

前回の記事「Dropbox APIでデータ移行ツールを作ってみた (前編) 」では、データ移行で使用するDropbox APIエンドポイントとサンプルコードを紹介しました。弊社が開発したデータ移行ツールでは、upload_session系のエンドポイントを使ってファイルデータのアップロードを並列で処理するようにしています。
今回は、実際並列でファイルデータをアップロードするようにしたら、どれだけ効果があるのかを実際に開発したツールを使って検証しようと思います。また、並列化以外に工夫したポイントなども紹介したいと思います。
データ移行検証1
まずは、ファイルアップロードの並列度を変えると、移行時間がどれだけ短縮できるのか?という観点で検証してみましょう!
検証方法と環境
- ネットワーク回線速度 (ネットワーク回線速度計測サイトを使って計測):
- アップロード 130Mbps
- ダウンロード 150Mbps
- ファイルサイズ: 2MiB/ファイル
- 転送ファイル数:10ファイル (合計 20MiBの転送)
- 検証パターン:
- 並列度:1, 2, 4, 10 (データアップロード・ワーカープロセス数)
- コミット(※):並列度と同じに固定
※ コミットとは、finish_batchでのメタデータ書込み対象ファイル数のことです
並列度1 のときは、メタデータも 1ファイルずつ書き込むという感じで。
- 検証組み合わせ:
- 並列度1 x コミット数1
- 並列度2 x コミット数2
- 並列度4 x コミット数4
- 並列度10 x コミット数10
検証1の結果と考察
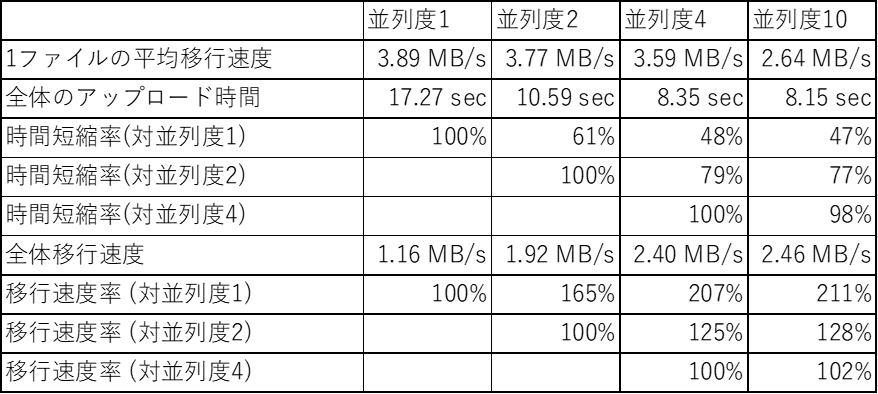
表1:並列度の違いと移行速度
並列度1の場合、upload_session/start & append で1ファイル分のデータをアップロードし、その後 upload_session/finish_batch で 1ファイル分のメタデータの書込むというのを、10ファイル分繰り返しています。
一方、並列度10の場合、10ファイル分のデータを並列にアップロードし、1回で10ファイル分のメタデータを書き込みます。
表1を見ると、並列度1 から並列度2にすると、全体のアップロード時間が約 60% に短縮されています。2並列でファイルをアップロードするからといって、アップロード時間が半分にはなりませんでした。
並列度を「4」にした場合、アップロード時間が 約50%になっています。並列度2の場合時間を40%削減できましたが、並列度4では並列化の効果は少なくなっています。並列度を「10」にした場合、全体のアップロード時間は並列度4とほぼ同じくらいで、並列度をぐんと上げた効果は余り出ていないような感じです。
表1の「1ファイルの平均移行速度」を見てください。並列度を上げると反比例して、1ファイルの平均移行速度が遅くなっていることがわかりますね。並列化は、データ送信処理を行うプロセスを複数作成し、各プロセスが同時並行でファイルアップロードを行うように実装されていますが、プロセス数がPCに搭載されているCPUのコア数以上になると、各プロセスが本当の意味での同時進行ではなくなってしまいます。検証に利用したPCのコア数は 8 だったため、並列度10だとコア数を超過しており、処理速度の短縮にはならなかった可能性があります。他にも、ネットワークの帯域など外部要因の影響もあるでしょう。
この結果から、並列度を上げれば単純に比例してデータ移行時間が短くなるわけではないことがわかります。実際にデータ移行を行う際は、利用するPCやネットワーク環境などの影響を考慮し、事前検証して最適な並列度を調べる必要があります。弊社がお客様のデータ移行を行う際に必ずお客様環境での事前検証作業を行うのは、このためです。
参考記事: Dropboxへのデータ移行ってどうやるの?
データ移行検証2
次の検証では、もう少しデータ移行規模を大きくしてみたいと思います。検証1と同じファイルを利用しますが、ファイル数を増やして 合計 1GiB のデータ移行を実施したいと思います。
検証方法と環境
- ネットワーク回線速度 (検証1と同じ):
- アップロード 130Mbps
- ダウンロード 150Mbps
- ファイルサイズ: 2MiB/ファイル (検証1と同じ)
- 転送ファイル数:
- 500 ファイル (合計 1 GiBの転送)
- 検証パターン:
- 並列度:1, 4, 10, 15
- コミット数:50 (データ移行ツールのデフォルト値)
検証2の結果と考察
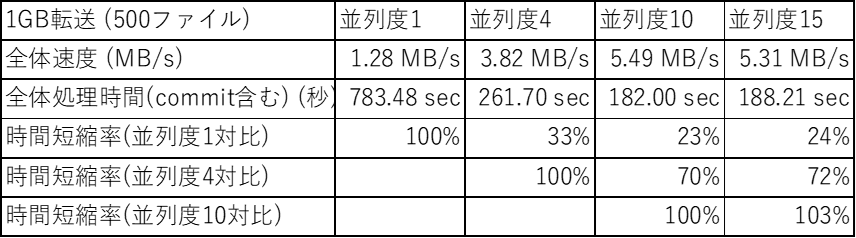
表2 検証2の結果
表2のとおり、1GiBのデータ移行時間は、並列度1の場合は約13分 (783秒)、並列度4の場合は 約4.4分、並列度10だと約3分となりました。10ファイル(20MiB)の場合よりも移行したデータ量(ファイル数)が大きいので、並列度による移行時間の違いがはっきりでています。並列度10だと 並列度1と比較して 約4.5倍速くなっています。
一方、並列度10と並列度15では、並列度15の方が遅くなっています。これは、並列度15の場合Dropboxへのデータアップロード処理で一時的なエラーが発生したことが影響していると思われます。データ移行ツールでは、一時的なエラーが発生すると少し時間を空けてから再アップロードするように実装しているため、全体的な処理時間が伸びてしまったようです。
最も速度が早かった、並列度10の結果を元に1TBのデータを移行するのみかかる時間や1ヶ月で移行可能なデータ量を計算してみると….
1TBのデータなら 50時間 ( 1GB 約3分 = 3 x 1,000 = 3,000分 = 50時間)
1ヶ月で 約 14 TB ( 50時間/TB なので 30日 x 24時間 ÷ 50時間/TB ≒ 14.4 TB)
ネットワーク帯域に余裕があるなら、PC台数を増やし、それぞれ別フォルダを移行するようにすることで、1ヶ月で移行できるデータ量を増やすことも可能です。
アップロード時のエラーについて
並列度15の場合に、データアップロード時に発生したエラーは、「429 – Too many requests」というものです。Dropbox APIリファレンス・マニュアルによると、「このエラーは過去数分間に送信したリクエスト数が多すぎる」ことで発生するようです。これは、Dropbox社がDropboxを利用している全ユーザに平等にサービスを提供するという観点から、特定ユーザのリクエストばかり処理することを制限しているために発生するエラーです。エラーになる条件、閾値は非公開のため、アプリ側でこのエラーが発生しないように制御することは難しく、エラー発生時の処理をしっかり作っておく必要があります。
リファレンス・マニュアルには「Too many requests」のエラーが発生した場合は、エラーレスポンスに含まれる「Retry-Later」で指定されている秒数間待ったあと、リクエストを再送するようにと書かれています。弊社のデータ移行ツールでは、「Too many requests」エラーのエラーエスポンスを解析し、Retry-Laterで指定された秒数間、sleepし、再アップロードを試みるように設計しています。このようにすれば、データ移行の確実性はアップしますが、sleep時間が発生することで全体の処理時間は延びてしまいます。移行処理時間を単純に短くするだけなら、エラー時はそのファイルの移行を諦め、次に処理を進めるという方法もアリですね。
並列度を高くした結果、Too many requests エラーが多発するような状況になると、待機時間が増え、移行時間がどんどん延びてしまいます。Too many requestsエラーが発生したことを、他のプロセスに知らせるような作りにはなっていないため、最悪すべてのプロセスがToo many requestsエラーになってしまい、全体のアップロードがしばらく進まなくなる可能性もあります。したがって、このエラーが発生しない程度の並列度を探るというのが、重要となってきます。
今回の検証では、やや大きめのファイルサイズとなる 2MiB のものを使っていましたが、テキストファイルやMicrosoft Officeのファイルなど小さなファイルが中心の場合は、1ファイルの送信時間が短くなる分、リクエスト数が増えちゃいますので、Too many requestsエラーの確率が高くなることが予想されます。その場合は、並列度を下げるなどの工夫が必要かもしれません。移行データの平均ファイルサイズも、並列度を決めるパラメータになりそうですね。
- 移行ファイルサイズが大きい => 並列度 高
- 移行ファイルサイズが小さい => 並列度 低
データ移行ツールの開発秘話
「開発秘話」なんておおげさな見出しにしちゃいましたが、ここでは開発時に工夫したこととか、まだやりきれていないことととかをご紹介したいと思います。
差分移行機能とミラー機能
データ移行ツールの開発は、お客様のデータ移行を実施するためにツールが必要というのが出発点でした。
ファイルサーバからクラウドへのデータ移行は、ファイルサーバ間移行のような速度を出せないため、データ移行期間中もお客様にはファイルサーバのデータを使って通常業務を継続して頂く必要があります。このため、通常業務で発生したファイルの追加、更新、削除を、移行先であるDropboxに反映する必要があります。この更新分を反映するために実施する再アップロード作業を「差分移行」と呼んでいます。
差分移行では、ファイルサーバとDropboxにアップロードし終わっているデータの「突き合せ」を行い、差分移行すべきファイル(下記の①~③)を検出するわけです。
① ファイルサーバに新しく追加されたファイル
② ファイルサーバで更新されたファイル
③ ファイルサーバで削除されたファイル
①の検出は、Dropboxに存在しないファイルを見つければOKです。初回移行で移行できなかったファイルも①としてアップロード対象になりますので、エラーリカバリもできて一石二鳥です。
③の検出は、Dropboxだけに存在するファイルを見つけます。見つけたあと、Dropboxのファイルを削除すべきかどうかは、お客様データですので消す消さないは選択できたほうが良さそうです。
②の更新されたファイルの検出は、いくつかのパターンが考えられます。
A. ファイルサイズが一致しない (ファイルを書換えたら、サイズが変わる)
B. ファイル更新時間が異なる (ファイルを書換えたら、更新時間が新しくなる)
C. ファイルの中身が一致しない (ハッシュ値を計算し、比較する。Dropboxはファイル情報としてハッシュ値を持つ)
A.は、テキストファイルとかだと、一文字だけの書き換えではファイルサイズが変わらないこともあります。このため、ファイルサイズが同じだからといって移行対象外にするのは、ちょっとリスクが高そうです。
B.は、逆にファイルの中身は変わっていないのに、更新時間だけ新しくなるという可能性があります。差分移行は、できだけアップロードすべきデータ量を少なくし、短時間で終わらせたいので、ファイルデータが異なるものだけをアップロードするようにしたいですね。
と考えると、アップロード対象のファイルの検出は、ハッシュ値を比較するのが確実そうです。
Dropboxの場合、保存されているファイル一覧データを取得すると、その中に「content_hash」という計算されたハッシュ値が含まれます。また、このハッシュ値を計算する方法も公開されていますので、ファイルサーバ側のファイルデータのハッシュ値を計算し、content_hashの値と比較することでファイルの中身が一致するか、一致しないかを判断できます。弊社のデータ移行ツールでは、標準ではハッシュ値比較を行い、差分移行対象のファイルを決定するようにしています。
ただ、ハッシュ値を計算するには、一度ローカルファイルを読み込む時間が必要になるため、パフォーマンスはよくありません。なので、ファイル更新時間だけ見るオプションも用意しています。
そして、先程の③。Dropboxにしか存在しない というのは実は、ふたつの可能性があります。
A. 初回移行後、ファイルサーバ側でファイルを削除したため、アップロード済みのファイルがDropboxに残ってる
B. Dropboxに直接ファイルを作ってしまった (もともとファイルサーバには存在しないファイル)
A. なら機械的に削除しても問題なさそうですが、B. のファイルを削除しては問題となってしまう可能性があるため、機械的に「削除」するわけにもいきません。そこで、弊社のデータ移行ツールでは、標準では③の場合、ログに記録を残すだけでDropbox側のファイルは削除しません。オプションで、移行元と移行先が完全に一致する状態にする「ミラーモード」を用意し、ミラーモードを選択すると、Dropboxにしか存在しないファイルを「削除」するようにしています。
Pythonのマルチプロセス構成と移行ログ
データ移行ツールでは、ファイルアップロード処理を並列化するために図1のように少し複雑なプロセス構成となっています。
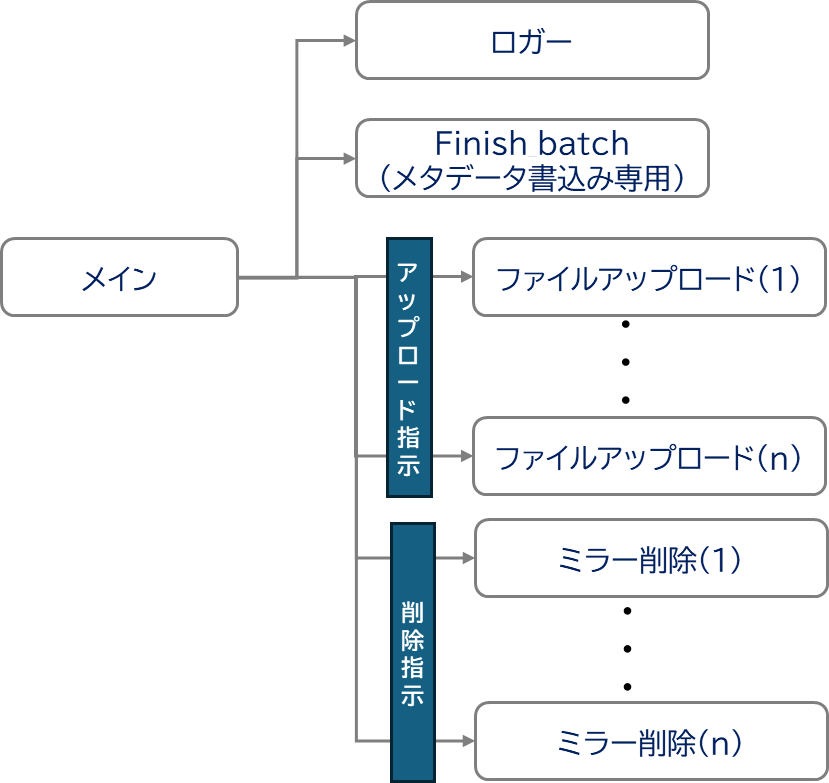
図1 データ移行ツールのプロセス構成
メインプロセスが、移行元フォルダに保存されているファイルリストを読み出し、各ファイルアップロードプロセスに割り当てていきます。ミラーモードで移行している場合、Dropboxのみに存在するフォルダ/ファイルを削除する処理も並列化されています。他にファイルアップロードの結果をまとめ、指定されたコミット数分まとめてファイルメタデータをDropboxに書き込む処理も独立したプロセスとなっています。
複数プロセスで構成されているため、致命的エラーやユーザによる処理中止時など、動いているプロセスをきれいに終了するようにしています。
また、移行できたのか、できていないのかを確認できるようにするため、すべてのデータ移行結果をログファイルに記録する必要がありますが、複数プロセスから1つのログ・ファイルに書き込むことはできません。このため、各プロセスではログメッセージなどファイルに記録したいメッセージをメッセージキューを介して、ログ書込み専用プロセスに受け渡し、ログ書込み専用プロセスが順番にファイルに書き込むという仕組みを採用しています (図2)。
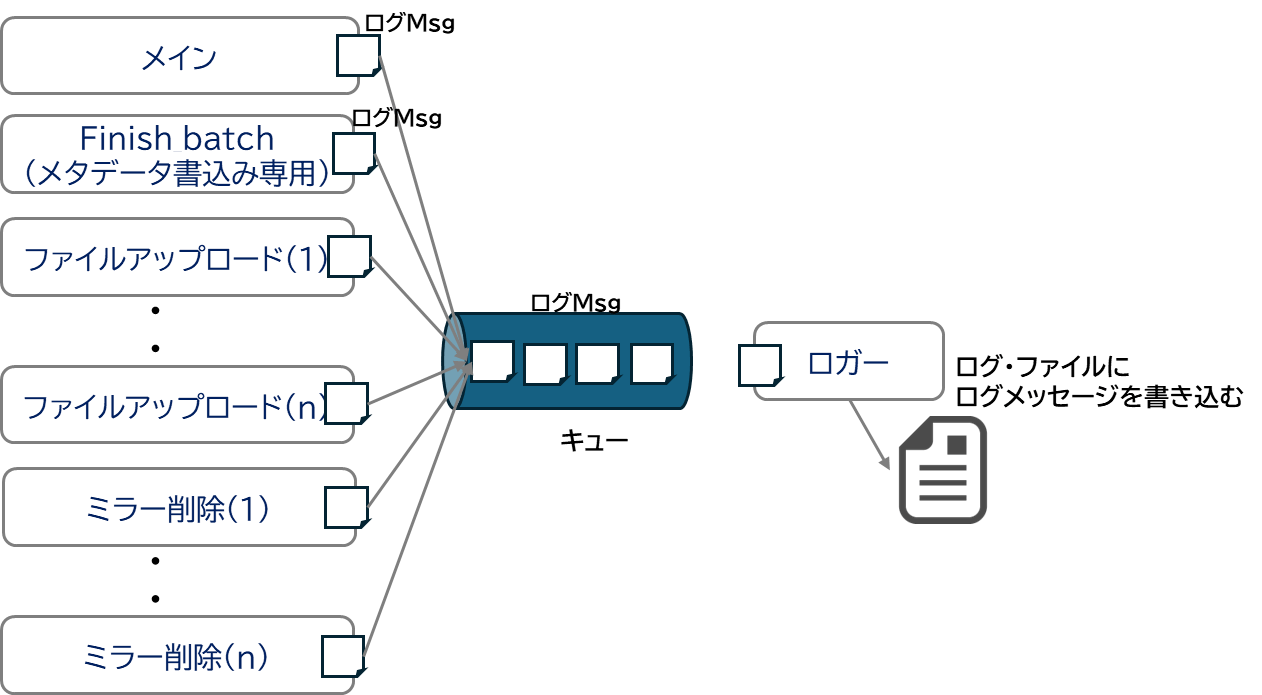
図2 ログメッセージの出力
ファイルアップロードプロセスはバイナリデータのアップロードが完了すると、アップロードしたデータのファイル情報をメッセージキューを介して、finish_batchプロセスに渡します。finish_batchプロセスは、キューから受け取ったファイル情報が指定された数分溜まると upload_session/finish_batchエンドポイントを使ってメタデータの書込みを行います。
ファイル名に利用できない文字が含まれたり、指定されたパスが正しくないなど、メタデータの書込み時にエラーとなる場合もあります。このため、finish_batchエンドポイントのレスポンスを確認し、成功、失敗をきちんとログに書き込むことが重要なポイントとなっています。

図3 メタデータの書込み
おわりに
前回、今回とDropbox APIを駆使して開発したデータ移行ツールの仕組みなどを紹介しました。興味をもって読んで頂けたでしょうか? 今後もDropbox APIやDropboxのちょっとDeepな記事をご紹介していきたいと思います!
SCSKでは、お客様のご要件に合わせたDropbox APIツールの開発も行っております。Dropbox運用の効率化や棚卸しなどでツールがほしい!といったご要望があれば、是非 SCSKまでご遠絡頂けたらと思います
問合せ先: dropbox-sales@scsk.jp
弊社Dropbox紹介ページ: https://www.scsk.jp/product/common/dropbox/index.html