

こんにちは、高坂です。
前回の記事では、Prisma Cloudのアラート解決状況をバブルチャートで可視化する試みについてご紹介しました。
バブルチャートでの可視化は、「どの領域で」「どれくらいの量と重要度のアラートが」「どの程度放置されているか」を直感的に把握する上で非常に有効でした。しかし、2次元のグラフであるバブルチャートでは、主に扱える変数が限られるという制約がありました。例えば、「アラートの種類」と「重要度」という2つの軸で状況を見ることはできても、そこに3つ目以上の要因を加えて、より多角的に分析することは困難でした。
そこで今回は、機械学習の手法の一つである「決定木」を使い、アラートの対応条件を分析する方法を試しました。決定木を用いることで、Policy Type(種類)、Policy Severity(重要度)、そしてAlert Time(発生時期)といった複数の変数を同時に扱い、「チームの対応ルールがいつ、どのように変化したか」を解明することを目指します。
決定木とは
決定木は、機械学習のアルゴリズムの一種で、その名の通り、データを分類するためのルールを木のような構造(ツリー構造)で表現する手法です。
詳しい仕組みは以下の記事がわかりやすいです。
決定木を用いる最大のメリットは、その結果の分かりやすさにあります。他の高度な機械学習モデルが、時に「ブラックボックス」として振る舞うことがあるのに対し、決定木は人間が読んで解釈できる「if-then」形式のルールを出力します。
分析の前提と注意点
ただし、この決定木が万能というわけではないことを注釈しておきます。
決定木は、分析対象のデータ、今回の場合だとチームのアラート対応状況に、何らかの一貫したパターンや傾向(=暗黙のルール)が存在することを前提としています。
今回の決定木での分析を行えば、必ずしも明確な結果が保証されるわけではないということはご了承ください。
もし、チームの対応方針が定まっておらず完全に場当たり的であったり、担当者ごとに判断基準が大きく異なっていたりする場合、決定木は明確で解釈しやすいルールを見つけ出せない可能性があります。結果として、非常に複雑で、ビジネス的な意味を見出しにくいツリーが出力されるかもしれません。
可視化の準備:分析シナリオと仮想データの作成
今回の分析では「Policy Type」、「Policy Severity」、「Alert Time」、「Alert Status」のデータを使用していきます。
決定木がどのようなルールを見つけ出すのかを具体的に見ていくために、今回は「とある組織で行われたアラート対応」という仮想的なシナリオを用意し、それに基づいてダミーデータを用意しました。
このシナリオには、明確なアラート対応と「改善前」と「改善後」のフェーズが存在します。
【Phase 1】 対応ルール導入前(〜2025年7月31日まで)
この組織のセキュリティ運用チームは、日々大量に発生するアラートへの対応に追われ、疲弊していました。明確なトリアージ基準はなく、対応は一部のベテラン担当者の経験と勘に頼っている状況でした。
この時期の暗黙的な対応ルールは、非常にシンプルでした。
Criticalアラートだけは絶対に対応する: これだけは経営層からも厳しく言われていたため、何があっても必ず解決していました。- それ以外(
High以下)は、ほぼ手付かず: チームのリソースが足りず、ほとんどのアラートは未解決(Open)のまま放置されていました。
【Phase 2】 新ルール導入の時代(2025年8月1日以降)
2025年8月1日、チームに経験豊富な新しいマネージャーが着任し、アラート対応プロセスを抜本的に見直しました。アラートの重要度とタイプに基づいた、明確なトリアージルールを導入したのです。
新しいルールは以下の通りです。
CriticalとHighは、最優先で必ず解決する。MediumとLowは、タイプによって対応を分ける。configタイプ: 新しく導入された自動修復スクリプトの対象となり、ほぼ自動で解決されるようになりました。- それ以外のタイプ(
iam,network,anomaly): 手動での調査が必要なため優先度が低く、多くが未解決のままとなりました。
データ構成のマトリクス
上記のシナリオを、ダミーデータ生成のための具体的な構成表にまとめます。
| 期間 | 条件 | Policy Severity |
Policy Type |
Alert Status の確率分布 |
|---|---|---|---|---|
| Phase 1(〜2025/7/31) | Severityがcritical |
critical |
すべて | resolved: 95%
|
Severityがcriticalでない |
high, medium, low, informational |
すべて | open: 90%
|
|
| Phase 2(2025/8/1〜) | Severityがhigh以上 |
critical, high |
すべて | resolved: 98%
|
Severityがmedium以下 |
medium, low, informational |
config |
resolved: 90%
|
|
Severityがmedium以下 |
medium, low, informational |
iam, network, anomaly |
open: 85%
|
Pythonによる実装
今回の可視化分析には、前回同様Pythonを使用しました。
主な利用ライブラリは、データの加工にはpandas、モデルの学習にはscikit-learnを利用しました。
処理の概要
ここではコードの全ての詳細には触れませんが、実装の主要なステップと、特に工夫したポイントをご紹介します。
Step1: データの前処理
まず、pandasを使って生のアラートデータをモデルが学習できる形式に変換します。 今回の分析の鍵であるAlert Timeは、そのままでは機械学習モデルが扱えません。そこで、各アラートの発生日時を、分析期間の開始日からの経過日数(days_since_start)という数値に変換しました。これにより、決定木は「開始から何日目以降」といった時間的な分岐点を見つけ出せるようになります。 また、Policy TypeやPolicy Severityといったカテゴリカルなデータも、モデルが理解できる数値形式(ダミー変数)に変換しています。
Step2: モデルの学習
次に、scikit-learnのDecisionTreeClassifierを使って、準備したデータから決定木モデルを学習させます。 この際、前章で触れたポリシーの重要度を分析に反映させるために、重要度ごとに重みづけを実装しています。fitメソッドを呼び出す際に、criticalやhighのアラートに計算した「重み」を渡すことで、実際のセキュリティー運用を考慮した分析を目指しています。
Step3: 2つのアウトプット生成
学習が完了したら、その結果出力します。
今回の実装では通常の決定木とは別で、決定木の結果を生成AIに解釈してもらうためのルールテキストをJSONで生成します。
決定木の分析もAIにさせてみようという試みで、決定木の生成されたテキストを実際に生成AIに入力してみるところまでしてみようと思います。
結果の表示
以下結果です。
決定木
前述のダミーデータで決定木をさせると、以下の結果が得られました。
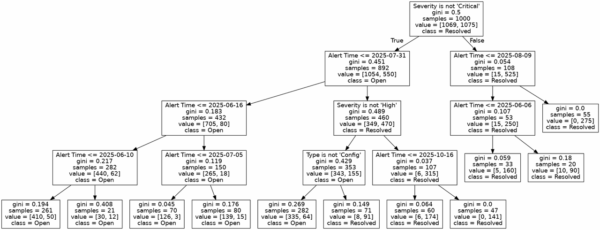
画像なので文字が見にくくて申し訳ないのですが、見方はざっくり以下です。
- 分岐条件: ノードの一番上に書かれているテキスト(例:Severity is not ‘Critical’)は、データを分割するための質問(分岐条件)です。
- 分岐の方向: この条件を満たす場合(真 / True)は左下のノードへ、満たさない場合(偽 / False)は右下のノードへとデータが振り分けられます。
samples: そのノードに到達したアラートの総数を示しています。value:samplesの内訳です。class_namesが['Open', 'Resolved']の順であるため、例えばvalue = [315, 35]は、Openが315件、Resolvedが35件含まれていることを意味します。class: そのノードで最も多数派となったクラスを示します。つまり、そのノードに分類されたアラートが、最終的にどちらに予測されるかを表しています。ツリーの末端(葉ノード)では、これが最終的な結論となります。
以上を踏まえると、決定木の結果はざっくり以下の様に分析できます。
まず最初に、ポリシー重要度が”Critical”(Severity is not ‘Critical’がFalse)だとほとんどのアラートが”Resolved”となっていることがわかります。
ポリシー重要度が”Critical”じゃないアラートについては、次にAlert Timeで条件分岐が起こっています。
“Critical”以外のアラートでは、2025/7/31以前は”Open”,以降は”Resolved”となっております。
さらに2025/7/31のアラートについては、”High”アラートは”Resolved”で、”High”(とCritical)以外のアラートについては”Config”タイプのものは”Resolved”となっております。
どうでしょう、最初にご紹介したシナリオを再現できているのではないでしょうか。
ルールテキスト
ルールテキストは以下の様に出力されます。
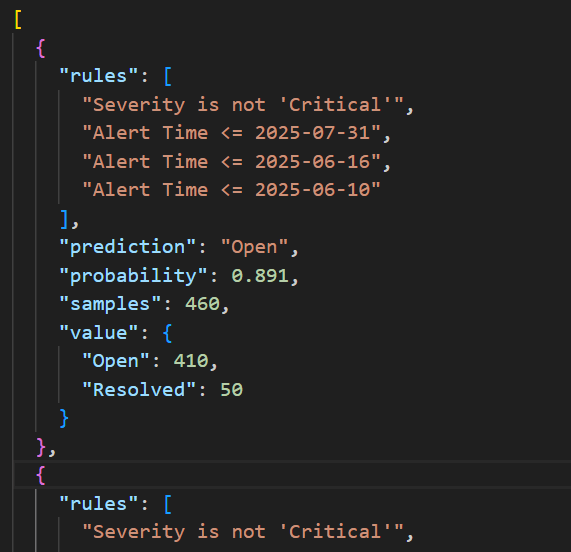
これをChatGPTのような生成AIに入力し、「結果を要約して」とお願いすると以下の結果を得ました。
以下は、提示された決定木の分析結果の要約です。
1. 「Severity(重大度)」で最初に分岐
「Critical(重大)」かどうかで大きく傾向が分かれる。2. Severityが「Critical」でない場合
【2025-07-31以前のアラート】
ほとんどが「Open」状態(解決されていない)。
「Alert Time」が細かく過去日付に分岐されるが、どの分岐も「Open」割合が高い(約70~98%)。
【2025-07-31以降のアラート】
「Severity」が「High」でない(それ以外):
「Type」が「Config」かどうかで差が出る。
「Config」タイプは、ほぼ「Resolved」。
それ以外は「Open」割合が高い。
「Severity」が「High」:
「Alert Time(警告発生日)」が新しいほど「Resolved」(解決済み)率が極めて高い(約97~100%)。3. Severityが「Critical」の場合
時期に関係なく「Resolved」が多い傾向。
2025-08-09以降は100%解決済み。
それより前でも90%以上が解決済み。
要点まとめ
Severityが高い(Critical / High)、かつアラートの発生日が新しければ「Resolved」(解決済み)が多い。
Severityが低く、発生日が古いほど「Open」(未解決)が多い。
Configタイプは比較的解決されやすい。
アラート発生直後や重大度の高いものは、解決対応が迅速に実施されている傾向。
この結果から、「重大なアラートほど早急に解決されるが、古い・低重大度のアラートは未解決が多い」
と言えるでしょう。運用上は、低重大度のアラートや古い未解決案件のフォローアップが課題となりそうです。
まとめ
今回は機械学習の手法の一つである「決定木」を使い、アラートの対応条件を分析する方法を試しました。
決定木分析の結果、「Severity(重大度)」「Type(アラート種別)」「Alert Time(発生日)」という三つの変数が分析結果に現れました。前回作成したバブルチャートでは主に一度に二要素までの関係しか視覚化できませんでしたが、決定木による分析により、3変数以上の要因の組み合わせの分析が可能になり、データの奥行きや傾向把握の可能性が広がったかと思います。
また、今回は決定木分析の結果をテキストに出力することで、結果の解釈と要約の部分で生成AIの活用の可能性を示せたかと思います。
今回紹介した手法は一例であり、データの性質や分析目的によっては、さらに多様な可視化や分析手法が存在します。今後もPrisma Cloudから取得できるデータのさらなる活用方法について、試行錯誤し結果を発信していければと考えております。
また、当社では、Prisma Cloudを利用して複数クラウド環境の設定状況を自動でチェックし、設定ミスやコンプライアンス違反、異常行動などのリスクを診断するCSPMソリューションを販売しております。ご興味のある方はお気軽にお問い合わせください。リンクはこちら↓
