

はじめに
こんにちは!SCSK江嶋です。
本記事では、Azureのサービスを用いたRAGの構築方法について説明します。
- そもそもRAGとは?
- AzureでRAGを構築する際、どのサービスをどう使えばいい?
- Azure AI Search、Azure OpenAIって聞いたことあるけど何者?
上記のような疑問を持っている入門者向けに記事を書きます。少しでも参考になると幸いです!
RAG(Retrieval Augmented Generation)とは
RAGの概要
RAG(Retrieval Augmented Generation:検索拡張生成)は、LLM(大規模言語モデル)の回答生成に、社内文書やナレッジベースなど「外部データの検索結果」を組み合わせて回答精度を高めるアプローチです。
LLMは非常に強力ですが、基本的には「学習時点までの知識」と「入力されたプロンプト」に依存して回答します。そのため、次のような課題が起こりがちです。
- 社内規程や設計書など、モデルが学習していない最新情報には弱い
- もっともらしく見えるが誤っている回答(いわゆるハルシネーション)が混ざる
- 「その回答の根拠はどこ?」という出典提示が難しい
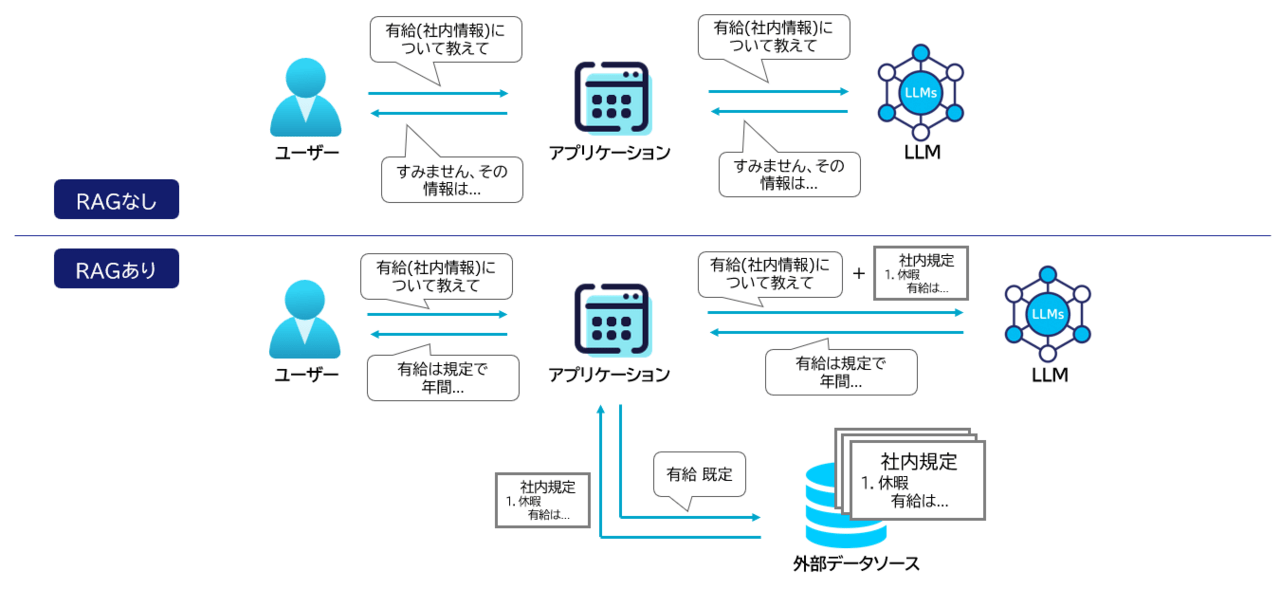
下図にRAGのありなしの比較図を掲載します。
RAGは、これらの弱点を補うために、質問に関連する文書を先に探し(Retrieval)、その内容を材料として回答を作る(Generation)という流れを取ります。図でいうと「RAGなし」ではユーザーの質問がそのままLLMに渡るのに対し、「RAGあり」では検索→関連情報の抽出→LLMという“参照プロセス”が挟まります。結果として、LLMは見つけた根拠をもとに答える形になります。
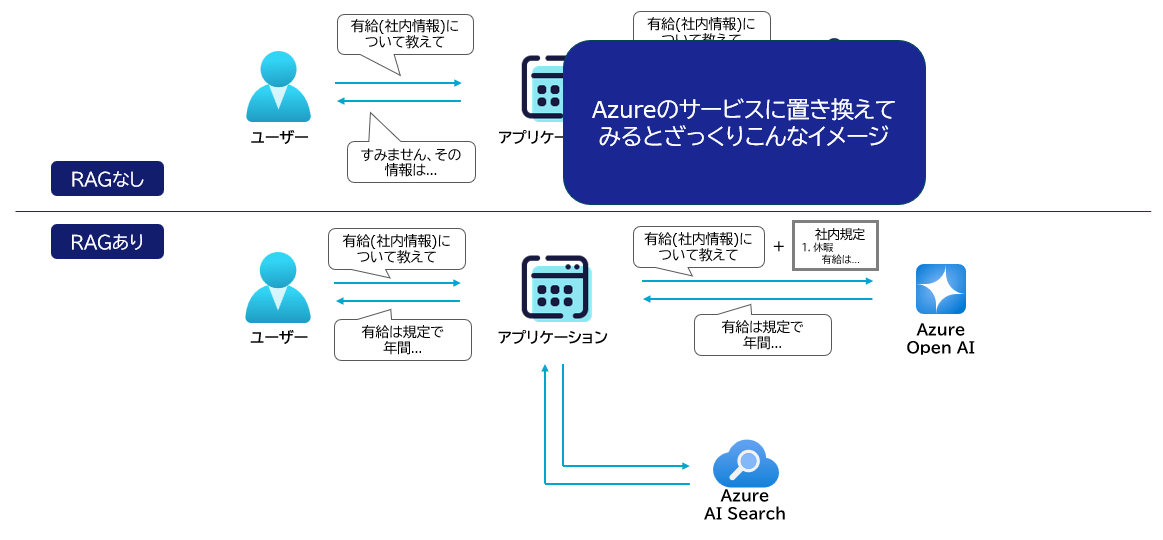
Azureでどう実現する?
本記事のテーマである Azure OpenAI × Azure AI Search は、RAG構成の王道パターンです。ざっくり役割分担は次の通りです。
- Azure AI Search:文書を索引化し、キーワード検索/ベクトル検索で関連情報を取得する
- Azure OpenAI(LLM):検索で得た根拠を使って自然な文章として回答を生成する
この構成にすることで、LLM単体では難しい「社内データに基づく回答」を実現しやすくなります。
(参考) 学習(ファインチューニング)ではなくRAGを使う理由
「社内情報を覚えさせたいなら学習すればいいのでは?」と思うかもしれません。
しかし、RAGがよく選ばれるのは次の理由からです。
- 情報更新に強い:文書を差し替えるだけで反映できる(再学習が不要)
- 根拠を提示しやすい:どの文書を参照したか追跡できる
- 運用と統制がしやすい:アクセス制御や監査ログなど、検索基盤側で管理しやすい
特に業務利用では「最新の規程に従う」「回答の根拠が説明できる」が重要になるため、RAGは現実的な選択肢になりやすいです。
Azure AI Searchとは
Azure AI Searchの概要
Azure AI Searchは、Azure上で提供されるフルマネージドの検索サービスです。
Azure AI Searchの役割を一言で言うと、「検索できる形に文書を整えて、必要なときに素早く取り出す仕組み」です。
- 文書を取り込み、検索用のデータ構造(インデックス)を作る
- 検索クエリに対して、関連度が高いデータを返す
- 検索結果にスコアリングやフィルタ、並び替えなどを適用する
RAGにおいては、ここで返ってきた検索結果(根拠)をプロンプトに含めて、Azure OpenAIが回答文を生成する流れになります。
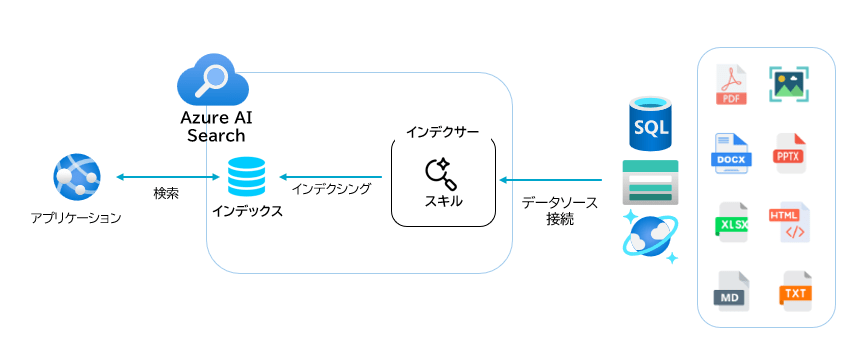
構成要素
図に描かれている要素を、RAGの準備〜検索までの流れに沿って整理します。
(1) インデックス(Index)
検索対象の本体です。
文書のテキストやメタデータをフィールドとして定義し、検索に使う属性(検索対象・フィルタ可能・返却対象など)を設計します。
インデックス設計例:
content(本文テキスト)title(タイトル)sourceUrl(参照元URL)category/updatedAt(絞り込み用メタデータ)contentVector(ベクトル検索用の埋め込み)
RAGでは、本文+メタデータ+ベクトルを持たせる設計が定番です。
(2) データソース(Data Source)
インデックスに取り込みたい元データの置き場所です。
Blob Storage、SQL、Cosmos DB など、様々なストレージ/DB、様々なファイル形式を検索対象として扱えるのがポイントです。
(3) インデクサー(Indexer)
データソースから文書を読み取り、インデックスに反映する取り込みジョブです。
定期実行により、更新や追加をインデックスへ追従させることもできます。
(4) スキルセット(Skillset)
取り込み時に、文書へ前処理(エンリッチメント)をかける仕組みです。
例として、PDFからのテキスト抽出、OCR、言語判定、キーフレーズ抽出などがあり、「検索しやすい形」に整えるときに使用します。
Azure OpenAIとは
Azure OpenAIの概要
Azure OpenAI は、OpenAIの大規模言語モデル(LLM)を Azure上のマネージドサービスとして利用できるサービスです。
チャット(対話)や文章要約、情報抽出、分類、コード生成などの生成AI機能を、Azureの認証・ネットワーク・監査といった企業利用向けの仕組みと合わせて扱えるのが特徴です。
RAGでは、Azure OpenAIは「検索で集めた根拠(コンテキスト)を使って、自然な回答文を作る役」を担当します。
前章の Azure AI Search が “探す” なら、Azure OpenAI は “答えを文章にする” 側です。
RAGでよく使う機能
チャット/テキスト生成
RAGの「最終回答」を生成する中心機能です。
検索で取った根拠を本文に含め、根拠に基づいて回答するように指示して出力させます。
よくあるプロンプト方針:
- 根拠(コンテキスト)に含まれる内容のみで答える
- 根拠が不足している場合は「分からない」や「追加情報が必要」と返す
- 参照元URLや文書タイトルを引用として添える(根拠提示)
Embeddings(埋め込み)
文章をベクトル化する機能です。
RAGでは、文書や質問文をEmbeddingしてベクトル検索を行うケースが多いため、検索の精度そのものに影響します。
- 文書側:チャンク化したテキストをEmbeddingしてインデックスへ格納
- 質問側:質問文をEmbeddingし、近い文書チャンクを検索
リソースを作成してみよう
使用するサービスについてなんとなく理解できましたか?ここから実際にリソースを作成してみましょう!
データソースの作成
検索対象ファイルの準備
今回検索対象とする社内文書として架空の契約書を準備しました。このドキュメントをデータソースとして登録し、AI Searchにインデックスとして登録する流れです。この架空の書類の情報は当然LLMは知らないので、動作確認でこの書類の情報を参照して回答してくれたら成功というわけです。

Azureのstorageに格納
上記で用意したファイルをAzureのストレージに配置します。今回はBlobに格納します。
ストレージアカウントを作成した後、コンテナを作成し、下図のように対象ファイルをコンテナにアップロードします。
Azure OpenAIでモデルをデプロイする
Azure OpenAIのリソースを作成し概要タブから「Foundryポータルの詳細」を押しFoundryポータルを開きます。
チャットタブからモデルを選択しデプロイする。
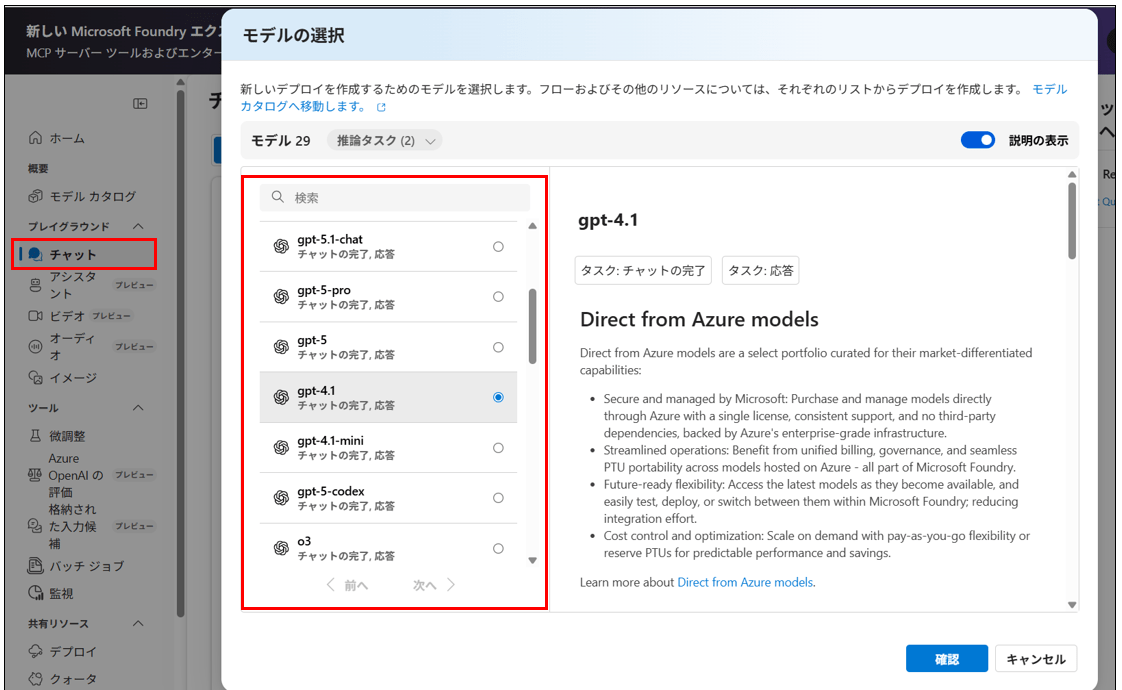
モデルカタログタブからembeddingモデルを選択しデプロイする。
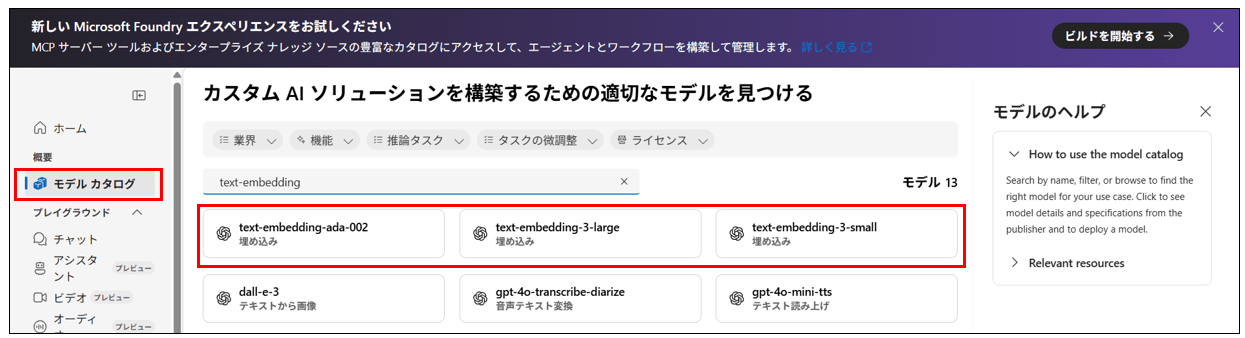
Azure AI Searchでインデックスを作成する
次にインデックスを作成します。Azure AI Searchのリソースを作成したあと、概要タブから「データのインポート(新規)」を押します。
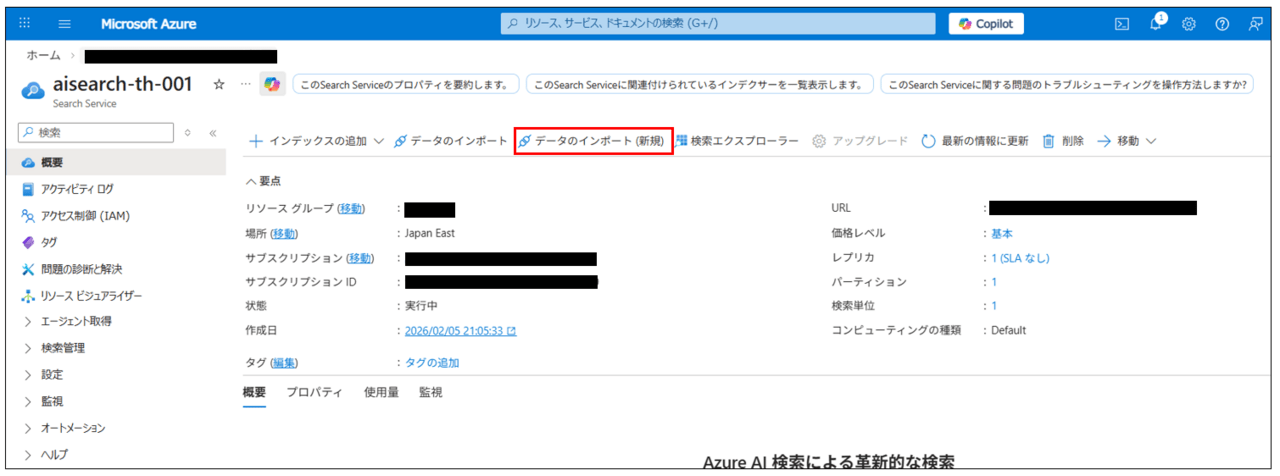
データソースを選択します。
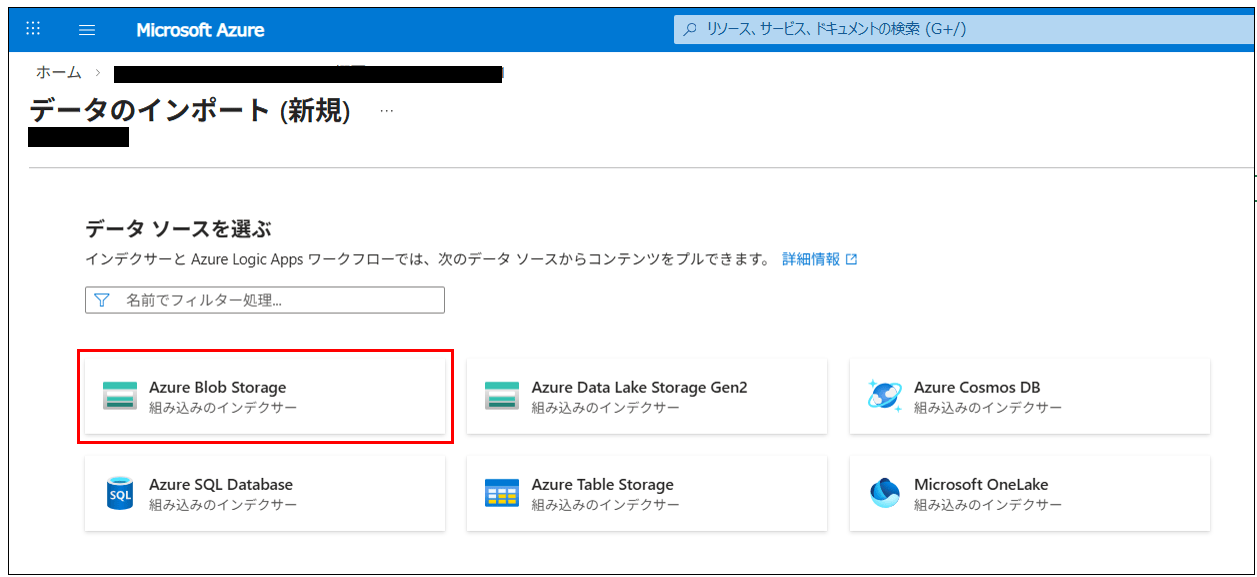
シナリオはRAGを選択します。
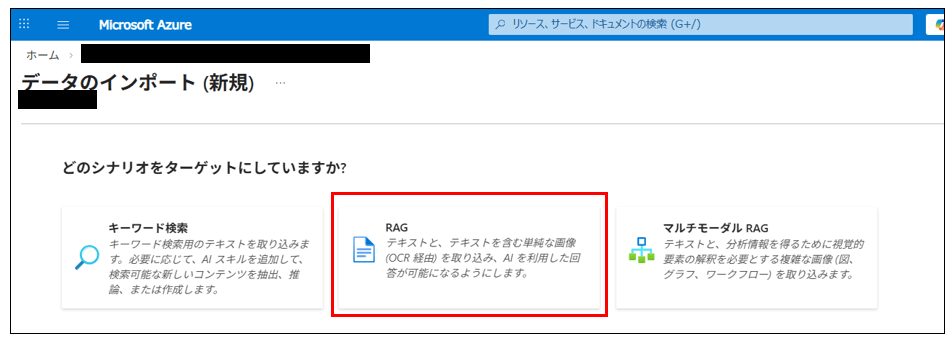
データへの接続画面では、作成したストレージアカウントと対象コンテナを選択する。
テキストをベクトル化する画面では、デプロイしたEmbeddingモデルを選択する。
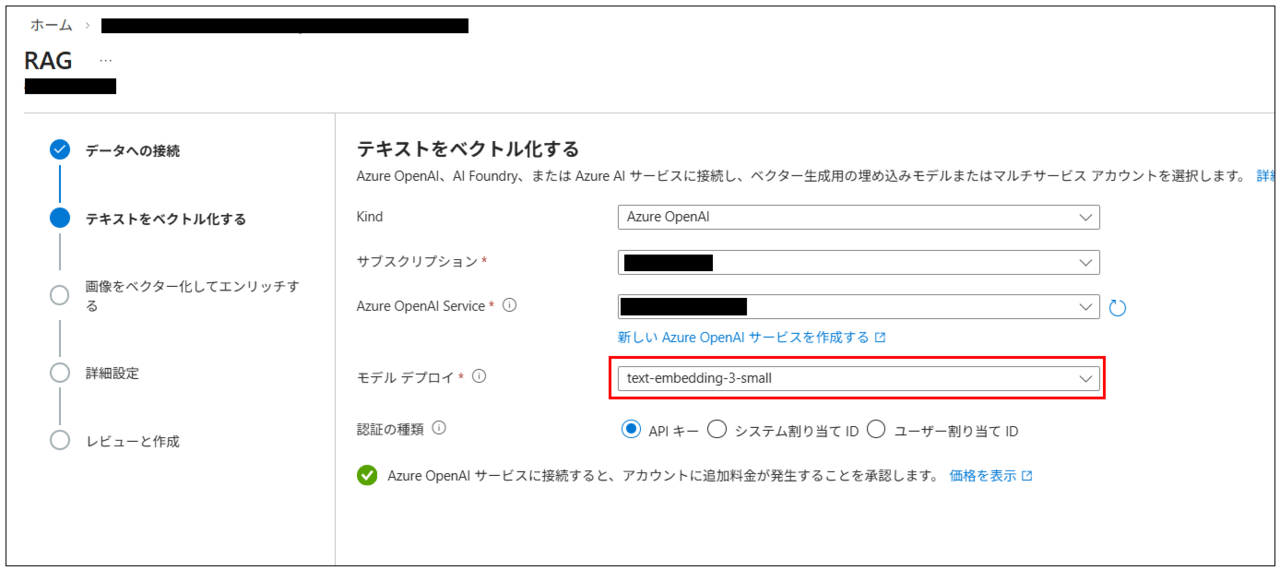
作成ボタンを押すとインデックス、インデクサー、スキルが自動生成されます。
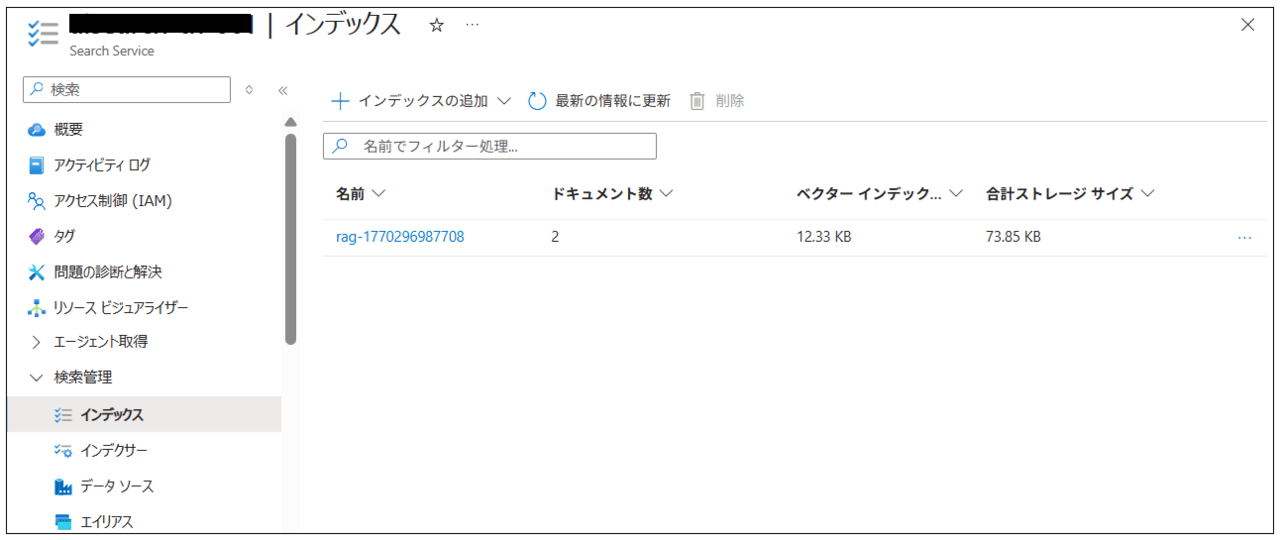
動作確認してみよう
ここまでで、インデックスの作成まで完了しました。ここからMicrosoft Foundryで動作確認をしてみましょう!
Foundryポータルを開き、デプロイしたチャットモデル画面に移動します。データソースの追加ボタンから
対象AI Searchのインデックスを選択すると、データソースとして紐づけができます。
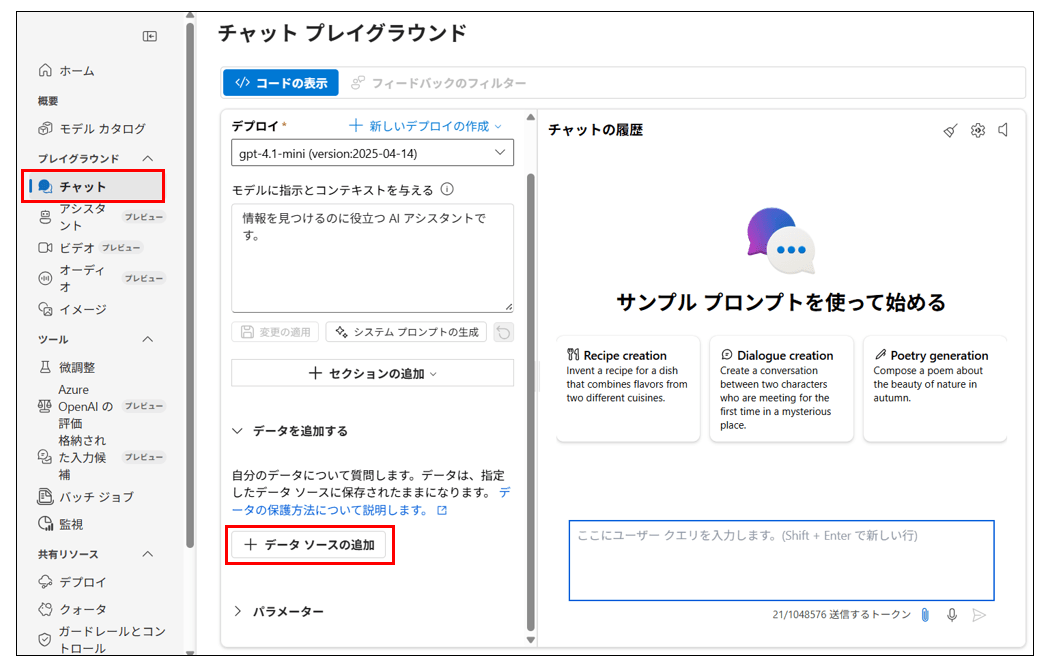
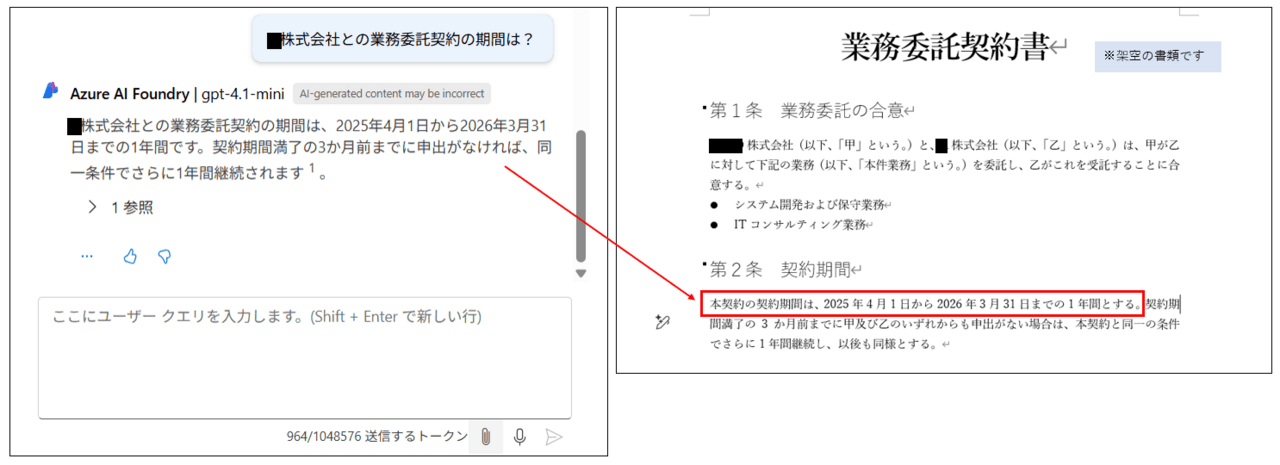
ここまできたら、いよいよチャット画面で動作確認です。
LLMが知りえないデータソースとして追加した社内文書の内容を聞いてみると、データソースを参照した結果を含んでLLMが
回答を返してくれました!!
さいごに
本記事では、Azure OpenAI と Azure AI Search を使ったRAGの基本構成を、全体像から実装の入口まで一通り紹介しました。
LLM単体では難しい「社内文書や最新情報に基づく回答」を、検索(Azure AI Search)で根拠を取得し、生成(Azure OpenAI)で文章化することで実現できるのがRAGの大きな強みです。
入門としては、まず 「検索で正しい根拠を取れること」 が最優先です。RAGの品質はLLMよりも、実は チャンク設計・メタデータ設計・検索方式(キーワード/ベクトル/ハイブリッド) の影響を強く受けます。うまく回答できない場合は、モデルやプロンプトをいじる前に、AI Search側のインデックスと検索結果を先に疑うのが近道です。
なお、今回は入門として “検索→根拠→生成” の最小構成に絞って説明しましたが、実運用では要件に応じてさらに色々な拡張アプローチがあります。たとえば、検索前処理を高度化する カスタムスキル、LLMの外部処理を組み込む Function Calling、PDFや帳票から構造化情報を抽出する Azure AI Document Intelligence などを組み合わせることで、取り込み精度・検索精度・回答品質を段階的に引き上げられます。必要になったタイミングで、これらの選択肢も検討すると良いでしょう。
この記事が、RAGをAzureで始める際の最初の一歩になれば嬉しいです。
ここまでお付き合いいただきありがとうございました!!