

LifeKeeperの『困った』を『できた!』に変える!サポート事例から学ぶトラブルシューティング&再発防止策
こんにちは、SCSKの前田です。
いつも TechHarmony をご覧いただきありがとうございます。
これまでの連載では、クラウド環境特有の挙動やOSバージョンアップ時の注意点を中心に解説してきました。しかし、クラウド上でHAクラスタを構築する際、避けて通れないもう一つの大きなテーマがあります。それが、DataKeeperを用いた「データレプリケーション(シェアード・ナッシング構成)」です。
クラウド環境ではオンプレミスのような共有ストレージ(SAN)が利用できないケースが多く、DataKeeperによってネットワーク経由でリアルタイムにデータを同期する手法が主流となっています。この仕組みは非常に強力ですが、一方で「データの複製」という物理的な制約を伴うため、オンプレミスでの共有ディスク構成に慣れたエンジニアほど、同期中の挙動やパフォーマンスへの影響、そして障害発生時の動作に頭を悩ませることが少なくありません。
「同期中なのにフェイルオーバーが発生したらどうなるのか?」「大量のデータ転送がアプリの性能を圧迫しないか?」――こうした疑問は、設計や検証の現場で必ずと言っていいほど浮上します。
本連載企画「LifeKeeper の『困った』を『できた!』に変える!サポート事例から学ぶトラブルシューティング&再発防止策」のカテゴリ4では、データ保護の核心である DataKeeper にスポットを当て、現場で直面しがちな「ミラー同期の壁」を乗り越えるための実践的な知恵を共有していきます。
1. はじめに
今回のテーマは、DataKeeperの運用において最も重要な「ミラー同期中の挙動」と「性能への影響」です。
DataKeeperは、稼働系ノードのデータを待機系ノードへ常に複製し続けることで、共有ディスクなしでの高可用性を実現します。しかし、この「同期」というプロセスは、LifeKeeperのフェイルオーバー判断とも密接に関わっています。そのため、同期の状態を正しく理解していないと、いざという時の障害試験で「想定通りに切り替わらない!」といった事態を招きかねません。
本記事では、サポートセンターに寄せられた具体的な事例を通じ、DataKeeperがデータの整合性を守るためにどのような挙動を見せるのか、そしてパフォーマンス評価において陥りがちな「罠」をどう回避すべきかを、以下の3つの観点から深掘りします。
- 同期中の障害発生時、フェイルオーバーが成立する「絶対条件」とは?
- メモリやIOPSへの影響を正しく評価する方法
- Windows環境でのサービス起動失敗を防ぐ設計のポイント
これを読めば、DataKeeperの同期ステータスに対する不安を解消し、自信を持って構築・運用に臨めるようになるはずです。
💡 次回の記事(カテゴリ4 第2弾)はこちら!
▶【DataKeeper:ミラー同期とデータ保護の核心 #2】スナップショットから戻したのに動かない!?リストア後の「整合性」確保とバックアップ連携の盲点 – TechHarmony
今回の「困った!」事例
【ケース①】同期中の障害試験でフェイルオーバーが失敗する
-
事象: AWS環境での障害試験中、アクティブ系ノードのネットワークをセキュリティグループで遮断したところ、待機系へのフェイルオーバーが失敗し、リソースの開始に失敗した。
-
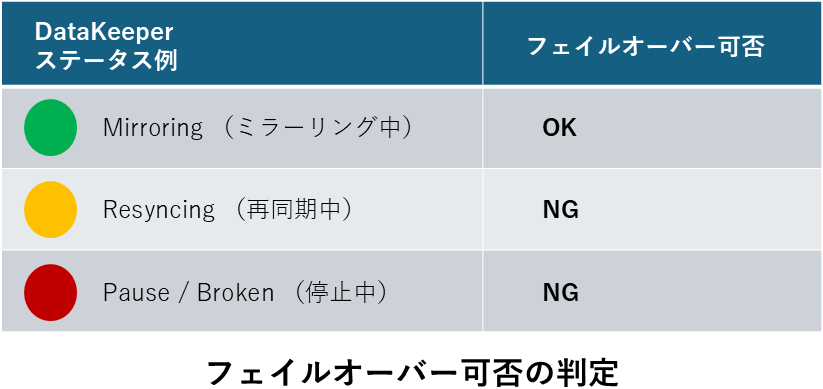
原因究明のプロセス: まず、DataKeeperにおけるフェイルオーバーの「絶対条件」を整理しましょう。DataKeeperはデータの整合性を守るため、ミラー状態が「Mirroring(ミラーリング中)」である時しか、原則として切り替えを許可しません。
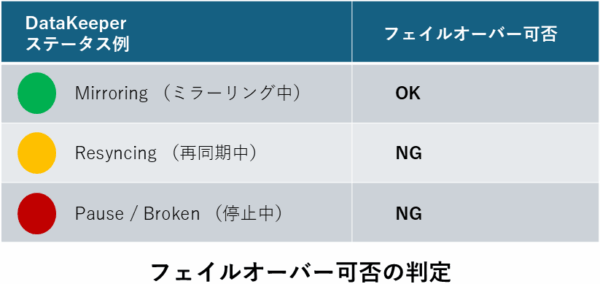
たとえLifeKeeperが「相手がダウンした!」と判断しても、DataKeeperのステータスが青信号(Mirroring)でない限り、安全装置が働いてフェイルオーバーは中止(Abort)されます。これはWindows版でもLinux版でも変わらない、DataKeeper運用の鉄則です。
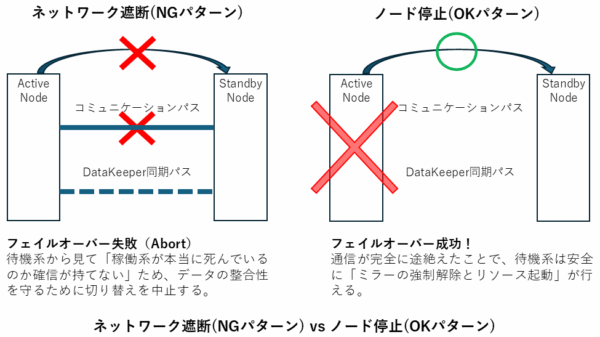
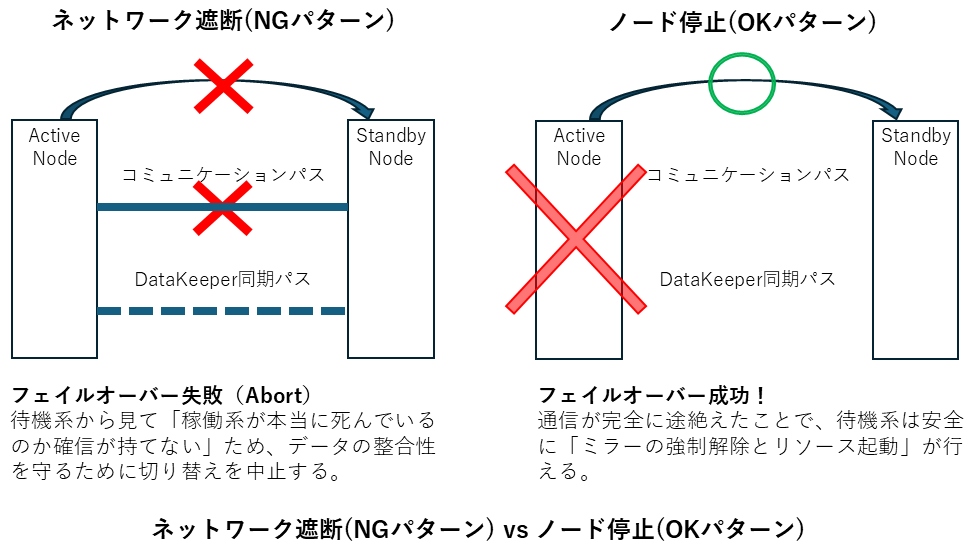
今回の「失敗」の深層 では、なぜ今回の試験では失敗したのでしょうか? 実はここにクラウド環境特有の「罠」がありました。ネットワークをセキュリティグループで中途半端に遮断したことで、心拍確認(コミュニケーションパス)は途絶えたものの、DataKeeperの同期用ポートの「セッションが残っている(まだ通信が続いている)」と誤認される状態になっていたのです。
これにより、待機系ノードは「稼働系はダウンした」と判断して切り替えようとしたものの、DataKeeper側が「いや、まだ相手からのパケットを感じる(err=55)。整合性が保てないから切り替えられない!」と拒否してしまった――。これが「err=55」によるAbortの正体です。
【ケース②】大量データ移行時のメモリ・IOPSへの影響
-
事象: 初期構築や大量データ移行時に、「同期処理がメモリを圧迫してアプリに影響が出ないか?」という不安や、「DataKeeper自体のIOPSを測定したい」という要望。
-
原因究明: DataKeeperの同期処理自体は、CPUやネットワークは使用しますが、メモリを大量に消費する仕組みではありません。ただし、OSレベルのファイル書き込みによるキャッシュ消費は発生します。
-
解決策: DataKeeper単体のIOPSを直接測る機能はありません。そのため、下記のように「同期がある時」と「一時停止した時」の差分で計測し、オーバーヘッドを評価するのが実務的な手法です。
・STEP 1(同期あり): [アプリ] → [OS書き込み] → [DataKeeper同期] → [ディスク] =合計の IOPS
・STEP 2(同期一時停止): [アプリ] → [OS書き込み] ―(同期停止中)―→ [ディスク] =素の IOPS
・測定の結論 : STEP 1 - STEP 2 = DataKeeperによるオーバーヘッド
「再発させない!」ための対応策と学び
■ 障害試験のベストプラクティス
クラウド環境での「ノード障害」試験では、ネットワーク遮断(セキュリティグループ)ではなく、インスタンスの「停止」や「OSクラッシュ(NotMyFault等)」を利用してください。これにより「確実な通信断」を発生させ、DataKeeperを迷わせることなくフェイルオーバーさせることが可能です。
■ Windows環境での「自動(遅延開始)」の活用
OS起動時にDataKeeperサービスが他のサービス(イベントログ等)との連携に失敗し、自動起動に失敗するケースがあります。
- 対策: LifeKeeperおよびDataKeeperのサービスを「自動(遅延開始)」に設定することで、OS起動時のリソース競合を回避し、安定した起動を実現できます。
■ 設計時の柔軟な構成
LVM(論理ボリュームマネージャー)で一つのディスクを分割し、それぞれの論理ボリュームに対してデータレプリケーションリソースを作成することも可能です。マウントポイントとデバイスが適切に認識されていれば、製品仕様上の制限はありません。
構築・運用の再確認チェックリスト
設計・構築時に以下の項目を確認しておきましょう。
- 同期ステータス監視: 運用監視項目に「ミラー状態」が含まれているか?(Mirroring以外での切り替えは不可と認識しているか)
- LVM構成の確認: Linux環境でLVM分割した論理ボリュームごとにレプリケーション設定が可能であることを理解しているか?
- サービス起動設定: Windows環境では「遅延開始」を検討したか?
- 障害試験シナリオ: ネットワーク遮断ではなく、ノード停止をベースにした試験計画になっているか?
まとめ
DataKeeperは、データの整合性を何よりも優先します。そのため、「同期が不完全な状態」や「通信が不安定な状態」では、あえて動かないことで大切なデータを守っているのです。
「なぜフェイルオーバーしないのか?」という「困った」に直面した時は、まずミラーのステータスと、障害試験の手法が適切かを確認してみてください。この特性を理解することで、より堅牢なシステムの構築が可能になります。
次回予告
次回の「DataKeeper:ミラー同期とデータ保護の核心」シリーズ第2弾では、今回解説した「リアルタイムの同期」から一歩進んで、運用に欠かせない「バックアップとリストア」にフォーカスします。
【DataKeeper:ミラー同期とデータ保護の核心 #2】 スナップショットは万能じゃない!?バックアップ連携の注意点とリストアの最適手順
「クラウドのスナップショット機能を使えばバックアップは完璧」……そう思っていませんか? DataKeeperが管理するボリュームに対して、VSS(ボリューム・シャドウ・コピー・サービス)やクラウド標準のスナップショット機能を利用する場合、実はDataKeeperの挙動やデータの整合性に配慮した「作法」が必要です。
- スナップショット取得中、DataKeeperの同期に影響はあるのか?
- スナップショットからリストアした後、DataKeeperのミラーを正しく再開させる手順とは?
次回は、クラウド環境でのデータ保護をより盤石にするための、バックアップ連携のベストプラクティスを具体的な手順と共に詳しく解説します。どうぞお楽しみに!
📚 本連載のバックナンバー
過去のトラブル事例と解決策もぜひあわせてご覧ください!
カテゴリ1:リソース起動・フェイルオーバー失敗の深層
▶【リソース起動・フェイルオーバー失敗の深層 #1】EC2リソースが起動しない!クラウド連携の盲点とデバッグ術 – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #2】ファイルシステムの思わぬ落とし穴:エラーコードから原因を読み解く – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #3】設定ミス・通信障害・バージョン違いの深層と再発防止策 – TechHarmony
カテゴリ2:OS・LKバージョンアップで泣かないために
▶【OS・LKバージョンアップで泣かないために #1】OSバージョンは変えていないのに!?カーネル更新の「落とし穴」と互換性の真実 – TechHarmony
▶【OS・LKバージョンアップで泣かないために #2】「設定が消えた!?」「亡霊IPが警告!?」を防ぐロードマップ:単純な上書き更新に潜む落とし穴と回避策 – TechHarmony
カテゴリ3:クラウド環境特有の落とし穴
▶【クラウド環境特有の落とし穴 #1】良かれと思った自動復旧が仇に!?AWS環境(EC2/Route53/S3)でハマる構成と回避策 – TechHarmony
▶【クラウド環境特有の落とし穴 #2】オンプレ感覚の「同一サブネット」はNG!?Azure環境のネットワーク要件とQuorum設計の最適解 – TechHarmony
カテゴリ4:DataKeeper:ミラー同期とデータ保護の核心
▶【DataKeeper:ミラー同期とデータ保護の核心 #1】同期中だから切り替わらない!?フェイルオーバーの「絶対条件」と性能評価の罠
▶【DataKeeper:ミラー同期とデータ保護の核心 #2】スナップショットから戻したのに動かない!?リストア後の「整合性」確保とバックアップ連携の盲点 – TechHarmony
カテゴリ5:クラスタ健全性維持の要
▶【クラスタ健全性維持の要 #1】クラスタの番人Quorum/Witness:その設定、本当に必要? 正しく選んで正しく守る設計術 – TechHarmony