
SCSKの畑です。
先般のエントリの内容は MySQL における特定障害シナリオからの復旧手順の検証に関連するものでしたが、引き続き今回はその障害シナリオや復旧手順について説明したいと思います。また、その復旧手順に関連する内容として RDS/Aurora (MySQL) におけるバイナリログの確認・取得方法についても合わせて紹介します。
データベースの構成について
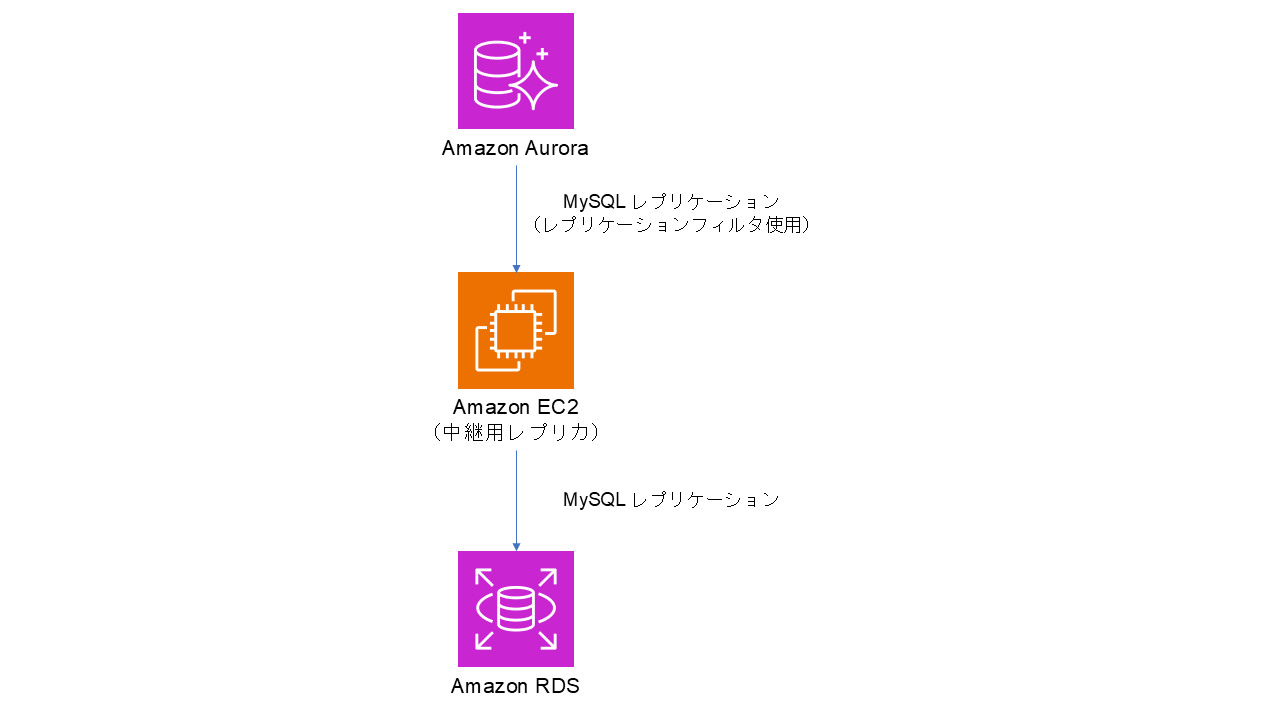
まず、本エントリで言及していくデータベース環境の構成について説明します。
具体的には、以下の通り Aurora ⇒ EC2 上の MySQL ⇒ RDS という流れで、ログポジションベースのレプリケーションが構成されている環境となります。また、Aurora ⇒ EC2 上の MySQL 間ではレプリケーションフィルタを使用しており、特定のテーブルに対する更新のみをレプリケーションしています。よって、必然的に EC2 上の MySQL ⇒ RDS 間においても同じテーブルに対する更新のみがレプリケーションされます。
また、Aurora 及び RDS はそれぞれ別の目的で複数のアプリケーションから使用されており、両方のデータベースを使用しているアプリケーションも存在します。
また、MySQL データベースにおけるレプリケーションの概要については、概要を同じ課の野上さんが昨年度まとめてくれていたので、そちらも合わせてご覧いただければと思います。

検証対象の障害シナリオ及び復旧手順について
検証対象の障害シナリオ
EC2 の AZ 障害が対象のシナリオとなります。
本案件における Aurora や RDS はマルチ AZ 構成とするため、単一 AZ 障害が発生した場合でもクラスタ or インスタンスがフェイルオーバすることで継続稼働できます。対して EC2 の場合は単一 AZ 上にのみ構成されるため、同 AZ で障害が発生した場合は継続稼働できません。EC2 の復旧手順自体は発生した AZ 障害の内容によりケースバイケースで変わってくると思われますが、どちらにせよ EC2 上で稼働していた MySQL のデータが障害発生直前の状態で復旧できる可能性は低いと考えるべきです。
よって、 EC2 の復旧後に MySQL のデータを復旧し、上流の Aurora 及び下流の RDS 間とレプリケーションを再開するための手順について検討する必要がありました。
復旧手順
こちらは先般のエントリでも触れていた通り、「MySQL のデータをマネージド PITR で特定時刻のデータ断面にリカバリした後、その時刻以降のトランザクションログを対象としてレプリケーションすることで復旧する」流れとなります。具体的には以下の通りです。
- EC2 インスタンスを AMI から再作成
- AZ 障害により AMI より EC2 インスタンスの再作成が必要という前提のため
- Aurora のマネージド PITR 機能を使用して、(できる限り最新の)特定時刻のデータ断面にリカバリした Aurora を作成
- AMI に含まれる EC2 上 MySQL のデータの一貫性/整合性が保証されていない前提のため
- 指定した「特定時刻」以降のバイナリログが Aurora 上に全て保持されていること
- 1.で作成した Aurora から、EC2 及び RDS にレプリケーションしている対象のテーブルデータをエクスポートし、EC2 及び RDS にインポート
- 1.で指定した「特定時刻」に該当するバイナリログ(トランザクションログ)のログポジションを、Aurora 上に保持しているバイナリログから特定し、EC2 のレプリケーション開始ポジションに設定
- EC2 上のバイナリログの現在のログポジションを確認し、RDS のレプリケーション開始ポジションに設定
- EC2 及び RDS でレプリケーションを再開
今回はレプリケーション中継用の EC2 で障害が発生していますので、EC2 だけではなくその下流の RDS についてもレプリケーションの対象テーブルデータを特定時刻のデータ断面にリカバリする必要があります。この部分が手順 2-3 ですね。その上で、特定時刻以降のトランザクションログを対象としてレプリケーションを再開する部分が手順 4-6 にあたるのですが、ここが少々難解です。
まず、レプリケーションの設定は、レプリケーションのターゲットとなる MySQL で行う必要があります。つまり、Aurora ⇒ EC2 のレプリケーションについては EC2 上で、EC2 ⇒ RDS のレプリケーションについては RDS 上で設定します。そして先述の通りログポジションベースのレプリケーションを使用しているため、レプリケーション再開(再構成)にはレプリケーションのソースとなる MySQL のバイナリログポジションを指定する必要があります。つまり、RDS では EC2 のバイナリログポジション、EC2 では Aurora のバイナリログポジションをそれぞれ指定することになります。
この内、EC2 についてはレプリケーション中継用であり、元々 Aurora からのレプリケーションによる更新以外は発生しません。よって、手順 3 の完了後は 手順 6 によるレプリケーション再開までデータベースに更新が発生せず静止点が保たれるため、RDS のレプリケーション再開時に指定するログポジションは EC2 上のバイナリログの現在のポジションをそのまま使用すれば OK です。
一方で、EC2 の AZ 障害が発生しても Aurora は先述の通り継続稼働できるため、データの静止点は確保できないことから、EC2 と同じような方法ではバイナリログポジションの確認ができません。よって、代わりに Aurora 上のバイナリログの内容を確認して、手順 1 で指定した特定時刻に該当するログポジションを特定する必要があるということになります。つまり手順 4 ですね。
そして、この「Aurora 上のバイナリログの内容確認」手順が未検証であったため、やってみたところ意外と手間取ったというのが次セクションの話になります。
補足:MySQL のレプリケーション構成方式について
さて、ここまで読んでお気づきの方もいると思うのですが、本構成で使用しているログポジションベースのレプリケーション構成方式が、実のところ上記のように複雑な手順を必要とした理由となっています。
MySQL のレプリケーション構成方式は以下2種類があり、新しいのは GTID を使用した方式です。(と言っても初出は MySQL 5.6 なのでかれこれ 10 年以上前のことになりますが、、初めて案件で触ったのも 2013 年でした)
- GTID(Global Transaction ID)を使用したレプリケーション構成
- バイナリログポジションを直接使用した使用したレプリケーション構成
GTID の説明は先般紹介した野上さんのエントリから引用させて頂きますが、以下の通りです。
GTIDとは・・・
発生元のサーバー (ソース) でコミットされた各トランザクションに関連付けられる一意の識別子です。 この識別子は、レプリケーション構成内のすべてのサーバーで一意です。
GTIDを使用することで、どのサーバにどのトランザクションまで実行してあるのかがわかるため、レプリケーション設定時にレプリケーションを始めるトランザクションを自動で設定してくれます。
よって、もし GTID を使用してレプリケーションを構成していた場合は、さきほど説明した一連の手順のようにバイナリログポジションを手動で導出及び再設定する必要がなくなるため、以下のように手順が大幅に簡略化されます。
- EC2 インスタンスを AMI から再作成
- Aurora のマネージド PITR 機能を使用して、特定時刻のデータ断面にリカバリした Aurora を作成
- 1.で作成した Aurora から、EC2 にレプリケーションしている対象のテーブルデータをエクスポートし、EC2 にインポート
- EC2 及び RDS でレプリケーションを再開
ここ最近は MySQL のレプリケーションの構成方式は基本的に GTID ベースが使用されることが多いため、本案件でも変更可否を打診してみたのですが、以下 URL のような GTID の制約に抵触していないかの影響調査、及び抵触している場合のアプリケーション改修が AWS への移行期間(カットオーバー)に合わなかったため、本障害時の想定復旧時間を許容頂く前提で最終的に見送りとなりました。

バイナリログの確認自体はできるけど・・
さて、話が少々脇道に逸れてしまったので本題に戻りますが、「Aurora 上のバイナリログの内容確認」手順を検証すべく、マネジメントコンソールから Aurora のログセクションを確認してみたのですがバイナリログは見当たらず。ドキュメントも確認してみたのですが同様でした。いわゆる通常のログファイルとは扱いが異なるので、同じセクションにないこと自体は腑に落ちました。

改めて調べてみると、Aurora (RDS) からのバイナリログの取得(ダウンロード)については mysqlbinlog ユーティリティを使用する必要があることが分かりました。正直ちょっと驚きではありましたが、どちらにせよバイナリログの内容確認(=PITR 対象の特定時刻に対応するログポジションの導出)にはこのユーティリティが必要なので、手順上は特に問題ありません。

ということで、後は Aurora (MySQL) 上からバイナリログ情報を確認して、ダウンロード&内容確認する必要のあるバイナリログを特定できれば一通り手順を確立できると考えました。先述の通り、PITR 対象の特定時刻における更新が含まれているバイナリログが取得できれば良いので、バイナリログの最終更新日時だけでも分かれば対象が特定できると思い、Aurora (MySQL) 上からバイナリログ情報を確認してみたところ、、
mysql> show binary logs; +----------------------------+-----------+-----------+ | Log_name | File_size | Encrypted | +----------------------------+-----------+-----------+ | mysql-bin-changelog.000009 | 743393 | No | | mysql-bin-changelog.000010 | 214 | No | | mysql-bin-changelog.000011 | 214 | No | | mysql-bin-changelog.000012 | 157 | No | +----------------------------+-----------+-----------+ 4 rows in set (0.01 sec)
なんと、バイナリログファイルの最終更新日時は MySQL 上の情報に含まれないんですね。そこで、どうやってバイナリログの最終更新日時を確認していたかを MySQL を良く触っていた当時の案件資料などから確認したところ、、OS のファイルシステム上から最終更新日時を確認する手順となっていました。
もちろん当然ながら、Aurora/RDS 上ではこの方法は使えません。
さて困ったということで本腰を入れて色々調べてみたのですが、結論から言うと筋の良い方法がなかったため、最終的な手順としては以下の通り、ある意味繰り返し実行を前提とするようなあまりスマートではないものになってしまいました。。
- show binary logs 文でバイナリログの一覧を取得
- mysqlbinlog で最新のバイナリログ(原則ファイル名における通し番号が最も大きいもの)を取得し、そのバイナリログ内に PITR 対象とする特定時刻が含まれているかを確認
- PITR 対象とする特定時刻が含まれていれば、そのログポジションを取得
- PITR 対象とする特定時刻が含まれていなければ、次に新しいバイナリログを取得し同じ確認を繰り返す
mysqlbinlog を使用した Aurora/RDS 上のバイナリログの取得・内容確認手順
ということで、最後に上記手順における mysqlbinlog のコマンド例についてまとめて本エントリを終わりたいと思います。なお、使用できるオプションについては以下の MySQL 公式マニュアルなども合わせてご参照ください。

Aurora/RDS から対象のバイナリログをダウンロード
こちらは特に難しくないですが、一応ポイントだけ書いておきます。
$ mysqlbinlog --host=<Aurora/RDSのエンドポイント名> --port=<Aurora/RDSのポート番号> --user=<ユーザ名> --password --read-from-remote-server --raw --verbose --result-file=<バイナリログの保存先> <ダウンロードするバイナリログ名> Enter password: <使用するユーザのパスワードを入力>
- –read-from-remote-server オプションにより、リモートサーバ(Aurora/RDS)からバイナリログを取得
- データベース接続に使用するユーザには REPLICATION SLAVE 権限が必要
- –raw オプション及び –verbose オプションは基本付けておくと良さそう(今回の用途だと –verbose は不要かも)
ダウンロードしたバイナリログ内における特定時刻以降のログポジションを取得
こちらの取得(導出)方法は複数あるとは思いますが、一例として記載します。
$ mysqlbinlog --start-datetime="<開始時刻(特定時刻)>" <バイナリログファイルパス> | head -n 20
このコマンドを実行すると以下のような出力結果が得られます。以下実行例では指定したバイナリログにおける 2026-01-21 14:05:32 以降の内容を取得しています。
$ mysqlbinlog --start-datetime="2026-01-21 14:05:32" binlog/mysql-bin-changelog.000004 | head -n 20 # The proper term is pseudo_replica_mode, but we use this compatibility alias # to make the statement usable on server versions 8.0.24 and older. /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; DELIMITER /*!*/; # at 4 #260119 2:34:34 server id 1770264728 end_log_pos 126 CRC32 0x46d7316f Start: binlog v 4, server v 8.0.42 created 260119 2:34:34 at startup ROLLBACK/*!*/; BINLOG ' OphtaQ+YGIRpegAAAH4AAAAAAAQAOC4wLjQyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAA6mG1pEwANAAgAAAAABAAEAAAAYgAEGggAAAAICAgCAAAACgoKKioAEjQA CigAAW8x10Y= '/*!*/; # at 1450948 #260121 14:05:32 server id 1770264728 end_log_pos 1451027 CRC32 0x5369edb0 Anonymous_GTID last_committed=4592 sequence_number=4593 rbr_only=yes original_committed_timestamp=1769004332197054 immediate_commit_timestamp=1769004332197054 transaction_length=311 /*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/; # original_commit_timestamp=1769004332197054 (2026-01-21 14:05:32.197054 UTC) # immediate_commit_timestamp=1769004332197054 (2026-01-21 14:05:32.197054 UTC) /*!80001 SET @@session.original_commit_timestamp=1769004332197054*//*!*/; /*!80014 SET @@session.original_server_version=80042*//*!*/;
あまり可読性は高くないのですが、上記出力結果における「# at」に続く数値がログポジション、その次の行の「#」に続くタイムスタンプがそのポジションに対応する時刻をそれぞれ示しています。また、mysqlbinlog ユーティリティの仕様として「# at 4」から始まるバイナリログ内の最初のログエントリ(7-14 行目)が必ず含まれています。–start-datetime で指定した時刻以降のログエントリが対象のバイナリログ内に含まれている場合は、その直後(15行目)以降に出力されます。上記実行例の場合は指定した時刻(2026-01-21 14:05:32)の更新が記録されていることが 16 行目から分かります。
よって、先述した復旧手順において確認すべきポイントは次の 2 つとなります。
- 最初のログエントリにおけるタイムスタンプが、PITR 対象の特定時刻より前の時刻であること
- –start-datetime で指定する時刻以降のログエントリが含まれていること
- –start-datetime で指定する時刻以降のログエントリが含まれていない場合、最初のログエントリのみが表示される
よって、仮に先述した一連の復旧手順において、上記時刻を指定して PITR したデータを EC2 上の MySQL にインポートした場合、EC2 上でレプリケーション再開のために指定すべきバイナリログファイルは「mysql-bin-changelog.000004」、ポジションは「1450948」となります。
$ mysqlbinlog --start-datetime="2026-01-21 14:05:32" binlog/mysql-bin-changelog.000004 | egrep -A 1 "^# at" | head -n 20 # at 4 #260119 2:34:34 server id 1770264728 end_log_pos 126 CRC32 0x46d7316f Start: binlog v 4, server v 8.0.42 created 260119 2:34:34 at startup -- # at 1450948 #260121 14:05:32 server id 1770264728 end_log_pos 1451027 CRC32 0x5369edb0 Anonymous_GTID last_committed=4592 sequence_number=4593 rbr_only=yes original_committed_timestamp=1769004332197054 immediate_commit_timestamp=1769004332197054 transaction_length=311 -- # at 1451027 #260121 14:05:32 server id 1770264728 end_log_pos 1451119 CRC32 0xb1f278f0 Query thread_id=28836 exec_time=0 error_code=0 -- # at 1451119 #260121 14:05:32 server id 1770264728 end_log_pos 1451184 CRC32 0x4c427a20 Table_map: `repl_test`.`record_table` mapped to number 122 -- # at 1451184 #260121 14:05:32 server id 1770264728 end_log_pos 1451228 CRC32 0x3e65d56d Write_rows: table id 122 flags: STMT_END_F -- # at 1451228 #260121 14:05:32 server id 1770264728 end_log_pos 1451259 CRC32 0xf59a6d5b Xid = 1459644 -- # at 1451259 #260121 14:05:32 server id 1770264728 end_log_pos 1451338 CRC32 0xc31d6b97 Anonymous_GTID last_committed=4593 sequence_number=4594 rbr_only=yes original_committed_timestamp=1769004332431555 immediate_commit_timestamp=1769004332431555 transaction_length=311
まとめ
ちょっと想定以上に長くなってしまったこともあり、2本構成のエントリの前半を構成説明~復旧手順まで、後半を Aurora/RDS 特有のトピックとしてまとめる方が収まりが良かった気がします、、が、先般のエントリではマネージド PITR の挙動にフォーカスして説明したかったこともありご容赦ください。個人的にあの挙動は結構衝撃的だったので。。
また、mysqlbinlog 自体は MySQL を触っていれば多少なりとも馴染みのあるユーティリティではあるのですが、RDS/Aurora のバイナリログを取得するために使用することになるとは思いませんでした。マネジメントコンソールから取得できるようになっていると便利だなと思いつつ、必要となるケースは少ないから仕方ないかなとも思います。
ただ、バイナリログの一覧や更新日時については、マネジメントコンソールなり AWS CLI なり、別の手段で確認できるようにしておいて欲しいところです。MySQL 側から確認の術がないという仕様も同じくらいどうかとは思うんですけど、結果的にこの点を確認するためにやや非効率な手順が必要となってしまっているのは否めず。サーバレスアーキテクチャが当たり前になりつつ昨今、マネージドサービスの制約である「OS レイヤーを直接触れない」ことの弊害を久々に感じた出来事でした。
本記事がどなたかの役に立てば幸いです。
なお、AMI に含まれる EC2 上 MySQL のデータの一貫性/整合性が保証されており、かつそのデータ断面の時刻以降のバイナリログが Aurora 上に全て保持されている前提であれば手順 2 は不要です。この場合、手順 3 では EC2 上 MySQL のデータを RDS にエクスポート/インポートすることになります。
ただし、この方式では定期的に MySQL 及び EC2 を停止して AMI を取得する必要があるため、その間は Aurora ⇒ RDS 間のレプリケーションが実質的に停止してしまいます。その時間を許容できるかどうかが採用可否に直結しますが、本案件では NG だったため採用に至りませんでした。
また、AMI の取得間隔によって RTO が増大してしまうというのも考慮すべきポイントです。例えば 1 日間隔で AMI を取得していた場合は、障害発生のタイミング次第で最大 1 日程度のバイナリログを Aurora ⇒ EC2 ⇒ RDS と再度レプリケートする必要があるため、最終的な復旧までより多くの時間を要してしまう可能性があるためです。上記手順の場合は手順 2 においてできる限り最新の特定時刻を指定するようにしているため、レプリケート対象のバイナリログの量はより小さくなります。