
SCSKの畑です。
前回のエントリに引き続き、今年度のアプリケーション性能改善の取り組みについて説明していきたいと思います。今回はテーブルデータのバリデーションチェック機能の性能改善について説明していきます。
はじめに
テーブルデータのバリデーションチェック機能についての背景や概要については、昨年度投稿したエントリで一通り説明していましたので詳細はこちらをご覧頂ければと思います。

簡単に本稿でも説明すると、本アプリケーションを使用して Redshift のテーブルを更新する際にデータの整合性を担保する目的で、テーブル定義に基づく各種制約(列のデータ型定義によるものや NOT NULL制約、PK/UK/FK 制約) をアプリケーション側でチェックするための機能です。特に PK/UK/FK 制約については Redshift 上で制約として機能しないことから、テーブルデータを更新する前にアプリケーション側でチェックできないと制約に反するデータを更新できてしまうため、データの整合性を担保する観点において重要な機能でした。
具体的な実装としては、こちらも前回のエントリで取り上げている tabulator というテーブルデータを取り扱うためのライブラリの組み込み機能をそのまま使用していました。ただ、複合キーによる PK/UK や FK 制約についてはさすがに用意されていなかったため、自前で実装したものをライブラリの組み込み機能にカスタムバリデータとして組み込むことで実装しました。
このバリデーションチェックは Redshift 上のテーブルに更新を反映する前の事前チェックとして、編集中のデータに対して画面上で実行されますが、特にデータ量の大きいテーブルでの所要時間が大幅に伸びるケース(最大10分程度)が散見されるようになりました。数分程度ならまだしも10分を超えてくるようなら改善して欲しい旨お客さんからも打診頂き、改善に向けて取り組むことになりました。
今回の取り組みに至った原因とその背景
前回エントリとほぼ同じなのですが、「本アプリケーションで扱うテーブル(定義・データ)の長大化」が主な原因でした。
テーブル定義に従ってデータのバリデーションチェックをする以上、対象データの増加に伴い計算量が増えるのは自明なことです。また、扱うテーブルの定義自体も昨年度のアプリケーションリリース時からすると相対的により複雑化・長大化の傾向があり、テーブルの列や制約の数が増えることでバリデーションチェックの対象も増加し、最終的には同じように計算コストの増加に繋がってしまいました。
実装上の問題点
こちらも前回エントリの問題点と概ね同じで、先述した通り tabulator の組み込み機能を使用していることでした。昨年度リリース時点のテーブル定義やデータ量でテストした限りだと、一番データ量の大きなテーブル(数万行)でも十数秒だったのですが、場合によっては数分〜十分程度を要するようになってしまいました。
tabulator 標準のバリデータを使用している処理もあったので、当初はそれも含めて全てカスタムバリデータに変更することで改善できないかとも考えたのですが、tabulator 標準のバリデータでチェックしている内容は相対的に単純で工夫の余地が少なそうだったため、tabulator の組み込み機能ではなくバックエンド側にバリデーションチェック処理を移管する方向性で検討することにしました。
改修の方向性
さて、本件については改修の方向性は最初からはっきりしており、具体的には個々のデータバリデーションを並列実行することで処理時間を短縮するアプローチを考えていました。以下2点が主な理由です。
- 個々のバリデーションチェック(データ型定義や NOT NULL/PK/UK/FK 制約)はそれぞれ独立しており、支障なく並列実行可能であることから高速化が期待できる
- バックエンドに処理を移管することでバックエンド側の計算リソースをフル活用可能
特に2点目はフロントエンドから処理を移管する大きな理由となりました。仮にフロントエンド(tabulator)の機能でバリデーションチェックの並列化が可能だったとしても、それによりクライアントの計算リソースをフル活用することになってしまうため、それはそれで支障があったものと思います。例えば Web ブラウザからページ内処理が重くなってしまっている旨の警告が出る、Web ブラウザ側で処理を中断されるなどの可能性があると考えました。
本アプリケーションによるバックエンド処理は基本的に Lambda (Python)で実装しているので、新しくバリデーションチェック用の Lambda を作って並列実行すれば良いかなとこの時点では楽観的に考えていたのですが・・
Lambda における並列実行の問題点と解決策
Python における並列実行はマルチスレッドとマルチプロセスの2種類がありますが、バリデーションチェックに必要な計算処理の特性(基本的には CPU バウンド)を考えるとマルチプロセス一択でした。よって、まず ProcessPoolExecutor を使用したマルチプロセスによる並列実行のプロトタイプを Lambda 上で動かしてみたところ、以下のようなエラーが出てしまいました。
{
"errorMessage": "[Errno 13] Permission denied",
"errorType": "PermissionError",
"requestId": "4e125fb8-8d71-47f3-b70c-91e37f2023df",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 5, in lambda_handler\n main()\n",
" File \"/var/task/lambda_function.py\", line 16, in main\n with ProcessPoolExecutor(max_workers=4) as executor:\n",
" File \"/var/lang/lib/python3.11/concurrent/futures/process.py\", line 732, in __init__\n self._call_queue = _SafeQueue(\n",
" File \"/var/lang/lib/python3.11/concurrent/futures/process.py\", line 173, in __init__\n super().__init__(max_size, ctx=ctx)\n",
" File \"/var/lang/lib/python3.11/multiprocessing/queues.py\", line 43, in __init__\n self._rlock = ctx.Lock()\n",
" File \"/var/lang/lib/python3.11/multiprocessing/context.py\", line 68, in Lock\n return Lock(ctx=self.get_context())\n",
" File \"/var/lang/lib/python3.11/multiprocessing/synchronize.py\", line 169, in __init__\n SemLock.__init__(self, SEMAPHORE, 1, 1, ctx=ctx)\n",
" File \"/var/lang/lib/python3.11/multiprocessing/synchronize.py\", line 57, in __init__\n sl = self._semlock = _multiprocessing.SemLock(\n"
]
}
んー?プロトタイプレベルの実装なんだからコードに間違いはないと思うし、そもそもエラーの内容が良く分からないな・・と思いながら調べてみたところ、本事象に該当する情報が AWS 公式含めてゴロゴロ出てきました。要するに、ProcessPoolExecutor は共有メモリ(/dev/shm) 経由で親子プロセス間の通信や管理を行うが、Lambda がそれをサポートしていないため実行できないというのが理由のようでした。

マルチスレッドは使えるものの、先述の通り CPU バウンドな処理の高速化は原理上望めない&試したみたところ想定通りの結果となったためどうしたものかと思っていたのですが、Web 上の情報を色々調べていくと共有メモリ(/dev/shm) を使用しない実装でマルチプロセス処理を実現している例も複数見受けられたことから、それらの情報を参考にさせて頂きつつ自前で実装することにしました。具体的には、multiprocessing.Process により子プロセスを生成の上、multiprocessing.Pipe (パイプ)により親子プロセス間で通信して各種情報のやり取りを行うような方式となります。上記の AWS 公式 URL でも同じような方式が記載されていました。
以下、各構成要素における実装例を記載していきます。
バックエンド (Amplify/AppSync)
先述の通り元々はフロントエンド(tabulator)で完結していたため新規実装になっています。ただ、バリデーションチェック結果を画面表示するために必要な情報(フォーマット)は現行のフロントエンド実装より明らかであり、かつ変更の必要はなかったため、スキーマ設計をフロントエンド実装に合わせるような形となりました。
enum ValiType {
PK
UK
FK
NOT_NULL
DATA_TYPE_INT
DATA_TYPE_CHAR
DEL_FLG
}
type ValiInfo {
type: ValiType!
columns: [String!]!
}
type ValiResult {
index: Int!
info: [ValiInfo!]!
}
内容についても簡単に説明します。
- バリデーションチェックの結果として、テーブル定義に基づく各種制約に違反している行の情報が ValiResult の配列に格納される
- ValiResult には制約違反した特定の行の番号、及びその行に含まれる制約違反の詳細情報の配列が格納される
- 前回のエントリと同じように、テーブルデータにおける特定の一意な行を取得するために行番号を使用している
- 制約違反の詳細情報は、制約違反の種類を示す ValiType (enum) と、列名の組み合わせで表現
バックエンド (Lambda)
以下、並列実行部分の一部抜粋です。先述の通り、Lambda における Python マルチプロセス処理の実装方式はほぼ限られていると思われるので特に目新しさはないですが、ちょっとだけ工夫した部分もあるので備忘を兼ねて。。
def validation_worker(task_pipe, result_pipe,
df_serialized: bytes, table_data_info: Dict, fk_reference_data_serialized: bytes):
"""バリデーションワーカープロセス(動的タスク取得)"""
try:
df = pickle.loads(df_serialized)
fk_reference_data = pickle.loads(fk_reference_data_serialized)
func_map = {
'validate_primary_key': validate_primary_key,
'validate_unique_key': validate_unique_key,
'validate_foreign_key': validate_foreign_key,
'validate_not_null': validate_not_null,
'validate_integer_type': validate_integer_type,
'validate_char_type': validate_char_type,
'validate_delete_flag': validate_delete_flag
}
while True:
# タスクをリクエストして受信(同一Pipeで双方向通信)
task_pipe.send('READY')
task = task_pipe.recv()
if task is None: # 終了シグナル
break
try:
# バリデーションタイプに対応した関数を取得
vali_type, func_name, args = task
func = func_map[func_name]
# バリデーションタイプに応じて関数に渡す引数を変更
if func_name == 'validate_foreign_key':
fk_info, ref_data_key = args
ref_data = fk_reference_data[ref_data_key]
violations = func(df, fk_info, ref_data)
elif func_name == 'validate_delete_flag':
violations = func(df)
else:
violations = func(df, args[0])
# バリデーションチェック結果を親プロセスに送信
for violation in violations:
result_pipe.send({
'index': violation['index'],
'info': [{'type': vali_type, 'columns': violation['columns']}]
})
except Exception as e:
logger.error(f"Validation task error: {e}")
except Exception as e:
logger.error(f"Validation worker error: {e}")
finally:
task_pipe.close()
result_pipe.close()
def validate_constraints_parallel(df: pd.DataFrame, table_data_info: Dict, fk_reference_data: Dict) -> List[Dict[str, Any]]:
"""制約チェックを並列実行(動的タスク割り当て)"""
df_serialized = pickle.dumps(df)
fk_reference_data_serialized = pickle.dumps(fk_reference_data)
tasks = prepare_validation_tasks(table_data_info, df.columns, fk_reference_data)
# バリデーションチェックタスクがない場合は空配列を返して終了
if not tasks:
return []
# ワーカー数決定
num_workers = min(MAX_WORKERS, len(tasks), multiprocessing.cpu_count())
# プロセスとパイプを作成(2種類)
processes = []
task_pipes = [] # ワーカーとの双方向通信用
result_pipes = [] # ワーカーからの結果受信用
# ワーカープロセスの並列起動
for _ in range(num_workers):
task_parent, task_child = multiprocessing.Pipe()
result_parent, result_child = multiprocessing.Pipe()
task_pipes.append(task_parent)
result_pipes.append(result_parent)
p = multiprocessing.Process(
target=validation_worker,
args=(task_child, result_child, df_serialized, table_data_info, fk_reference_data_serialized)
)
p.start()
processes.append(p)
task_index = 0
active_workers = num_workers
all_violations = []
# タスク割り当てとバリデーションチェック結収集のループ実行
while active_workers > 0:
# タスク割り当て処理
for i, task_pipe in enumerate(task_pipes):
if task_pipe.closed:
continue
if task_pipe.poll(0.01): # 10msタイムアウトでポーリング
try:
msg = task_pipe.recv()
if msg == 'READY':
if task_index < len(tasks):
# 次のタスクを送信
task_pipe.send(tasks[task_index])
task_index += 1
else:
# 全タスク完了、終了シグナルを送信
task_pipe.send(None)
task_pipe.close()
active_workers -= 1
except Exception as e:
logger.error(f"Dispatcher error: {e}")
# バリデーションチェック結果を並行収集
for result_pipe in result_pipes:
if result_pipe.closed:
continue
while result_pipe.poll(0): # ノンブロッキングでポーリング
try:
violation = result_pipe.recv()
all_violations.append(violation)
except:
break
# アクティブワーカーが0になった後、残りのバリデーションチェック結果を収集
for result_pipe in result_pipes:
while result_pipe.poll(0.1):
try:
violation = result_pipe.recv()
all_violations.append(violation)
except:
break
result_pipe.close()
# プロセス終了を待機
for p in processes:
p.join()
# バリデーションチェック結果を行番号でマージ/ソートして返却
return merge_and_sort_violations(all_violations)
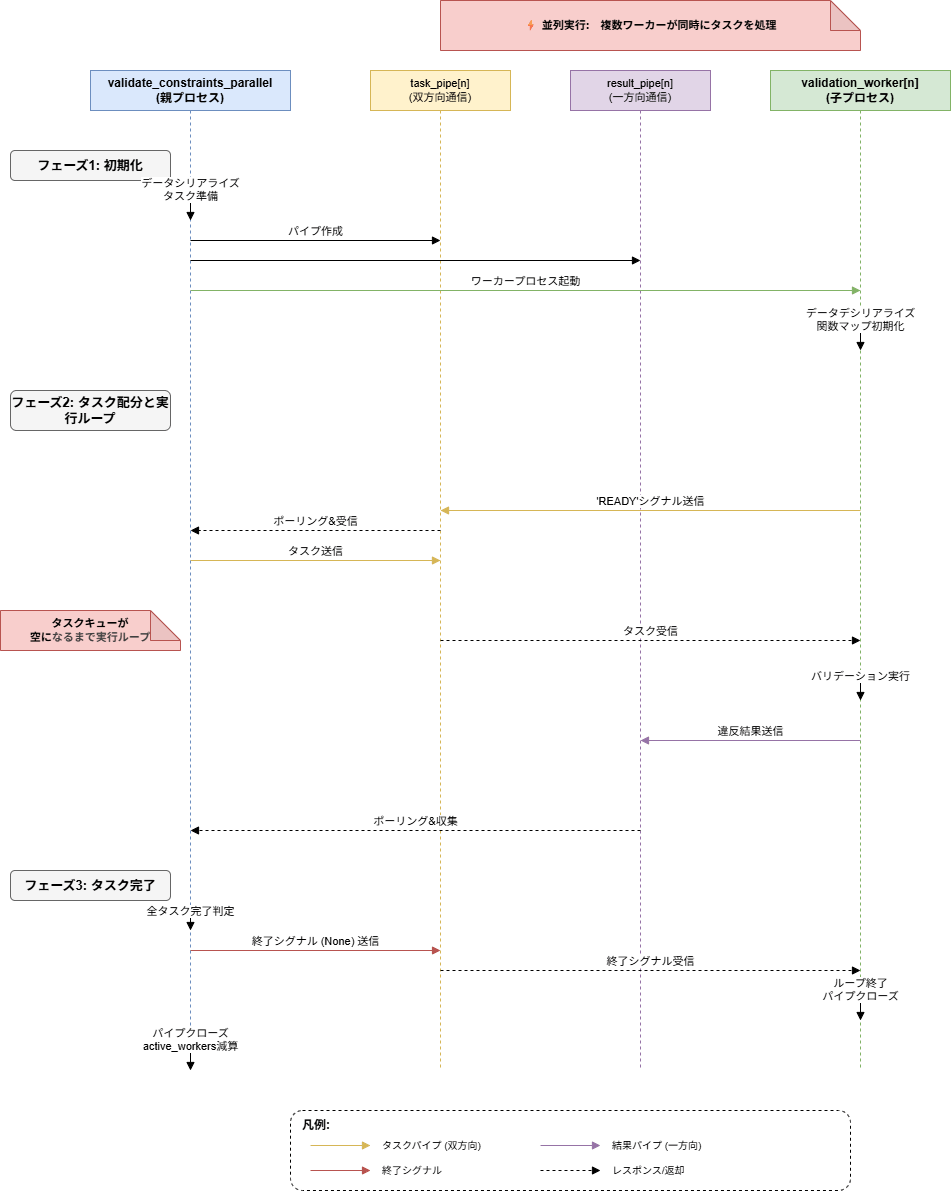
validate_constraints_parallel メソッドがバリデーションチェックを並列実行するためのコーディネータ、validation_worker メソッドがマルチプロセスにより個々のバリデーションチェックタスクを実行するワーカーです。それぞれの内容についても簡単にまとめます。
validate_constraints_parallel
いまいまの Lambda の仕様におけるベーシックなマルチプロセス処理の実装は、multiprocessing.Process により生成した子プロセスに対してタスクをラウンドロビンで事前に割り当てることだと思いますが、この場合子プロセスに割り当てられたタスクの内容によって子プロセスごとの処理時間にバラつきが出やすくなる可能性があるため、キューイングにより子プロセスへのタスク割り当てを行っています。
マルチプロセスにおけるキューイング処理のため素直に multiprocessing.Queue などを使用して実装したいところなのですが、先述の通り Lambda で共有メモリ(/dev/shm)がサポートされていないためこちらも使用できません。このため、具体的には親子プロセス間で2つの Pipe を用意し、以下のような用途で使い分けることでキューイング処理を実現しています。共有メモリを使用できる実装と比較するとやや力業というか、厳密には擬似的な実装となってしまいますが・・
- 双方向通信用 Pipe(親プロセス ↔ 子プロセス):task_pipes
- 親子プロセス間の実行制御に使用
- 片方向通信用 Pipe(親プロセス ← 子プロセス):result_pipes
- 子プロセスで実行したバリデーションチェック結果を親プロセスに返すために使用
その上で、以下のようなシーケンスで処理を実行することで、キューイングにより子プロセスへのタスク割り当てを行っています。
- 算出された並列度で子プロセスを起動
- 起動された子プロセスから親プロセスにタスクの割り当て要求シグナルとして「READY」文字列を送信
- タスク割り当てを要求後は定期的に task_pipes を polling し、タスク割り当てを待つ
- 「None」を受信した場合は割り当てられるタスクが残存していないことを意味しているため、子プロセスを終了
- 親プロセスで task_pipes を定期的に polling し、「READY」が受信できたらタスクのキュー配列からタスクを取り出し、対応する子プロセスに task_pipes 経由でタスク情報を送信(割り当て)
- 並行して result_pipes も定期的に polling し、子プロセス側で完了しているバリデーションチェックの結果があれば取得
- 親プロセス側で定期的に result_pipes の中身を取得しないと Pipe のバッファサイズ(64KB)を超過してしまい、子プロセスにおける result_pipes への書き込み(送信)処理がブロッキングされてしまう可能性があるため
- 並行して result_pipes も定期的に polling し、子プロセス側で完了しているバリデーションチェックの結果があれば取得
- タスクを割り当てられた子プロセスでバリデーションチェック処理を実行し、結果を result_pipes 経由で送信
- 結果送信後は 2. に戻り、次のタスク割り当てを待つ
- タスクのキュー配列に格納されていた全タスクの取り出しが完了次第、各子プロセスに終了シグナルとして「None」を送信
子プロセスで実行中のタスクがあればその完了後に終了、そうでなければ即時終了 - 全子プロセスの終了後、result_pipes に残存しているバリデーションチェックの結果を全て取得の上、適切なフォーマットに変換して呼び出し元のメインハンドラに返す
一応シーケンス図も書いてみましたが、さすがにちょっと面倒だったので Kiro にお願いしてみました。こういう用途に使えるようになったのは本当に便利ですよね・・
validation_worker
個々のバリデーションチェックを実行するために、親プロセスから起動される子プロセス内の実装を記述しています。よって実装内容自体は上記シーケンスで示されている通りとなるため、ここで特筆すべき点は特にありません。
強いて言うなら、親プロセスから引数経由で DataFrame の受け渡しがあるため、その前後で pickle でシリアライズ/デシリアライズしているくらいでしょうか。それから、個々のバリデーションチェックはそれぞれメソッドとして定義しており、親プロセスからは対応するメソッド名のみを受け取っています。
フロントエンド (typescript)
こちらは今回の一連の変更前後で実装を変更していませんが、備忘がてら合わせて残しておきます。前回のエントリで言及した内容と同じように rowFormatter コールバックを使用した実装となっており、行番号を使用して制約違反に該当する行を導出し、フォーマット(色)を変更しています。
// テーブルデータ編集時のrowFormatter設定
const ecRowsFormatter = function(row){
// バリデーションエラー行の色付け
// ValidationInfos.value配列のROW_IDと、row.getIndex()が一致する行をフィルタ
const row_vali_info = ValidationInfos.value.filter(info => info.ROW_ID === row.getIndex());
for ( const vali_info of row_vali_info ) {
for ( const cell of row.getCells() ) {
if (cell.getColumn().getDefinition().title === vali_info.col_name){
cell.getElement().style.backgroundColor = "#fca5a5";
break
}
}
}
}
以上の一連の対応により、データサイズが数万行単位/テーブルの列数が十数個となる大きなテーブルにおいてもバリデーションチェックの所要時間を最大数十秒程度まで短縮することができ、解決と相成りました。
まとめ
本件はバックエンドの Lambda をマルチプロセスで動かせれば解決できるだろうという目論見が割と早くからあったものの、ちゃんとマルチプロセス処理を動かすのに思ったより時間がかかってしまいました。本件に関する Web 上の情報もかなり多いので裏を返すとそれだけニーズがあるようにも思えるのですが、実現に至らないのは Lambda のアーキテクチャ(実行環境)におけるアイソレーション絡みの話あたりが理由なのかなーと思います。
Lambda は水平方向にスケールする思想のサービスというのは認識しているのですが、今回のケースでその思想に素直に従うと、極端な話フロントエンド側が並列処理のコーディネータをするような実装にもなりかねないのがちょっとイマイチだなと思っていて。もちろん現実解は StepFunctions あたりを間に挟むような実装でしょうが、気合を入れてシャードしないといけないような計算コストの高い処理はともかく、今回のようなケースだと正直オーバースペック&かえって面倒に感じてしまいます。それこそ、その必要性が出てきてからの対応でも遅くないくらいというか。今回のようにちょっと頑張ればマルチプロセスで動かせるだけ全然マシなんですけど、やっぱりもうちょっと楽に実装できたらなあと個人的には思います。。
本記事がどなたかの役に立てば幸いです。
バックエンドに処理を移管することで、フロントエンド(tabulator)で処理していた場合と比較してデータ量の少ない/シンプルな定義のテーブルについてはトータルの処理時間が伸びてしまうケースもあります。ただ今回のケースではデータ量の多い/複雑な定義のテーブルについて処理時間を短縮すること(スループットを改善すること)がゴールであったため、そちらを優先しました。
また、本機能は実質的にオンラインバッチであるため、今まで(非常に)短かった処理時間が少々長くなったとしても機能要件は満たしていた(相対的にユーザに受け入れられやすかった)という点もあったと思います。前回のエントリで取り上げた更新差分情報の表示については、バックエンド側で更新差分の計算をした上でそれをフロントエンドで表示する処理が重かったためレスポンスの改善自体がゴールであり、本件とは少し事情が異なりました。