

こんにちは、SCSK林です!
様々なデータ活用が推進される中、データの蓄積場所(データレイク)と分析基盤を異なるクラウドで運用するようなケースもあると思います。一度AWS S3に溜まった膨大なデータを動かすことは容易ではありません。一方で、分析層ではGoogle CloudのBigQueryが持つクエリ性能や、マネージドなETLサービスを活用したいというニーズがあります。
私が担当した某プロジェクトでは、この「AWSにデータ、Google Cloudで分析」というハイブリッド構成を、完全閉域網で実現することが求められました。本記事では、100以上のインターフェースを抱える大規模なデータ連携基盤において、AWSのネットワーク機能をいかに駆使して「セキュア・低遅延・低運用コスト」を実現したか、その設計思想を解説します。
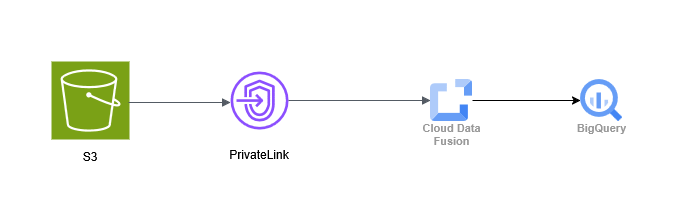
アーキテクチャ概要:Amazon S3 × Google Cloud Data Fusion
今回のアーキテクチャの主役は、Amazon S3とGoogle Cloud Data Fusionです。
システム構成の概要
- Storage (AWS) : S3。数百万レコードにおよぶ日次の業務データが蓄積されるデータレイク。
- ETL (Google Cloud) : Cloud Data Fusion。GUIベースでパイプラインを構築・管理。
- Network : AWS Direct Connect ⇔ Partner Interconnect による専用線接続。
- Security : インターネットを一切経由しない閉域網構成。
解決すべき技術的課題
- 接続性の確保 : 専用線経由でGCPからS3へどうやって「プライベートIP」でアクセスするか。
- 名前解決(DNS) : 異なるクラウド間で、複雑なインフラを立てずにどうやってS3のFQDNを解決するか。
- スケーラビリティ : 100を超えるインターフェースのトラフィックをどう効率的に捌くか。
【技術的ポイント①】Gateway型を棄却し、PrivateLinkを選定
AWSでS3へのプライベートアクセスを考える際、まず頭に浮かぶのは「Gateway VPC Endpoint」でしょう。しかし、本プロジェクトでは「Interface VPC Endpoint」を使用しました。
Gateway Endpointの仕様的限界
S3 Gateway Endpointは、VPCのルートテーブルを書き換えることで機能します。しかし、この仕組みは「VPCの外部(Direct ConnectやVPNの向こう側)」からは利用できないという制約があります。Google CLoud側から専用線経由でアクセスしようとしても、Gateway Endpointへルーティングを飛ばすことはできません。
この制約を回避するためには、VPC内にForward Proxy(Squid等を搭載したEC2)を立てる必要がありますが、これは「サーバーレス・マネージド」というプロジェクトの方針に反し、運用コストと単一障害点(SPOF)のリスクを増大させます。
Interface VPC Endpoint (PrivateLink) の採用
今回使用したのが、Interface VPC Endpoint (AWS PrivateLink) です。 PrivateLinkは、VPC内のサブネットにENI(Elastic Network Interface)を払い出し、S3への通信をそのIPアドレス経由で行います。
- メリット : 専用線(Direct Connect)越しに、Google CloudからS3のプライベートIPへ直接ルーティングが可能。
- 運用の排除 : EC2のようなOS管理が不要。AWSが提供するフルマネージドな高可用性をそのまま享受できる。
100以上のIFが集中する基盤において、インフラの保守をAWSにオフロードできるメリットは、処理量に応じた課金を十分に正当化できるものでした。
【技術的ポイント②】シンプルなマルチクラウドDNS設計
PrivateLinkを採用した際、次に問題となるのが「DNSの名前解決」です。Google Cloud上のData Fusionから、AWS S3のエンドポイント名をどう解決するか。
通常、ここでも「Route 53 Resolver Endpointを立てて、GCP Cloud DNSと条件付き転送(Forwarding)を設定する」という構成が検討されます。しかし、今回はシンプルで保守性の高い方式を採用しました。
PrivateLinkのDNS特性の活用
AWS PrivateLinkでS3エンドポイントを作成すると、vpce-xxxx.s3.region.vpce.amazonaws.com のような専用のFQDNが払い出されます。このFQDNは、パブリックなDNSサーバから名前解決しても、VPC内のプライベートIPアドレスを返却するという特性を持っています。
Google Clooud の Cloud DNSでのCNAME変換
この特性を活かし、Google Cloud側の設定のみで名前解決を完結させました。 具体的には、Cloud DNSにおいて、Data Fusionが参照するS3の接続先ドメイン名を、AWSから払い出されたPrivateLink用のFQDNへCNAMEレコードとして登録したのです。
- 構成フロー:
- Data Fusionが
s3.ap-northeast-1.amazonaws.comへアクセス。 - Cloud DNSがそれを PrivateLinkのFQDN(
vpce-xxxx...)にCNAME解決。 - そのFQDNをパブリックDNS経由で解決すると、AWS VPC内のプライベートIPが返る。
- 専用線(Direct Connect)経由で、そのプライベートIPへ直接通信。
- Data Fusionが
この設計により、AWS側にResolver Endpointという追加の有償リソースを立てることなく、また複雑なクロスクラウドのDNS転送設定も不要にしました。
まとめ
本プロジェクトを通じて、AWSとGoogle Cloudのいいとこ取りをしたハイブリッドデータ連携基盤が完成しました。
- 安定性 : 100以上のインターフェース、日次数百万レコードの転送において、専用線とPrivateLinkの組み合わせにより極めて低いエラー率と安定したスループットを維持。
- コスト最適化 : 冗長化されたプロキシサーバやDNSフォワーダーの構築・運用工数を削減し、純粋なデータ処理に集中。
- 拡張性 : 今後インターフェースが増加しても、ネットワーク経路やDNS設定を変更することなく、Data Fusion上のパイプライン追加だけで対応可能な拡張性を確保。
AWSの各サービスは単体でも強力ですが、その特性を深く理解することで他クラウドとの連携において価値を発揮すると感じました。
この記事がどなたかのお役に立つと幸いです。