
こんにちは!SCSKの野口です。
前回の記事では、RAGの全体像(Indexing / Retrieval / Augmentation / Generation)と、「LLMの性能そのものより、前段の設計で品質が決まる」ことを整理しました。

今回はシリーズ1(RAGの基本要素)の第2回として、「チャンキング(チャンク化)」を扱います。
早速ですが皆さんに質問です。
「検索結果は返ってくるのに、回答が噛み合わない/断片的になる」こと、ありませんか?
現場でよく起きるこの状況、Retrieval(検索)の問題に見えますが、実はIndexing時に“根拠をどう切り出して保存したか”が原因になっているケースが少なくありません。
というのも、RAGは「検索したチャンク(断片)」をコンテキストとしてLLMに渡す仕組みなので、そもそもチャンクの単位が悪ければ、検索が当たっていても“回答に必要な情報が揃わない”状態になります。
RAGからの情報検索自体は成功しているのに取得した情報の品質が低い——これはRAGの“あるある”です。
そこで本記事では、まずRAG全体像の中でチャンキングがどこに位置し、どのような役割を果たしているのかを図で押さえたうえで、サイズ・オーバーラップ・戦略の選び方、そして簡単な検証デモまで一気に整理します。
本記事で扱う範囲
- チャンキングの位置づけ:RAGのIndexing工程の中で、チャンキングが検索品質にどう効くか
- 設計パラメータと戦略:chunk size / overlap の勘所と、代表的なチャンキング戦略の使い分け
- 検証の進め方:LangChain + Vertex AI Embeddings(Google)で、戦略差を“取得チャンク”として見える化するデモ
※評価(Ragasなどの定量評価)は重要なので触れますが、詳細は次回(評価編)で扱います。
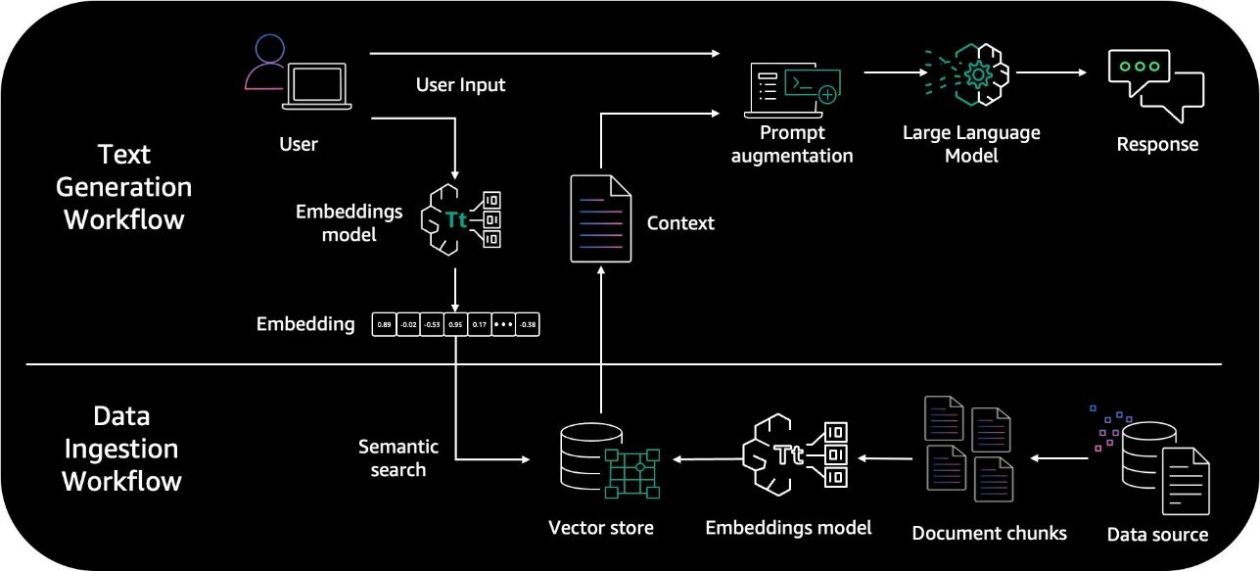
RAGのIndexing工程
チャンキングは、RAGのIndexing(インデックス作成)工程の中核です。ここでの設計が、後続のRetrieval品質に直結します。
Indexingの基本フロー
- 文書を取り込む(Parsing / 整形)
- 文書をチャンクに分割する(Chunking)
- チャンクを埋め込みに変換する(Embeddings)
- ベクトルDB(または検索基盤)に保存する(Indexing)
基本フローに関しては、私が発表した下記資料「RAGの全体像とチャンキングの位置付け」でまとめているので一読ください。
※Parsing部分については表現を省いた図を載せています。
2026年1月 豊洲会(発表資料)
また、下記AWSブログでもRAGの流れが記載されています。
チャンキング(チャンク化)とは
チャンキング(Chunking)とは、長いドキュメントを検索と生成に扱いやすい単位へ分割し、各チャンクを埋め込み(Embedding)に変換して保存する工程です。
ポイントは、チャンキングが単なる「文章を切る」作業ではなく、検索精度・文脈保持・コスト・レイテンシを制御する重要な作業だという点です。極端に言えば、LLMがどれだけ高性能でも、“拾う根拠がズレていれば、ズレたまま賢く答える”だけです。
先程の発表資料内でも触れていますが、「不適切なチャンクは、ゴミを入れてゴミを出す(Garbage In, Gargabe Out)」と言い換えることができます。
まず押さえる:サイズとオーバーラップ(最重要パラメータ)
チャンキング設計の基本は、chunk size(サイズ)とchunk overlap(オーバーラップ)です。ここを外すと、後段の「戦略(splitter)の種類」をどれだけ工夫しても、Retrieval品質が安定しません。
用語整理:chunk / chunk size / chunk overlapについて
ここでいう chunk は「検索・生成で扱うために分割したテキストのひとかたまり」を指します。
そのひとかたまりの上限長が chunk size、隣り合うチャンク同士で重複させる長さが chunk overlap です。
- chunk size:1チャンクに含めるテキスト量(上限)。単位はトークン(推奨)または文字数。
- chunk overlap:隣接チャンク間で重複させる量。境界で情報が欠けるのを緩和する役割を持つ。
図解:size=500, overlap=100 のとき何が起きる?
例えば chunk size = 500、overlap = 100 なら、
1つ目のチャンクが 0〜500、2つ目は 400〜900 のように 100分だけ重なります。
(※開始位置は (n-1) × (size - overlap) のスライディングウィンドウになります)
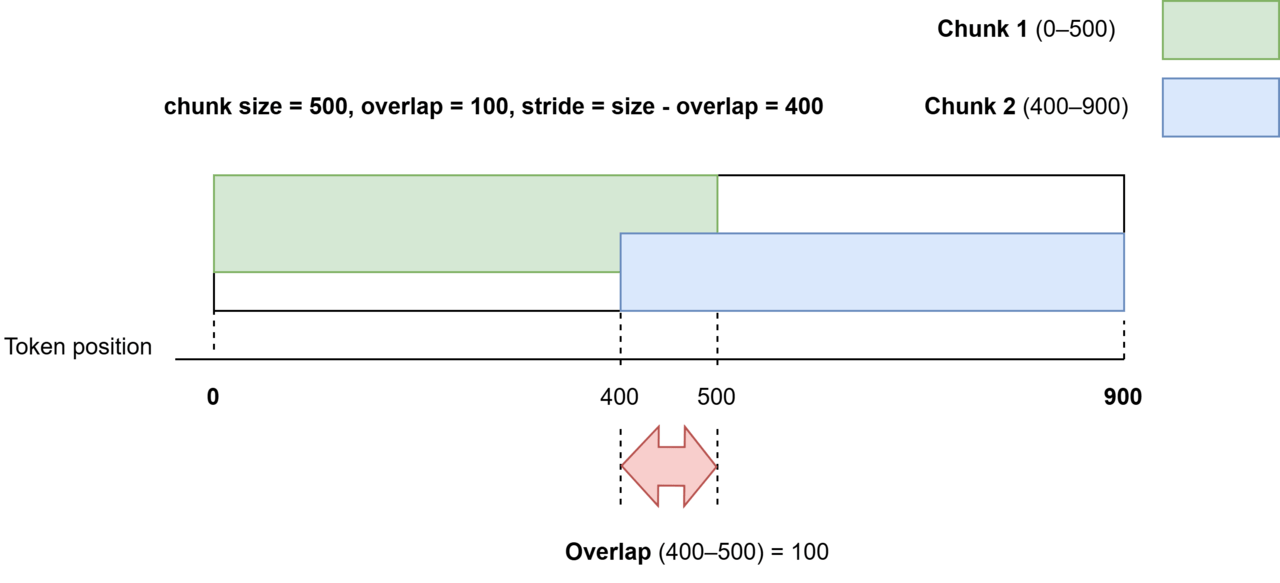
図 例)サイズとオーバーラップの関係
精度・文脈・コストへの影響について
chunk size と overlap は、検索精度(ノイズ)、文脈保持(断片化耐性)、コスト/レイテンシに影響を与えます。
ここでは「回答がどう崩れているか」の感覚が掴めるように、ポイントだけ整理します。
1) chunk size が影響を与えるもの(ノイズ ↔ 文脈)
- 大きすぎる:1チャンクに関係ない情報が混ざりやすく、検索でノイズが乗る(ベクトルが“平均化”され、クエリとの整合が甘くなる)。生成側も入力トークンが増え、コスト・レイテンシが増える。
- 小さすぎる:条件・例外・参照(主語、前提)がチャンク境界で別れやすくなり、回答が断片的になりやすい。チャンク数が増えるため、検索(Top-k / rerank)負荷も増えやすい。
2) chunk overlap が影響を与えるもの(境界欠落 ↔ 冗長)
固定長分割では、文の途中や「ただし〜」などの条件節が境界で切れやすく、取得はできても「例外条件が落ちる」「主語が消える」といった形で回答が崩れることがあります。
overlap はこの“境界欠落”を緩和します。
- overlap を増やす:断片化に強くなる(必要な根拠が同じチャンクに残りやすい)。
- overlap を増やしすぎる:同じ内容が複数チャンクに入って検索結果が冗長になり、コストも増える(インデックスサイズ・取得チャンク重複)。
3) chunk size / overlapの調整
まず 固定長 + overlap をベースラインにして、回答がどう崩れているか(断片化/ノイズ混入など)を見ながら調整するのが堅実です。
- 回答が断片的 → overlap を増やす、または size を少し大きくする
- 関係ない文が混ざる(ノイズ) → overlap を減らす、size を小さくする、必要なら構造認識・メタデータを活用する
目安としては、まず overlap を chunk size の 10〜20% 程度から始めると、境界問題を抑えつつコストもそこまで増えることはないかと思います。
トークン基準で考えることの重要性
チャンクサイズを文字数で切ると、モデル側のトークナイザ差分で想定以上にトークンが膨らむことがあります。
そのため、文字数を基準にチャンクサイズを選択するのではなく、「トークンベースでサイズを管理」する事が重要となります(特に日本語は差が出やすい)。
下記の公式情報は参考になるので、ご確認ください。
・Azure AI Search:チャンキングの考え方/推奨の出発点(例:512 tokens + 25% overlap)

・Google Cloud:取り込み時の chunk_size / chunk_overlap、レイアウト解析の統合(RAG Engine)

・Weaviate:chunkingのベースラインと発展手法の整理(overlap目安含む)
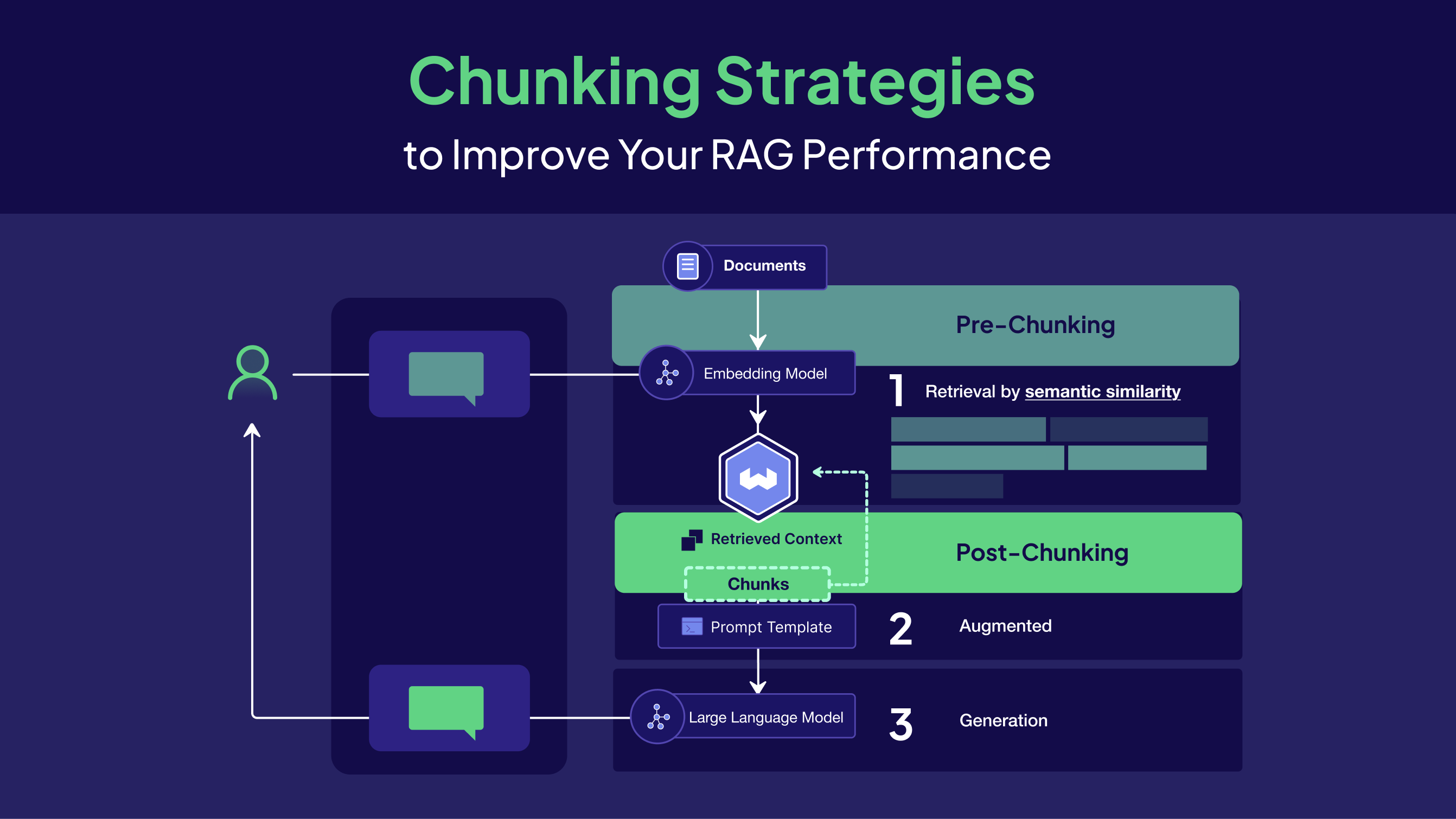
チャンキング戦略の全体像:代表6パターン(+発展2)
ここからは、チャンキング戦略の手法を整理します。
チャンキング戦略を選択する際は、いきなり高度な戦略に飛ぶのではなく、
- 固定長 or 再帰でベースラインを作る
- 回答の崩れ方(断片化/ノイズ/表崩れ)から原因を推定する
- 必要なところだけチャンキング戦略変更(構造認識/セマンティック/階層/コンテキスト付与)
の順が、検証コストが小さくなるかと思います。
それぞれのチャンキング戦略の説明とLangChainでの実装コードについて簡単に説明します。
(1) 固定長(トークン)+オーバーラップ
- 位置づけ:最初に作るべきベースライン。チューニング(size/overlap)とログ観察がしやすく、改善サイクルの起点になります。
- 強み:実装が簡単。速度・コスト見積もりがしやすい。比較実験(A/B)で差分を取りやすい。
- 弱み:文の途中で切れたり、表・コード・章節構造を無視して分割しがち(=構造がある文書では品質が低くなりやすい)。
LangChain最小実装
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_sise=512,
chunk_overlap=128,
separator="",
keep_separator=False,
)
chunks = splitter.split_text(text) # text: str
(2) 再帰的分割(段落→改行→空白…の優先順位)
- 仕組み:自然な区切り(段落・改行)を優先しつつ上限サイズに収める。
- 強み:固定長より「読みやすいチャンク」になりやすく、検索が安定しやすい。
- 弱み:表やコードなど“構造を持つデータ”では崩れることがある(前処理が重要)。
- 向く文書:議事録、ブログ、一般ドキュメント、自然言語中心の資料。
LangChain最小実装
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_sise=1200, chunk_overlap=100)
chunks = splitter.split_text(text)
# 必要であれば、下記のように「優先する区切り」を明示する
splitter = RecursiveCharacterTextSplitter(
chunk_size=1200,
chunk_overlap=100,
separators=["\n\n", "\n", "。", " ", ""]
)
chunks = splitter.split_text(text)
(3) 構造認識(見出し・表・リスト・レイアウト)
- 仕組み:見出し階層、箇条書き、表、HTMLタグ、PDFレイアウト等を解析して「論理単位」で分割。
- 強み:仕様書やPDFで起こりがちな「表崩れ」「章節の断絶」を抑えやすい。メタデータ(章タイトルなど)も付けやすい。
- 弱み:前処理(パース)の品質がボトルネック。導入コストも上がりやすい。
- 向く文書:Markdown/HTML/PDF/Office文書(特に表が多い資料)。
LangChain最小実装
「構造認識」は入力形式で実装が分かれます。
ここでは、HTML / Markdownの見出しをメタデータ化して分割する例を示します。
HTML(タグ単位で分割)
from langchain_text_splitters import HTMLHeaderTextSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3")
]
splitter = HTMLHeaderTextSplitter(headers_to_split_on)
docs = splitter.split_text(html_text) # html_text: str
Markdown(見出しで分割)
from langchain_text_splitters import MarkdownHeaderTextSplitter headers_to_split_on = [ ("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3") ] splitter = MarkdownHeaderTextSplitter(headers_to_split_on=[("#","h1"), ("##","h2"), ("###","h3")]) docs = splitter.split_text(markdown_text)
(4) セマンティック分割(意味の変わり目で切る)
- 仕組み:隣接文の埋め込み類似度が落ちる地点をbreakpointとして分割。
- 強み:トピック境界を捉えやすく、長文・論文で“概念の連続性”を保ちやすい。
- 弱み:前処理コストが増える。閾値(どこで切るか)のチューニングが必要。
- 向く文書:長文記事、論文、説明書(話題が頻繁に切り替わる資料)。
LangChain最小実装
ここでは、埋め込み類似度でbreakpointを打つことでセマンティック分割を実装する例を示します。
import numpy as np
from langchain_google_vertexai import VertexAIEmbeddings
emb = VertexAIEmbeddings(model_name="gemini-embedding-001")
sents = text.split("。") # 例:粗めの文分割(実際はもっと丁寧に分割)
vecs = np.array(emb.embed_documents(sents))
sim = (vecs[:-1] * vecs[1:]).sum(axis=1) / (np.linalg.norm(vecs[:-1],axis=1)*np.linalg.norm(vecs[1:],axis=1))
breaks = np.where(sim < 0.75)[0] # 閾値は要調整
# breaks を境界にチャンクを組み立てる(ここは数行では割愛)
しかし、LangChainの公式ドキュメントを確認すると、「VertexAIEmbeddings」は非推奨(将来リリースで削除)となっています。

公式ドキュメントに記載のとおり、「GoogleGenerativeAIEmbeddings」で代替してください。
https://docs.langchain.com/oss/python/integrations/text_embedding/google_generative_ai
(5) 階層(Hierarchical)
- 仕組み:検索は小チャンクで行い、生成の際は親チャンク(より大きい文脈)を渡す。
- 強み:条件・例外・前提などの“背景”が回答に乗りやすく、断片化に強い。
- 弱み:親サイズを大きくしすぎるとコスト増。親子の設計(サイズ比・親サイズの選び方)が要点。
- 向く文書:規約・設計書・仕様書・研究資料(参照関係が強い資料)。
LangChain最小実装
「子で検索し、親を渡す」までの一連の流れを最小構成で示します。
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain_text_splitters import RecursiveCharacterTextSplitter
child = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=50) # 子: 小さい単位
parent = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=100) # 親: 大きい単位
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vs, docstore=store,
child_splitter=child, parent_splitter=parent
)
retriever.add_documents(docs) # docs: List[Document]
(6) メタデータ駆動(フィルタ/分割/並べ替え)
- 仕組み:章節、日付、システム名、部品名などのメタデータを付け、検索時にフィルタや優先順位付けに活用する。
- 強み:専門用語が多い領域で、誤ヒットやノイズを抑えやすい。運用の“説明責任”にも効く。
- 弱み:付与設計が雑だと逆効果(フィルタが効かない、メタデータが不整合など)。
- 向く文書:社内ドキュメント全般(AP基盤ドキュメントは特に相性が良い)。
LangChain最小実装
分割自体は再帰的分割・構造認識を利用し、metadataを付けて検索時にフィルタするのがポイントです(これはVectorStore側の機能に依存します)。
from langchain_core.documents import Document
docs = [
Document(page_content="...", metadata={"system":"AP基盤", "version":"v1"}),
Document(page_content="...", metadata={"system":"AP基盤", "version":"v2"}),
]
vectorstore.add_documents(docs)
retriever = vectorstore.as_retriever(search_kwargs={"k": 5, "filter": {"system": "AP基盤"}})
hits = retriever.invoke("デフォルト設定値は?")
上記では、filter=でフィルタリングを行っています。このフィルタリングが効くかどうかはVectorStore実装依存です。
(例: Pinecone / Weaviate 等は強い、FAISSは弱い)
[発展] コンテキスト付与(チャンクに“位置づけ説明”を足す)
チャンク単体では主語や前提が抜けがちな場合、チャンクに短い説明(文書内での位置づけ)を付与してから埋め込む、という発展的アプローチがあります。主に「指示代名詞が多い」「前提が多い」文書で効きますが、索引コストは増えます。
LangChain最小実装
チャンク本文に短い前置き(タイトル / 章 /目的など)をつけて埋め込む例を示します。
from langchain_core.documents import Document
enriched = []
for d in docs: # docs: Document[]
prefix = f"[{d.metadata.get('h2','')}/{d.metadata.get('h3','')}] "
enriched.append(Document(page_content=prefix + d.page_content, metadata=d.metadata))
vectorstore.add_documents(enriched)
[発展] Late Chunking(先に文書全体でエンコード→後で分割)
通常は「chunk→embed」ですが、先に文書全体を通して文脈を持たせたベクトル表現を得てから分割する、という発展的な考え方です。文書全体の文脈が効く一方、適用条件やコスト面の検討が必要です。
参考
・LangChain:Text Splitters(概念と実装)

・Google Cloud:layout parser統合(構造認識の入口として有用)
・Pinecone:semantic/contextual chunking を含む戦略整理
・Weaviate:chunking戦略(+発展手法)整理
・IBM watsonx:LangChain互換Chunker/隣接チャンク拡張(window search)

戦略別比較表:精度・コスト・実装難度のトレードオフ
各戦略は万能ではありません。精度(Precision)/ノイズ耐性 / 実装難度 / コスト / レイテンシのトレードオフを確認し、どの戦略を利用するかを判断する必要があります。
下記表に各チャンキング戦略の特徴をまとめています。
表. チャンキング戦略比較
| 戦略 | 精度 | ノイズ耐性 | 実装難度 | コスト | レイテンシ |
|---|---|---|---|---|---|
| 固定長 + overlap | 低〜中 | 低 | 低 | 低 | 低 |
| 再帰的分割 | 中 | 中 | 低 | 低 | 低 |
| 構造認識 | 中〜高 | 高 | 中 | 中 | 中 |
| セマンティック | 高 | 高 | 高 | 高 | 高 |
| 階層(small-to-big) | 中〜高 | 中 | 中 | 中 | 中 |
| コンテキスト付与/発展 | 中〜高 | 高 | 中〜高 | 中〜高 | 中〜高 |
この表は「どれが最強か」を決めるものではありません。各チャンキング戦略に得意な文章構造などがあるため、事前にその内容を加味して選択する必要があります。また、最初に選んだ戦略であまり精度が出なかった場合は、他のチャンキング戦略を採用してみるなどのトライ&エラーも必要になります。
チャンキング戦略 選び方
一度採用した戦略で思うような精度が出ない場合は「回答パターン」を確認するとよいです。
回答パターンとその原因・対策の一例を示します。下記が正解ではありませんが、参考にしていただければと思います。
表. 回答パターンの原因とその対策
| 回答の崩れ方(よくあるパターン) | ありがちな原因 | 優先して試す対策 |
|---|---|---|
| 回答が断片的(例外条件が落ちる) | サイズ小さすぎ / overlap不足 | overlap増 / 階層(small-to-big) |
| 関係ない文が混ざる(ノイズ多い) | サイズ大きすぎ / 前処理不足 | サイズ削減 / 構造認識 / メタデータフィルタ |
| 表の数値が崩れる | PDF/表のパース崩れ | 構造認識(layout parser等)/ 取り込み前処理の改善 |
| 同じ用語でも別文書がヒットする | メタデータ不足 / フィルタ無し | メタデータ付与(システム/部品/版数)+ フィルタ |
| 検索は当たるのに主語が不明 | 参照が多い / 文脈が抜ける | overlap増 / コンテキスト付与 |
検証デモ:LangChain + Vertex AI
ここからはデモパートです。今回は「チャンキング戦略によって、検索で拾える根拠がどう変わるか」を、LangChainでサクッと比較できる形にします。
なお、本デモの内容をもう少し詳しくした内容についてはGitHubで公開しているので、ぜひ確認してみてください。
構成:TextSplitter(戦略) → Embeddings(Vertex AI) → VectorStore(ローカル) → Retriever → 取得チャンクの比較
前提:環境構築
今回はuvを利用して環境構築を行います。
# 作業ディレクトリ準備 mkdir langchain_demo && cd langchain_demo # uv初期化 uv init # ライブラリ準備 uv add langchain \ langchain-community \ langchain-text-splitters \ langchain-google-genai \ faiss-cpu \ python-dotenv \ numpy \ tiktoken # GitHubリポジトリを参考にする場合は、下記コマンドで依存関係を解決できます。 uv sync
図 ディレクトリ構造
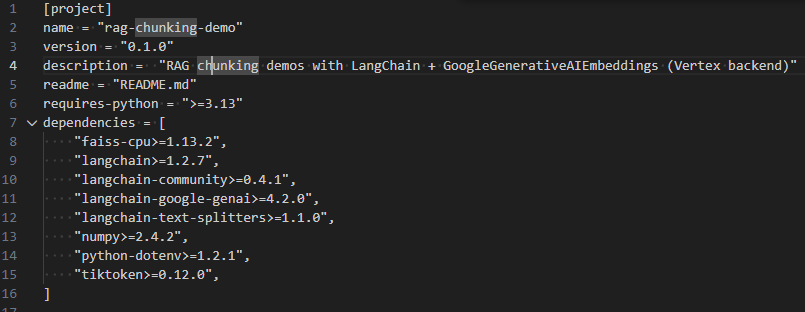
図 pyproject.tomlの内容
環境変数
.envファイルにVertexAI経由でGoogleモデルを呼び出すための設定を行います。
APIキーは事前に発行しておく必要があります。
GOOGLE_API_KEY=<取得したAPIキー>
GOOGLE_CLOUD_PROJECT=<Google Cloudのプロジェクト名>
GOOGLE_CLOUD_LOCATION=<リージョン名>
GOOGLE_GENAI_USE_VERTEXAI=true
EMBEDDING_MODEL=gemini-embedding-001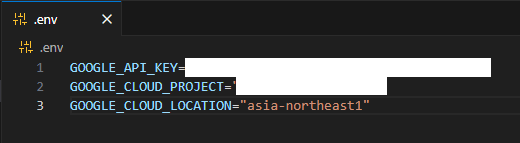
図 環境変数の設定
共通:ベクトル化と検索のユーティリティ
import os
from dataclasses import dataclass
from typing import List, Tuple
from dotenv import load_dotenv
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import FAISS
# LangChain splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 環境変数の読み込み
load_dotenv()
@dataclass
class SearchResult:
label: str
docs: List[str]
def build_vs(chunks: List[str], embeddings: GoogleGenerativeAIEmbeddings) -> FAISS:
"""Build a local FAISS vector store from plain text chunks."""
return FAISS.from_texts(chunks, embedding=embeddings)
def topk_texts(vs: FAISS, query: str, k: int = 3) -> List[str]:
docs = vs.similarity_search(query, k=k)
return [d.page_content for d in docs]
def show(title: str, texts: List[str]) -> None:
print(f"\n===== {title} =====")
for i, t in enumerate(texts, 1):
print(f"\n--- top{i} ---\n{t}")
# Embeddings(Google Generative AI)
# 本記事では、gemini-embedding-001を利用します。利用できるモデルは下記を確認してください
embeddings = GoogleGenerativeAIEmbeddings(
model=os.getenv("EMBEDDING_MODEL", "gemini-embedding-001"),
api_key=os.getenv("GOOGLE_API_KEY"),
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION"),
vertexai=os.getenv("GOOGLE_GENAI_USE_VERTEXAI", "true").lower() == "true",
)
デモ1:overlapの有無で「例外条件が落ちる」を再現
対応ソース:demos/demo1_overlap_effect.py
目的:単発ケースだけでなく複数ケースでも、overlap が Top1 の根拠取得に与える影響を確認します。
このデモで確認すること
- 目的:境界分断が起きたとき、overlap が Top1 の根拠欠落をどこまで緩和できるかを確認する
- 設定:
chunk_size=120、overlap=0とoverlap=20、検索はk=1(Top1)で比較 - 期待される差分:overlap ありの方が「基本 + 例外」が同一チャンクに残りやすく、Top1 欠落が減る
- 読み方:`判定` 行と `Top1で基本+例外を同時取得できた件数`(再現率)を見る
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 共通ユーティリティ(build_vs / topk_texts / show)と embeddings は前節を利用
def make_doc(noise_repeat: int) -> str:
return (
"背景説明。" * noise_repeat
+ "A部品の設定方針は次の通り。基本はX=ONとする。"
+ "ただしBモード時のみ例外でX=OFFとする。"
)
query = "A部品の設定方針を教えてください。基本設定(X=ON)と例外設定(X=OFF)を両方含めてください。"
# チャンク化:境界でX=ONが分断される設定
chunk_size = 120
overlap0 = 0
overlap1 = 20
split0 = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap0)
split1 = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=overlap1)
# 代表ケース(noise_repeat=20)
doc = make_doc(20)
chunks0 = split0.split_text(doc)
chunks1 = split1.split_text(doc)
show("overlap=0(境界で例外が落ちやすい)", topk_texts(build_vs(chunks0, embeddings), query, k=1))
show("overlap=20(例外が同居しやすい)", topk_texts(build_vs(chunks1, embeddings), query, k=1))
# 複数ケース
for r in [16, 18, 20, 22, 24]:
d = make_doc(r)
c0 = split0.split_text(d)
c1 = split1.split_text(d)
t0 = topk_texts(build_vs(c0, embeddings), query, k=1)
t1 = topk_texts(build_vs(c1, embeddings), query, k=1)
ok0 = any("X=ON" in t and "X=OFF" in t for t in t0)
ok1 = any("X=ON" in t and "X=OFF" in t for t in t1)
print(f"noise_repeat={r}: overlap=0 -> {'○' if ok0 else '×'}, overlap=20 -> {'○' if ok1 else '×'}")
実行結果
実行コマンド
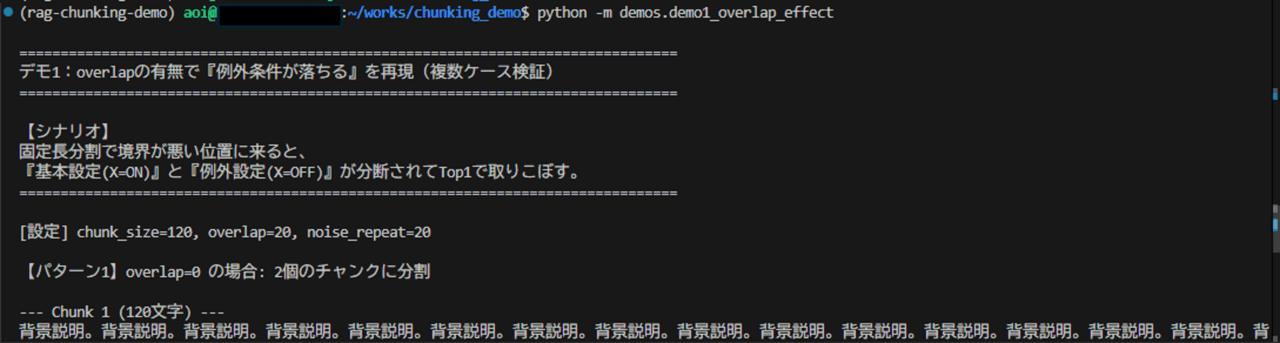
出力結果(要約)
[設定] chunk_size=120
【代表ケース】noise_repeat=20
overlap=0 : 判定 × 例外設定(X=OFF)が欠落
overlap=20 : 判定 ○ 基本設定と例外設定の両方が含まれる
【追加検証】複数ケースでの再現率(Top1)
noise_repeat=16: overlap=0 -> ×, overlap=20 -> ×
noise_repeat=18: overlap=0 -> ×, overlap=20 -> ×
noise_repeat=20: overlap=0 -> ×, overlap=20 -> ○
noise_repeat=22: overlap=0 -> ○, overlap=20 -> ○
noise_repeat=24: overlap=0 -> ○, overlap=20 -> ○
Top1で基本+例外を同時取得できた件数
overlap=0: 2/5
overlap=20: 3/5考察
- 代表ケースでは overlap=0 で取りこぼし、overlap=20 で回収できることを再現しました。
- 複数ケースでも overlap=20 の方が Top1 で根拠が揃う件数が多く(3/5 vs 2/5)、改善傾向を確認できました。
- 差分は境界位置に依存するため、実務では overlap 単体ではなく chunk_size と k を合わせて調整するのが妥当です。
- 今回のミニデモでは差分は限定的ですが、実務プロジェクトの長文・多条件文書では境界分断が増えるため、overlapの効き目は一般に大きくなります。
観察ポイント
- overlapは常に効く魔法ではなく、境界依存の問題を緩和する手段
- Top1運用では、境界情報を残す保険として有効に働きやすい
デモ2:固定長(token) vs 再帰分割で「読みやすいチャンク」を比較
対応ソース:demos/demo2_token_vs_recursive.py
目的:固定長だと文がブツ切れになり、人間が読んでも意味が取りづらい(=LLMにも厳しい)ことを示します。
※token側は日本語で文字化けしにくい `token_splitter()` を使います。langchaignの「CharacterTextSplitter」を利用しています。
しかし、日本語のチャンキング時にチャンク文字列が文字化けしてしまうという事象が発生していました。
下記のような感じです。
...制御する� �計判断です。
どうやら「TokenTextSplitter」では、日本語などのマルチバイト文字を含む文字列を分割すると、分割後に文字化けが発生する可能性があるようです。
そのため、今回は「TokenTextSplitter」ではなく、「CharacterTextSplitter」を採用しています。
langchain公式ドキュメント

このデモで確認すること
- 目的:固定長分割と再帰分割で、チャンクの可読性と意味まとまりがどう変わるかを比較する
- 設定:Token側は
chunk_size=25、Recursive側はchunk_size=120、どちらもoverlap=0 - 期待される差分:Token分割は文途中で切れやすく、Recursive分割は自然な文境界を保ちやすい
- 読み方:Token側の `[NG] 文の途中で切断` と、Recursive側の `[OK] 自然な区切り` を比較する
from langchain_text_splitters import RecursiveCharacterTextSplitter
from src.splitters import token_splitter
text = """
RAGのチャンキングは単なる分割ではありません。
検索精度と文脈保持、さらにコストとレイテンシのトレードオフを制御する設計判断です。
例えば、条件・例外・参照が多い仕様書では、文脈の断片化が致命的になります。
"""
token_split = token_splitter(chunk_size=25, chunk_overlap=0)
rec_split = RecursiveCharacterTextSplitter(chunk_size=120, chunk_overlap=0)
token_chunks = token_split.split_text(text)
rec_chunks = rec_split.split_text(text)
print("\n===== token split(固定長のイメージ) =====")
for c in token_chunks:
print("-", c)
print("\n===== recursive split(自然なまとまり) =====")
for c in rec_chunks:
print("-", c)
実行結果
実行コマンド
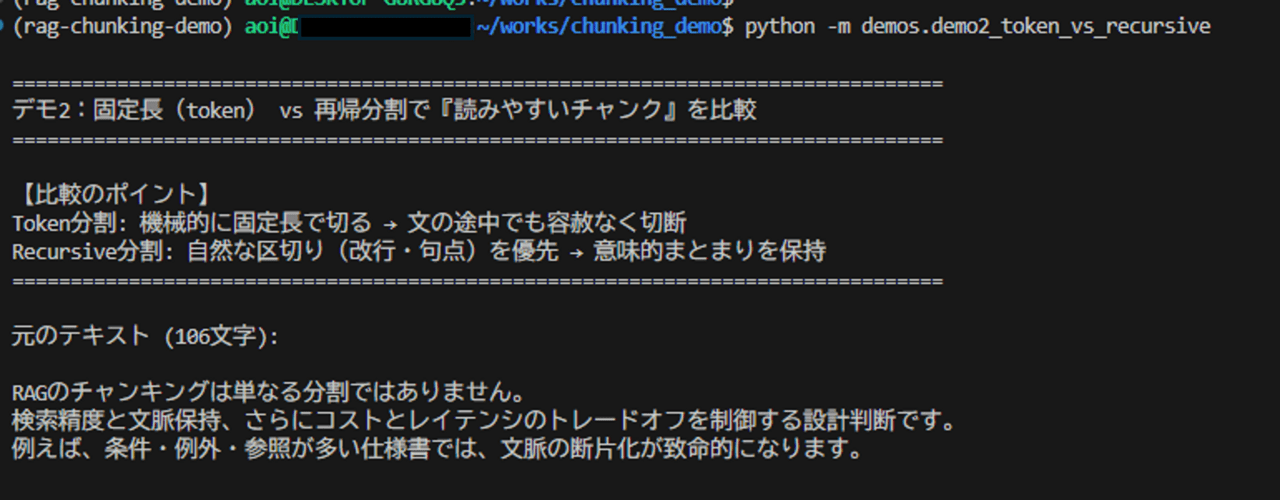
出力結果(要約)
【パターン1】Token分割 (chunk_size=25トークン)
結果: 7個のチャンクに分割
例:
- 『RAGのチャンキングは単なる分割ではありま』
- 『せん。検索精度と文脈保』
【パターン2】Recursive分割 (chunk_size=120文字)
結果: 1個のチャンクに分割
例:
- 『RAGのチャンキングは単なる分割ではありません。...(全文)』考察
- Token分割は長さ制御には強い一方、文の途中切断が連続し、意味まとまりが崩れやすいことが確認できました。
- Recursive分割は今回のテキストでは1チャンクに収まり、文脈の一貫性を保持できています。
- 日本語では「文字化けしないtoken分割」を使っても、文脈保持の観点ではRecursive優位になりやすい、という位置づけが妥当です。
デモ3:構造認識(レイアウト解析)に寄せると何が嬉しいか
対応ソース:demos/demo3_semantic_breakpoints.py
目的:構造なしの分割と、見出し構造を使った分割で、チャンクの意味的まとまりがどう変わるかを比較します。
このデモで確認すること
- 目的:平文分割と見出し分割で、トピック完結性と検索向けメタデータの有無を比較する
- 設定:平文は
RecursiveCharacterTextSplitter、構造ありはMarkdownHeaderTextSplitter(Header 1〜3) - 期待される差分:見出し分割の方が章単位でまとまり、Headerメタデータが付与される
- 読み方:`メタデータ` 行と、平文側の「トピック混在」有無を確認する
from src.splitters import markdown_header_splitter, recursive_splitter
plain_doc = """
システム設定ガイド
A部品の設定
基本設定
A部品の設定方針は次の通りです。
基本は「X=ON」とする。
例外設定
ただし、Bモードの場合は例外で、X=OFFとする。
"""
markdown_doc = """
# システム設定ガイド
## 1. A部品の設定
### 基本設定
A部品の設定方針は次の通りです。
基本は「X=ON」とする。
### 例外設定
ただし、Bモードの場合は例外で、X=OFFとする。
"""
# パターン1: 構造なし(Recursive)
plain_chunks = recursive_splitter(chunk_size=100, chunk_overlap=0).split_text(plain_doc)
# パターン2: 構造認識(Markdown Header)
headers_to_split_on = [("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3")]
md_docs = markdown_header_splitter(headers_to_split_on).split_text(markdown_doc)
print("plain chunks:", len(plain_chunks))
print("markdown header chunks:", len(md_docs))
for d in md_docs:
print(d.metadata, d.page_content[:40])
実行結果
実行コマンド
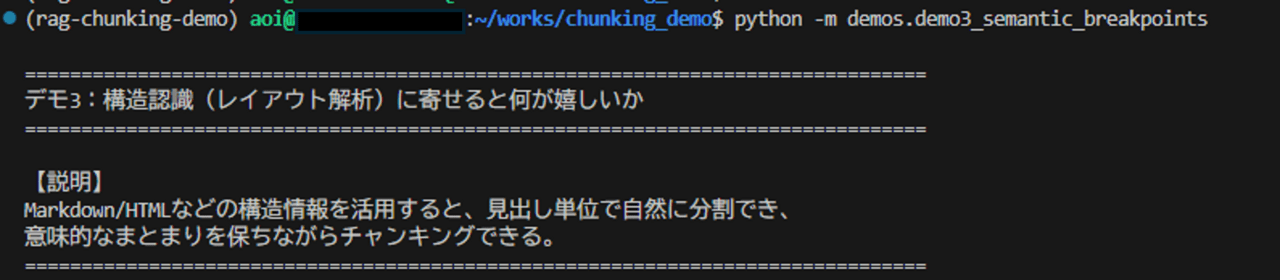
出力結果(要約)
【パターン1】構造なし(Recursive)
結果: 3個のチャンク
- Chunk 2 に「例外設定」と「認証設定」が同居し、トピックが混在
【パターン2】Markdown Header分割
結果: 4個のチャンク(見出し単位)
- Chunk 1 metadata: {'Header 1': 'システム設定ガイド', 'Header 2': '1. A部品の設定', 'Header 3': '基本設定'}
- Chunk 2 metadata: {'Header 1': 'システム設定ガイド', 'Header 2': '1. A部品の設定', 'Header 3': '例外設定'}考察
- 構造なし分割では「見出しだけ残る」「異なる章が同居する」状態が発生し、検索時の解釈が不安定になります。
- 見出し分割ではチャンク境界が文書構造と一致し、トピック完結性とメタデータ活用性が大きく向上します。
- 仕様書・手順書・運用ドキュメントのような構造化文書では、まずHeader分割を優先するのが実践的です。
観察ポイント
- 構造なし分割では、見出しと本文が混在しやすく、トピックが分散しやすい
- 見出し分割では、Headerメタデータ付きでトピック単位にまとまりやすい
参考
・LangChain:Text Splitters(概念と実装)
・LangChain:Vertex AI embeddings integration

・Google Cloud:layout parser統合(構造認識の入口として有用)
評価(次回記事):チャンキング改善はどう測る?
チャンキングは“それっぽく”改善できてしまう一方で、主観評価に寄ると迷走しがちです。最低限、次の指標で定量的に「良くなった/悪くなった」を測れる状態にしておくのが安全です(詳細は次回で扱います)。
- Context Recall:正解に必要な根拠がTop-kに入っているか
- Context Precision:Top-kがノイズだらけになっていないか
- Faithfulness:回答が取得した根拠に接地しているか
- Answer Relevancy:質問にちゃんと答えているか
おすすめの評価・改善ループは、
- 代表クエリ50件(ファクト系/分析系/手順系を混ぜる)
- ベースライン(固定長+overlap or 再帰)でTop-kログを保存
- 1つだけ条件を変えて比較(サイズだけ、overlapだけ、構造認識だけ…)
です。これで“改善の方向性”が掴めます。
(補足)Amazon Bedrock Knowledge Basesで考える場合
シリーズ2以降で本格的に検証予定ですが、「マネージドサービスで楽をしたい」場合の整理も置いておきます。
AWSでは、Amazon Bedrock Knowledge Basesというマネージドサービスが提供されており、RAG環境を簡単に構築することが可能です。2026年2月時点で利用できるAmazon Bedrock Knowledge Bases(Bedrock KB)で利用できるチャンキング戦略は下記となります。
これまで説明してきたチャンキング戦略と対応付けると、ざっくり次のイメージです(詳細はTipsシリーズで検証します)。
表. Amazon Bedrock Knowledge Bases で利用可能なチャンキング戦略
| Bedrock KB | 一般戦略の読み替え | 一言 |
|---|---|---|
| Default | ベースライン | 迷ったらまずこれ |
| Fixed-size | 固定長 + overlap | 速度・コスト優先 |
| Hierarchical | 階層(Hierarchical) | 複雑文脈向け |
| Semantic | セマンティック | 高精度寄り(コスト増に注意) |
| None | 分割なし | 前処理済み/FAQ向け |
まとめ
本記事では、RAGにおけるチャンキング戦略について説明してきました。
- まずは固定長 + overlap/再帰分割でベースラインを作る
- 断片化・ノイズ・表崩れなど、回答がどう崩れているかから原因を推定し、必要なところだけ高度化する
- デモのように、取得チャンクを比較して「どこが壊れているか」を観察する
- 改善は評価指標(Recall/Precision/Faithfulness等)で“定量的に測れる状態”にして進める
次回は、この改善が本当に効いているかを判断するために、RAGの評価(定量評価)を扱います。Ragasなどの評価指標で「良くなった/悪くなった」を測れる状態にしていきましょう。
次回もぜひご覧ください。
