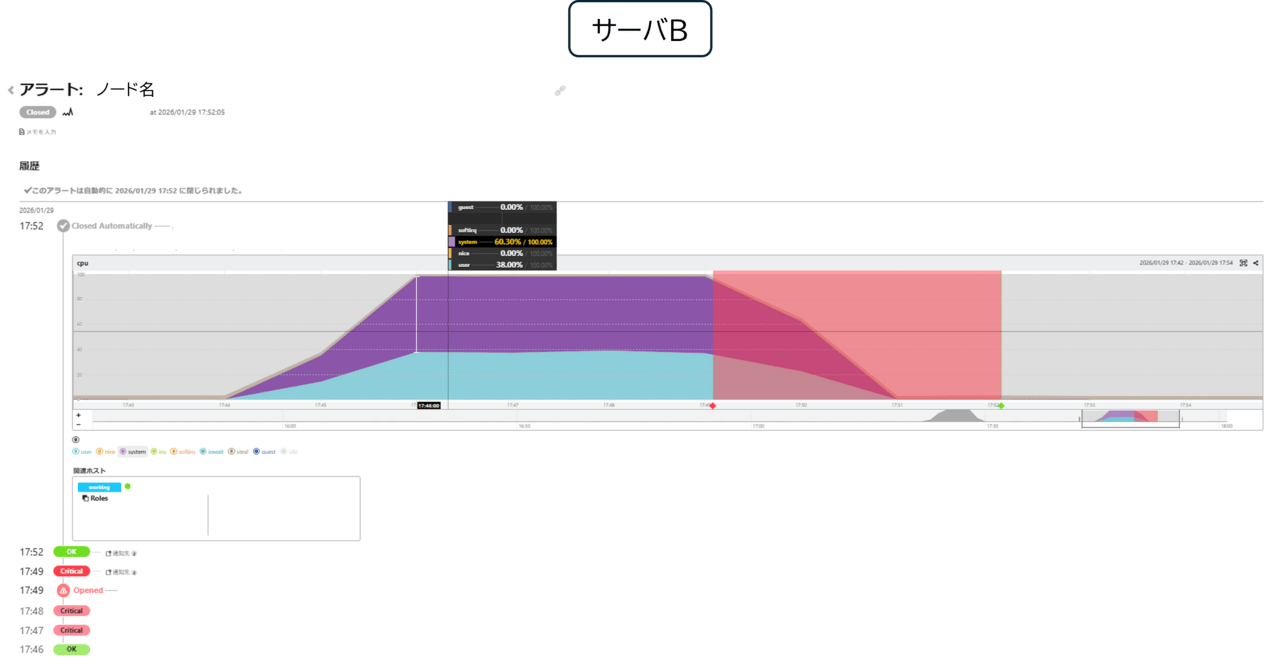
小話
今回のブログを書くにあたり、まず検証でアラートが発生することを確認しました。
この際に、結果のスクリーンショットは撮影していませんでした。
ブログ執筆のため、同様の事象でアラートを発生させようとするとアラートが発生しませんでした。
1/10と1/20に下記コマンドを実行すると、1/10ではアラートが発生し1/20では発生しませんでした。
stress-ng --cpu 0 --cpu-load 100 --timeout 5m --metrics
はてな社に問い合わせてみると、学習モデルは定期的に更新されているようで、1/10時点での学習モデルと1/20時点での学習モデルは同じものではありませんでした。1/20の学習モデルは検証で負荷を与えたメトリックデータを含んで学習されていたため、同じ事象(正常)とみなしてアラートが発生しなかったようです。
新しくサーバを作成して同様の事象を発生させることが必要でとても苦労しました。
ただ、学習モデルが自動的に日々更新される点はとても便利な機能だと感じました。
まとめ
今回はMackerelのロール内異常検知の機能に触れてみました。
サーバへ急激に負荷を与えると、正しく異常が検知されたのでAIのすごさも再認識しました。
ヘルプページにも記載されている通り根本原因を検知できるわけではないので、使い方が重要だと感じました。
ロール内異常検知は正常時と異なる挙動を検知する機能ですので、導入部分で触れた閾値決定の手助けで利用するのは難しいと感じました。また、学習モデルに使用されるデータは過去数十日のため、月一回の定期作業で発生する負荷を異常として判断する可能性もあります。
そのため別の用途として、サーバの挙動が変化したことに気付き、根本原因調査の足掛かりとして利用できるのではないかと感じました。
ただ、今回は実運用で使用しているサーバを対象としていないため、今後は実運用のサーバでの挙動も確認して利用用途考えていきたいです!
最後までお読みいただきありがとうございました!