

こんにちは。SCSKの島村です。
前回の Govern 編では、AIエージェントに「ガードレール」と「ハーネス」を付けてセキュリティ・統制を確保する方法を整理しました。
https://blog.usize-tech.com/gemini-enterprise-2-governance/
今回は Optimize(最適化)レイヤー としてエージェントの品質を継続的に磨き続ける仕組みを、2026年に急速に広まった Agent Harness/Harness Engineering の概念と対比しながら私なりに整理をしてみました。
エージェントは安全に動くだけでは十分ではありません。高い品質を維持し、継続的に改善されていく仕組みが必要です。作って終わりではなく、本番環境で動きながら磨かれ続けるエージェント — それを実現するのが 今回ご紹介するAgent PlatformにおけるOptimize レイヤーです。
本記事では、『AIエージェントを「磨き続ける」仕組み — Agent ハーネス Engineering の視点から』について調査・整理した内容をご紹介します。
1.1 「ハーネス」の3つの系譜
「ハーネス」という言葉は元来「馬具」を意味し、各工学分野で独立に使われてきました。
| 系譜 | 時代 | 定義 | 特徴 |
|---|---|---|---|
| テストハーネス(SE) | 1980年代〜 | テスト対象を制御環境に接続し、入出力を捕捉する枠組み | テスト時のみ動作。終われば除去 |
| セーフティハーネス(安全工学) | 工業の歴史 | 対象の動きを拘束・追跡し、危険な逸脱を防ぐ仕組み | 常時動作。安全を確保 |
| Agent ハーネス(AI / 2026年〜) | 2025〜2026年 | モデル以外のすべて — ツール、メモリ、ガードレール、検証、オーケストレーション | 常時動作。品質+安全+実行のすべてを包含 |
前回の Govern 編で使った「ハーネス」は②のセーフティハーネスに近い意味でしたが、2026年の業界では③のより広い意味で使われています。
1.2 Agent ハーネスの定義 — 各論者の整理
2026年2月に Mitchell Hashimoto(HashiCorp共同創業者)が提唱し、一気に広まった概念です。
Mitchell Hashimoto の定義
「エージェントがミスをするたびに、そのミスが二度と起こらないように環境に修正を組み込む実践」
LangChain の定式化
Agent = Model + Harness
ハーネスとは、コード・設定・実行ロジックの総体。モデルに状態、ツール実行、フィードバックループ、強制制約を与えることで、初めてモデルがエージェントになる。
Martin Fowler / Böckeler(Thoughtworks)の定式化
Harness = Guides(フィードフォワード制御)+ Sensors(フィードバック制御)
- Guides = エージェントが行動する前に方向を制御する仕組み
- Sensors = エージェントが行動した後に観測し、自己修正を促す仕組み
1.3 なぜ定義がバラバラなのか
根本的な理由は、Agent ハーネスの定義が「モデル以外の全部」と極めて広いことです。ガードレールもテストも観測もオーケストレーションも、すべてハーネスの一部です。
つまり業界用語の「Agent ハーネス」は、前回のGovern編で対比した「ガードレール vs ハーネス」の両方を含む上位概念です。
1.4 テストハーネスから Agent ハーネスへの進化
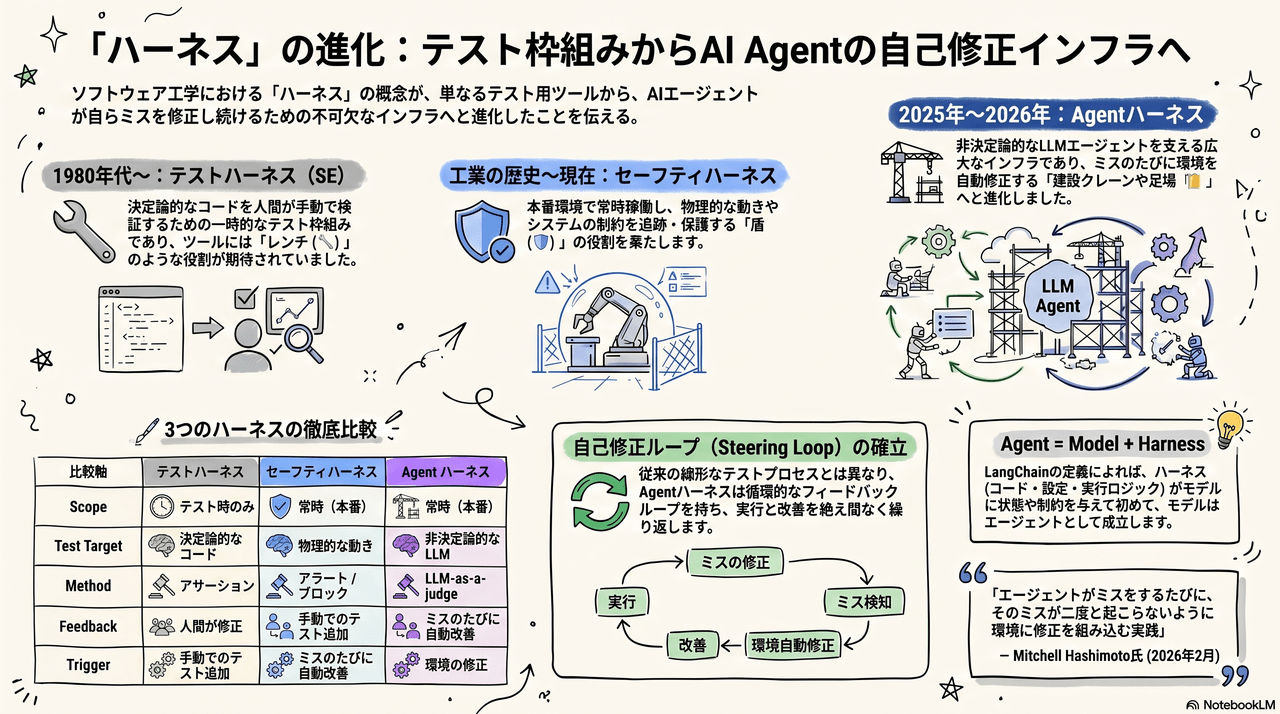
| 観点 | テストハーネス(従来のSE) | Agent ハーネス(2026年) |
|---|---|---|
| テスト対象 | 決定論的なコード | 非決定論的なLLMエージェント |
| 環境 | テスト時のみ構築 → 除去 | 本番に常駐 |
| 入力制御 | テストケースの手動定義 | 合成ユーザー(LLMが動的生成) |
| 判定方法 | アサーション(等値比較) | LLM-as-a-judge(意味的判定) |
| フィードバック先 | 人間が修正 | 環境が自動修正 + 人間 |
| 進化のトリガー | テスト追加(手動) | ミスのたびに環境が自動改善 |
決定的な違い:Steering Loop(自己修正ループ)の存在
- テストハーネス:テスト失敗 → 人間が修正 → 再テスト → Pass/Fail
- Agent ハーネス:品質低下検知 → Sensor が検出 → 環境が自動改善を提案 → 再評価 → 採用
2. Agent Platform の Optimize = Google が提供する「品質ハーネス」
2.1 Agent Platform 全体を Agent ハーネスとして見る
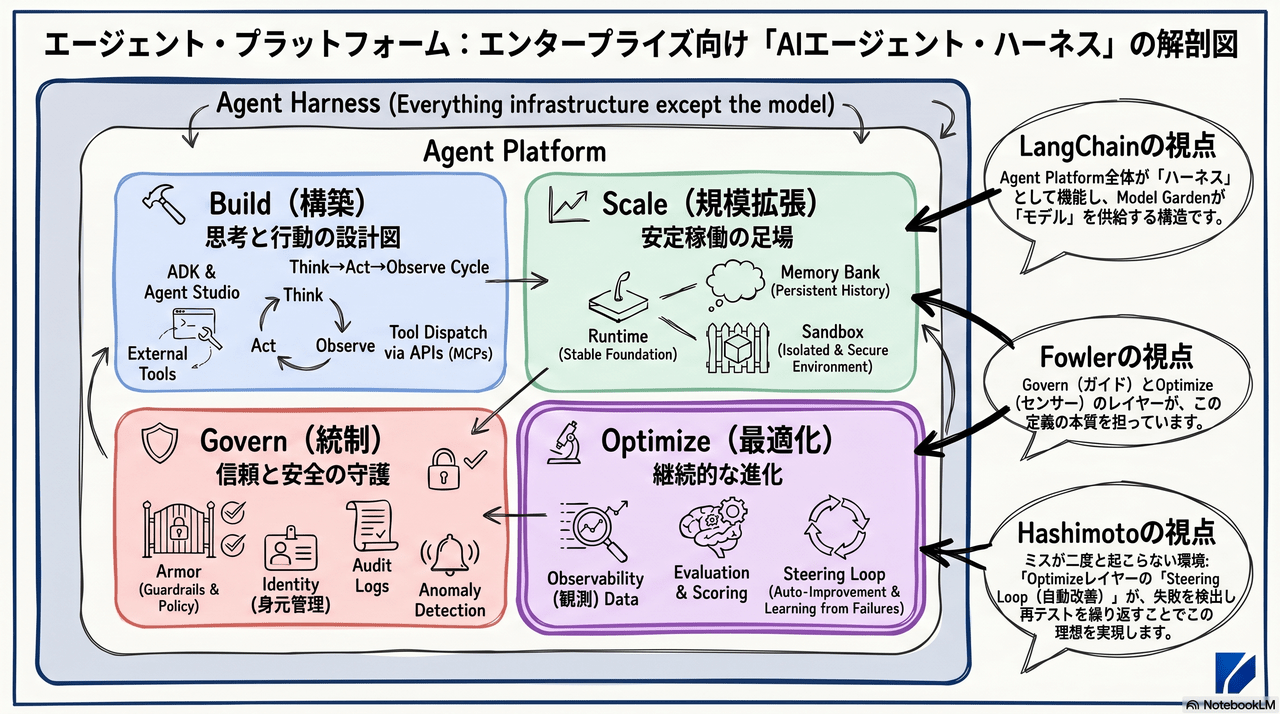
Agent Platform の4レイヤーは、業界が言う「Agent ハーネス」をエンタープライズ向けに機能分解して提供したものです。
| レイヤー | Agent ハーネスにおける役割 |
|---|---|
| Build | ハーネスの「構築手段」— ADK, Agent Studio でオーケストレーションを組む |
| Scale | ハーネスの「実行基盤」— Runtime, Sandbox, Memory で安定稼働を支える |
| Govern | ハーネスの「セキュリティ層」— ガードレール + セキュリティ Sensor |
| Optimize | ハーネスの「品質層」— 品質 Sensor + Steering Loop の自動化 |
2.2 Optimize の4サービス — Guides / Sensors モデルで整理
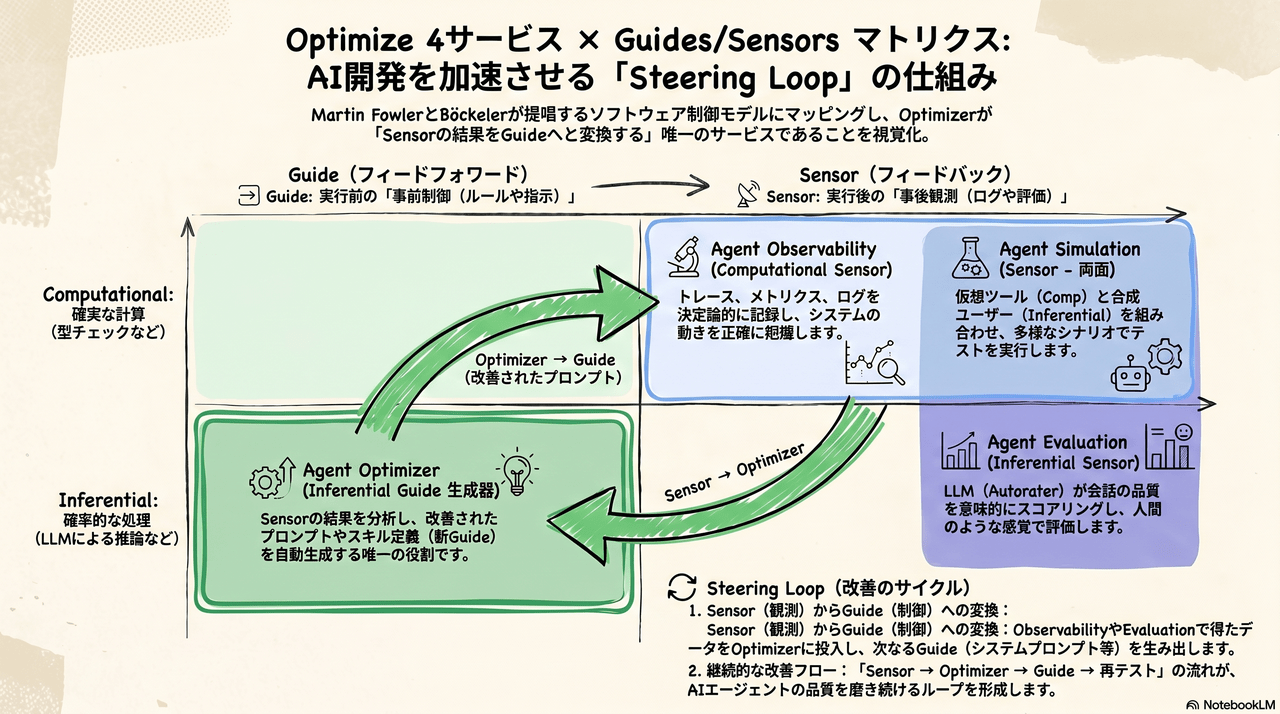
Martin Fowler / Böckeler は Agent ハーネスの構成要素を 2軸×2軸の4象限 で整理しました。Optimize の4サービスをこのモデルにマッピングします。
| サービス | Guide / Sensor | Comp / Inferential | 説明 |
|---|---|---|---|
| Agent Observability | Sensor | Computational | トレース・メトリクスを決定論的に記録 |
| Agent Evaluation | Sensor | Inferential | Autorater(LLM-as-a-judge)が会話品質を意味的判定 |
| Agent Simulation | Sensor | 両方 | 仮想ツール=Comp、合成ユーザー&スコアリング=Inferential |
| Agent Optimizer | Guide 生成器 | Inferential | Sensor 結果から改善プロンプト(= 新 Guide)を自動生成 |
Optimizer の特殊な位置づけ
Evaluation / Simulation / Observability は Sensor(品質を観測する)ですが、Optimizer は「Sensor の結果を次の Guide に変換するメタ機能」です。
この変換エンジンこそが Steering Loop を自動化する中核サービスです。
この変換エンジンこそが Steering Loop を自動化する中核サービスです。
3. Optimize の4サービス — 詳細解説
3.1 Agent Evaluation — 本番品質の継続 Sensor
Agent Evaluation は、本番環境で稼働中のエージェントに対して継続的に品質を計測するサービスです。
従来のモデル評価が「1つのプロンプトに対する1つの応答」を評価していたのに対し、マルチターンの会話全体を評価対象とします。
従来のモデル評価が「1つのプロンプトに対する1つの応答」を評価していたのに対し、マルチターンの会話全体を評価対象とします。
| 特徴 | 説明 |
|---|---|
| マルチターン評価 | 会話全体の流れ・ロジック・一貫性をスコアリング |
| Autorater(自動評価者) | LLMを評価者として使い、人間の判断基準に近い品質スコアを自動算出 |
| 本番トラフィック対応 | デプロイ後の実トラフィックに対して継続的に評価を実行 |
| カスタム評価基準 | ユースケースに応じた独自の評価メトリクスを定義可能 |
| ターンキーダッシュボード | 評価結果を可視化するダッシュボードが即利用可能 |
GenAI Client SDK(Python)からプログラマティックに実行でき、CI/CD パイプラインに組み込むことも可能です。
3.2 Agent Simulation — デプロイ前の品質ゲート
Agent Simulation は、エージェントを本番にデプロイする前に品質を検証するテスト環境です。
従来のテストハーネスの3要件(隔離・制御・観測)を満たしつつ、Agent 固有の要素を追加しています。
従来のテストハーネスの3要件(隔離・制御・観測)を満たしつつ、Agent 固有の要素を追加しています。
| テストハーネスの要件 | 従来の実現方法 | Agent Simulation での実現 |
|---|---|---|
| 入力の制御 | テストケースの手動定義 | 合成ユーザー(LLMがペルソナ・目標に基づき動的に入力生成) |
| 環境の隔離 | モック / スタブ | 仮想ツール環境(DB・API を仮想化、副作用なし) |
| 出力の捕捉 | アサーション | 自動スコアリング(タスク成功率・安全性・効率性) |
| (Agent固有)マルチステップ | — | 複数ターンの対話シナリオ全体を実行・評価 |
| (Agent固有)大規模テスト | — | 数千件の会話を自動生成し統計的に評価 |
3.3 Agent Observability — 推論過程の可視化
Agent Observability は、エージェントの内部動作をリアルタイムに可視化するサービスです。
「なぜそのような応答をしたのか」をデバッグするための完全な実行トレースを提供します。
「なぜそのような応答をしたのか」をデバッグするための完全な実行トレースを提供します。
| 特徴 | 説明 |
|---|---|
| 実行トレース(Traces) | リクエストからレスポンスまでの全ステップを時系列で記録 |
| メトリクス監視 | レイテンシ、トークン消費量、ツール呼び出し回数等 |
| マルチエージェント対応 | 複数エージェントの連携フロー全体を追跡 |
| MCP サーバー監視 | Model Context Protocol サーバーの状態もモニタリング |
| OpenTelemetry 対応 | 標準のオブザーバビリティプロトコルに準拠。ADK には計装が組み込み済み |
Google Cloud の Cloud Trace / Cloud Monitoring / Cloud Logging と統合されており、ADK の OpenTelemetry 計装を有効化するだけでテレメトリが自動送信されます。
3.4 Agent Optimizer — Sensor → Guide 変換エンジン
Agent Optimizer は、本番環境での失敗パターンを自動的にクラスタリングし、システムプロンプトの改善案を提案するサービスです。
Mitchell Hashimoto が言う「ミスが二度と起こらない環境を自動的に作る」を具現化しています。
Mitchell Hashimoto が言う「ミスが二度と起こらない環境を自動的に作る」を具現化しています。
| モード | 入力 | プロセス | 出力 |
|---|---|---|---|
| Zero-shot | 現在のプロンプトのみ | 曖昧さ・不足・冗長を自動検出 | 改善されたプロンプト |
| Data-driven | プロンプト + ラベル付きサンプル + 評価メトリクス | 反復的に実行→評価→改善 | 最適化されたプロンプト |
4. Steering Loop — Agent Platform が実現する自動改善サイクル
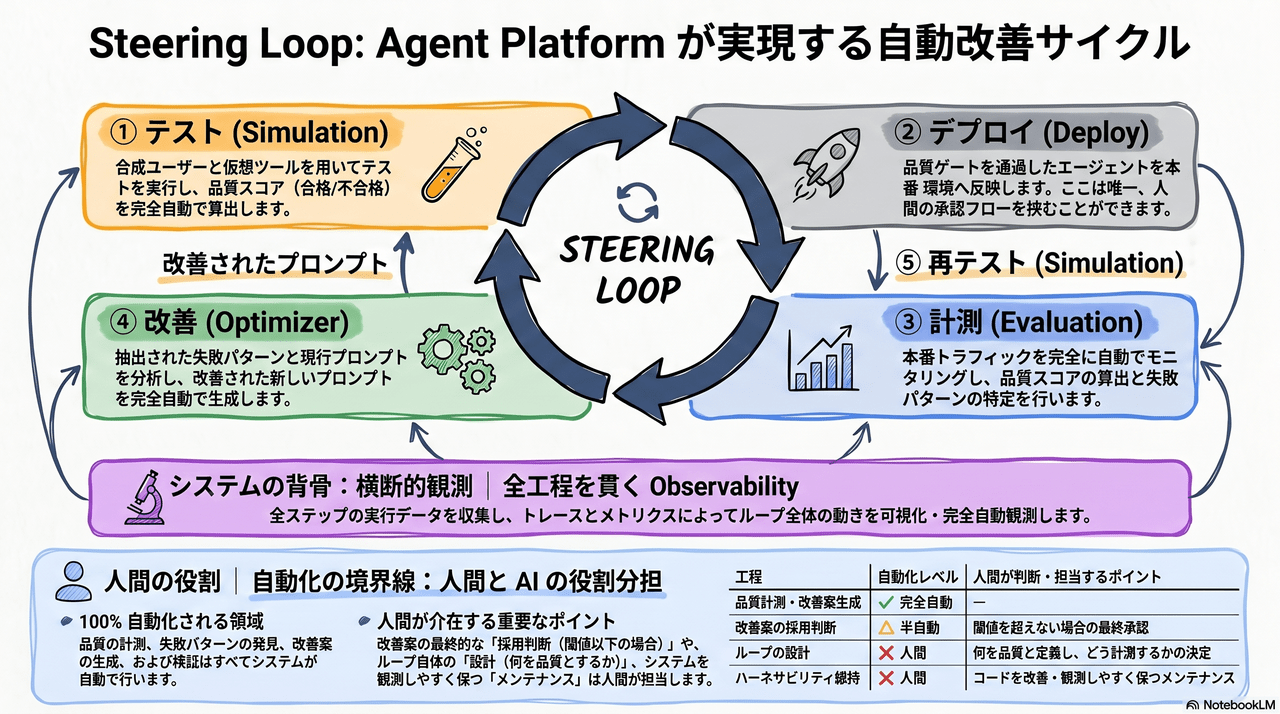
4つのサービスは独立ではなく、以下のフィードバックループとして連携します。
| Step | サービス | やること | 自動化レベル |
|---|---|---|---|
| ① | Simulation | デプロイ前に合成ユーザーで品質を検証 | ✓ 完全自動 |
| ② | Evaluation | 本番トラフィックで継続的にスコアリング | ✓ 完全自動 |
| ③ | Optimizer | 失敗パターンからプロンプト改善案を生成 | ✓ 完全自動 |
| ④ | Simulation | 改善版を再度テスト → 品質ゲート通過で Deploy | ✓ 完全自動 |
| 横断 | Observability | 全フェーズの実行をトレース・可視化 | ✓ 完全自動 |
人間が担う部分
- Steering Loop の設計 — 何を品質と定義し、どう計測するか
- 品質ゲートの閾値設定 — 合格ラインの決定
- 改善案の最終承認 — Optimizer の提案を採用するか否か
- ハーネサビリティの維持 — コードベースを観測・改善しやすく保つ設計判断
5. Govern × Optimize — 統一フレームワーク
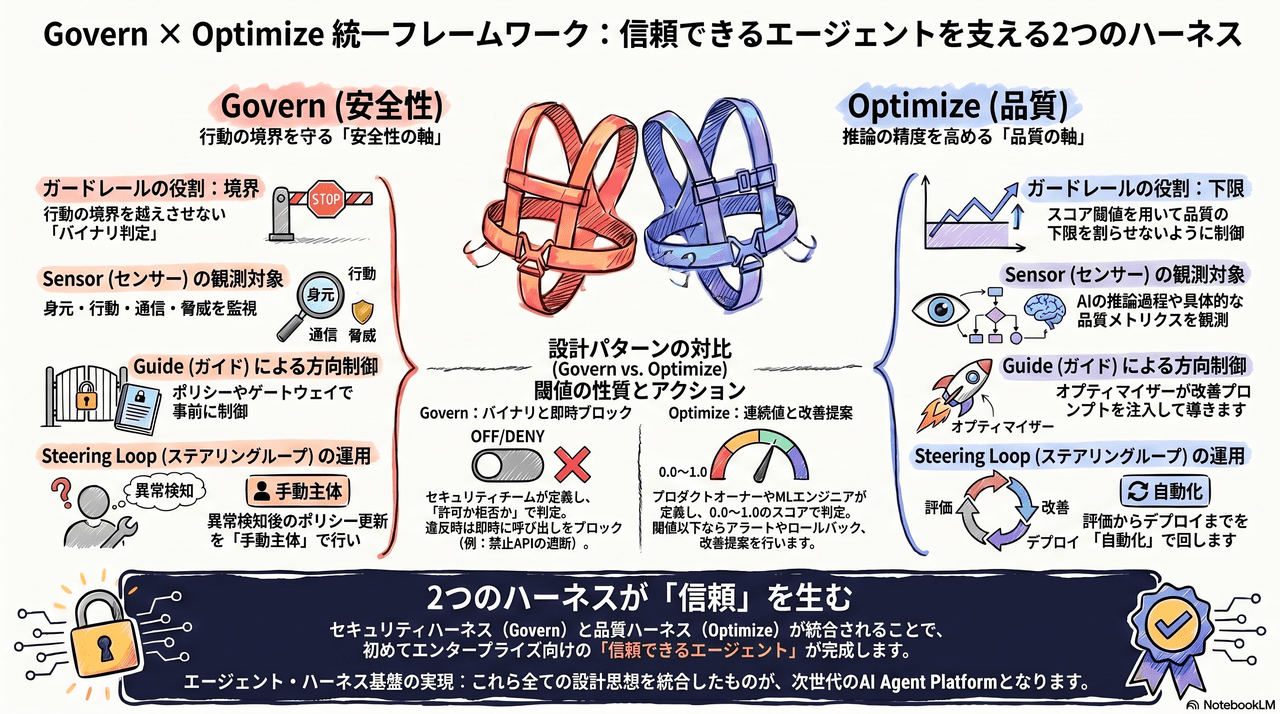
Govern と Optimize は同じ設計思想(ガードレール + Sensor + Guide + Steering Loop)で構築されています。違いは「何を守るか」の軸だけです。
| 設計パターン | Govern(安全性の軸) | Optimize(品質の軸) |
|---|---|---|
| ガードレール | 行動の境界を越えさせない(Model Armor / Policy / Gateway) | 品質の下限を割らせない(Simulation / Evaluation の閾値) |
| Sensor | 身元・行動・通信・脅威を観測(Identity / Anomaly / Security) | 推論過程・品質メトリクスを観測(Observability / Evaluation) |
| Guide | Policy / Gateway で事前に方向制御 | Optimizer が改善プロンプトを注入 |
| Steering Loop | Anomaly → Security → Policy更新(手動主体) | Eval → Optimizer → Simulation → Deploy(自動化) |
Govern がエージェントの「安全性」を守り、Optimize がエージェントの「品質」を高める。
両方揃って初めて企業がエージェントの自律性を安心して解放できます。
両方揃って初めて企業がエージェントの自律性を安心して解放できます。
6. 段階的導入ガイド — どこから始めるか
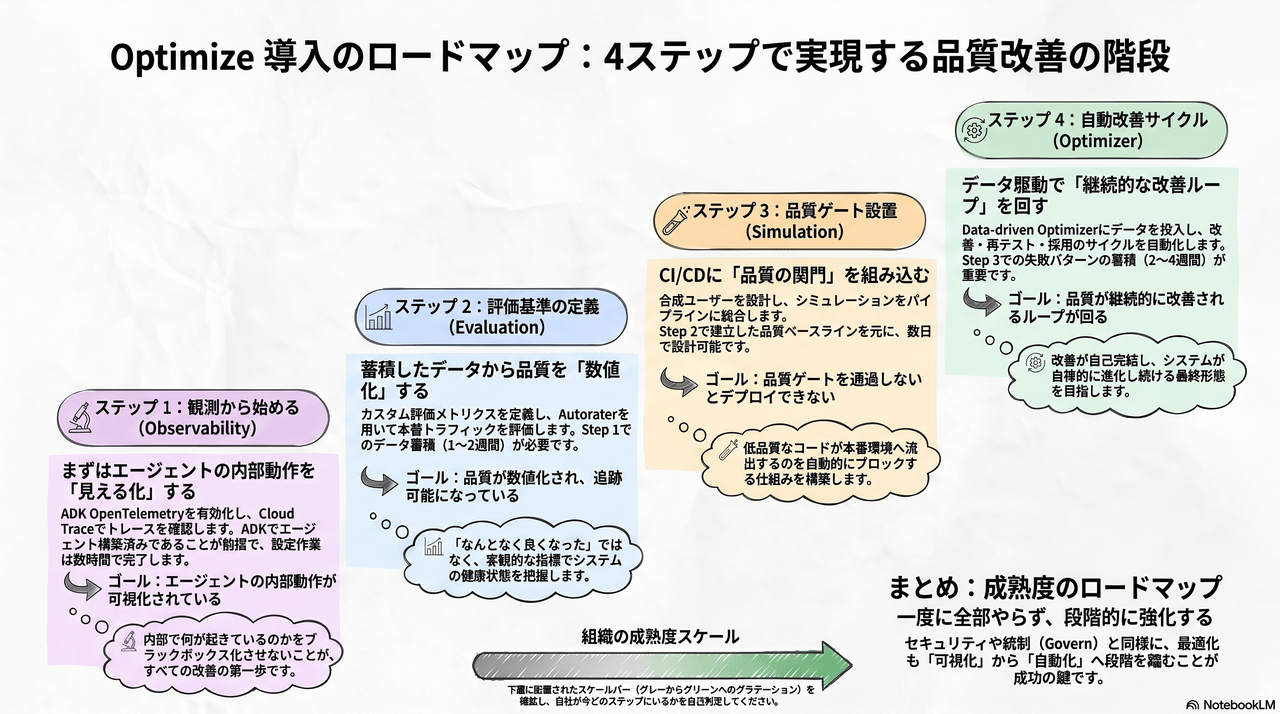
すべてを一度に導入する必要はありません。組織の成熟度に応じて段階的に構築していくのが現実的です。
| Step | テーマ | サービス | ゴール | 所要時間目安 |
|---|---|---|---|---|
| 1 | 🔬 観測から始める | Observability | 内部動作が可視化されている | 数時間(設定のみ) |
| 2 | 📊 評価基準の定義 | Evaluation | 品質が数値化され追跡可能 | 1〜2週間 |
| 3 | 🧪 品質ゲート設置 | Simulation | 品質ゲート未通過ならデプロイ不可 | 数日 |
| 4 | ⚙️🔄 自動改善サイクル | Optimizer | 品質が継続的に改善されるループが回る | 2〜4週間 |
7. まとめ
Agent ハーネス Engineering の3つのキーメッセージ
1. Agent ハーネス = モデル以外のすべて
ガードレールもテストも観測も、すべてハーネスの一部。Agent Platform は、このハーネスをエンタープライズ向けに4レイヤー(Build / Scale / Govern / Optimize)に分解して提供しています。
2. Optimize は品質の Steering Loop を自動化する
Sensor(Evaluation / Observability)が品質を観測し、Optimizer が次の Guide(改善プロンプト)を生成し、Simulation で検証する。「ミスが二度と起こらない環境を自動的に作る」ことを目指すサービス群です。
3. Govern × Optimize で「信頼できるエージェント」が完成する
Govern が安全性の境界を守り、Optimize が品質の下限を守る。両方揃って初めて企業がエージェントの自律性を安心して解放できます。
対応表(全体サマリー)
| 概念 | Govern(安全性) | Optimize(品質) |
|---|---|---|
| ガードレール | Model Armor / Policy / Gateway | Simulation / Evaluation の閾値 |
| Sensor | Identity / Anomaly / Security | Observability / Evaluation |
| Guide | Policy / Gateway のルール定義 | Optimizer が生成する改善プロンプト |
| Steering Loop | Anomaly → Security → Policy更新 | Eval → Optimizer → Simulation → Deploy |
次回予告
次回は Build(構築)編 として、ADK によるエージェント構築を実際にハンズオンで検証できればと思います。Agent Platform の Optimize 4サービスが検証可能になった際には、追って実践編をお届けする予定です。
今後とも、AIMLに関する情報やGoogle CloudのAIMLサービスのアップデート情報を掲載していきたいと思います。
最後まで読んでいただき、ありがとうございました!!!
今後とも、AIMLに関する情報やGoogle CloudのAIMLサービスのアップデート情報を掲載していきたいと思います。
最後まで読んでいただき、ありがとうございました!!!