
SCSKの畑です。
今回もデータベース関連の話題ですが、若干毛色の異なる内容となります。
要件とその背景
本案件における MySQL (RDS/Aurora) の各種ログは Cloudwatch Logs に出力されているような設計となっているのですが、ログの一部をマスキングできないかという相談を受けました。具体的には以下のような要件です。
- 本番環境用 AWS アカウントの Cloudwatch Logs に出力されたログはマスキングしない
- 運用保守用 AWS アカウントの Cloudwatch Logs に本番環境用 AWS アカウントで出力されたログを転送し、その際にログの一部をマスキングしたい
上記要件の背景として、お客さんが本番環境用 AWS アカウントでオペレーションする場合は、本番運用ルーム(特権区画)に入室の上、各種制約の下で作業する必要があります。よって、一般区画でもアクセスできる AWS アカウント上で本番環境の RDS/Aurora ログ確認・分析やそれに基づく各種調査を行えるようにすることで、より円滑に運用・保守を行えるようにしたいという意図がありました。
ただし、MySQL ログにはいわゆる PII のような機微な情報が含まれる可能性があることから、運用保守用 AWS アカウントの Cloudwatch Logs にログを転送する際は 100% 確実にマスキングを行う必要があります。ここが方式検討時におけるポイントでした。
補足:マスキング対象の MySQL ログについて
そもそも、PII のような機微な情報が含まれる可能性がある MySQL ログがあるのか?と思われる方もいるかもしれません。その疑問自体は正しいと思っていて、実質的に「データベース上で実行された SQL 文がそのままログに出力される」ようなケースのみが該当します。例えば SQL 文の where 句にそのような機微な情報が含まれているようなケースですね。
つまり、データベース上で実行された SQL 文がそのままログに出力され得る MySQL ログのみをマスキング対象とすれば OK ということになります。具体的には以下 3 種類となりますが、MySQL エラーログについては極めて限定的なケースであるため、実質的にはほぼスロークエリログ及び監査ログのみが対象となります。
- MySQL エラーログ
- スロークエリログ
- 監査ログ(クエリ情報を出力する場合)
本案件では監査ログにクエリ情報を出力しない方針であったため、まずはスロークエリログを対象に検討を進めることになりました。
スロークエリの出力例は以下の通りです。ヘッダとして実行時間やユーザ、クエリ実行時の各種統計情報が含まれており、実行された SQL 文の情報は SET timestamp 文の直後に出力されます。
# Time: 2025-05-13T05:36:51.377085Z # User@Host: admin[admin] @ [10.10.51.21] Id: 6102 # Query_time: 1.192364 Lock_time: 0.000002 Rows_sent: 0 Rows_examined: 4999999 use test; SET timestamp=1747113033; select * from regex_test where col1 > 100 and col2 = "abc"
実装案1:Bedrock or マスキングに適したマネージドサービスの使用
元々のお客さんからの要望としては、生成AI(LLM)や機械学習などを使用して、非決定的なルールで PII のような情報を検知してマスキングを実現できないか?という内容でした。正規表現などを使用してログマスキング用のスクリプトを実装するようなアプローチでは決定的なルールとなるため、未知のパターンにそのまま対応できないこと、対応に際して相応のコストがかかることなどが理由でした。AWS 上でそのような仕組みの実装を検討するとなると、当然ですが Bedrock が候補となります。
一方で、生成 AI の原理・特性上、PII のような情報を含むログを入力しても 100% マスキングできるという保証はありません。生成 AI が非決定的なルール(プロンプト)を解釈して処理ができる以上、その振る舞いも非決定的になることは現状避けられないとも言えます。いずれにせよ、先述の通り運用保守用 AWS アカウントの Cloudwatch Logs にログを転送する際は 100% 確実にマスキングを行う必要があり、この要件を満たすことができなかったため今回は見送りとなり、決定的なルールによるマスキング方式を採用することとなりました。
なお、元々のお客さんの要件としては必ずしも生成 AI(LLM)の使用が前提ではなく、例えば Cloudwatch Logs のマネージドデータ保護ポリシーや Macie、Comprehend などのマネージドサービスを使用して PII 情報のマスキングをすることも並行して検討していました。残念ながらいずれのサービスも日本語に対応していない情報が多かったため、いずれも候補から外さざるを得なかったというのが正直なところです。(Macie は PII 情報の検知までが対象となるため、その先のマスキングをどうするかはまた別問題となりますが・・)


ログマスキング方針及びルールの検討
さて、先述の通り決定的なルールを定めることになりましたが、そのルールを定めるためにスロークエリログに含まれる SQL 文のどの部分をどうマスキングするのかの方針を検討する必要がありました。
当初は PII に該当する情報が含まれるテーブルやカラム及び具体的な PII 情報についてお客さんに調査頂いた上で、その対象が SQL 文内に含まれる場合のみ該当情報をマスキングするようなルールを検討する、という進め方を検討していました。SQL 文におけるマスキング範囲が広くなればなるほど当然ながらログ(情報)の価値は相対的に下がってしまうためです。
ただ、お客さん側で調査に割ける工数が限定的であり、ログマスキング対象を十分に特定かつ網羅できるだけの情報をプロジェクト期間内に整理するのが難しそうということが分かったため、お客さんとも協議の上、最終的には「MySQL の SQL 構文上 PII 情報が含まれ得る箇所を全て網羅的にマスキングする」という方針でマスキングを行うことに決定しました。また、網羅的にマスキングすることを最優先とし、本来対象外の部分がマスキングのルール・仕組み上マスキングされてしまうことは許容する旨も合わせて決定しました。
その方針を踏まえて、SQL 構文を MySQL のドキュメントから調査した結果、MySQL におけるリテラル値をマスキングすれば、必然的に SQL 構文上 PII 情報が含まれ得る箇所を全て網羅的にマスキングできるのではないかと考えました。

検討の結果、上記 URL に示されているリテラル値の一覧から、「数値」と「文字列リテラル」の 2 種類を対象にマスキングするようなルールであれば上記要件を満たせるのではないかと最終的に判断しました。数値リテラルではなく数値を対象とすることで、日付リテラルや 16 進数リテラルの一部を合わせてマスキングできるためです。booleanリテラルや NULL 値は対象外となりますが、一旦は対象外として良いということでお客さんと合意しました。必要になった場合は追加すればよいという判断です。
実装案2:Cloudwatch Logs のカスタムデータ識別子の使用
上記決定を踏まえてまず考えたのが Cloudwatch Logs のカスタムデータ識別子の使用です。Cloudwatch Logs 内でログマスキングを完結できるシンプルな構成となりますし、ドキュメントを見る限りは正規表現も使用できるので「数値」と「文字列リテラル」の 2 種類を対象にマスキングするようなルールも実装できそうと考えたためです。

ということで早速試してみたのですが以下のような制約が発覚したため、結論として今回は使用できないという判断になりました。
- 使用できる正規表現の記法が限定されている
- 正規表現パターンにマッチした部分が全てマスクされるような挙動となる
- 1つのロググループに対して設定できるカスタムデータ識別子が最大 10 個
- 200 文字以上の正規表現パターンは使用できない
今回、特にネックとなったのは 1、2 点目でしたので、もう少し掘り下げて説明します。
使用できる正規表現の記法が限定されている
私の検証した範囲ですが、最小マッチや前方/後方参照、否定先読みといった正規表現パターンが使用できませんでした。特に、否定先読みのような複雑な正規表現パターンについては「regex too complex」のようなエラーが表示されてしまい、カスタムデータ識別子として登録できませんでした。
また、「文字列リテラル」にマッチングさせる正規表現パターンに最小マッチが使用できないのも実用上問題がありました。例えば、ダブルクォートで囲われた文字列リテラルは一例として “[^”]*?” のような正規表現でマッチングできますが、最小マッチ (?) が使えないので “[^”]*” となってしまいます。ダブルクォートで囲われた任意の文字列が最大マッチとなってしまうため、本来マスキング対象として意図していない部分までマスキングされてしまいます。
具体例を挙げると、以下のような SQL 文の場合は
select * from regex_test where col1 > 100 and col2 = "abc"
以下のようにほぼ想定通りマスキングできます。
select * from regex_test where col1 > 100 and col2 = *****
一方で、このように文字列リテラルが複数現れるような SQL 文の場合は
select * from regex_test where col1 > 100 and col2 = "abc" and col3 = "edf"
最大マッチの影響で、col2 への問い合わせ条件に指定された文字列リテラルから、col3 への問い合わせ条件に指定された文字列リテラルまでが丸々正規表現パターンにマッチングしてしまうため、より広い範囲がマスキングされてしまいます。この SQL の場合だと col3 への問い合わせ条件が完全にマスキングされてしまい、元の SQL 文の構造的な情報が失われてしまいます。
select * from regex_test where col1 > 100 and col2 = ******************
この SQL 文は単純な分まだマシですが、サブクエリや複数表の結合などが含まれる複雑な SQL 文の場合は文字列リテラルの最大マッチによってマスキングされてしまう範囲が更に膨大になることも考えられます。先述した通り、本来対象外の部分がマスキングのルール・仕組み上マスキングされてしまうことは許容するという方針があるとしても、SQL 文の原型を留めないような広範囲をマスキングされてしまうと運用保守用 AWS アカウント上のログから有意な調査ができなくなってしまうということになります。
正規表現パターンにマッチした部分が全てマスクされるような挙動となる
こちらは数値のマスキングで問題となりました。先述した通り、スロークエリログのヘッダには様々な情報が含まれていますが、単純に数値をマスクすると以下の通り、重要な情報が概ねマスクされてしまうことになります。
# Time: ****-**-**T**:**:**.******Z # User@Host: admin[admin] @ [**.**.**.**] Id: **** # Query_time: *.****** Lock_time: *.****** Rows_sent: * Rows_examined: ******* use test; SET timestamp=**********; select * from regex_test where col* > *** and col* = "abc"
数値は文字列リテラルと違いシングルクォート/ダブルクォートによる囲み文字がないため、シンプルな正規表現で SQL 文内の数値にのみマッチさせることが困難です。よって、現実的な方法としては SET timestamp 文以降の SQL 文のみを正規表現によるマスキングの対象とすることが最も簡単な解決策なのですが、残念ながらカスタムデータ識別子ではパターンマッチした部分が全てマスクされてしまうような仕様のためこのような対応が取れませんでした。
実装案3:Lambda(Python)の使用
ということでより幅広い正規表現の記法を扱えるソリューションとしては、やはり Lambda(Python)の使用がベターではないかという結論となりました。先述したログマスキングルールを実装する分にはある意味どうとでもなるため、Lambda を使用したログマスキングをどのようなアーキテクチャで実現するのかの検討に入りました。
アーキテクチャとしては大まかに以下 2 つの案をお客さんと検討しましたが、スロークエリログの性質上大量に出力されるようなケースは少ないため、アーキテクチャのシンプルさを取って結論としては案 1 を採用しました。もし今後ログ出力が増大したり、出力量の多いログがマスキング対象に追加された場合は、案 2 の方が筋が良さそうではあります。
案1:Cloudwatch Logs のサブスクリプションフィルタ経由でログマスキング用の Lambda をリアルタイム実行
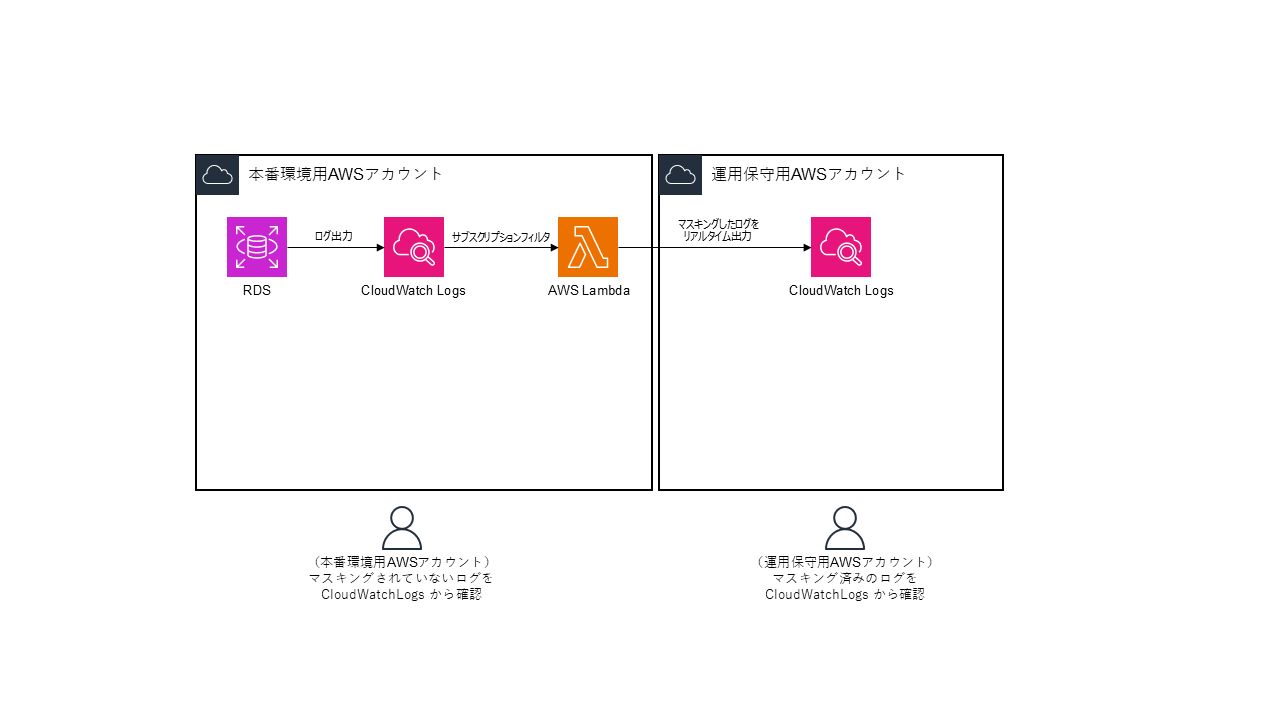
先述した通りのシンプルな構成で、マスキングされたログを運用保守用 AWS アカウントにリアルタイム出力できます。ログ出力量に応じてログマスキング用 Lambda の呼び出し回数が多くなるためコスト面への影響が考えられますが、反面 Lambda のマスキング対象が単一のログエントリ(スロークエリログ)になるため、Lambda の実装をよりシンプルにすることができます。また、サブスクリプションフィルタ経由でログマスキング対象の Lambda を呼び出す構成上、一時的なエラーで Lambda の実行に失敗した場合のリトライが難しいのがデメリットではあります。
案2:Firehose で Cloudwatch Logs のログを S3 に出力し、EventBridge 経由でログマスキング用の Lambda をバッチ実行
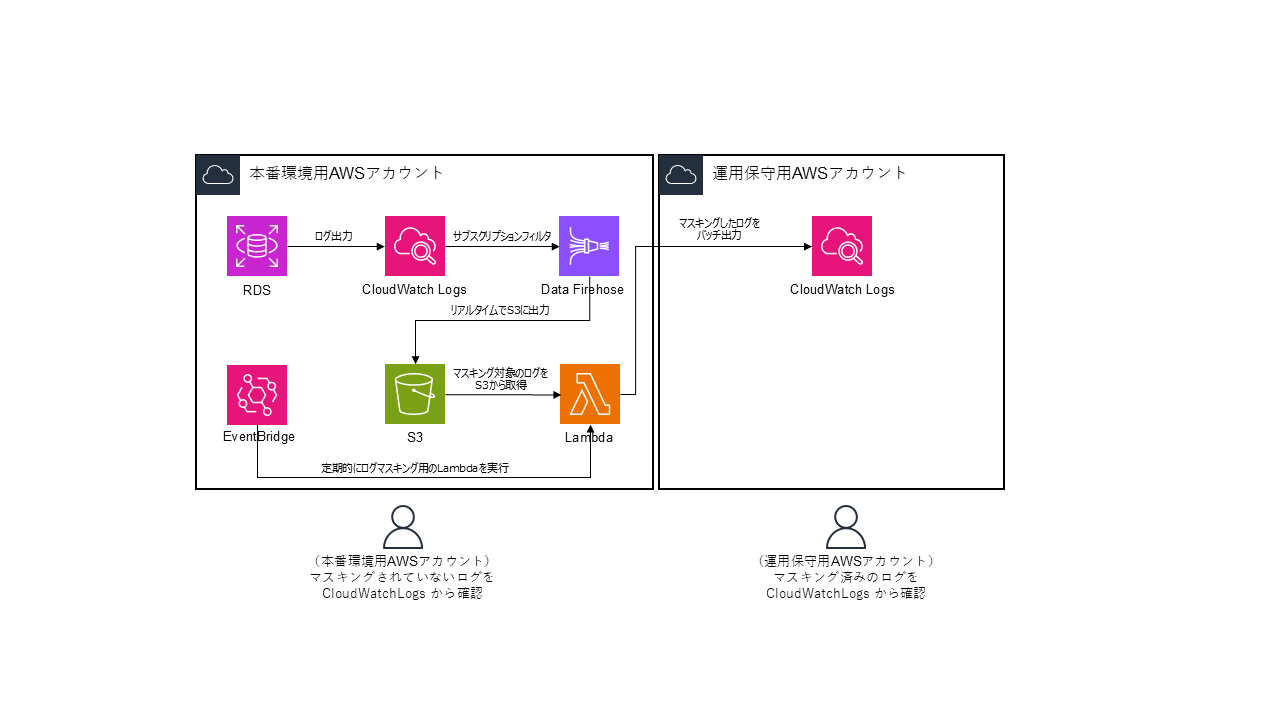
Firehose で Cloudwatch Logs のログを S3 に出力しておき、EventBridge 経由でログマスキング用の Lambda をバッチ実行する構成です。案 1 と比較するとログマスキング処理失敗時のリトライが容易なこと、及びバッチ実行が可能なこと(= Lambda の実行回数を相対的に抑えられる)の 2 点がメリットになります。最も、これらのメリットを得るためには Lambda の実装が相応に複雑になるため、アーキテクチャの複雑性と合わせてトレードオフになる部分だと思います。バッチ実行が必須要件となる場合はこのようなアーキテクチャを採用する必要が出てきますが。
案 1 におけるログマスキング用 Lambda の実装例
最後に、案 1 におけるログマスキング用 Lambda の実装例を紹介します。ただこの実装例はクロスアカウントの Cloudwatch Logs 出力に対応していないので、もし時間があれば改訂するかもしれません。。
import json
import time
import base64
import gzip
import re
import boto3
# ロググループとログストリームの設定(サンプル)
LOG_GROUP_NAME = '/custom/mysql-masked-log'
LOG_STREAM_NAME = 'slowquery'
def lambda_handler(event, context):
# base64でデコード
decoded_data = base64.b64decode(event['awslogs']['data'])
# gzipで解凍
decompressed_data = gzip.decompress(decoded_data)
json_data = json.loads(decompressed_data)
# 文字列リテラル置換用の正規表現
regex_str = r'(["\'])((?:\\.|(?!\1).)*?)(\1)'
# SET timestamp文以降のSQL文を抽出するための正規表現
settimestamp_pattern = r'(?s)(.*?SET\s+timestamp.*?\n)(.*)'
# 数値リテラル置換用関数
def replace_numbers(match):
before_settimestamp = match.group(1) # SET TIMESTAMPまでの部分
after_settimestamp = match.group(2) # SET TIMESTAMP以降の部分
# 数値リテラル(整数・小数)のみを「?」に置換(識別子中の数字は対象外)
masked_numbers = re.sub(r'\b\d+(\.\d+)?\b', '?', after_settimestamp)
return before_settimestamp + masked_numbers
# 全logEventsを処理(複数件対応)
log_events = json_data.get('logEvents', [])
masked_events = []
for log_event in log_events:
cwl_msg = log_event['message']
# 文字列リテラルを「*」に置換
masked_msg = re.sub(regex_str, r'\1*\1', cwl_msg, flags=re.DOTALL)
# SET timestamp文以降の数値リテラルを「?」に置換
# SET timestampパターンにマッチしなかった場合はこのコードでは考慮していない
masked_msg = re.sub(settimestamp_pattern, replace_numbers, masked_msg)
masked_events.append({
'timestamp': log_event.get('timestamp', int(round(time.time() * 1000))),
'message': masked_msg
})
# CWLにマスクしたスロークエリログを出力
log_to_cwl(masked_events)
return {
'statusCode': 200,
'body': json.dumps(f'Processed {len(masked_events)} log events')
}
def log_to_cwl(log_events: list):
"""
指定したロググループとログストリームにテキスト形式でログを出力する
Args:
log_events: {'timestamp': int, 'message': str} のリスト
"""
# CloudWatch Logs クライアントを初期化
logs_client = boto3.client('logs')
# ロググループが存在しない場合は作成
try:
logs_client.create_log_group(logGroupName=LOG_GROUP_NAME)
except logs_client.exceptions.ResourceAlreadyExistsException:
pass
# ログストリームが存在しない場合は作成
try:
logs_client.create_log_stream(
logGroupName=LOG_GROUP_NAME,
logStreamName=LOG_STREAM_NAME
)
except logs_client.exceptions.ResourceAlreadyExistsException:
pass
# ログを出力
logs_client.put_log_events(
logGroupName=LOG_GROUP_NAME,
logStreamName=LOG_STREAM_NAME,
logEvents=log_events
)
先述のログマスキングルールを Python で実装している以上の内容がないのであまり言及することはないのですが、一応ポイントだけ説明して終わりたいと思います。
- サブスクリプションフィルタ経由で Lambda に渡されるログは圧縮されているので、最初にデコード・解凍して取得
- 以下3種類の正規表現パターンを用意
- 文字列リテラルを「*」に置換
- 数値を「?」に置換
- SET timestamp 文以降の部分(=SQL文)と、それより前の部分を別々に抽出
- 取得したスロークエリログの内容から、まず文字列リテラルを「*」に置換した後、SET timestamp 文以降の部分に含まれる数値を「?」に置換
- Cloudwatch Logs 出力時に対象のロググループ/ログストリームが存在しない場合は Lambda 側で作成
まとめ
要件上最終的には無難な方式に落ち着きましたが、そこに至るまで色々と考えさせられたトピックだったなと思います。
Cloudwatch Logs のマネージドデータ識別子などのプリセットに定義されているルールがそのまま使用できれば一番良かったのですが、そのあたりはいわゆる言語の壁を感じたところです。一昔前はそもそも日本語における自然言語処理の観点でこの手の話が色々あったことを思い出すというか、そういうのが生成 AI(LLM)の隆盛で大分取っ払われたと思いきやこういうところにまだ残っているのだなと感じた次第です。別の機会があれば、Bedrock Guardrails も今後是非試してみたいところです。
本記事がどなたかの役に立てば幸いです。
対応時期は Bedrock Guardrails が日本語対応する少し前だったのですが、もし今であればこの機能の使用を前提とした上でもう少し真剣に Bedrock の使用を検討したかもしれません。いずれにせよ非決定的な要素は排除できないので、他のサービス/方式と組み合わせる、Bedrock のマスキング処理対象を限定するなどの検討が必要であろうなとは思います。