

SCSK いわいです。
前回はRaspberry Pi 5で気温/気圧/湿度センサーを使って測定し、
Webで表示、DBに取得データを検索するシステムを構築しました。
今回は測定したデータからAIを使って気温/気圧/湿度をリアルタイム予測してみます。
今回は前回セットアップした環境をそのまま流用します。

過去データから現在値を予測する
過去データから現在値を予測します。これには機械学習結果からの推論(教師あり学習)を使用します。
温度/湿度/気圧の予測のために「線形回帰」「非線形回帰」「LSTM(Long Short Term Memory)」の3つを試してみます。
「線形回帰」はデータの関係性が直線(線形)の場合で表せる場合に使われます。
⇒グラフにした時にだいたいまっすぐな線で表せる
例えば商品の売上と広告費用などが該当します。

「非線形回帰」は「データの関係性が曲線(非線形)」で表せる場合に使われます。
⇒グラフにした時に曲がった線で表せる
例えば投げたボールの高さと時間の関係が該当します。
「LSTM」は時系列データや文章など、時間の流れや順番が大事なデータをうまく使える機械学習のモデルです。
⇒過去と今の情報を組み合わせて考えられる仕組み
例えば株価の予測、文章の意味理解が該当します。
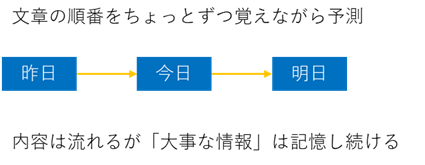
普通の再帰型ニューラルネットワークは「昔のこと」をすぐ忘れてしまいますが、LSTMは
「長い・短い記憶をうまく使い分けできる」ので、長い文章や長期的な傾向も扱えるようです。
なんだか今回のテーマに合致しそうな気配です。
ざっくりまとめると以下になります。
| 方式 | 得意なデータ | 値の関係 | 過去の情報との関係 | 例 |
|---|---|---|---|---|
| 線形回帰 | 数値 & シンプル | 直線 | 考慮しない | 商品の売上と広告費用 |
| 非線形回帰 (RF予測) |
数値 & 複雑 | 曲線 | 考慮しない | 投げたボールの高さと経過時間 |
| LSTM | 時系列・文章・音声等 | 複雑 + 順番 | 重視する | 株価予測、文書生成 |
これらの3つの方式を実装してどの予測値が実測値に近いか確認してみます。
システムのイメージ
前回作成したFlaskアプリケーションに機能を追加します。今回はWeb画面に測定結果と予測値を表示します。
蓄積した測定結果から予測モデルを作成して、予測モデルを使ってリアルタイムで現在の温度/湿度/気圧を予測してみます。
イメージはこんなカンジで。
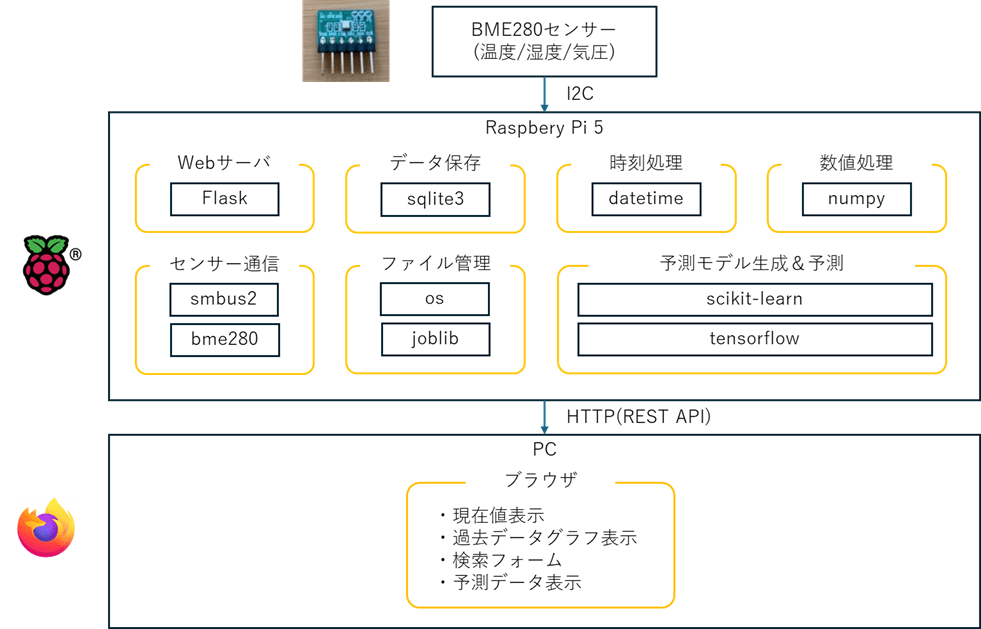
今回のシステムで導入する機能と各ライブラリの説明は以下のとおりです。
| 機能 | ライブラリ | 説明 |
|---|---|---|
| Webサーバ | Flask | 軽量なWebフレームワーク。センサー値や予測結果をWebアプリとしてブラウザに表示。 |
| センサー通信 | Smbus2 | ラズパイとI2C通信する。BME280と通信するために利用。 |
| bme280 | Bosch製の温湿度・気圧センサー BME280用のPythonライブラリ。データ取得する。 | |
| データ保存 | sqlite3 | 軽量な組み込み型データベースSQLiteを操作するためのライブラリ。計測データをローカルDBに保存・検索するために利用。 |
| 時刻処理 | datetime | 計測時刻の記録に利用。ローカルDBに保存するtimestampを生成。 |
| ファイル管理 (new) | os | OSレベルの操作。LSTMモデル/Scalerファイル(ディープラーニング結果ファイル)の存在確認に利用。 |
| joblib | Pythonオブジェクトを高速に保存・読み込みするためのライブラリ。学習済みScalerを保存・読み込みするために利用。 | |
| 数値処理 (new) | numpy | 数値計算ライブラリ。線形回帰やLSTMに渡すデータを配列に整形するために利用。 |
| 機械学習 (new) | scikit-learn | 線形回帰、非線形回帰をつかった予測のために利用。 |
| tensorflow | LSTM予測のために利用。 |
前回導入済みのライブラリに加え、ファイル管理用ライブラリ(joblib)、数値処理ライブラリ(numpy)、機械学習用ライブラリ(scikit-learn、tensorflow)を追加します。ファイル管理用ライブラリであるosはデフォルトでインストールされています。
過去のデータからLSTMモデルを作成する
LSTMモデルを作成するために高速演算用ライブラリのnumpy、機械学習ライブラリのscikit-learnとtensorflow、ファイル生成用ライブラリjoblibをインストールします。
| sudo pip install numpy –break-system-packages sudo pip install tensorflow –break-system-packages sudo pip install scikit-learn –break-system-packages sudo pip install joblib –break-system-packages |
ローカルに測定結果を蓄積しているDBファイルを元にLSTMモデルとScalerファイルを生成します。
Scalerファイルとは学習時のデータの最大値/最小値、標準偏差等を求めて、それぞれのデータをを0~1の数値に
置き換えるための定義ファイルとのこと。
この定義ファイルがないとそもそもどんな情報を元に学習した結果なのかわからず、
予測もできないため、学習時と予測時には同じ定義ファイルを使う必要があります。
import sqlite3
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
import joblib # スケーラー保存用
# ====== 設定 ======
DB_FILE = "bme280_data.db"
TREND_WINDOW = 10 # LSTM の timesteps
MODEL_FILE = "bme280_lstm_model.keras"
SCALER_FILE = "bme280_scaler.save"
# ====== SQLite からデータ取得 ======
def load_data():
with sqlite3.connect(DB_FILE) as conn:
c = conn.cursor()
c.execute("""
SELECT temperature, humidity, pressure
FROM measurements
ORDER BY timestamp ASC
""")
rows = c.fetchall()
data = np.array(rows, dtype=np.float32)
return data # shape = (n_samples, 3)
# ====== LSTM 用系列データ作成 ======
def create_sequences(data, window_size):
X, y = [], []
for i in range(len(data) - window_size):
X.append(data[i:i + window_size])
y.append(data[i + window_size])
return np.array(X), np.array(y)
# ====== メイン処理 ======
def main():
# --- データロード ---
data = load_data()
if len(data) <= TREND_WINDOW:
raise ValueError("データ数が TREND_WINDOW 以下です")
# --- 正規化 ---
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# --- 系列化 ---
X, y = create_sequences(data_scaled, TREND_WINDOW)
print("X shape:", X.shape) # (samples, timesteps, features)
print("y shape:", y.shape) # (samples, features)
# --- LSTM モデル ---
model = Sequential([
LSTM(32, input_shape=(X.shape[1], X.shape[2])),
Dense(X.shape[2]) # temperature, humidity, pressure
])
model.compile(
optimizer="adam",
loss="mse"
)
model.summary()
# --- 学習 ---
model.fit(
X,
y,
epochs=100,
batch_size=16,
verbose=1
)
# --- 保存(.keras 形式) ---
model.save(MODEL_FILE)
joblib.dump(scaler, SCALER_FILE)
print("✅ モデル保存:", MODEL_FILE)
print("✅ スケーラー保存:", SCALER_FILE)
# ====== 実行 ======
if __name__ == "__main__":
main()
予測用に直近10件のデータを測定し、学習結果から次の1件のデータを予測するLSTMモデルを作成しています。
これで温度/湿度/気圧予測の準備ができました。
Pythonスクリプト作成/実行
今回もChatGPTを利用してPythonスクリプトを作りました。
前回の構成に過去のデータから現在の気温/湿度/気圧を線形予測、RF予測、LSTM予測した結果を
表示する機能を追加しています。
線形予測は直近5000件のデータから現在の各値を予測、RF予測は過去の測定値からランダムな特徴やデータの一部を選定、
50パターンの決定木 = forestを生成して、その平均値から各値を予測するように設計しています。
Raspberry PiでWebサーバを起動します。
実行結果
上から「実測値」、「線形予測値」、「RF予測値」、「LSTM予測値」を表示しています。
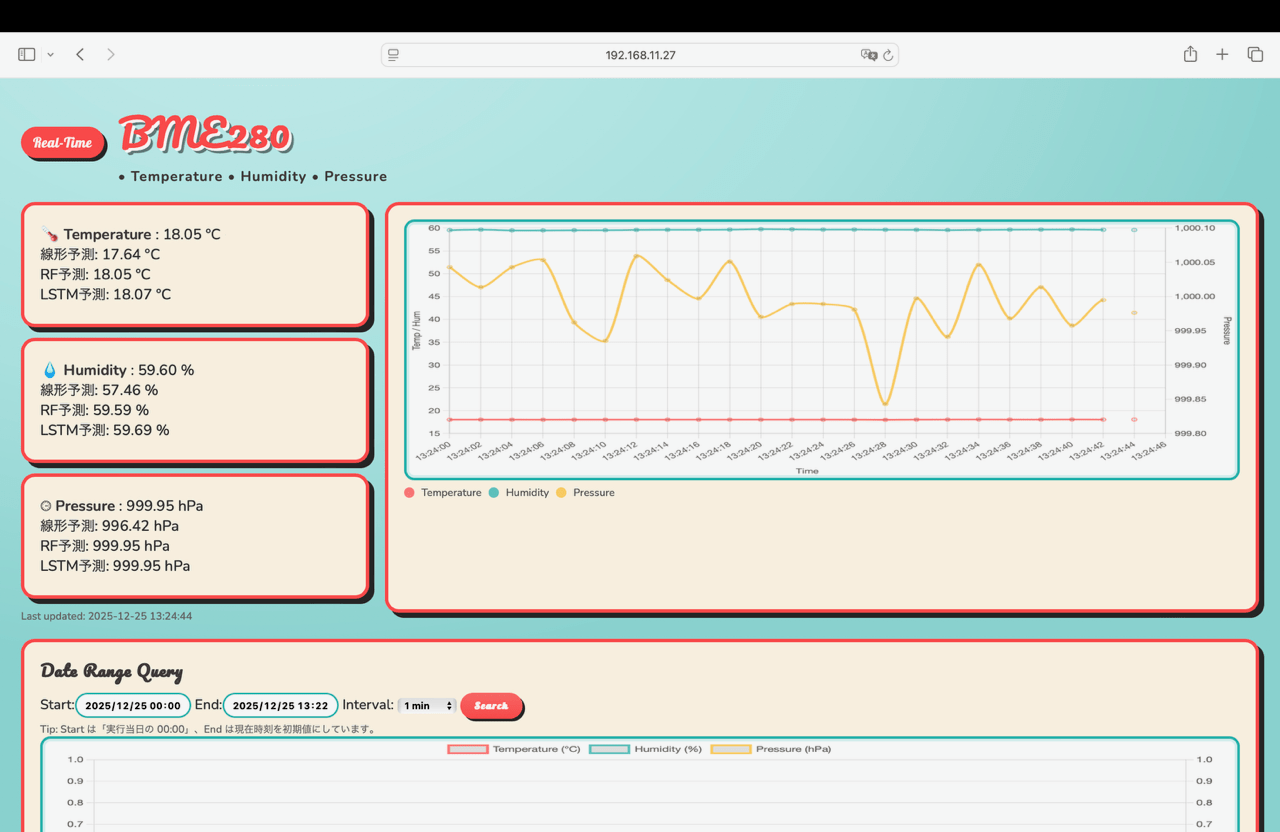
線形予測はだいぶ外れた値、RF予測は実測値にかなり近い値、LSTM予測は若干ずれた値となりました。
現実では温度/湿度/気温には以下の傾向があります。
温度:平坦⇒微増/微減⇒平坦
湿度:ジグザグ
気圧:ほぼ一定+揺れ
この現象に対してそれぞれのリアルタイム予測はざっくりと以下のように動きます。
線形予測:微増/微減したら次も微増/微減するはず
⇒そもそも現実と合致してないが傾向はわかる
RF予測:大体前と同じぐらいの値では?
⇒ほぼ正解
LSTM予測:過去の値からみてちょっと変えたほうがそれっぽい?
⇒賢すぎてノイズが発生することもあるがクセは覚えられる
今回のケースではそれぞれの予測は得意な分野があることがわかりました。
線形予測は「傾向予測、急激な変化を検出する」、RF予測は「リアルタイム予測、直近予測をする」、
LSTM予測は「周期的な予測、1時間後の予測をする」が得意なようです。
勉強になりました。