

こんにちは。SCSKの山口です。
今回は、BigQuery で機密データを扱う際に欠かせない「データマスキング」について書きます。
実装する中で、権限周りでかなり悩んだ部分もあったので記載しておきます。お役に立てると嬉しいです。
BigQuery のデータマスキング
概要
BigQuery では、「列レベルでのデータマスキング」をサポートしています。
この機能は「列レベルのアクセス制御」のベースの上に構築されているものなので、列レベルのアクセス制御を把握しておく必要があります。詳細は下記ブログをご参照ください。

下記手順で実装します。
- 分類と1つ以上のポリシータグを設定する
- ポリシータグのデータポリシーを構成する
- ポリシータグをBigQuery テーブルの列に割り当て、データポリシーを適用する
- マスクされたデータにアクセスできるユーザを、BigQuery のマスクされた読み取りロールに割り当てる
マスキングを実装すると、ユーザのロールに基づいてクエリの実行時にマスキングルールが自動的に適用されます。これはクエリに関する他のすべてのオペレーションよりも優先されます。
マスキングのルールに関しては、事前に用意された下記のルールから選択することができます。
使用可能なマスキングルール
使用可能なマスキングルールは以下の通りです。
- カスタムマスキングルーティン
- 年月日マスク
- デフォルトのマスキング値
- メールマスク
- 先頭/末尾の4文字
- Null化
カスタムマスキングルーティン
カスタムマスキングルーティンとは、「ユーザ定義関数(UDF)」を適用することにより、ユーザ独自のマスキングルールを実装する方法です。
カスタムマスキングルーティンでは、各種文字列関数の他、ハッシュ関数、日時関数など多くの関数が使用可能となっています。(詳細はこちら)
- 例)ユーザの社会保障番号を「XXX-XX-XXXX」に置き換えるマスキングルーティン
CREATE OR REPLACE FUNCTION SSN_Mask(ssn STRING) RETURNS STRING OPTIONS (data_governance_type="DATA_MASKING") AS ( SAFE.REGEXP_REPLACE(ssn, '[0-9]', 'X') # 123-45-6789 -> XXX-XX-XXXX );
年月日マスク
データ内の年以降の情報を切り捨てるマスキングルールです。
DATE,DATETIME,TIMESTAMP型のデータに対してのみ使用できます。
| 種類 | 元の値 | マスク後の値 |
|---|---|---|
DATE |
2030-07-17 | 2030-01-01 |
DATETIME |
2030-07-17T01:45:06 | 2030-01-01T00:00:00 |
TIMESTAMP |
2030-07-17 01:45:06 | 2030-01-01 00:00:00 |
デフォルトのマスキング値
対象の列のデータ型に基づいて、あらかじめ定められているデフォルトのマスキング値を返します。
| データ型 | デフォルトのマスキング値 |
|---|---|
STRING |
“” |
BYTES |
b” |
INTEGER |
0 |
FLOAT |
0.0 |
NUMERIC |
0 |
BOOLEAN |
FALSE |
TIMESTAMP |
1970-01-01 00:00:00 UTC |
DATE |
1970-01-01 |
TIME |
00:00:00 |
DATETIME |
1970-01-01T00:00:00 |
GEOGRAPHY |
POINT(0 0) |
BIGNUMERIC |
0 |
ARRAY |
[] |
STRUCT |
NOT_APPLICABLE
ポリシータグは、 |
JSON |
null |
メールマスク
有効なメールアドレスのアカウント部分(@より前)を「XXXXX」に置き換えます。
有効なメールアドレスでない場合は、SHA-256ハッシュ関数を使用してハッシュ化された値に置き換えます。
STRING型のデータにのみ使用できます。
| 元の値 | マスク後の値 |
|---|---|
abc123@gmail.com |
XXXXX@gmail.com |
randomtext |
jQHDyQuj7vJcveEe59ygb3Zcvj0B5FJINBzgM6Bypgw= |
test@gmail@gmail.com |
Qdje6MO+GLwI0u+KyRyAICDjHbLF1ImxRqaW08tY52k= |
先頭/末尾の4文字
先頭(末尾)を返し、文字列の残りの部分を「XXXXX」に置き換えます。
文字列の長さが4文字以下の場合は、SHA-256ハッシュ関数を使用してハッシュ化された値に置き換えます。
STRING型のデータにのみ使用できます。
| 元の値 | 先頭の4文字 | 末尾の4文字 |
|---|---|---|
| example | XXXXple | exaXXXX |
| rei | 80a23528c754a504894e9747d7df4fde20e937d3e9e63a86c001eecb0908b46 | 80a23528c754a504894e9747d7df4fde20e937d3e9e63a86c001eecb0908b46 |
Null化
列の値の代わりに「NULL」を返します。
列の値に加えて、データ型も非表示にしたい場合に有効です。
実践:データマスキング
ここからは実際にデータをマスキングしていきます。
下記テーブルを使用します。
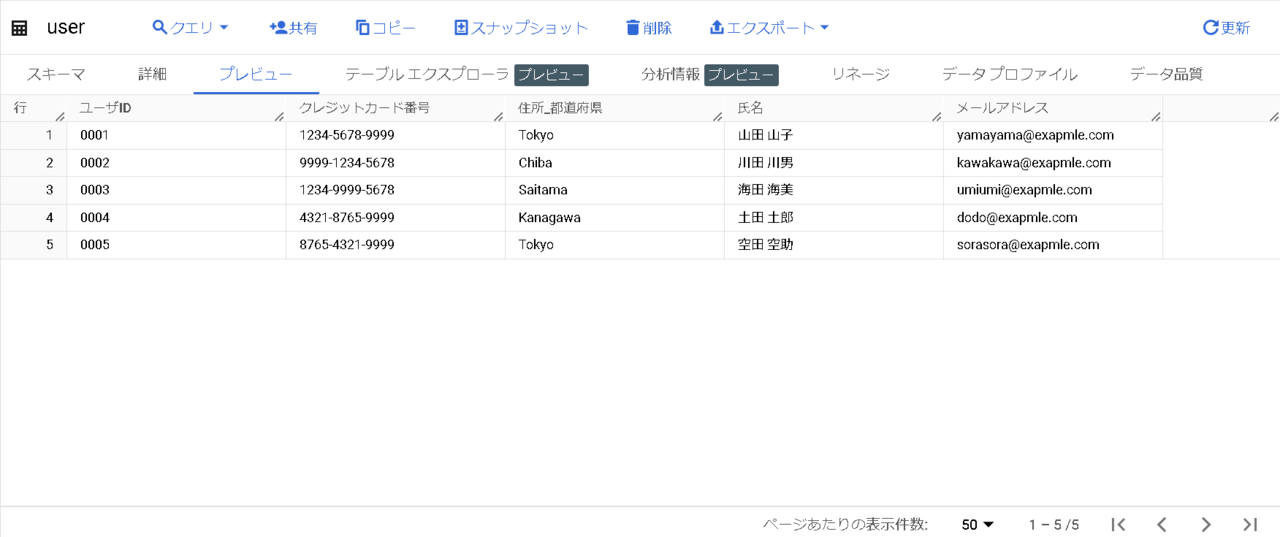
今回は、「クレジットカード番号」と「メールアドレス」をマスキングします。
また、事前にAdminユーザとMemberユーザの2つを用意し、それぞれの作業で分けて説明します。
Admin:分類の作成
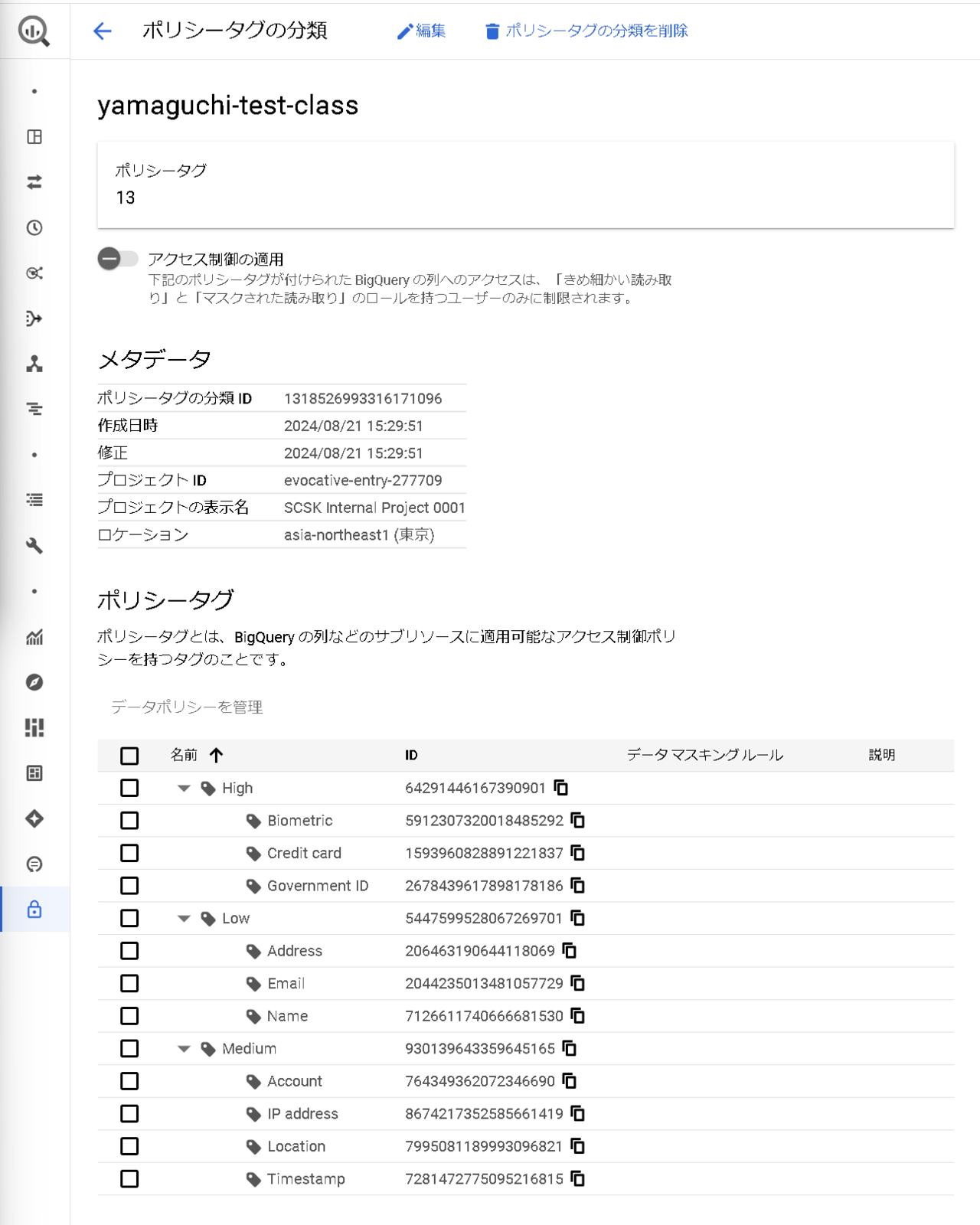
まず分類を作成する必要があります。
今回は、BigQuery のアクセス制御のブログで作成した下記分類を再利用します。
文類の作成方法についてはこちらのブログをご参照ください。
Admin:カスタムマスキングルーティンを作成する
次に、クレジットカード番号をマスキングするためのカスタムマスキングルーティンを作成します。
下記クエリを実行し、UDFを作成します。
CREATE OR REPLACE FUNCTION yamaguchi_test_acctrl.SSN_Mask(ssn STRING) RETURNS STRING OPTIONS (data_governance_type="DATA_MASKING") AS ( SAFE.REGEXP_REPLACE(ssn, '[0-9]', 'X') # 123-45-6789 -> XXX-XX-XXXX );
Admin:データポリシーを作成する
分類が準備できたら、次にデータポリシーを作成します。
- BigQuery画面の左ペインから「管理」-「ポリシータグ」を選択し、対象のポリシータグを選択した状態で「データポリシーを管理」をクリック
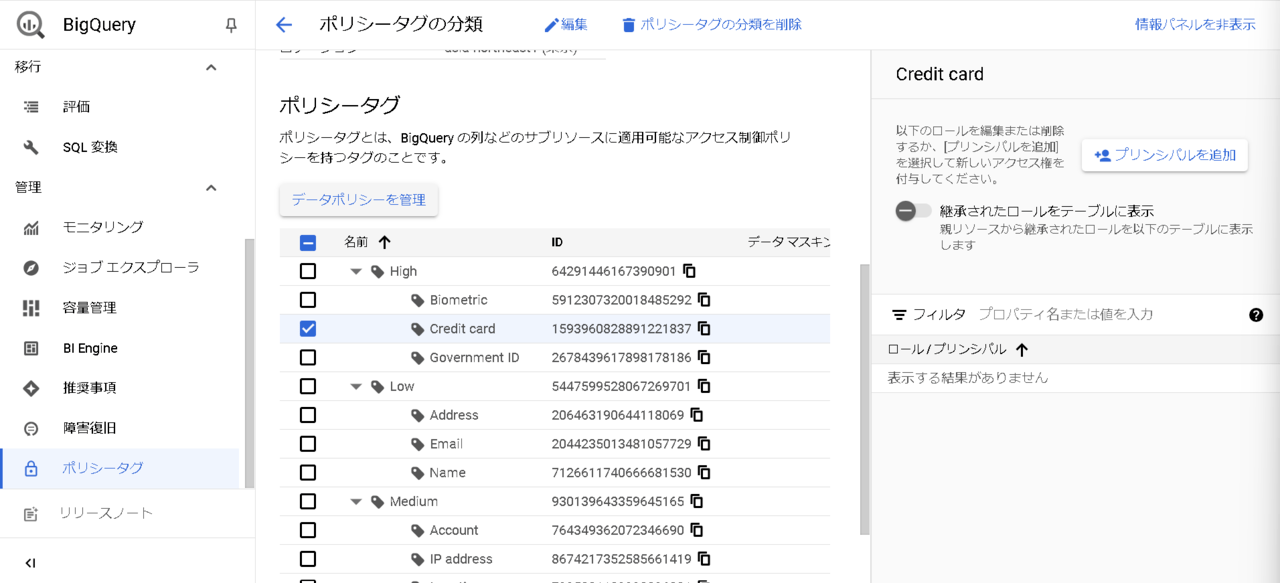
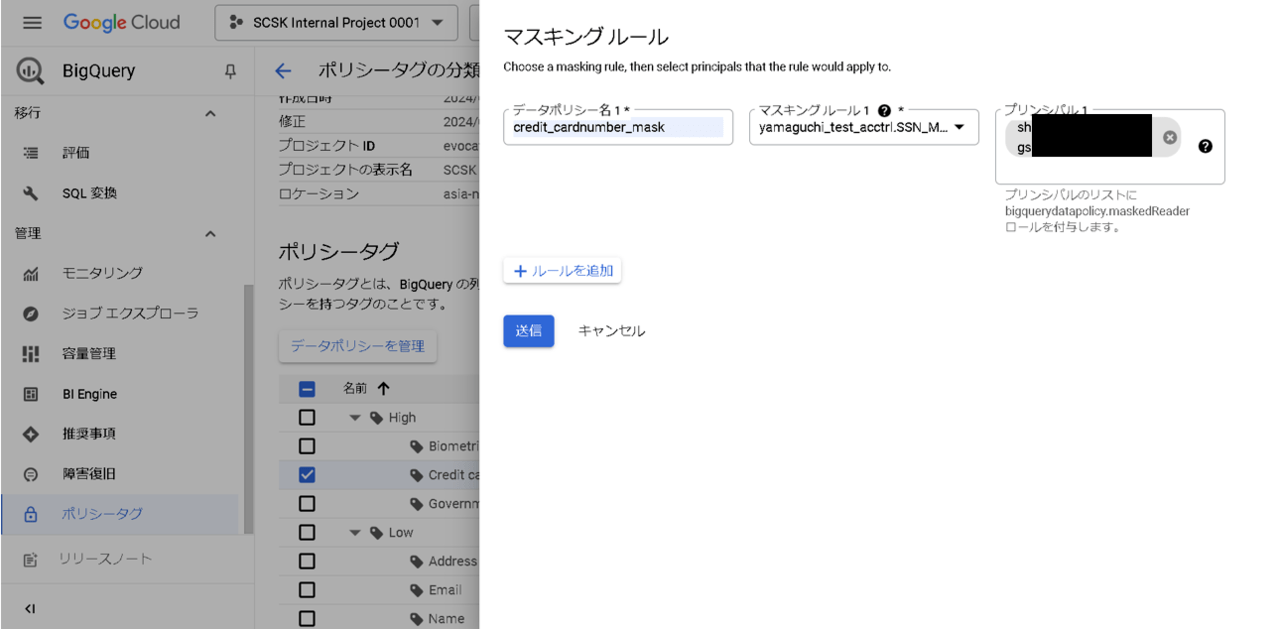
[クレジットカード番号:カスタムマスキングルーティン]
-
- 先ほど作成したルールを選択
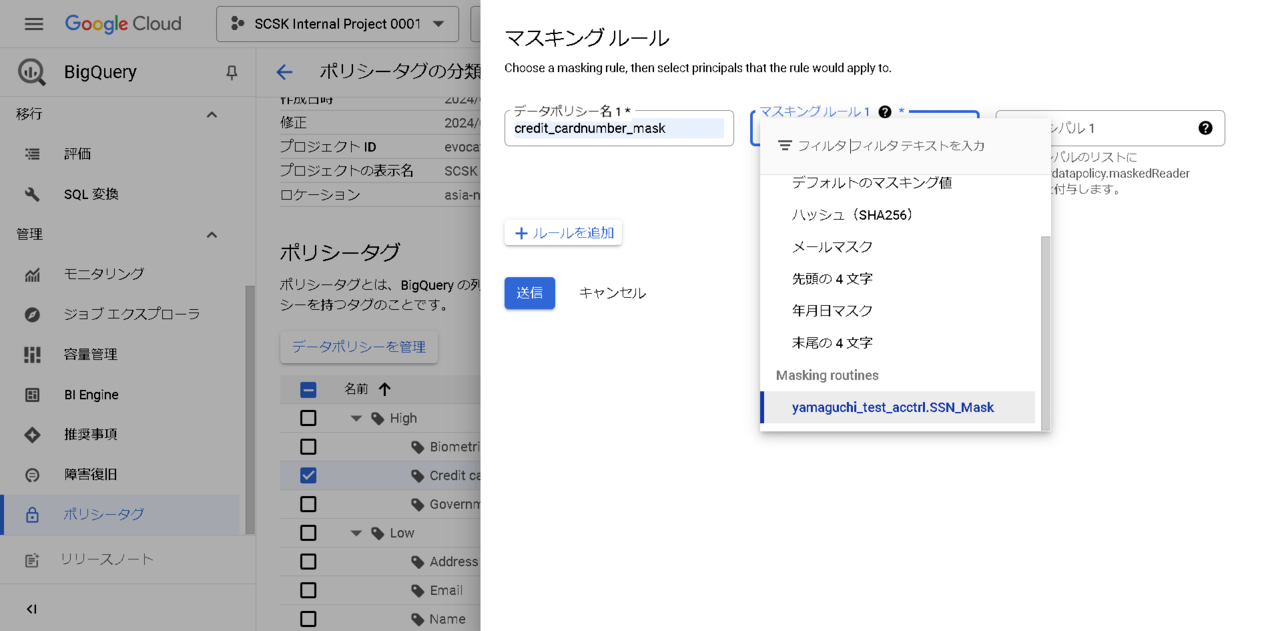
-
- 「プリンシパル」にマスキングルールを適用させたいユーザアカウントを入力
- [メールアドレス:メールマスク]
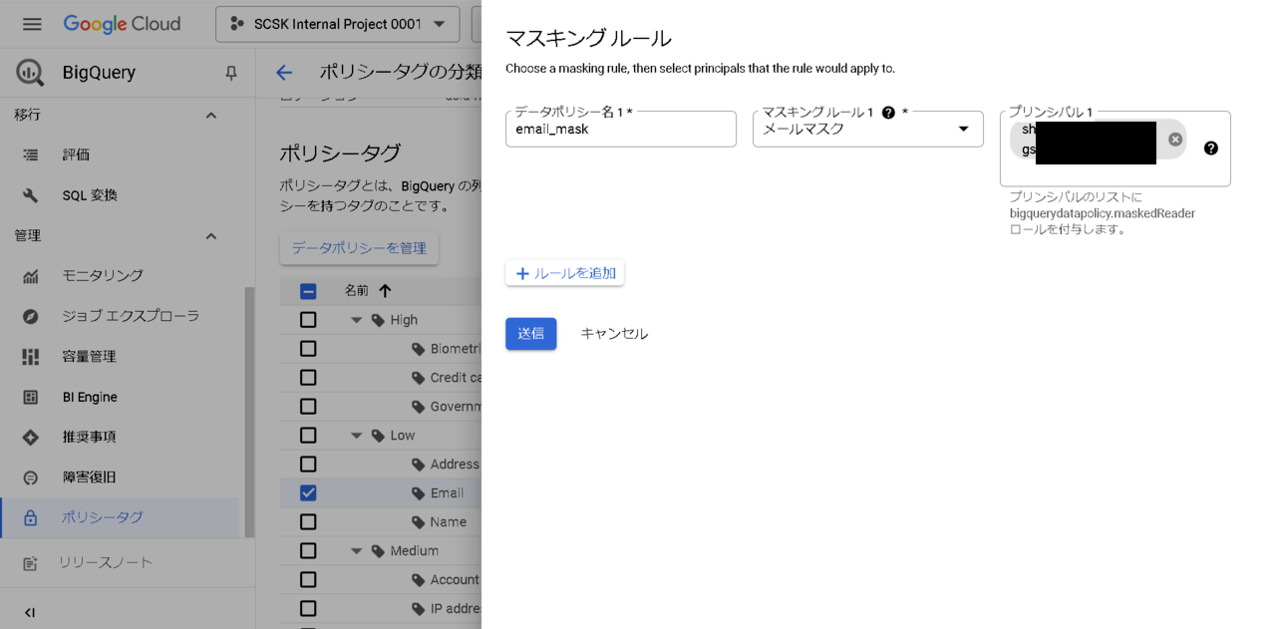
ここまででデータポリシーの作成は完了です。
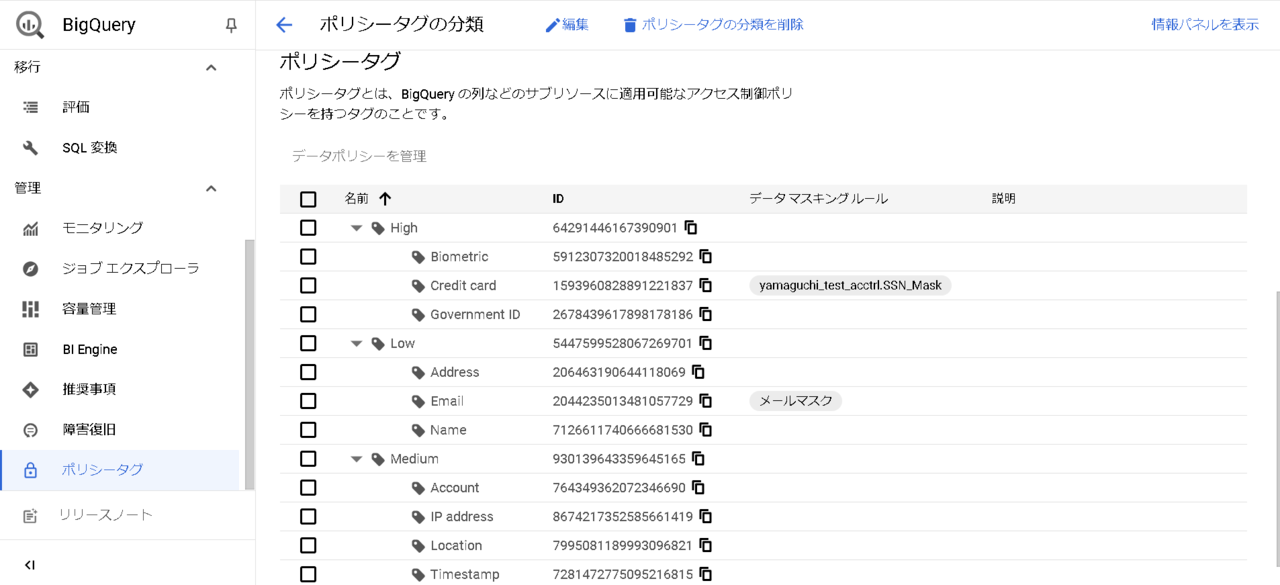
Admin:ポリシータグを列に設定する
この作業は、BigQuery のアクセス制御のブログで作成した設定を再利用します。
設定方法の詳細についてはこちらのブログをご参照ください。
- BigQueryの対象テーブルの「スキーマ」ペインで「スキーマの編集」をクリック
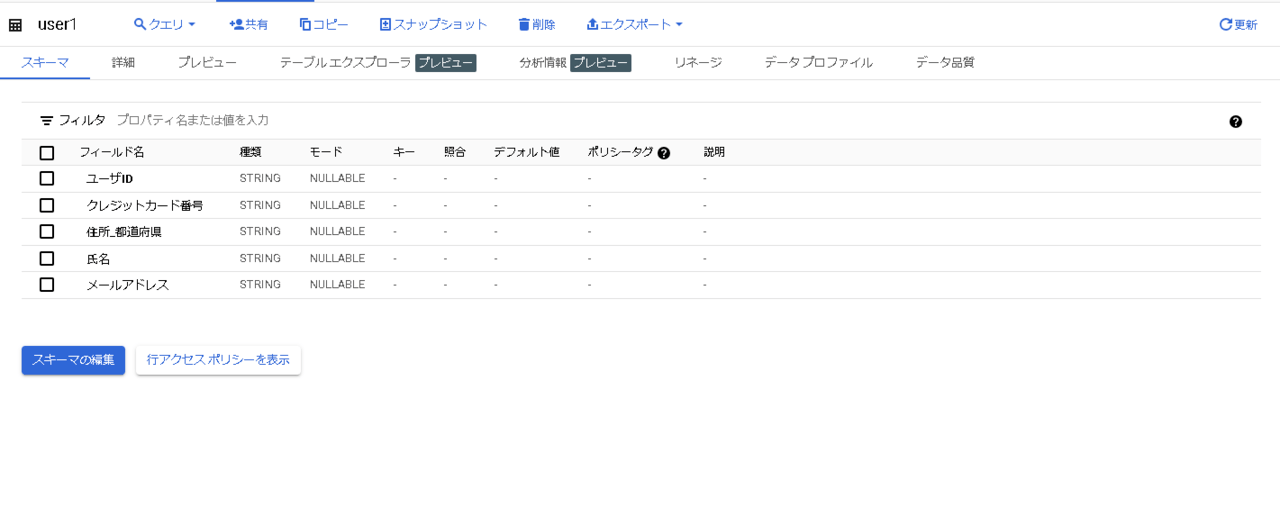
- 対象スキーマを選択した状態で「ADD POLICY TAG」をクリック
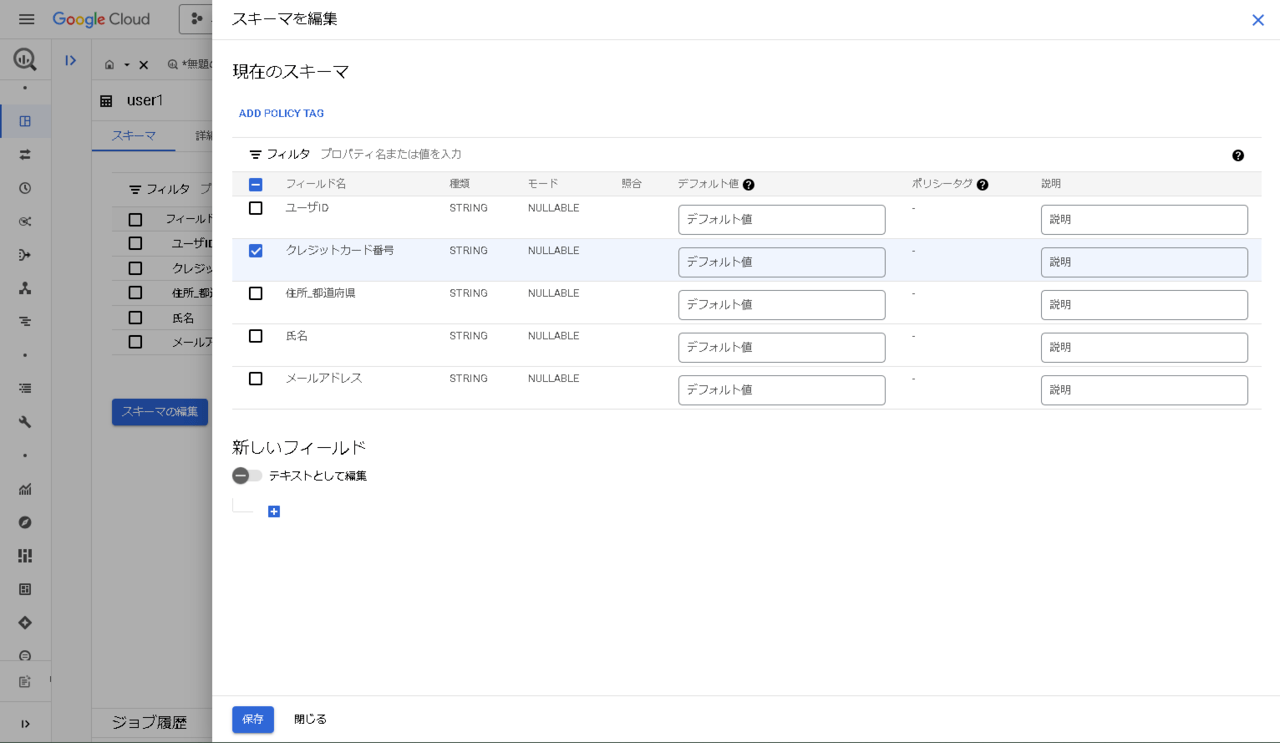
- 対象スキーマに設定するポリシータグを選択する
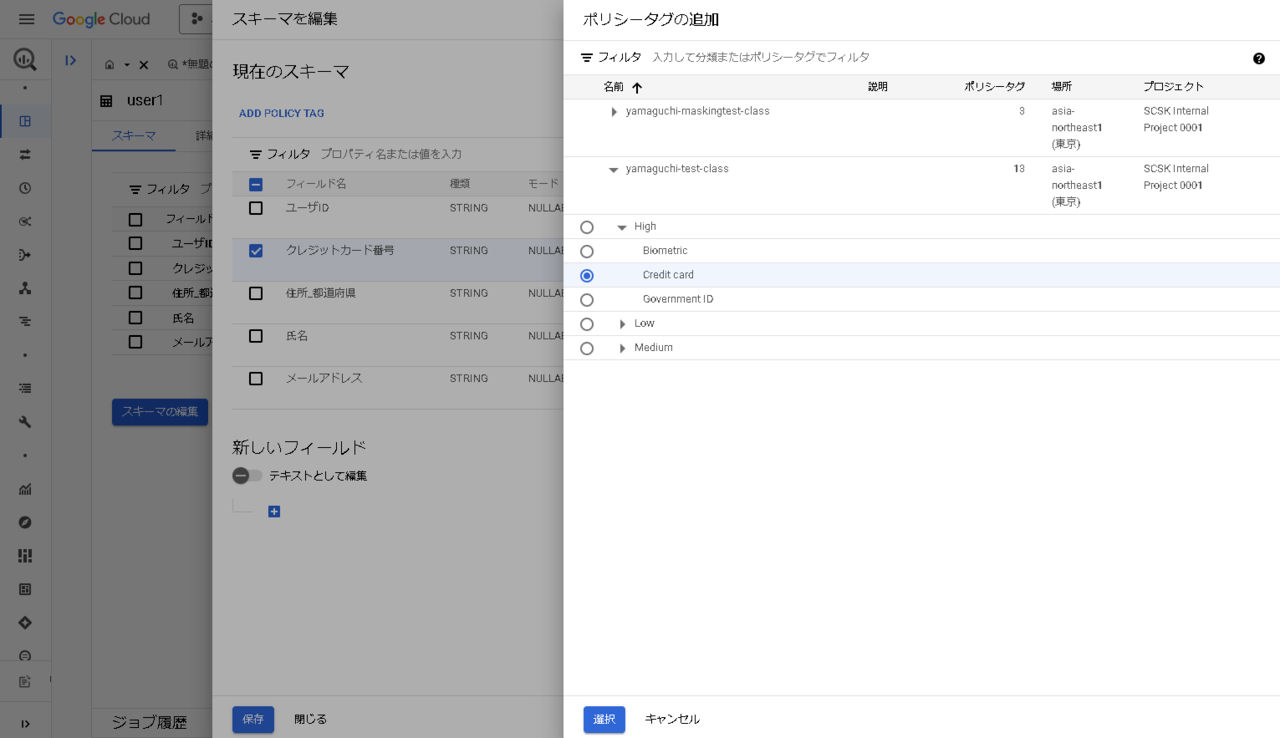
設定完了するとこんな感じになります。
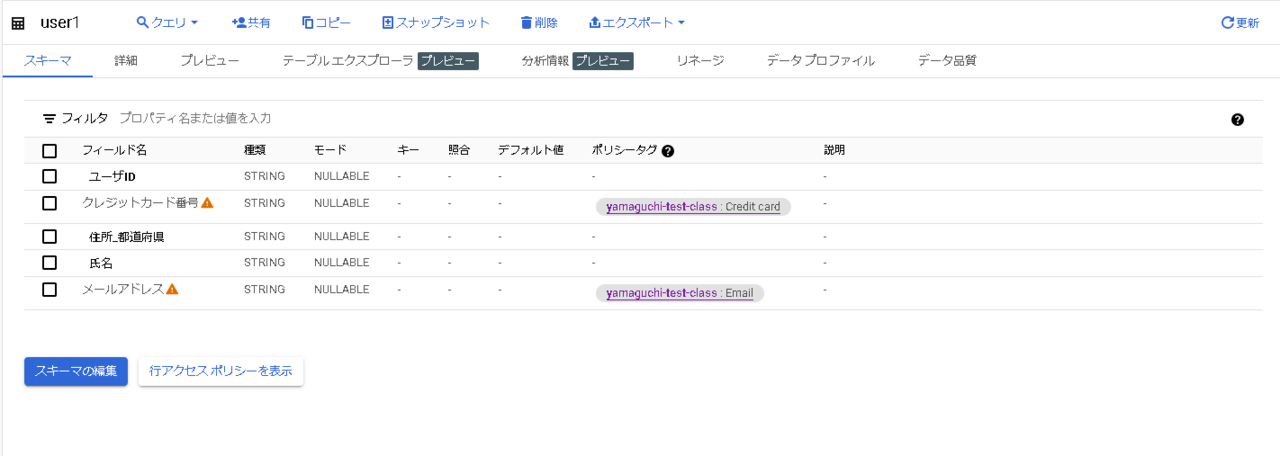
ここまででAdmin側での設定作業は完了です。
Member:テーブルデータ確認
Memberユーザでテーブルのプレビューを見てみます。
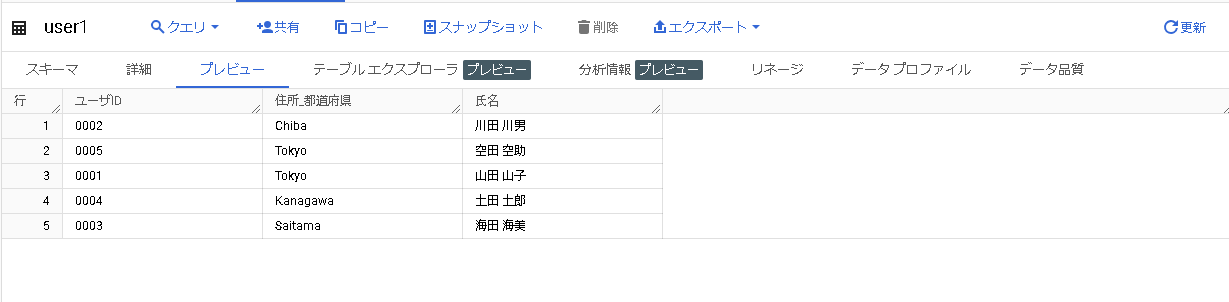
今回マスキングを設定したスキーマのデータが表示されなくなりました。
クエリを投げてデータを見てみます。
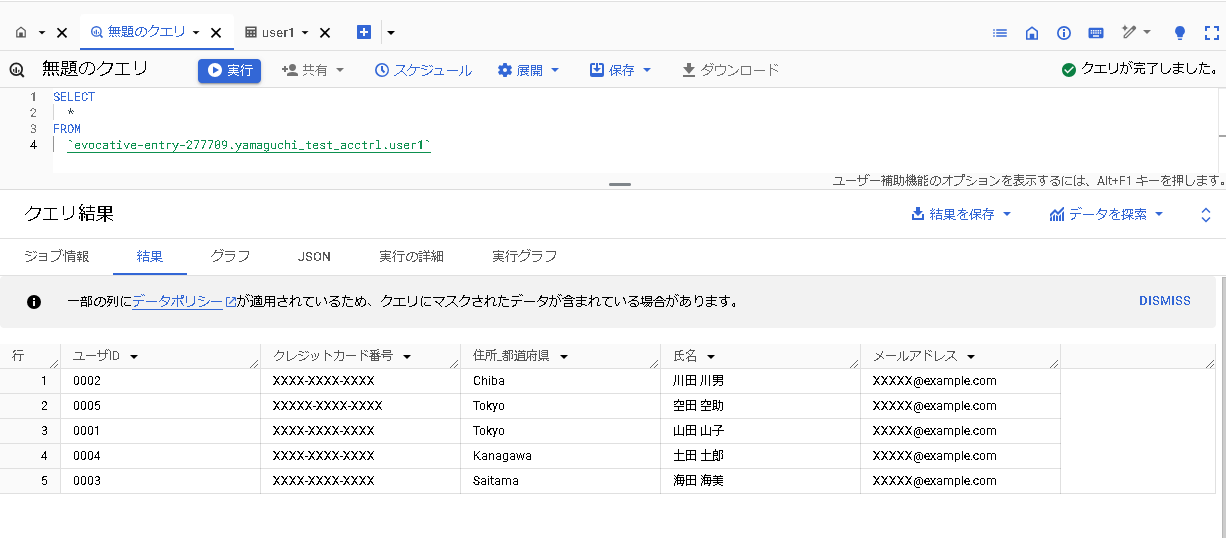
対象スキーマのデータがマスキングされた状態で表示されました。大成功です。
悩んだ点
冒頭にも書きましたが、マスキングがうまくいかず、半日くらい悩まされました。
結果として、権限の設定が原因でした。
今回登場する権限(ロール)は下記の二つです。
・マスクされた読み取りロール ・きめ細かい読み取りロール
公式ドキュメントを参考に下記の手順を実行しました。

結論として、2の「きめ細かい読み取り」ロールを、マスキングしたデータを見せたいMemberのアカウントに付与していたことが原因で、マスキングが適用されていませんでした。
各ロールの仕組みのドキュメントを見ると、下記記載があります。

図にすると以下の通りです。
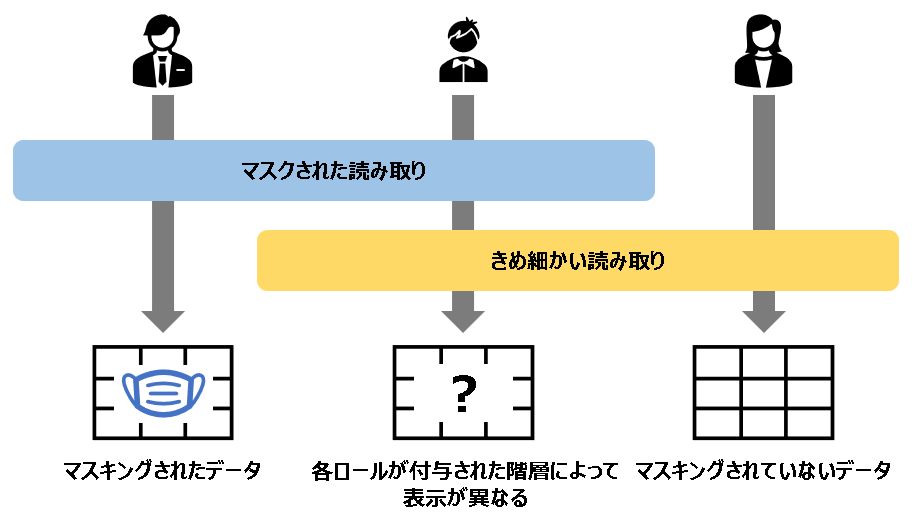
マスキングされたデータを見せたいユーザに対しては、マスクされた読み取りロールのみを付与するか、マスクされた読み取りロールが優位に働くようにする必要があります。
今回は、二つのロールを同じポリシータグ内で付与してしまっていたため、マスキングされたデータが表示されませんでした。
ちなみに、「マスクされた読み取りロール」はマスキングルールとプリンシパルを紐づける操作の際に自動的に付与されます。
公式ドキュメントに記載のあるベストプラクティスは、「データポリシー レベルでBigQuery のマスクされた読み取りロールを割り当てること」です。プロジェクトレベル以上でロールを割り当てると、プロジェクト内のすべてのデータポリシーに対する権限がユーザーに付与され、過剰な権限による問題の原因となります。
まとめ
今回はBigQueryのデータマスキングについて書きました。
今回はあらかじめ用意しておいたデータに対してマスキングを行いましたが、設定以降に入ってきたデータに対してももちろんマスキングが実行されます。都度設定する必要がないので大変便利ですね。
今回紹介したマスキングや前回のブログで紹介したアクセス制御に関しては、「分類やポリシーの設計」がとても重要になると思います。
また、データマスキングを列レベルのアクセス制御と組み合わせて使用することで、さまざまなユーザーグループのニーズに基づいたアクセス範囲を構成できます。
BigQueryの列レベルのアクセス制御に関しては、こちらのブログをご覧ください。