
今回はRaspberry Piのセンサーで取得したデータをAWS上で加工し、グラフ化してみたいと思います。
Raspberry Piで取得した気温・湿度のデータがAWS IoT Core等を通じて既にS3に入っている前提で、そのデータを加工していきます。
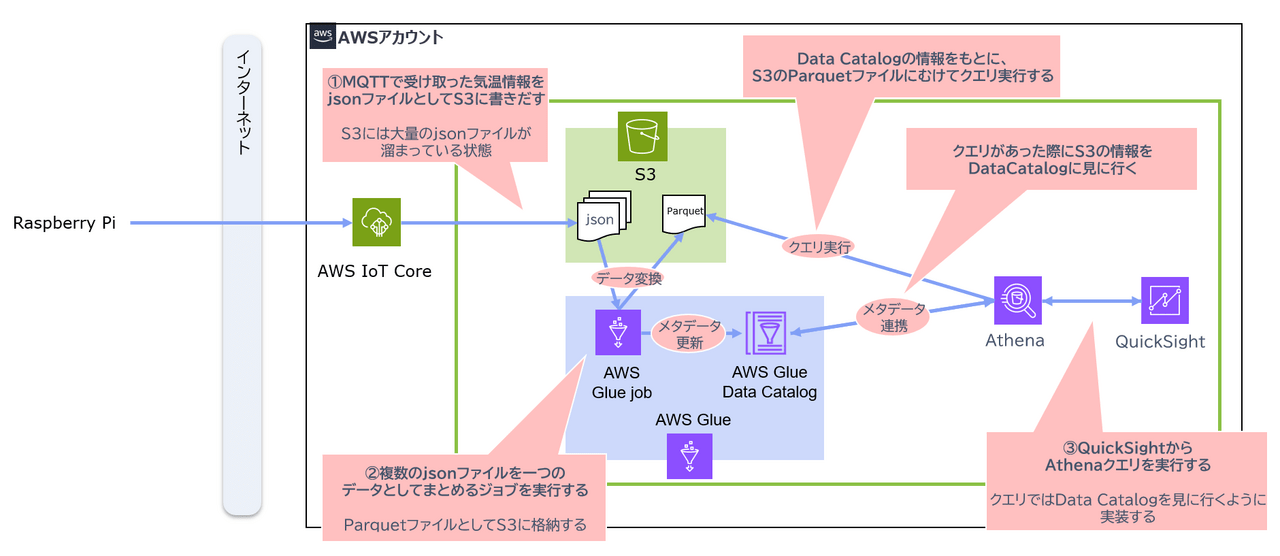
構成イメージ
今回構築するリソースと、データの流れは以下のイメージとなります。
構築してみる
S3にjsonファイルを書き出す
以下のように気温・湿度情報のデータをAWS IoTCore等を使用してRaspberry PiからS3に格納します。Raspberry PiからS3への接続方法については、本記事では割愛します。
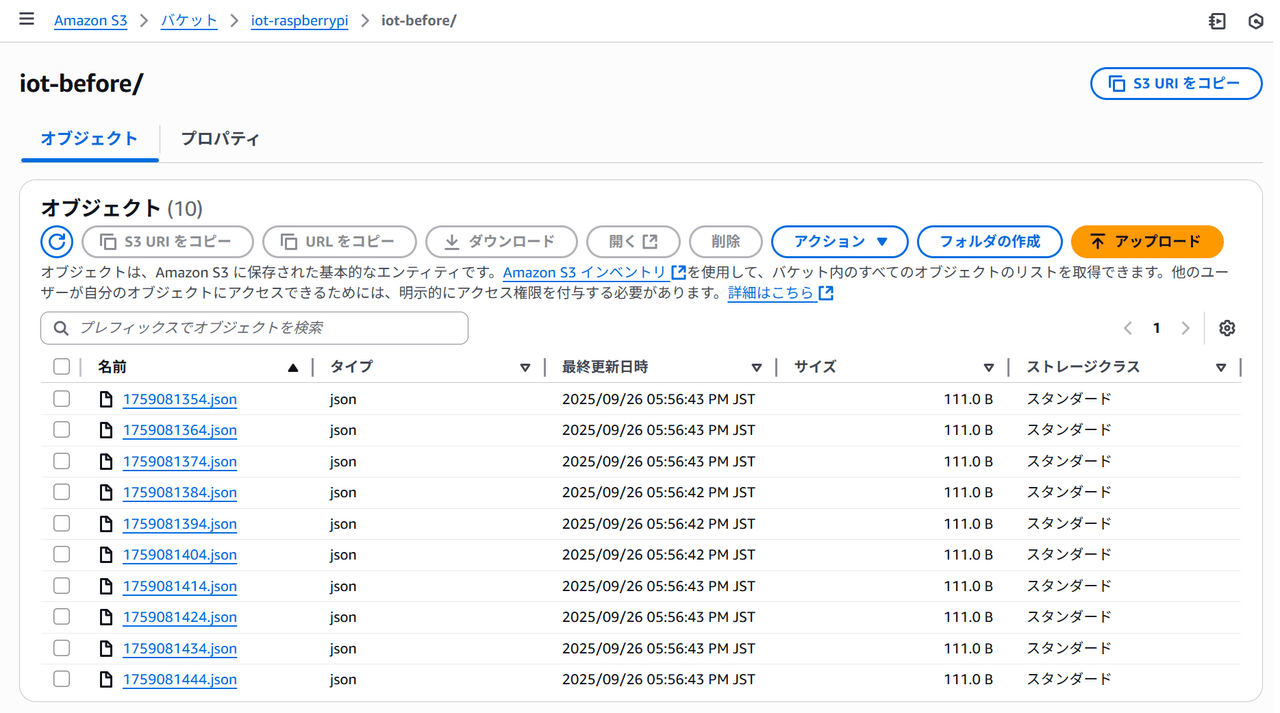
各ファイル内のデータは以下のような形式のデータとなっています。
{"thing_name": "my_dht22_sensor_pi5","timestamp": "2025-09-26 17:42:32","temperature_c": 25.3,"humidity": 60.5}
Glue jobで複数のjsonファイルをまとめる
Databaseを作成する
GlueのDatabasesから「Add database」をクリックします。

データベース名を入力して「Create database」をクリックします。
作成したデータベースの画面から、「Add table」をクリックします。
以下を入力して「Next」をクリックします。
- Name:任意のテーブル名
- Database:作成したデータベース名
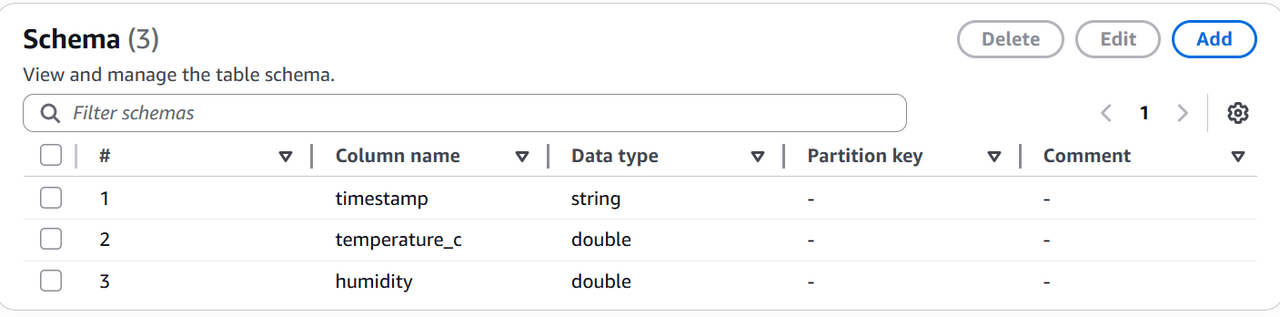
Schemaに以下を設定し「Next」をクリックします。
- timestamp:string
- temperature_c:double
- humidity:double
最終確認画面で、「Create」をクリックします。
Glue jobを作成する
Athenaで読み込みやすいように、①でS3に置かれている複数のjsonファイルをparquetファイルに成形するGlue jobを作成します。
Glueから「Script editor」をクリックし、EngineはSparkを選択して「Create script」をクリックします。
Scriptタブ
以下コードを入力します。各S3パス、Glue Data Catalog に登録するデータベース名とテーブル名は適宜変更してください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.sql import SparkSession
from awsglue.job import Job
from pyspark.sql.functions import *
from pyspark.sql.types import *
from awsglue.dynamicframe import DynamicFrame
# ジョブの引数を取得
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
# Spark および Glue のコンテキストを初期化
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# --- 設定 ---
# データのS3パス(Raspberry PiからIoT Core経由で来るJSON)
raw_data_path = "s3://iot-raspberrypi/iot-before/"
# 処理済みデータを保存するS3パス(Parquet形式)
processed_data_path = "s3://iot-raspberrypi/iot-after/"
# Glue Data Catalog に登録するデータベース名とテーブル名
glue_database_name = "raspberrypi"
glue_table_name = "raspberrypitable"
# --- データの読み込み ---
print(f"DEBUG: Attempting to read data from: {raw_data_path}")
# 明示的なスキーマを定義
source_schema = StructType([
StructField("thing_name", StringType(), True),
StructField("timestamp", LongType(), True),
StructField("temperature_c", DoubleType(), True),
StructField("humidity", DoubleType(), True)
])
datasource = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={"paths": [raw_data_path], "groupFiles": "inPartition"},
format="json",
format_options={"withHeader": "false", "inferSchema": "false"},
schema=source_schema,
transformation_ctx="datasource_raw"
)
df_raw = datasource.toDF()
# デバッグ出力(変更なし)
print("\nDEBUG: --- DataFrame Schema after reading JSON ---")
df_raw.printSchema()
print("\nDEBUG: --- First 5 rows of raw DataFrame (truncated=False) ---")
df_raw.show(5, truncate=False)
if "timestamp" in df_raw.columns:
print("\nDEBUG: --- Sample values of 'timestamp' column in df_raw ---")
df_raw.select("timestamp").limit(10).show(truncate=False)
if df_raw.count() == 0:
print("DEBUG: No new data to process. Exiting job.")
job.commit()
sys.exit(0)
print(f"DEBUG: Found {df_raw.count()} new records.")
# --- データ変換 ---
print("\nDEBUG: --- Starting timestamp conversion ---")
df_transformed = df_raw.withColumn(
"timestamp_seconds",
(col("timestamp") / 1000).cast(LongType())
).withColumn(
"timestamp_parsed",
from_unixtime(col("timestamp_seconds"))
)
# デバッグ出力
print("\nDEBUG: --- DataFrame Schema after timestamp conversion ---")
df_transformed.printSchema()
print("\nDEBUG: --- First 5 rows of transformed DataFrame (truncated=False) ---")
df_transformed.show(5, truncate=False)
# 最終的に保存したい列を選択
df_final = df_transformed.select(
col("timestamp"),
col("timestamp_parsed").alias("event_timestamp_utc"),
col("temperature_c"),
col("humidity")
)
# --- データの書き出しとGlue Data Catalogの更新 ---
print(f"Writing processed data to: {processed_data_path}")
processed_dynamic_frame = DynamicFrame.fromDF(df_final, glueContext, "processed_dynamic_frame")
glueContext.write_dynamic_frame.from_options(
frame=processed_dynamic_frame,
connection_type="s3",
connection_options={
"path": processed_data_path
},
format="parquet",
transformation_ctx="datasink",
)
job.commit()
print("Glue Job finished successfully.")
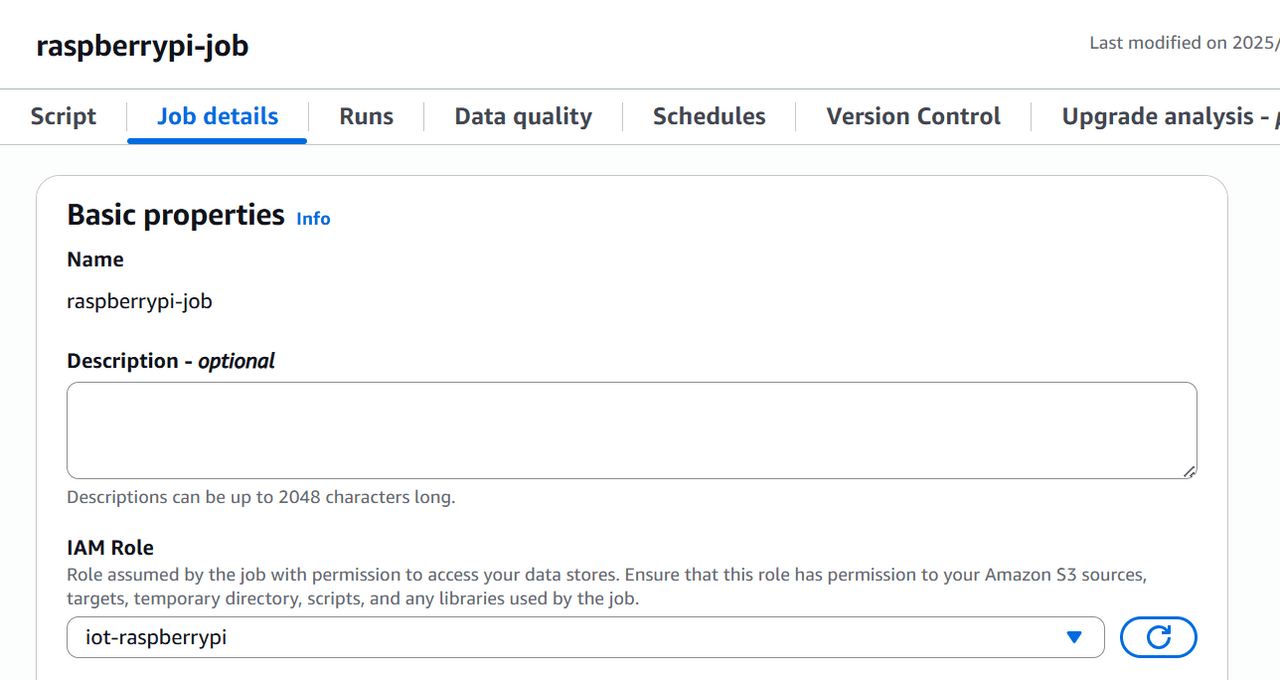
job detailsタブ
以下の値を設定します。
- Name:ジョブ名を任意の名前に指定します。
- IAM Role:S3バケットへの読み書き権限とAWSGlueServiceRoleが付与されたIAM Roleを作成し、アタッチします。
画面右上の「Save」ボタンをクリックします。
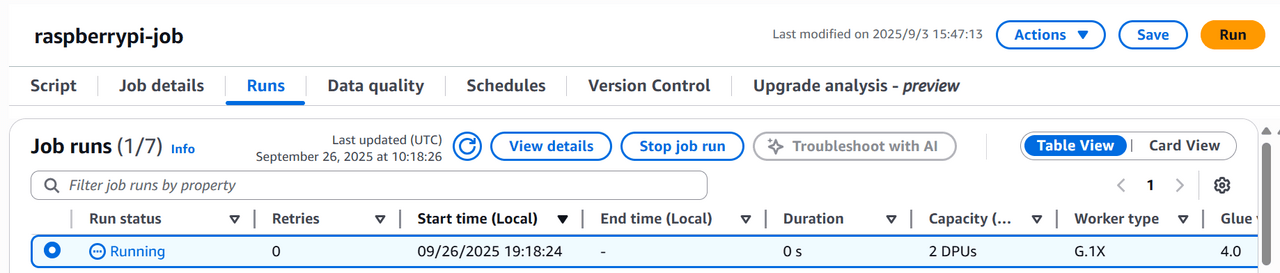
Runsタブ
右上の「Run」ボタンをクリックします。Job runs一覧に実行した履歴が出力されますので、画面リフレッシュしつつステータスがSuccessになるまで待ちます。
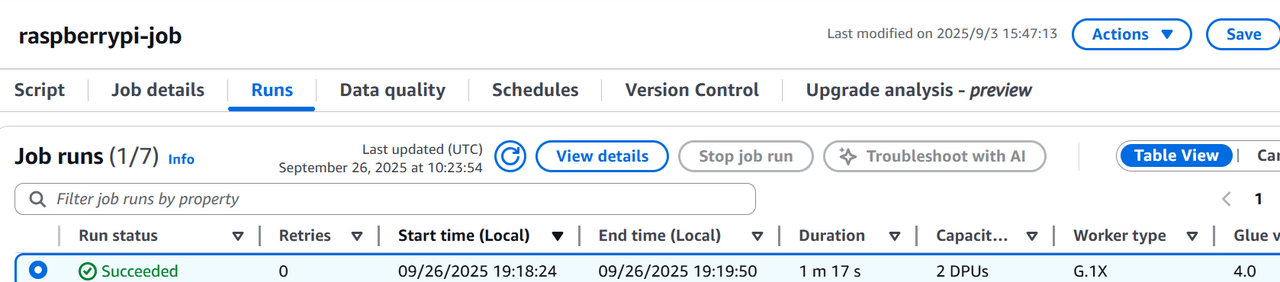
ステータスがSuccessになったらGluejobの設定は完了です。
Quicksightでグラフを作成する
データセットの作成
Quicksightアカウントにログインし、データセットタブから「新しいデータセットを作成」をクリックします。
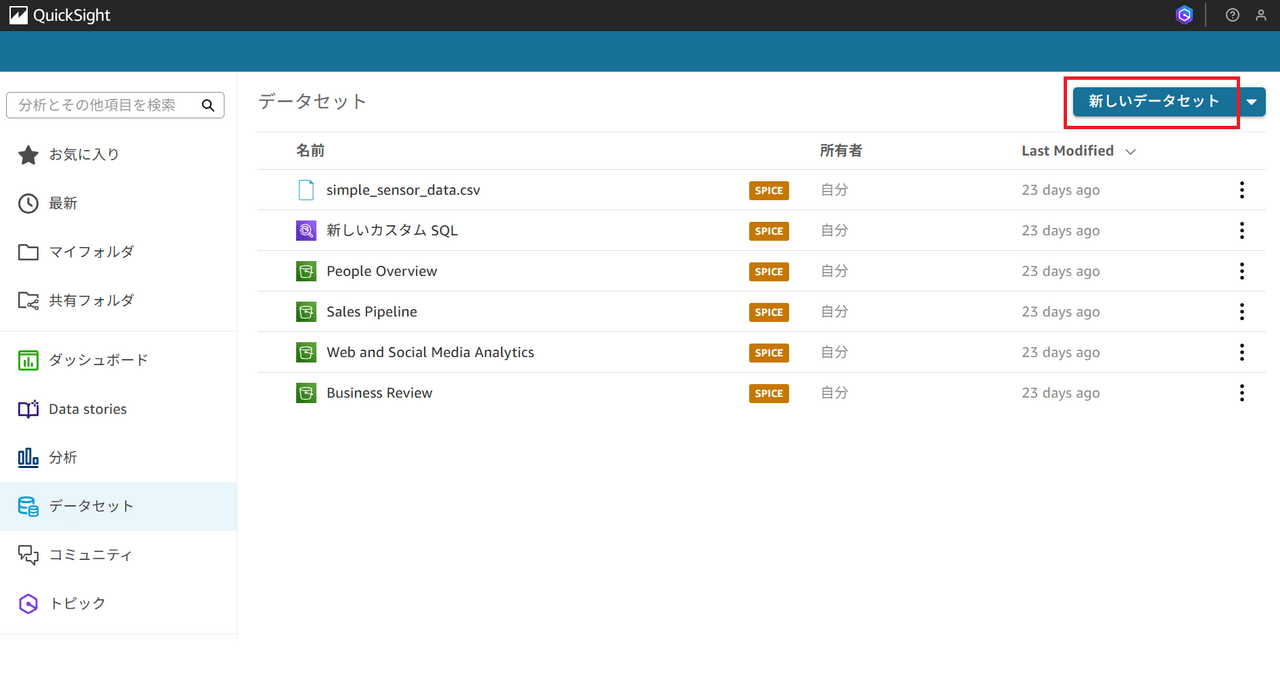
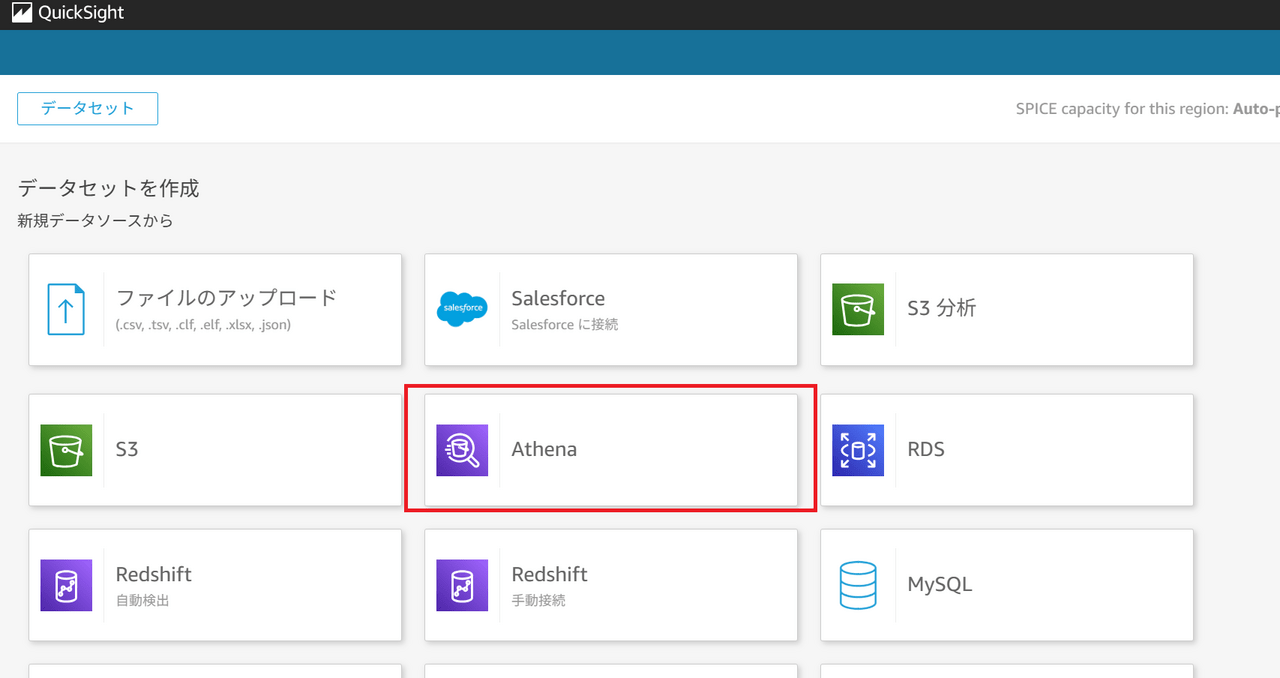
「Athena」をクリックします。
データソース名に任意の名前を入力して「データソースを作成」をクリックします。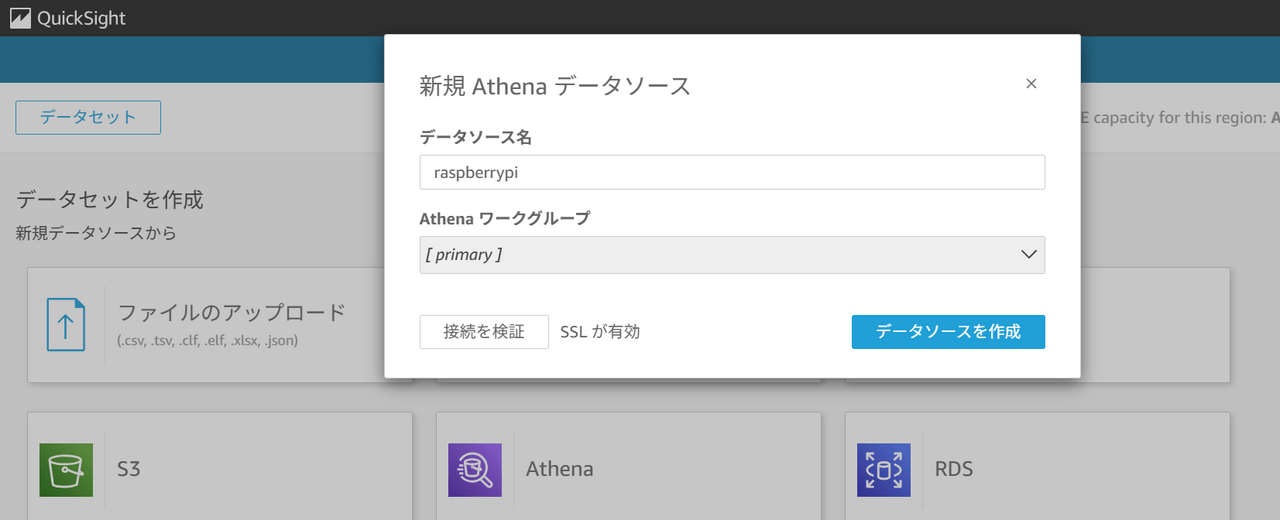
カタログはAwsDataCatalogを選択し、データベースとテーブルは②で作成したものを選択します。
「カスタムSQLを使用」をクリックします。
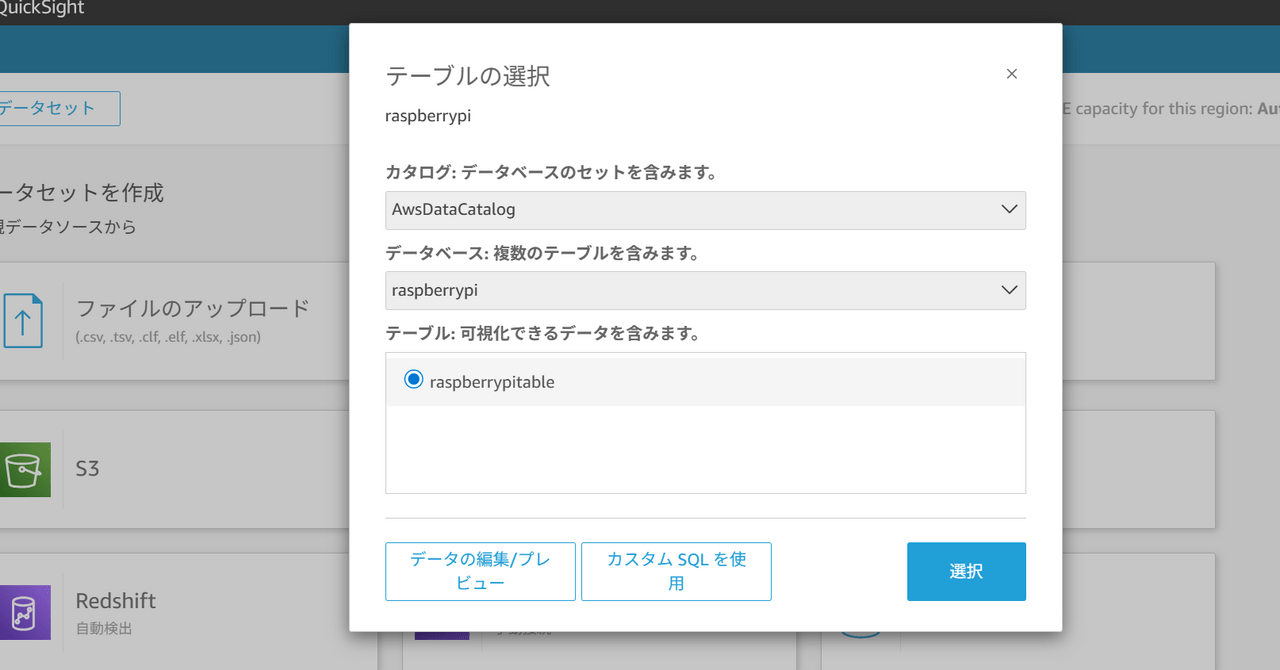
以下SQLを入力します。(データセット名、テーブル名は適宜変更してください)
SELECT CAST(timestamp AS TIMESTAMP) AS event_time_utc, temperature_c, humidity FROM "raspberrypi"."raspberrypitable"
「迅速な分析のためにSPICEへインポート」を選択して「Visualize」をクリックします。
分析の作成
そのまま以下の画面に遷移しますので、グラフを作成していきます。
以下を選択します。
- ビジュアルタイプ:折れ線グラフ
- X軸:event_time_utc
- Y軸:humidity、temperature_c
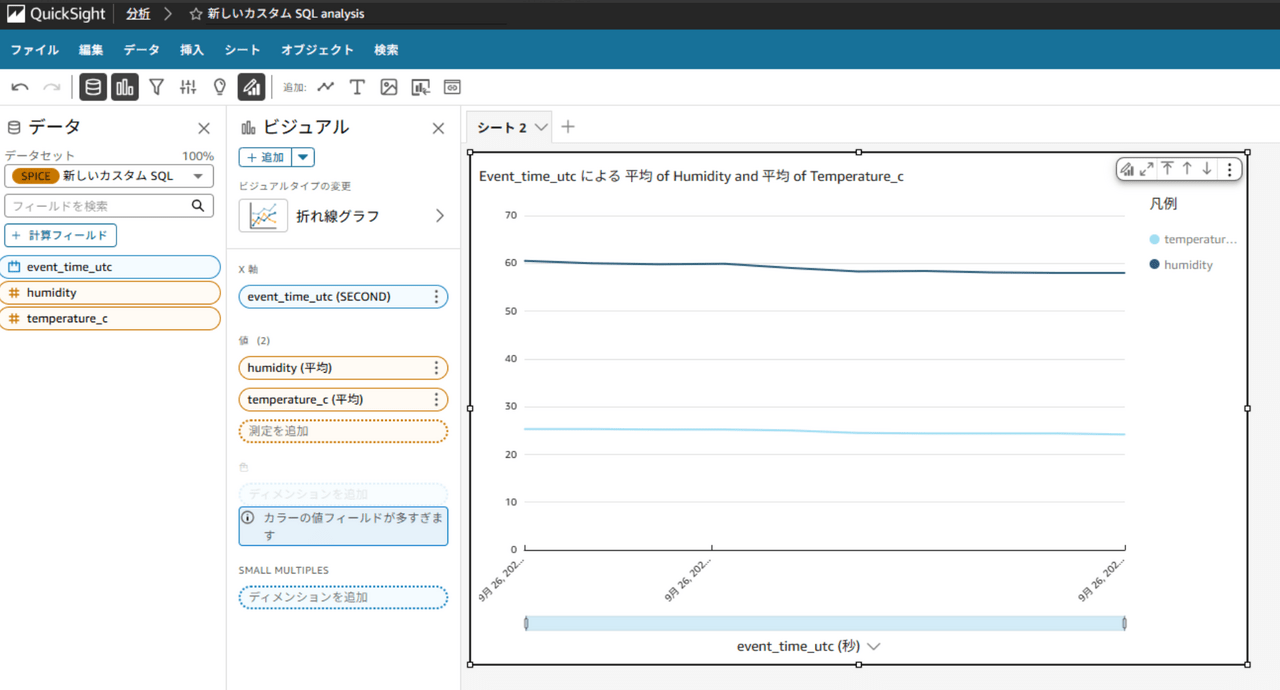
グラフが表示されました!
終わりに
今回はRaspberry Piで取得したデータをAWS上でグラフ化してみました。
気温・湿度情報をリアルタイムに取得するとなるとファイル数が膨大になるため、今回はGlue jobを使ってデータをまとめる方法で構築してみました。
Raspberry PiのようなIoTとAWSなどのクラウドサービスの掛け合わせについては、更に実用的な構築が無いか今後も検証してみたいと思います。