

 本記事は 夏休みクラウド自由研究2025 8/17付の記事です。 本記事は 夏休みクラウド自由研究2025 8/17付の記事です。 |
「AWSの最新情報を効率的にキャッチアップしたい…」
「毎日Qiitaをチェックするのは大変だけど、重要なトレンドは見逃したくない…」
エンジニアにとって、最新技術の動向を追い続けることは非常に重要!
ですが、忙しい日々の中で効率的に情報収集するのは難しい課題ですよね。
この記事では、そんな悩みを解決するために、AWSのサービスを組み合わせて、Qiitaに投稿されたAWS関連の最新記事から「おすすめトピックス」を自動で抽出し、毎日メールで通知してくれるシステムを構築する方法を、ステップ・バイ・ステップで解説します!
サーバー管理は一切不要で、一度作ればあとは自動であなたのために働いてくれる便利なシステムです。AWSの学習にもぴったりのテーマなので、ぜひ一緒に作ってみましょう!
この記事で構築するもの
完成するシステムの全体像は以下の通りです。
- 毎日決まった時刻に…EventBridgeがシステムを起動します。
- QiitaからAWS記事を自動収集…LambdaがQiita APIを叩いて最新記事を取得し、S3に保存します。
- AIが記事を分析…S3への保存をトリガーに別のLambdaが起動し、Amazon Comprehendが記事の内容を分析して、頻出する技術キーワード(トピックス)を抽出します。
- 結果をメールで通知…抽出したトピックスと記事リストをまとめて、SNSがあなたのメールアドレスに送信します。
準備するもの
構築を始める前に、以下の3つをご準備忘れずに!
- AWSアカウント: 無料利用枠の範囲内でほとんど試せます。
- IAMユーザー: セキュリティのため、管理者権限を持つIAMユーザーで作業しましょう。
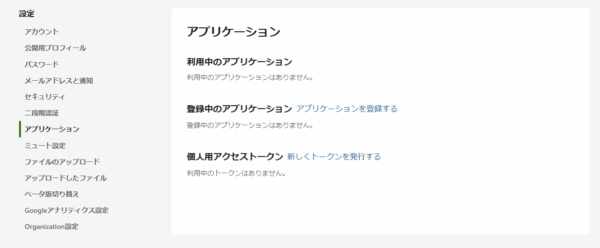
- Qiitaのアクセストークン: Qiita APIを利用するために必要です。こちらの「個人用アクセストークン」から
read_qiitaスコープで発行してください。発行したトークンは後で使いますので、メモしておきましょう。
準備はOKですか?それでは、さっそく構築を始めましょう!
Step 1. データの保管庫!S3バケットを作成しよう
まずは、取得したQiitaの記事データを保存しておくための場所(ストレージ)を用意します。AWSでは、このようなオブジェクトストレージサービスとしてAmazon S3を利用します。
- AWSマネジメントコンソールで「S3」を検索し、ダッシュボードを開きます。
- 「バケットを作成」をクリック。
- バケット名に世界で一意な名前を付けます(例:
qiita-aws-articles-自分の名前-日付)。 - リージョンは、基本的にすべてのサービスで同じ「アジアパシフィック (東京)
ap-northeast-1」に統一しましょう。 - あとはデフォルト設定のまま「バケットを作成」すれば完了です。ここまでは簡単ですかね…!

Step 3 通知システムの中核!SNSトピックを作成
次に、分析結果をメールで送信するための通知システムをAmazon SNSで構築していきます。
- コンソールで「SNS」を検索し、ダッシュボードへ。
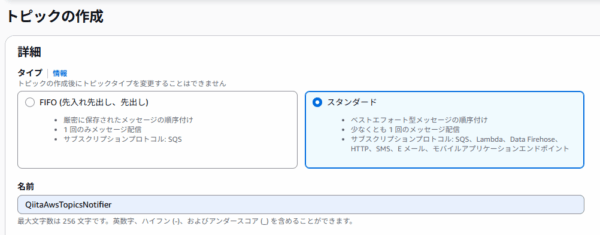
- 左メニューの「トピック」から「トピックの作成」をクリック。
- タイプは「スタンダード」、名前は「
QiitaAwsTopicsNotifier」など分かりやすいものを設定します。
- トピック作成後、「サブスクリプションの作成」ボタンを押します。
- プロトコルで「Eメール」を選び、エンドポイントに通知を受け取りたいメールアドレスを入力します。
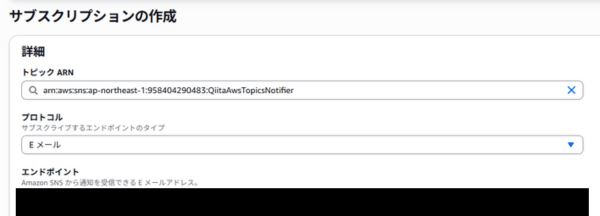
- 「サブスクリプションの作成」をクリックすると、入力したアドレスに確認メールが届きます。メール内の「Confirm subscription」リンクをクリックして承認を忘れずに行いましょう。
Step 3. IAMロールを作成
AWSのサービス同士が連携するには、「IAMロール」という権限設定が必要です。今回は2つのLambda関数を作るので、それぞれに必要な権限を持ったロールを2つ作成します。
- コンソールで「IAM」を検索し、ダッシュボードへ。
- 左メニューの「ロール」から「ロールを作成」をクリックします。
- 信頼されたエンティティタイプは「AWSのサービス」、ユースケースは「Lambda」を選択します。
記事取得用ロール (QiitaArticleGetRole)
- 許可ポリシー:
AWSLambdaBasicExecutionRole(Lambdaの基本的な実行ログを書き込む権限)AmazonS3FullAccess(S3にファイルを書き込む権限)
→(慣れてきたら、特定のバケットにのみ書き込めるように権限を絞ると、よりセキュアになります)
トピック抽出用ロール (QiitaTopicExtractRole)
- 許可ポリシー:
AWSLambdaBasicExecutionRoleAmazonS3FullAccess(S3からファイルを読み込む権限)ComprehendReadOnly(Amazon Comprehendでテキスト分析を行う権限)AmazonSNSFullAccess(SNSで通知を送信する権限)
それぞれポリシーを選択したら、分かりやすいロール名を付けて作成してください。
Step 4. 収集用Lambda関数の作成
いよいよメイン機能の実装です。まずはQiitaから記事データを取得するLambda関数を作成します。
- コンソールで「Lambda」を検索し、「関数の作成」をクリック。
- 以下の設定で関数を作成します。
- オプション: 「一から作成」
- 関数名:
getQiitaArticles - ランタイム: 「Python 3.13」以降
- 実行ロール: 「既存のロールを使用する」を選び、先ほど作成した
QiitaArticleGetRoleを選択。
- 関数が作成されたら、「コードソース」エディタに以下のPythonコードを貼り付けます。
import os import json import urllib.request import urllib.parse from datetime import datetime import boto3 # 環境変数から設定値を取得 QIITA_API_TOKEN = os.environ['QIITA_API_TOKEN'] S3_BUCKET_NAME = os.environ['S3_BUCKET_NAME'] s3 = boto3.client('s3') def lambda_handler(event, context): print("Fetching articles from Qiita using urllib...") headers = {'Authorization': f'Bearer {QIITA_API_TOKEN}'} # "AWS"タグがついており、LGTMが10以上の記事を50件取得 (取得件数を増やして分析精度を向上) query_params = {'page': '1', 'per_page': '50', 'query': 'tag:AWS stocks:>10'} # URLエンコード encoded_params = urllib.parse.urlencode(query_params) url = f'https://qiita.com/api/v2/items?{encoded_params}' req = urllib.request.Request(url, headers=headers, method='GET') try: with urllib.request.urlopen(req) as res: # ステータスコードのチェック if res.status >= 400: print(f"Error: Received status code {res.status}") raise urllib.error.HTTPError(res.url, res.status, res.reason, res.headers, res.fp) response_body = res.read().decode('utf-8') articles = json.loads(response_body) if not articles: print("No articles found.") return {'statusCode': 200, 'body': 'No articles found.'} today = datetime.utcnow().strftime('%Y-%m-%d') file_name = f'articles/{today}.json' s3.put_object( Bucket=S3_BUCKET_NAME, Key=file_name, Body=json.dumps(articles, ensure_ascii=False, indent=2), ContentType='application/json' ) print(f"Successfully saved {len(articles)} articles to s3://{S3_BUCKET_NAME}/{file_name}") return {'statusCode': 200, 'body': f'Successfully saved {len(articles)} articles.'} except urllib.error.HTTPError as e: print(f"Error fetching from Qiita API: {e}") error_content = e.read().decode('utf-8') print(f"Error details: {error_content}") raise e - 次に、「設定」タブ -> 「環境変数」で、以下の2つの変数を設定しまておきましょう。
- キー:
QIITA_API_TOKEN, 値: (準備したQiitaアクセストークン) - キー:
S3_BUCKET_NAME, 値: (Step 1で作成したS3バケット名)
- キー:
- 最後に、タイムアウト対策として「設定」タブ -> 「一般設定」でタイムアウトを1分に延長しておきましょう。
- 忘れずに「Deploy」ボタンをクリックして、変更を保存します。
Step 5: AIで分析&通知! トピック抽出用Lambda関数の作成
次に、S3に保存された記事データをAIで分析し、結果をSNSで通知する2つ目のLambda関数を作成します。
- 先ほどと同様に、新しいLambda関数を作成します。
- 関数名:
extractTopicsAndNotify - ランタイム: 「Python 3.13」以降
- 実行ロール:
QiitaTopicExtractRoleを選択
- 関数名:
- 「コードソース」に以下のコードを貼り付けます。Amazon Comprehendを呼び出してキーフレーズを抽出し、結果を整形してSNSに送信する処理です。
※頻出ワードに接続詞等を含まないようにするために少々汚いコードを書いています…。改善しますね…。import os import boto3 import json import re from collections import Counter # 環境変数から設定値を取得 SNS_TOPIC_ARN = os.environ['SNS_TOPIC_ARN'] s3 = boto3.client('s3') comprehend = boto3.client('comprehend', region_name='ap-northeast-1') sns = boto3.client('sns') # 除外する一般的な単語(ストップワード)のリスト STOP_WORDS = set([ "これ", "それ", "あれ", "この", "その", "あの", "ここ", "そこ", "あそこ", "こちら", "ため", "よう", "こと", "もの", "とき", "ところ", "うち", "ほう", "わけ", "はず", "さん", "くん", "ちゃん", "さま", "たち", "など", "ほか", "どう", "なに", "なぜ", "いつ", "どこ", "だれ", "どれ", "ほう", "以上", "以下", "未満", "以前", "以後", "今回", "次回", "本日", "明日", "昨日", "今日", "これら", "すべて", "一部", "全体", "一つ", "二つ", "三つ", "最初", "最後", "記事", "方法", "手順", "設定", "確認", "問題", "解決", "方法", "注意", "事項", "内容", "部分", "情報", "利用", "作成", "実行", "結果", "必要", "場合", "影響", "機能", "処理", "自分", "皆さん", "こんにちは" ]) def clean_text_for_summary(text): """概要用にテキストからMarkdownや改行、URLなどを除去する""" text = re.sub(r'https?://\S+', '', text) # URLを除去 text = re.sub(r'!\[.*?\]\(.*?\)', '', text) # Markdown画像を除去 text = re.sub(r'#+\s?', '', text) # 見出しを除去 text = re.sub(r'[`\*_]', '', text) # Markdown装飾を除去 text = text.replace('\n', ' ').replace('\r', '') # 改行をスペースに置換 return text.strip() def is_valid_topic(phrase): """トピックとして相応しいか判定する""" if len(phrase) <= 2 and not re.search(r'^[A-Z0-9]+$', phrase): # 2文字以下は基本除外 (S3などの大文字略語は許可) return False if phrase in STOP_WORDS: # ストップワードに含まれていたら除外 return False if re.search(r'[!-/:-@[-`{-~]', phrase): # 記号が多く含まれるものは除外 return False if phrase.isdigit(): # 数字のみは除外 return False return True def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] print(f"Processing file: s3://{bucket}/{key}") response = s3.get_object(Bucket=bucket, Key=key) articles = json.loads(response['Body'].read().decode('utf-8')) all_phrases = [] for article in articles: text_to_analyze = (article['title'] + " " + article['body'])[:4900] try: comp_response = comprehend.detect_key_phrases(Text=text_to_analyze, LanguageCode='ja') phrases = [p['Text'] for p in comp_response['KeyPhrases']] all_phrases.extend(phrases) except Exception as e: print(f"Error analyzing article {article['id']}: {e}") continue # トピックをフィルタリングして頻度順に並べる topic_counts = Counter(p for p in all_phrases if is_valid_topic(p)) hot_topics = [topic for topic, count in topic_counts.most_common(20)] # 上位20件 # おすすめ記事をLGTM数でソートして上位3件選出 sorted_articles = sorted(articles, key=lambda x: x.get('likes_count', 0), reverse=True) recommended_articles = sorted_articles[:3] # --- メッセージ作成 --- subject = "【自動通知】本日のQiita AWSおすすめトピックス" # 1. ホットトピックス hot_topics_text = "特に注目されたトピックスはありませんでした。" if hot_topics: hot_topics_text = ", ".join(hot_topics) # 2. おすすめ記事 recommended_articles_text = "" for i, article in enumerate(recommended_articles): summary = clean_text_for_summary(article['body'])[:120] + "..." recommended_articles_text += f"{i+1}. {article['title']}\n" recommended_articles_text += f"概要: {summary}\n" recommended_articles_text += f"URL: {article['url']}\n\n" # 3. 全記事リスト all_articles_text = "\n\n".join([f"- {a['title']}\n {a['url']}" for a in sorted_articles]) # メッセージを結合 message = ( "本日注目されたAWS関連のトピックスと、おすすめ記事です。\n\n" "------------------------------------\n" "▼ 今日のホットトピックス\n" f"{hot_topics_text}\n\n" "------------------------------------\n" "▼ 本日のおすすめ記事\n\n" f"{recommended_articles_text}" "------------------------------------\n" "▼ 新着記事一覧\n" f"{all_articles_text}" ) print("Publishing to SNS topic...") sns.publish(TopicArn=SNS_TOPIC_ARN, Message=message, Subject=subject) return {'statusCode': 200, 'body': 'Successfully extracted topics and notified.'}このLambda関数は、S3にファイルが置かれたら自動で動いてほしいので、トリガーを設定します。
- 関数デザイナー画面の「トリガーを追加」をクリック。
- ソースに「S3」を選択。
- バケットにStep 1で作成したバケットを指定。
- プレフィックスに
articles/と入力し、このフォルダ内でのイベントのみを検知するようにします。 - 警告を確認するチェックを入れて「追加」。
- こちらも環境変数を設定します。「設定」タブ -> 「環境変数」で以下を追加します。
- キー:
SNS_TOPIC_ARN, 値: (Step 2で作成したSNSトピックのARN)
- キー:
- タイムアウトを3分程度に延長し、「Deploy」で保存します。
Step 6. EventBridgeで定期実行を設定
最後の仕上げです! getQiitaArticles 関数を毎日自動で実行するためのスケジュールを設定します。
- コンソールで「EventBridge」を検索し、ダッシュボードへ。
- 「ルールを作成」をクリック。
- 名前に「
RunQiitaArticleGetterDaily」などを入力。 - ルールタイプで「スケジュール」を選択。
- スケジュールパターンで、実行頻度を設定します。例えば、毎日朝9時(JST)に実行したい場合は、Cron式
0 0 * * ? *を入力します (EventBridgeのスケジュールはUTC基準なので、日本時間の9時はUTCの0時です)。 - ターゲットとして「Lambda 関数」を選び、関数に
getQiitaArticlesを指定します。 - あとはデフォルトのまま進み、「ルールを作成」すれば完了です!
Step7. 動作確認
お疲れ様でした!これでシステムは完成です。
getQiitaArticles 関数のテスト機能を使って手動で一度実行してみましょう。成功すれば、S3にファイルが作成され、それをトリガーに extractTopicsAndNotify が動き、数分後にあなたの元へ分析結果のメールが届くはずです!
メールが届けば大成功!あとは設定した時刻になれば、毎日自動で情報が届きます。
発展:こんな使い方もできるかも…?
このシステムは、さらにカスタマイズすることも可能です。
- Slackに通知する: SNSの代わりにLambdaから直接Slack APIを叩くように変更。
- トピックをDBに保存: DynamoDBにトピックを保存し、長期的なトレンドを分析する。
- Webページで結果を公開: S3の静的ウェブサイトホスティング機能を使って、結果をWebページとして公開する。
- 分析精度を向上: LGTM数や記事の長さを考慮してトピックのスコア付けを行う。
まとめ
今回は、AWSのサーバーレスサービスを組み合わせ、Qiitaの技術トレンドを自動で収集・分析・通知するシステムを構築しました。
このプロジェクトを通して、以下のAWSサービスの基本的な連携方法を学ぶことができたのではないでしょうか…?
サーバーレスアーキテクチャは、このような「ちょっとした自動化」や「データ処理パイプライン」の構築に非常に便利です!ぜひ、これを機にあなただけの便利な自動化システム作りに挑戦してみてください!