

こんにちは。SCSKの山口です。
BigQueryのビュー機能、皆さん使いこなせていますか???
BigQueryは優れた処理能力と柔軟性を持ち、大量のデータ分析を効率的に使用できるDWHサービスです。
そんな BigQuery をさらに便利にする機能の一つが 「ビュー (View)」 です。ビューは、データベースに存在する仮想的なテーブルのように振る舞いますが、実際にはデータを物理的に保存しません。このことによってさまざまなメリットを生み出します。
この記事では、BigQuery のビュー機能の基本的な概念から、具体的な活用例、そして知っておくべき重要なポイントまでを徹底解説します。今回ご紹介するビュー機能を使いこなすことで、
- 複雑なクエリをシンプルにする
- 特定のデータだけを安全に共有する
- データ分析のワークフローを効率化する
事ができます。
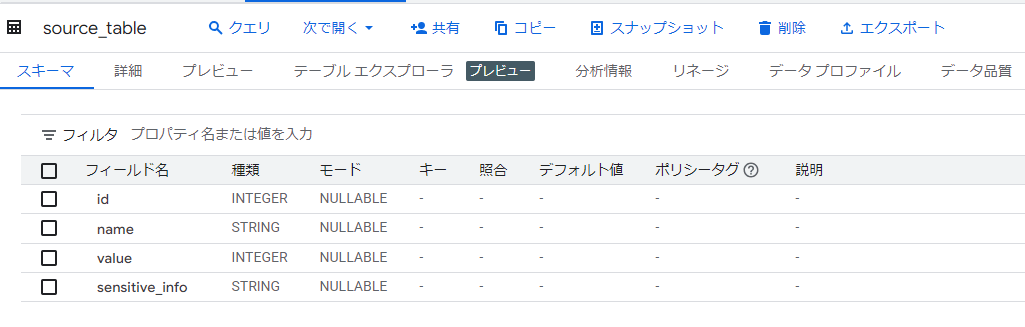
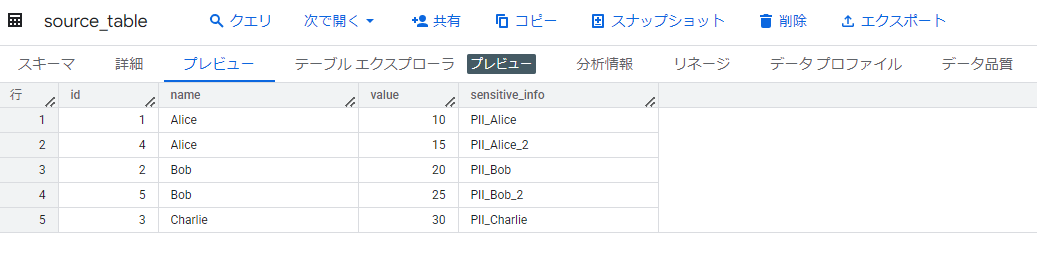
使用データ
今回検証で使用するデータです。
- データセット名:yamaguchi_test_views
- テーブル名:source_table
①標準ビュー
ビュー作成方法
下記クエリを実行し、作成します。
-- ビュー作成クエリ CREATE OR REPLACE VIEW `yamaguchi_test_views.name_value_sum_view` AS SELECT name, SUM(value) AS total_value FROM `yamaguchi_test_views.source_table` GROUP BY name;
重要なところを一般化します。
-- ビュー作成クエリ構文 CREATE OR REPLACE VIEW `[プロジェクトID].[データセット名].[ビュー名]` AS SELECT column1, column2, ... FROM `[プロジェクトID].[データセット名].[テーブル名]` WHERE condition;
- CREATE OR REPLACE VIEW:ビューを新規作成もしくは置き換えます
- AS:以降にビューの定義を開始します
- SELECT colmun…:ビューに含める列を指定します
- FROM:ビューの元となるテーブルを指定します
- WHERE(省略可):ビューに含める行をフィルタリングするための条件を指定します
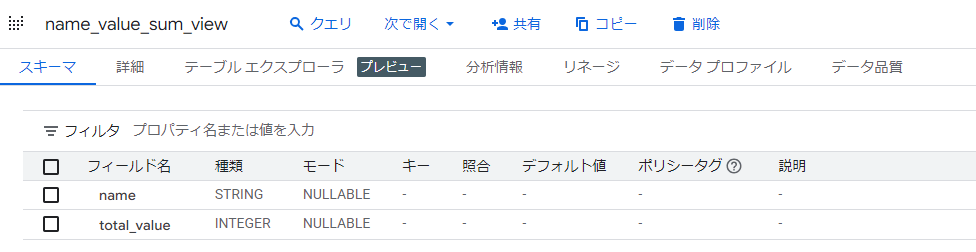
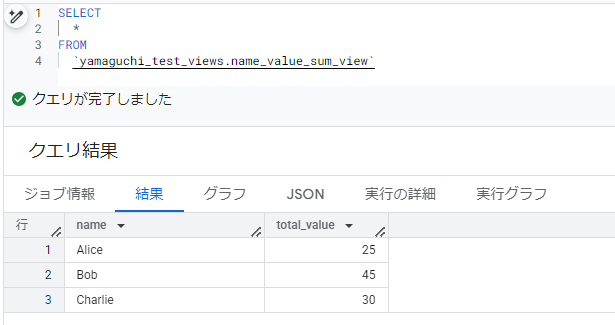
ビュー作成クエリで出来上がったビューが下記です。
データ確認
ビューは、物理的にデータを保持するテーブルとは異なり、仮想テーブル的な振る舞いをするので、「プレビュー」タブからデータを確認できません。なので、データを確認するにはSELECTクエリを発行する必要があります。
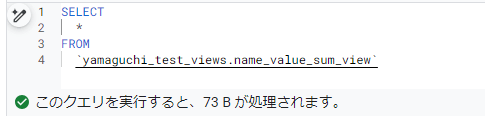
※仮想テーブルとはいえ、しっかりクエリ量は発生するのでご注意ください。
メリット
標準ビューを使うことによるメリットを書きます。
複雑なクエリを簡略化
今回は簡単なSQLで試しましたが、複数テーブルを結合したり、複雑な条件でフィルタリングしたりといった、複雑なクエリが実業務には登場します。
この複雑なクエリをあらかじめ標準ビューとして定義しておくことで、ユーザはビューに単純なSELECT文を発行するだけでデータアクセスできます。
今回の例でいうと、
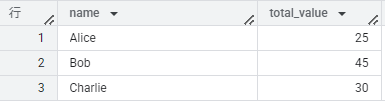
上記データを見るために必要になるクエリが、事前のビュー定義の有無で変わってきます。
| ビュー無 | ビュー有 |
SELECT name, SUM(value) AS total_value FROM `yamaguchi_test_views.source_table` GROUP BY name; |
SELECT * FROM `yamaguchi_test_views.name_value_sum_view` |
どちらが楽か、、、一目瞭然ですね。
データアクセスを論理的に分離
特定のビジネスロジックに基づいたデータのまとまりをビューとして提供することが可能なので、元となるテーブルを意識することなくデータを利用可能になります。
大切な元テーブルのデータに直接アクセスされることなくデータを共有できるので、セキュリティの観点からもメリットが大きいです。
レポート作成の効率化
レポートを作成する際、必要なデータをあらかじめ整形済みのビューとして作成しておくことで、レポート作成ツールからのクエリを簡潔にすることができます。
例えば、Looker等でダッシュボードを作る際に、開発効率を向上させることができます。
➁承認済みビュー
ビュー作成方法
今回はソーステーブルと同じデータセット(yamaguchi_test_views)に承認済みビューを作成します。
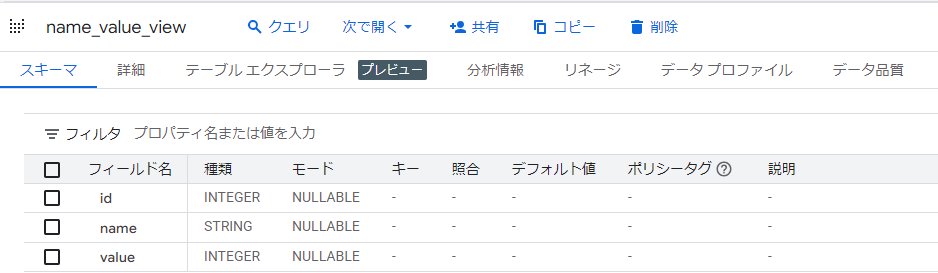
まずは、標準ビューと同じクエリ構文でビューを作成します。
CREATE VIEW `yamaguchi_test_views.name_value_view` AS SELECT id, name, value FROM `yamaguchi_test_views.source_table`;
次に「ビューの承認設定」を行います。
対象のビューが含まれるデータセットの「共有」タブから「ビューを承認」をクリックします。
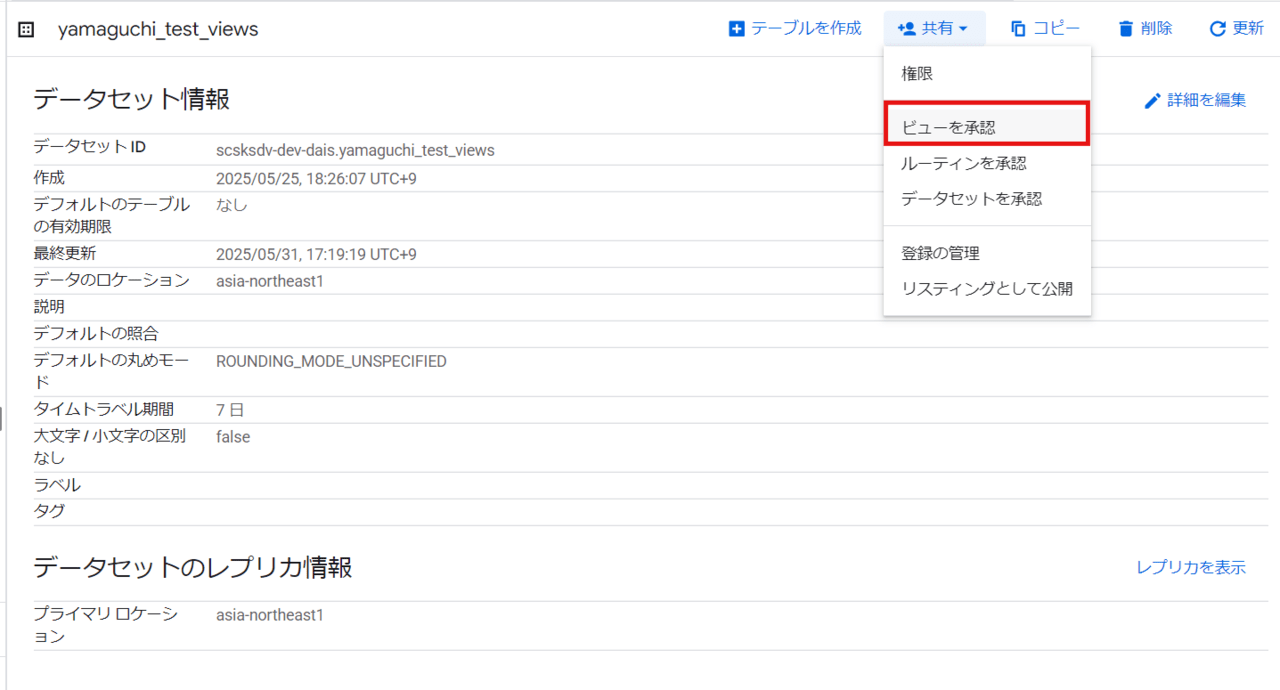
※対象ビューではなく「データセット」からの作業であることに注意してください。
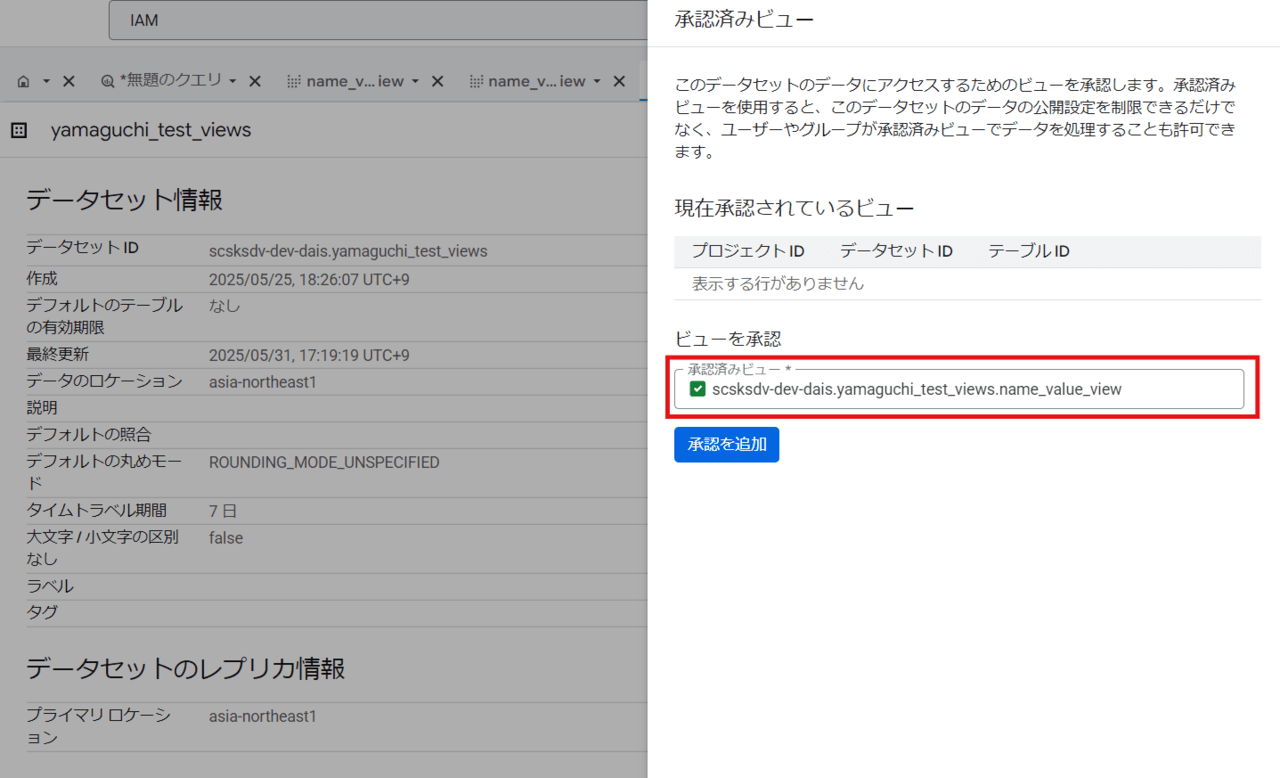
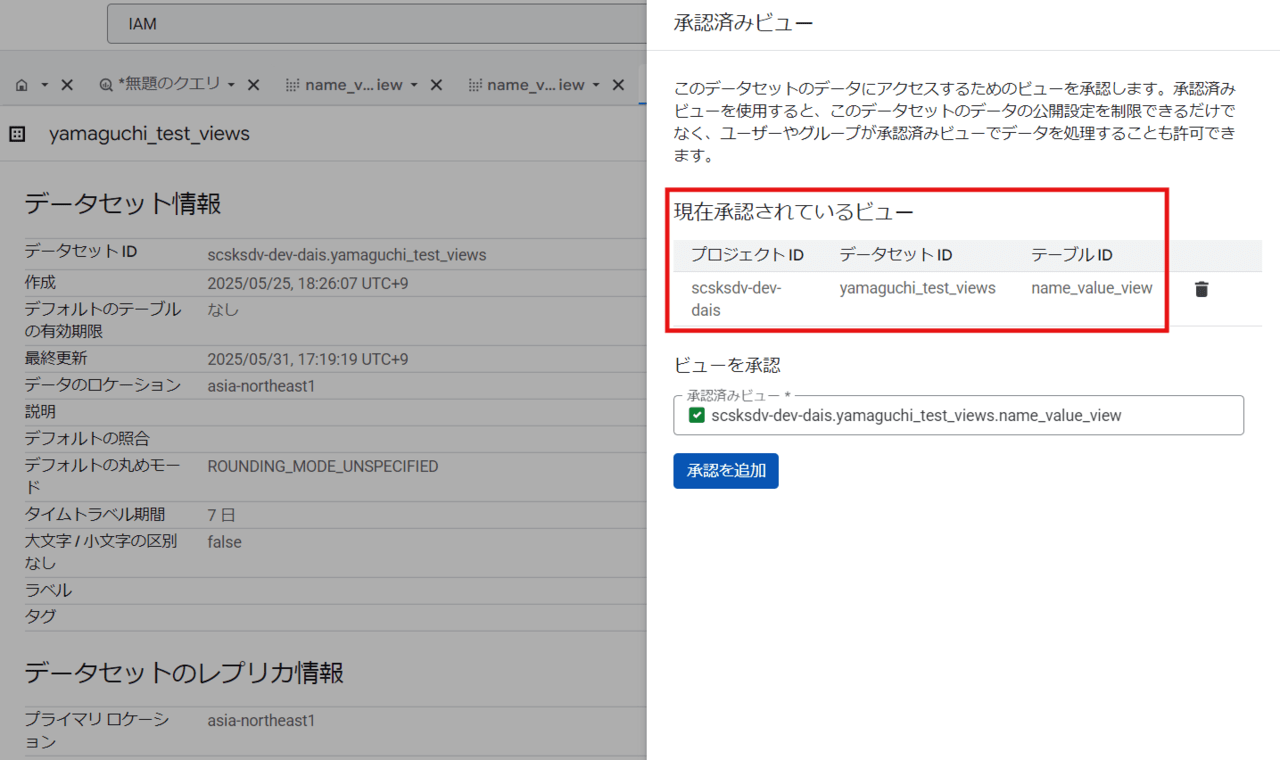
「ビューを承認」に対象のビューを入力し、「承認を追加」をクリックします。
権限設定
ここまでの作業で作成したテーブル、ビューの状況を整理します。
- source_table:個人情報あり(見せたくないデータがある元テーブル)
- name_value_view:個人情報なし(見せていいデータのみを抽出したビュー)
上記のデータセットに対して、下記アクセス制限をかけたいです。
- 管理ユーザ:どちらのにもアクセス可能
- 開発ユーザ:個人情報なし(name_value_view)の情報のみアクセス可能
では、ここから実際に権限設定していきます。
※注意:開発ユーザはプロジェクト内に何も権限を持っていないところからスタートとします。
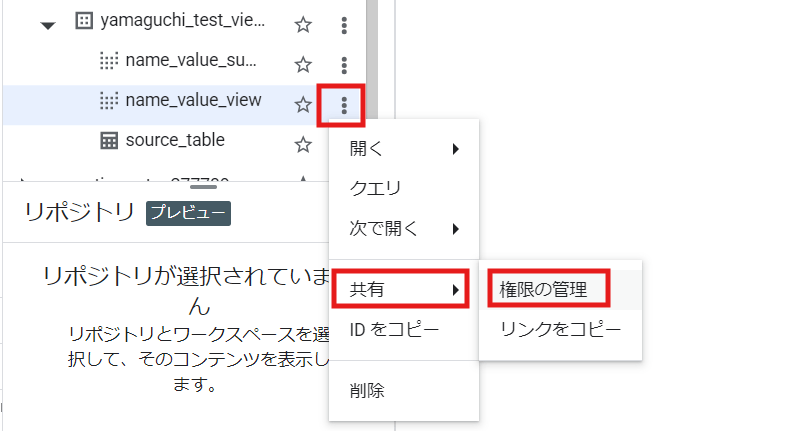
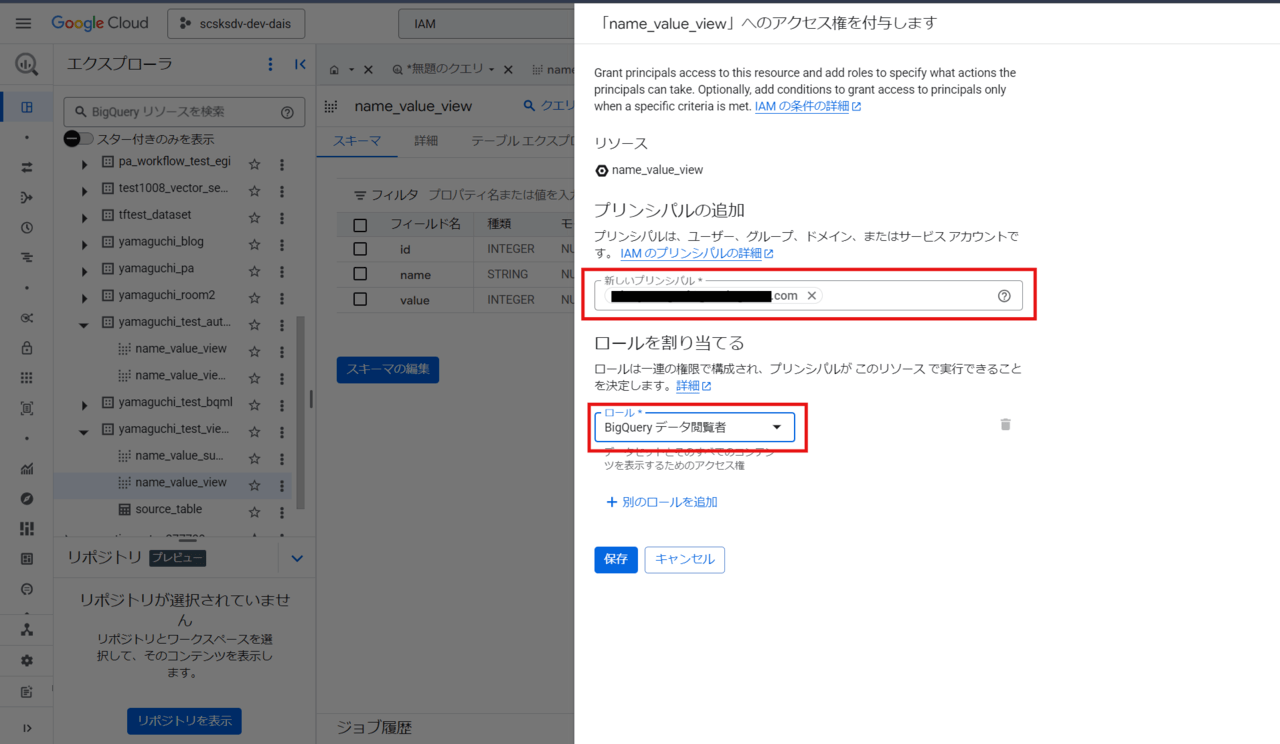
まず、開発ユーザに見立てたアカウントに「name_value_view」に対する「BigQuery データ閲覧者」を付与します。
対象のビューのメニューから「共有」-「権限の管理」をクリックします。
「プリンシパルを追加」をクリックし、開発ユーザに「BigQuery 閲覧者」のルールを付与します。
以上で権限設定は完了です。
開発ユーザからのクエリ実行
開発ユーザからクエリを実行してみます。
- ソーステーブルに対するクエリ
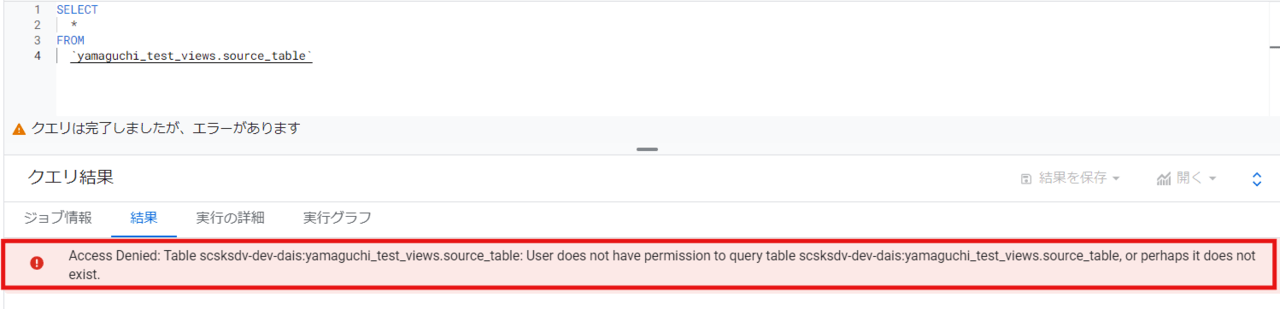
ソーステーブルに対する権限は付与されていないのでデータが見れませんでした。
- 承認済みビューに対するクエリ
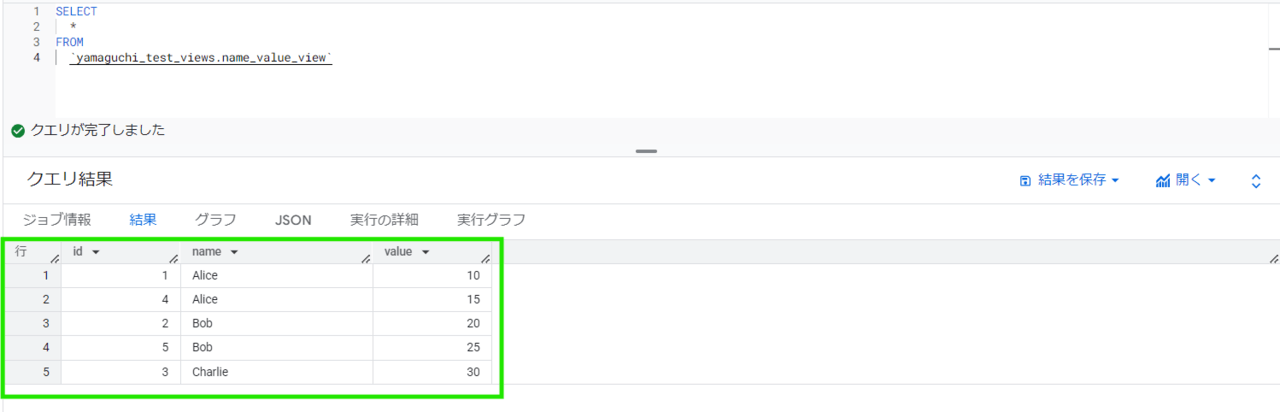
承認済みビューからはデータを見ることができました。
このように、承認済みビューを使用することで、
ソーステーブルに対する権限がないユーザでもビュー経由でのデータ取得が可能
になりました。これこそが承認済みビューの最大のメリットです。
ソーステーブル内の見せたくない情報は絞りつつ、開発ユーザへのデータ共有が実現できました。
③マテリアライズドビュー
ビュー作成方法
マテリアライズドビューは下記クエリで作成します。
CREATE MATERIALIZED VIEW `yamaguchi_test_views.name_value_sum_mv` AS SELECT name, SUM(value) AS total_value FROM `yamaguchi_test_views.source_table` GROUP BY name;
今回は、氏名(name)ごとに値(value)を合計した値の情報をマテリアライズドビュー化しました。
パフォーマンス比較
マテリアライズドビュー化した集計処理を、ソーステーブルに対して実行し、マテリアライズドビューの有無でのパフォーマンスを比較します。
ソーステーブルで集計処理
ソーステーブルに対して下記集計クエリを実行します。
SELECT name, SUM(value) AS total_value FROM `yamaguchi_test_views.source_table` GROUP BY name;
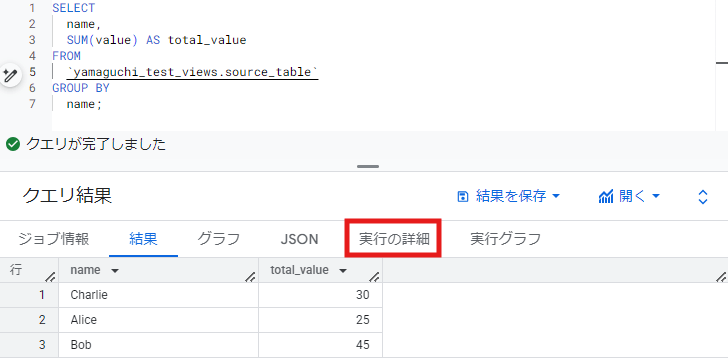
クエリ結果から、「実行の詳細」をクリックします。
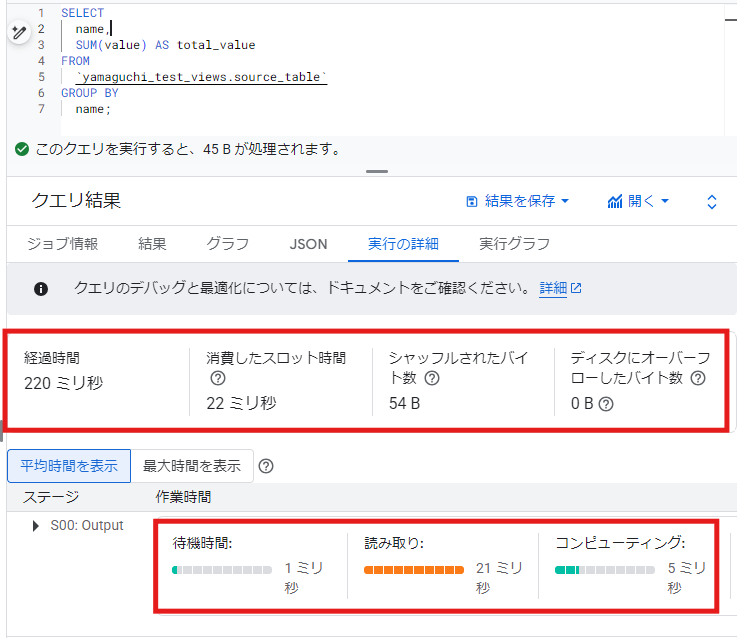
実行にかかった時間、バイト数などを確認することができます。
マテリアライズドビューで集計処理
マテリアライズドビューに対して同様の集計クエリを実行します。
SELECT * FROM `yamaguchi_test_views.name_value_sum_mv`;
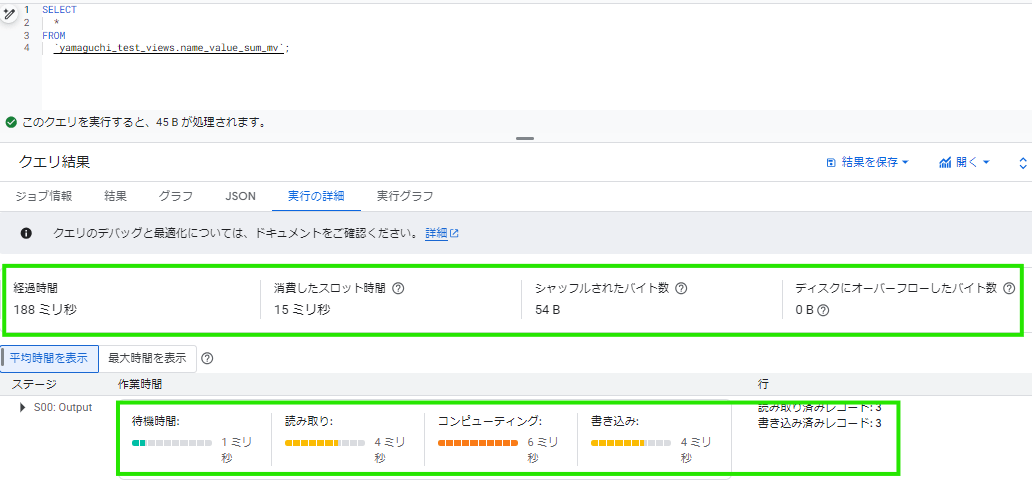
比較
両者を比較してみましょう
| 実テーブル | マテリアライズドビュー | |
| 経過時間 | 220 ms | 188 ms |
| 消費したスロット時間 | 22 ms | 15 ms |
| 読み取り時間 | 21 ms | 4 ms |
比較的顕著な差が出た項目をピックアップしました。
マテリアライズドビューを使用した場合、特に、「読み取り時間」で顕著な差が出ています。
今回は小規模なデータでの検証ですが、数十億行を超えるような大規模なデータセットに対して、頻繁に実行される集計クエリ(SUM, AVG, COUNTなど)の結果をマテリアライズドビューとして事前に計算しておくことで、
ソーステーブルの変更を反映
マテリアライズドビューを作成した後、ソーステーブルのデータに変更があった場合も、マテリアルビューは自動更新される仕組みになっています。
試しにソーステーブルにデータを追加してみましょう。
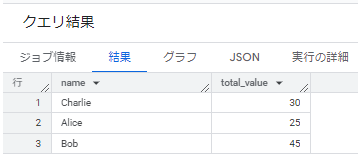
- データ追加前の集計クエリ結果を確認しておきます。
- ソーステーブルにデータを追加します。
INSERT INTO `yamaguchi_test_views.source_table` (id, name, value, sensitive_info) VALUES (6, 'Charlie', 35, 'PII_Charlie_2');
- マテリアルビューで集計結果を確認します。
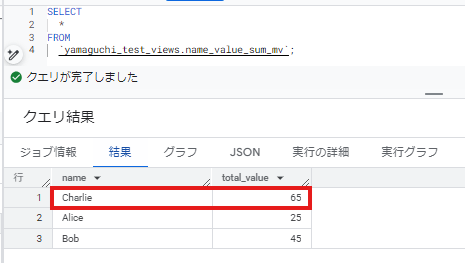
Charlieさんの値が変わっていることが確認できました。
ソーステーブルにデータを追加して数秒後にはデータが更新されていました。
まとめ
今回ピックアップしたそれぞれのビューの特徴、ユースケースをまとめます。
標準ビューのユースケース
- 複雑なクエリの簡略化: 複数のテーブルを結合したり、複雑な条件でフィルタリングしたりするクエリをビューとして定義することで、ユーザーは単純なSELECT文で必要なデータにアクセスできます。
- データアクセスの論理的な分離: 特定のビジネスロジックに基づいたデータのまとまりをビューとして提供することで、基となるテーブル構造を意識せずにデータを利用できます。
- レポート作成の効率化: レポートに必要なデータ整形済みのビューを作成しておくことで、レポート作成ツールからのクエリを簡潔にし、開発効率を向上させます。
承認済みビューのユースケース
- 機密性の高いデータの保護と共有: 個人情報や機密情報を含むテーブルから、特定のカラムを除外したビューを作成し、承認されたユーザーにのみアクセスを許可することで、安全にデータを共有できます。
- 特定のユーザーへのデータサブセットの安全な提供: 全てのデータへのアクセス権限を与えることなく、特定の条件でフィルタリングされたデータのみをビューとして提供できます。
- データガバナンスの強化: どのユーザーがどのデータにアクセスできるかを明確に管理し、意図しないデータ漏洩のリスクを低減します。
マテリアライズドビューのユースケース
- 大量データに対する高速な集計クエリ: 数十億行を超えるような大規模なデータセットに対して、頻繁に実行される集計クエリ(SUM, AVG, COUNTなど)の結果をマテリアライズドビューとして事前に計算しておくことで、クエリの実行時間を大幅に短縮できます。
- ダッシュボードやBIツールのパフォーマンス改善: リアルタイムに近いデータ表示が求められるダッシュボードやBIツールで、集計済みのマテリアライズドビューを参照することで、レスポンスタイムを向上させ、ユーザーエクスペリエンスを改善します。
- 頻繁に実行される集計処理の最適化: 定期的に実行されるETL/ELT処理の中で、集計結果をマテリアライズドビューとして保存しておくことで、ダウンストリームの処理を効率化できます。
検証を通して、それぞれのビューが持つ特性と、どのような場面でその特性が活かせるのかをご理解いただけたかと思います。ご自身のデータ分析の課題や要件に合わせて、最適なビューを選択し、BigQueryをより深く活用してみてください。