
こんにちは、SCSKの松岡です🕸️
Webクローリングおよび名寄せの検証において、AWS lambdaとAmazon Bedrockを活用したデータ収集アーキテクチャを検討した際の試行錯誤を整理しました。
従来のルールベースのクローリングと比較し、生成AIを用いた柔軟な情報抽出を取り入れることで、サイト構造の差異に耐えるデータ収集方式をどのように実現したか、また収集データと既存マスタを突合する名寄せの課題についても紹介します。
背景

データ活用基盤において、外部サイトからの商品情報を収集し、分析や業務活用に利用したいというニーズがありました。特に、複数サイトに分散した商品情報を横断的に収集し、一覧化・比較可能な形で整理することが求められています。
一方で、Webクローリングはサイトごとに構造が異なり、HTMLの変更や表記ゆれの影響を受けやすく、安定したデータ取得が難しいという課題があります。従来のルールベースの実装では、サイトごとに個別対応が必要となり、対象サイトの増加に伴って運用負荷が増大し、継続的な運用が困難になります。
また、収集処理の実行環境についても、特定端末に依存した構成では運用が属人化しやすく、安定したデータ収集基盤としては適さない状況でした。そのため、クラウド上で完結し、既存のワークフロー(例:AWS Step Functions)に組み込める形で実装することが求められました。
さらに、収集した商品情報をそのまま利用するだけでなく、既存のマスタデータと突合し、サイトごとに同一商品の整理(名寄せ)を行う必要がありました。しかし、商品名や型番の表記ゆれ、情報粒度の違いなどにより、単純な一致条件では対応できず、曖昧一致を前提とした設計が必要となります。
このような前提のもと、Webクローリングと生成AIを組み合わせたデータ収集方式および、名寄せの実現方法について検証を行いました。
構成と選定理由
背景の内容を踏まえ、このような構成でAWS環境でのWebクローリングを実現しました。
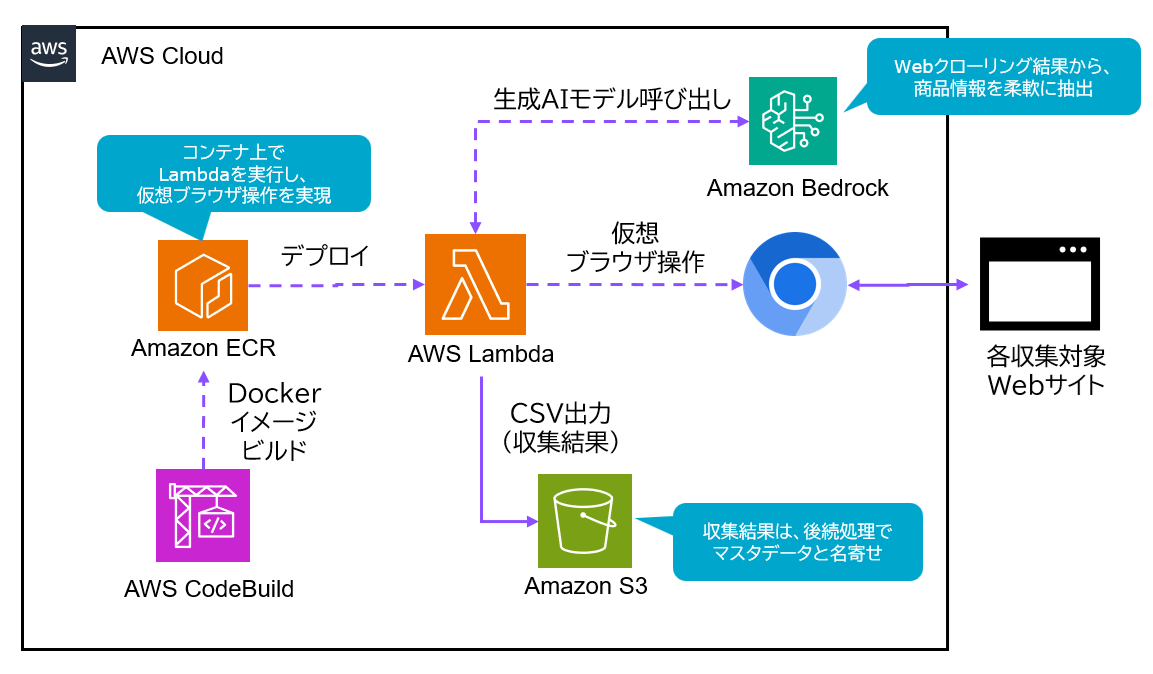
サイトごとに構造が異なるWebページから商品情報を収集するため、仮想ブラウザによるクローリング方式を採用しました。これにより、単純なHTTP取得では対応できない動的コンテンツやJavaScriptレンダリングにも対応可能としています。実行環境には、コンテナイメージを利用可能なAWS Lambdaを採用し、特定端末に依存しないクラウド上での実行基盤を構築しました。
次に、サイトごとのHTML構造の差異に対応するため、ルールベースではなく、Amazon Bedrockを用いた生成AIによる情報抽出を採用しました。これにより、ページ構造や表現の違いを吸収しながら、商品名や型番といった必要な情報を柔軟に取得できる構成としています。
また、収集処理をクラウド環境にて実行する運用を見据え、AWS CodeBuildを用いてDockerイメージをビルドし、Amazon ECRへ登録(プッシュ)してLambdaへデプロイを行う構成としました。これにより、環境差異のない再現性の高い運用を実現しています。
さらに、収集したデータはCSV形式でAmazon S3に出力し、後続の名寄せ処理やデータ活用基盤での利用を前提とした中間データとして蓄積します。本検証では名寄せ処理そのものは後段としつつ、曖昧一致を前提としたデータ構造で保持することを重視しました。
このように、「構造差異への対応」「運用の非属人化」という課題に対して、それぞれ適したサービスを組み合わせることで、柔軟かつ実運用を見据えたWebクローリングの基盤を構成しました。
気にしたポイント
実際に実装したWebクローリングの、処理順序ごとに気にしたポイントを整理します。
①収集対象サイトの指定(パラメータ化)
Lambda実行時に、対象URLをパラメータとして受け取る構成としました。これにより、単一の関数を使い回し、ジョブネットやワークフローから複数サイトの収集処理を横展開できるようにしています。
{
"url": "https://example.com",
"prompt": "商品名と価格を抽出してください。\n列は name, price。\nCSV形式で出力してください。"
}
また、urlと同様に、後述する生成AIでの解析処理時のpromptについてもパラメータ化しています。これにより、プロンプトの調整のみで対応可能なケースであれば、改修不要で対応可能な設計としています。
②WebサイトからHTMLの取得
HTML取得にはPlaywrightを採用しました。
Playwrightは、Microsoftが開発したオープンソースのブラウザ自動操作ライブラリです。Chromium・Firefox・WebKitといった複数ブラウザをプログラムから制御できます。
単純なHTTPリクエストではなく、実際のブラウザを起動してページを描画するため、JavaScriptによる動的コンテンツにも対応可能です。
ブラウザ設定は、動作確認をしながら、以下のような設定に調整しています。
# playwright ブラウザ設定
browser = p.chromium.launch(
headless=False,
args=[
"--no-sandbox",
"--disable-setuid-sandbox",
"--disable-dev-shm-usage",
"--disable-gpu",
"--single-process",
"--ignore-certificate-errors"
],
env={"DISPLAY": os.environ["DISPLAY"]}
)
context = browser.new_context(
ignore_https_errors=True,
locale="ja-JP",
timezone_id="Asia/Tokyo",
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
viewport={"width": 1920, "height": 1080}
)
context.set_default_navigation_timeout(90_000)
context.set_default_timeout(30_000)
page = context.new_page()
page.set_extra_http_headers({"Accept-Language": "ja,en-US;q=0.9,en;q=0.8"})
- LambdaはGUIを持たないため、ブラウザ描画のためにXvfbによる仮想ディスプレイを用意しています。本実装では、ヘッドレスブラウザではなく、仮想ディスプレイ上でブラウザを起動(疑似ヘッドフル)する構成としています。これにより、サイト側の描画差異や要素の非表示問題を回避し、安定したHTML取得を実現しています。
- 動作を安定させるために、不要なリソース消費をおさえるための無効設定を入れています。
- サイト側に、人間が操作している通常のブラウザだと思わせるためのコンテキスト設定をしています。
- レスポンシブサイトでは解像度によりメニューや要素が折りたたまれるため、画面解像度を1920×1080に固定しています。
- Accept-Languageの指定で日本語表示を優先し、取得データの言語揺れを防止しています。
- タイムアウト設定を明示的に指定し、操作のハング防止や、海外サイトアクセス時のネットワーク遅延を許容しています。
③取得したHTMLの解析
取得したHTMLは、従来のようなルールベースで解析するのではなく、Amazon Bedrockを用いて解析させています。
本実装では、モデルにAnthropic Claude 3.5 Sonnetを採用しました(2025年検証当時の最新バージョン)。検証の結果、HTMLが適切に取得できている前提であれば、生成AIの知能由来による商品情報の抽出漏れはほとんど発生せず、実用レベルの精度で抽出可能であることを確認しました。※実際の精度は、対象サイトの構造や収集対象に依存するかと思います。
- temperature=0.0とすることで、出力の揺らぎを抑え、同一入力に対して安定した結果を得られるようにしています。
- HTML本文はそのまま投入するとトークン上限に達する可能性があるため、文字数を制限しています。これにより、不要なコスト増加や処理遅延を防止しています。
- Bedrockの推論プロファイルを利用することで、モデル呼び出し時のリソース管理を柔軟に制御できる構成としています。
プロンプトは「ユーザープロンプト」と「システムプロンプト」に分けて設計しています。
ユーザープロンプトは、Lambdaのパラメータとして外部から指定可能とし、対象サイトや抽出内容に応じて柔軟に変更できる構成としています。一方で、システムプロンプトでは出力形式を厳密に制御し、後続処理で扱いやすいデータ形式を担保しています。
# システムプロンプト
sys = SystemMessage(
content=(
"あなたはWebページ本文から情報を抽出するツールです。"
"出力は必ずCSVのみ(ヘッダなし、カンマ区切り、LF改行)。"
"説明文や前置きは禁止。価格が無い場合は「記載なし」と明記してください。"
)
)
このように制約を明示することで、生成AIの自由度を抑えつつ、構造化データとして利用可能な形式で出力させています。
改善ポイント
ブラウザ操作が必要なサイトへの対応
本実装では、Playwrightによるブラウザ操作と生成AIによる情報抽出を組み合わせることで、一定の汎用性を持ったWebクローリングを実現しています。
しかし一部のサイトでは、単純なページ遷移やテキストベースのクリックでは対応できず、明示的なブラウザ操作が前提となるケースが存在します。
具体的には以下のようなケースです。
- 初回アクセス時にポップアップ広告や同意画面が表示され、操作しないとページが閲覧できない
- JavaScriptによる動的表示の後、ボタン操作によるメニュー切り替えが必要
- タブ切り替えやアコーディオン展開など、ユーザー操作を前提としたUI構造
これらのケースでは、仮想ブラウザ起動後にサイト特性に応じた操作が必要となります。Playwrightを用いて個別に実装することは可能ですが、サイトごとに処理を作り込む必要があり、これまでの「汎用的なクローリング」という思想とトレードオフになります。
この課題に対するアプローチとして、browser-use のようなライブラリを利用することで、ブラウザ操作自体を自然言語で制御する仕組みの導入が考えられます。
browser-useは、生成AIがブラウザを直接操作するためのオープンソースライブラリです。自然言語による指示を解釈して、クリックなどのアクションを自律的に実行してくれます。
これを導入することで、ポップアップの回避や複雑なメニュー遷移といった動的なUI操作をAIがその場で判断して完結できるようになり、サイトごとに個別コードを追加する手間を解消してくれる可能性があります。
収集した商品情報とマスタ情報の名寄せ
本記事でここまで触れていませんでしたが、収集した商品情報は、既存のマスタデータと紐付ける名寄せ処理を行うことで、実際の業務活用につなげることを想定しています。
しかし、複数のWebサイトから収集した商品情報は、サイトごとに表記ゆれ(例:「iPhone 15」と「アイフォン15」)や型番の記述粒度が異なるため、単純なID一致では突合できないケースが多く存在します。
この、曖昧な条件での名寄せを実現するためには、様々なアプローチが考えられます。
- Pythonによるカスタムロジックの実装:Levenshtein距離などを用いた文字列類似度の算出
- Pythonによるカスタムロジックの実装:ベクトル化による文脈ベースの類似度検索(Embedding)
- AWSマネージドサービスの活用:AWS Entity Resolutionを利用したルールベース/MLベースのマッチング
AWS Entity Resolution は、AWS上のデータに対して、ルールベースおよび機械学習ベースのマッチングをスケーラブルに提供するサービスです。
本検証では、業務ロジックに応じた柔軟なカスタマイズ性を重視し、Pythonベースでの名寄せロジックの検証を実施しています。
一方で、Entity Resolutionについても2025年初旬に検証を行っていました。当時は機能面で発展途上と判断し採用を見送りましたが、現在は高度なルールベースのファジーマッチング機能が強化されており、改めて適用可能性を検討したい領域です。
まとめ
本記事では、Webクローリングと生成AIを組み合わせたデータ収集基盤について、設計から実装、改善検討までの試行錯誤を整理しました。従来の構造依存のクローリングから、生成AIによる柔軟な情報抽出へ転換することで、サイト構造差異に対する耐性を向上させることができました。一方で、ブラウザ操作の高度化や名寄せの精度向上といった課題も残っており、今後はAIによる操作制御やマネージドサービスの活用も含め、さらなる実用化に向けた検証を進めていきたいと考えています!
(宣伝) クラウドデータ活用サービス
今回ご紹介した内容は、SCSKで提供しているクラウドデータ活用サービスの中で扱っているテーマの一部になります。
お客様のデータ活用状況に応じて、基盤構築から可視化、データ連携、データマネジメント、高度データ活用までを段階的にご支援しています!
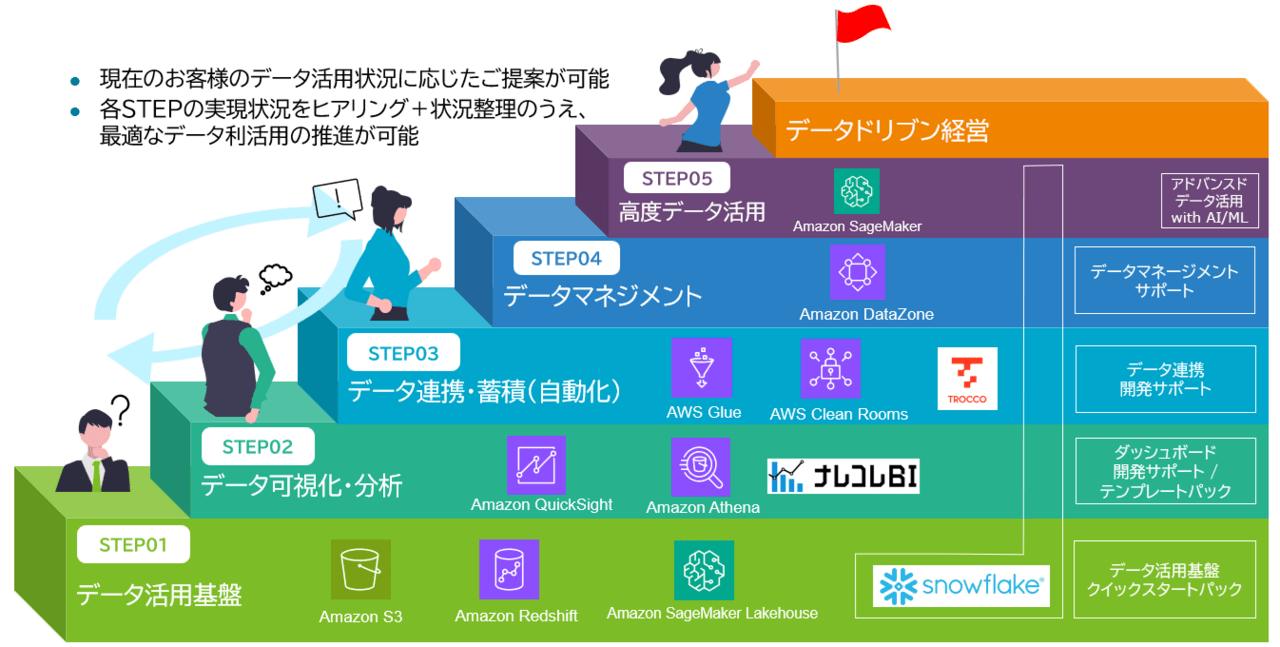
ご関心あれば、以下のサービスページもご参照ください。
