

こんにちは。SCSKの井上です。
この記事では、New Relic APM エージェントを導入した後に、アプリケーション監視画面をどのように読み解けばよいかを解説します。インフラとアプリケーション双方の状態を理解することで、ボトルネックを特定し、問題の早期発見や性能改善につなげられるようになります。
はじめに
アプリケーションを安定して動かすには、どの処理に時間がかかっているのか、どこで性能低下が起きているのかを把握することが重要です。New Relic APM を使うことで、アプリケーション内の動きを可視化し、ボトルネックの発見や改善ポイントの特定が迅速に行えます。APMエージェントの導入方法については、過去の記事からご確認いただけます。

APMのUI構成
この画面ではAPMの見方を解説します。
主要部分UI
New Relic APM の Summary 画面は、サービスの状態を一目で把握できるように、役割の異なる4つのエリアで構成されています。上部のフィルタ、ヘルス指標、時間範囲、右側のアクティビティなど、各エリアが いま何が起きているか”を素早く理解する手がかりになります。まずは、この4つのエリアがそれぞれどんな役割を持っているのかを簡単に説明します。
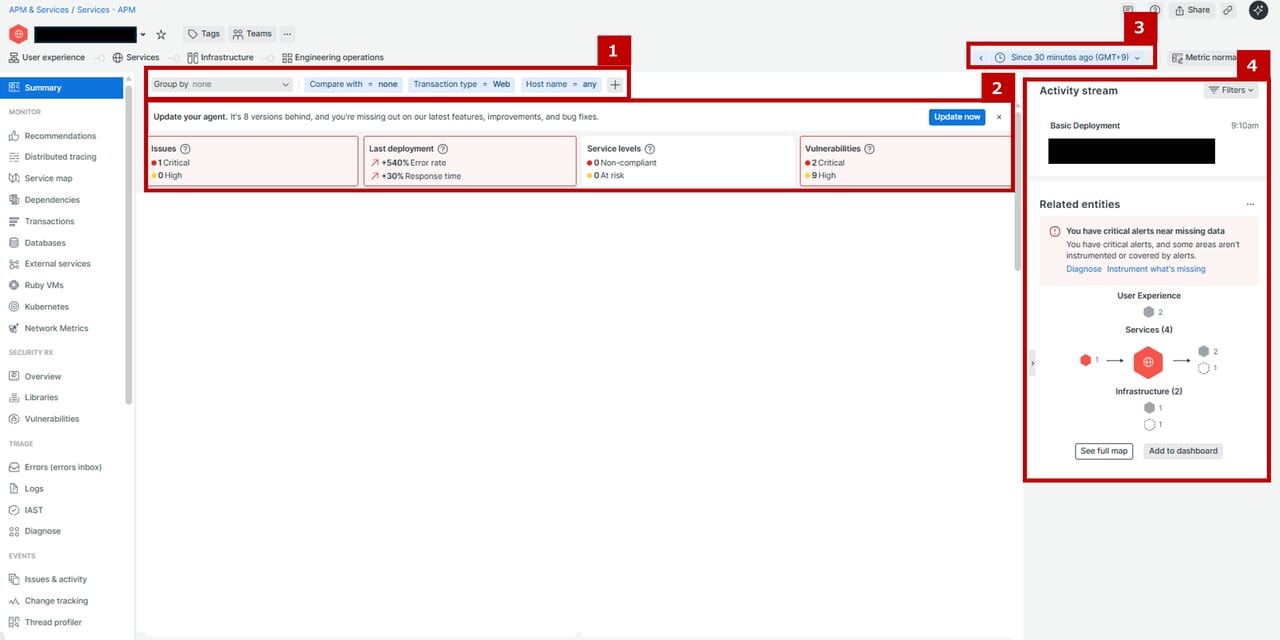
| エリア | 内容 |
| 1.画面上部のフィルタ & 表示切替エリア |
どの条件でデータを見るか(比較・フィルタ)
昨日・先週の同時間帯との比較、web全体像やAPI単位での絞り込み等
|
| 2.ヘルス指標パネル |
サービスの健康状態の概要(異常の早期発見)
|
| 3.期間選択 |
データの時間範囲を選択(変化点の確認)
|
| 4.アクティビティ履歴 & 関連エンティティ |
デプロイ・関連サービスなどのヒント(依存関係調査)
|

実際にSummary画面に表示されている情報を解説していきます。
【Web transactions timeの推移グラフ】
アプリの遅延要因が「どこで発生しているか」「いつ発生しているか」 を読み取ることができます。
【Throughputの推移グラフ】
アプリがどれくらいの数のリクエストを処理しているかを示します。急激な増加や低下もなく、負荷が一定している場合はリクエストが安定していると読むことができます。
【エラー発生率の推移グラフ】
アプリ側のロジックや特定の処理で断続的にエラーが出ているかを確認できます。Throughputの上下と連動している場合は、負荷が原因でエラーが増えている可能性があると読むことができます。
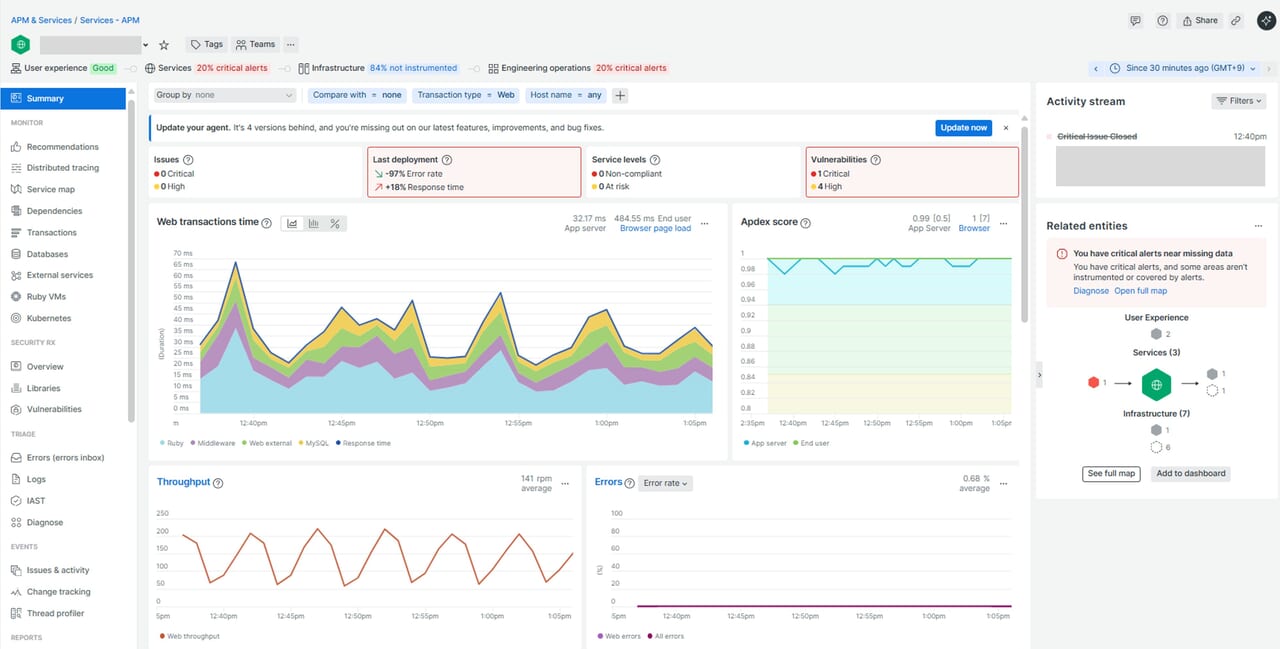
【Transactions】
最も遅い5件のトランザクションが表示されています。 平均応答時間は速いが最悪時は非常に遅いトランザクションがあります。処理が遅い原因はSlowest traceの時間をクリックすることで深堀することができます。
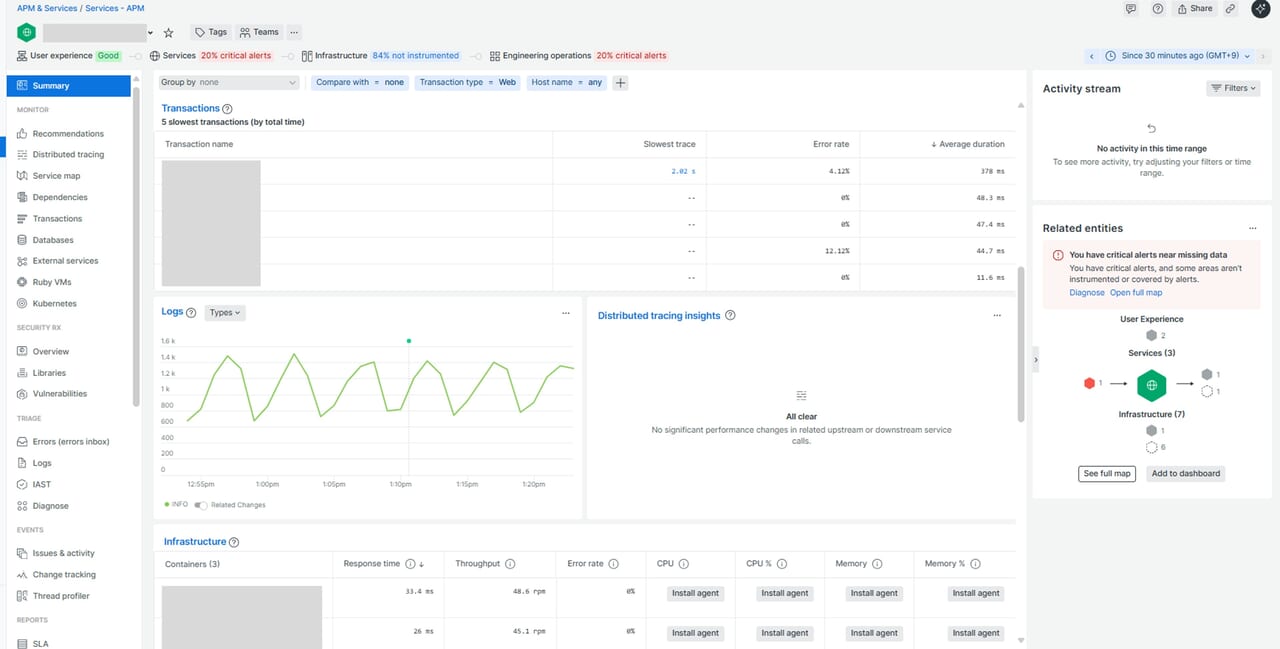
【Logs】
実際のエラー内容や例外スタック” を直接確認できます。エラー率は上がっているのに原因が分からない時は、最後にLogs を開いて実際にアプリがどんな状態なのかを確認します。
【Infrastructure】
アプリ側に問題がない場合、インフラ側のCPUスパイク・メモリ不足などが原因のケースも多く、その兆候をまとめて確認できます。Infrastructureエージェントが導入されている場合に表示されます。
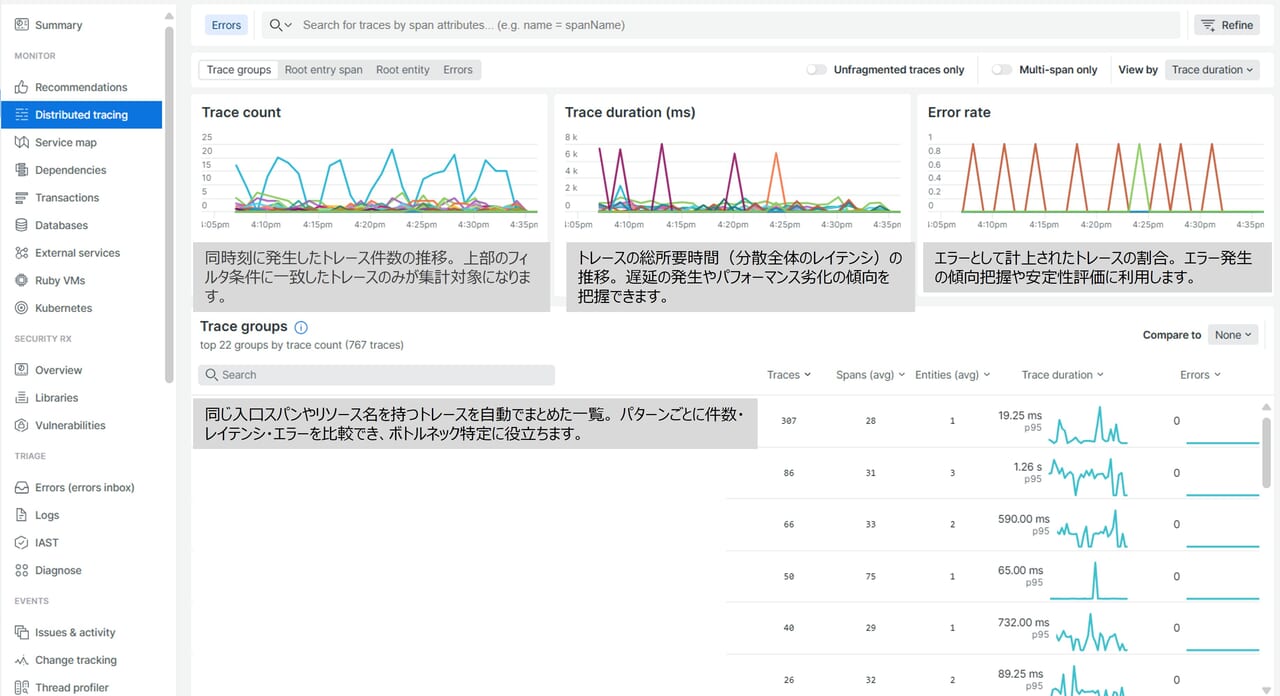
Distributed tracing
分散トレーシングとは、ネットで商品を注文するような1つの操作が、裏側でいくつものサービス(ログイン確認、在庫チェック、支払い処理など)を通って処理されるときに、それぞれのサービスで”いつ始まって、いつ終わったか”を記録して、全体の流れを見えるようにするしくみです。

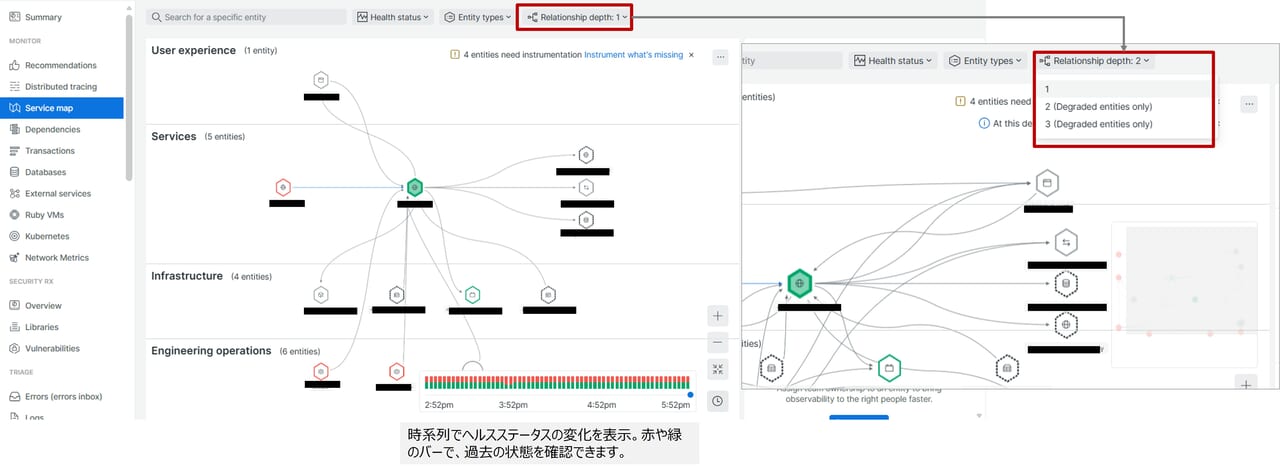
Servicemap (Maps)
サービスマップでは、システム全体の構成要素(ユーザー体験、サービス、インフラ、アプリ)とそれらの依存関係を可視化しています。この画面は主に 障害発生時の影響範囲分析や、依存関係を把握してトラブルシューティングを行うときに使います。
システム全体の構成要素を役割ごとに分類して依存関係をわかりやすくするため、4つに分類されています。この分類により、どの層で問題が発生しているかを迅速に特定し、影響範囲を把握することができます。
| マップ上の階層 | 説明 |
| User experience | ユーザーに直接影響するフロントエンドやUI関連のエンティティ |
| Services | アプリケーションのビジネスロジックやAPIなど、サービス層のコンポーネント |
| Infrastructure | サーバー、ホスト、ネットワークなど、サービスを支える基盤 |
| Engineering operations | デプロイ、CI/CD、アラートなど、運用や管理に関する要素 |
赤枠のRelationship depthは、サービスマップで表示する依存関係の階層の深さを設定します。どこまで依存関係を掘り下げて表示するかを制御する設定で、障害調査時に影響範囲を広く見るか、直接関連だけ見るか、を切り替えるために使います。

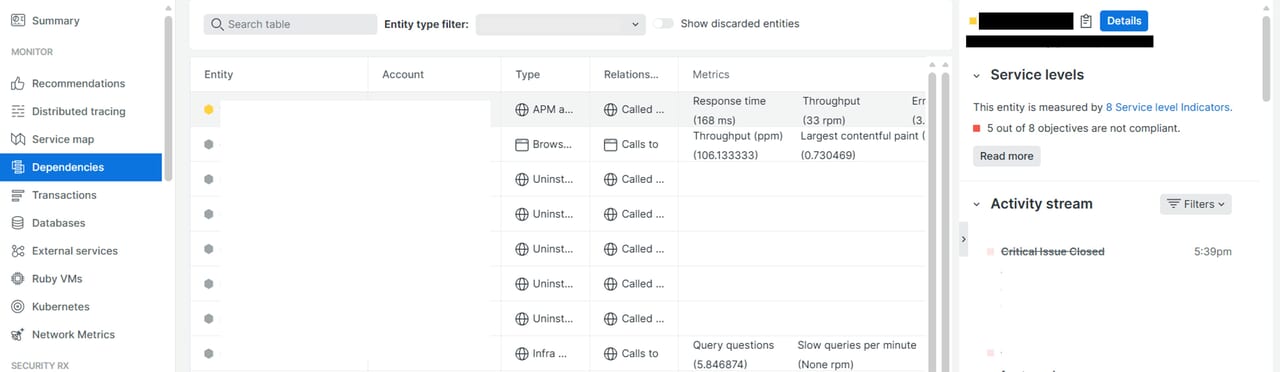
Dependencies
システム内のエンティティ(アプリケーション、サービス、DB、ホストなど)が他のエンティティにどのように依存しているかを示します。Service Mapはシステム全体のアーキテクチャを視覚化に対して、Dependenciesは特定のエンティティが依存しているリソースやサービスに焦点を当てています。Relationship列にて選択したEntityとの接続関係を示します。対象のエンティティから見て上流(called from)や下流(called to)の依存関係があり、どのサービスがどれに依存しているかを確認できます。

Transactions
| Sort by | 意味 | 利用シーン | 活用例 |
| Most time consuming | 合計処理時間が最も長いトランザクション | アプリ全体のパフォーマンス改善 | サービス全体の遅延要因を特定し、最適化対象を絞る |
| Slowest average response time | 平均応答時間が最も遅いトランザクション | ユーザー体験の改善 | UXに悪影響を与えている処理を特定し、応答時間を短縮 |
| Highest error rate | エラーが最も多く発生しているトランザクション | 障害対応・品質改善 | エラーの多い処理を調査し、例外処理や再試行ロジックを見直す |
| Throughput (calls per minute) | 最もリクエスト数が多いトランザクション | 負荷対策・スケーリング | 高頻度の処理に対してキャッシュ導入やスケールアウトを検討 |
| Apdex by most dissatisfying | ユーザー満足度が最も低いトランザクション | 顧客満足度の向上 | Apdexスコアが低い処理を改善し、ユーザー離脱を防ぐ |
![]()
上記画面のトランザクションをクリック後、パフォーマンス状況を詳細に把握することができます。トランザクションに絞った平均応答時間、スループット、エラー率、レスポンス時間の内訳などを分析できます。主にボトルネックの特定や遅延原因の詳細調査に使います。
![]()
Histrical Performance
過去のパフォーマンスデータ(yesterday,lastweek)を時系列で可視化・比較分析ができます。
| 利用シーン | 説明 | 目的・メリット |
| 傾向分析 | 過去のレスポンス時間やエラー率の推移を確認 | パフォーマンスの悪化や改善の兆候を把握 |
| 障害調査 | 特定の時間帯に発生したスパイクやエラーを分析 | インシデント対応・根本原因分析 |
| リリース影響確認 | デプロイ後のパフォーマンス変化を比較 | 新機能や修正の影響を定量的に評価 |
| キャパシティプランニング | 時期や時間帯ごとの負荷傾向を把握 | サーバー増強やスケーリングの判断材料 |
| 改善施策の効果測定 | チューニング前後のパフォーマンスを比較 | 最適化の成果を確認し、次の施策に活かす |
| ユーザー体験の推移確認 | Apdexスコアの変化を時系列で確認 | UX改善の効果を測定し、満足度向上へ |
![]()
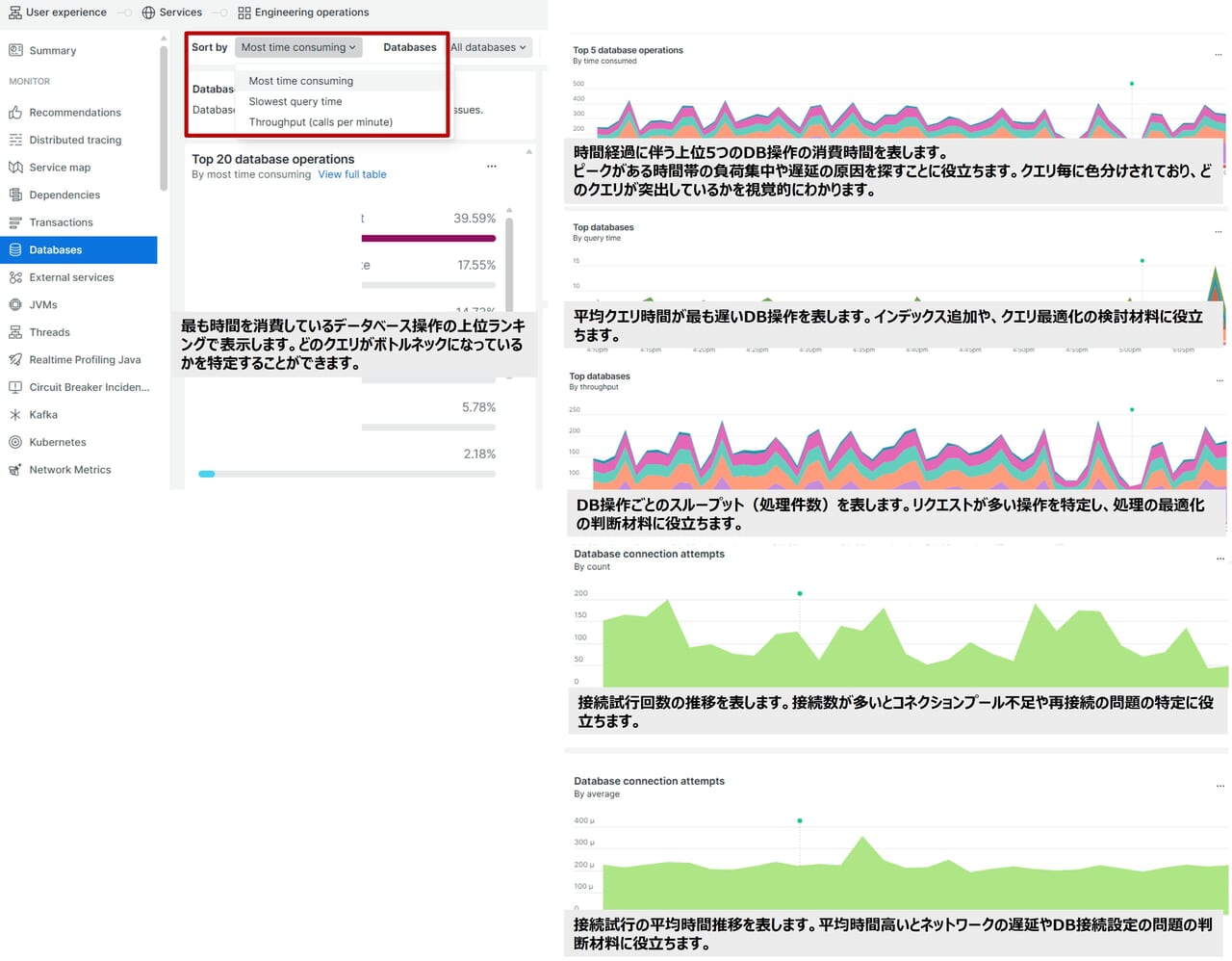
Databases
ソート方法は以下3パターンが利用できます。
| Sort by | 意味 | 利用シーン | 具体例 |
| Most time consuming | 合計実行時間が最も長いクエリ。頻度と実行時間の両方を考慮。 | パフォーマンスに最も影響を与えているクエリを特定し、最適化対象を絞る。 | 頻繁に呼び出される SELECT * FROM が全体のDB時間の50%を占めている。 |
| Slowest query time | 単一実行で最も時間がかかったクエリ。 | 異常に遅いクエリや、インデックスが適切に使われていないクエリ、非効率な結合処理を含むクエリを特定する。 | 一度だけ実行された JOIN クエリが5秒以上かかっていた。 |
| Throughput (calls per minute) | 単位時間あたりのクエリ実行回数(通常は1分あたり)。 | 負荷の高い時間帯や、スケーリングの必要性を判断する。 | 毎分1000回以上 INSERT INTO logs が実行されており、DB接続が逼迫している。 |
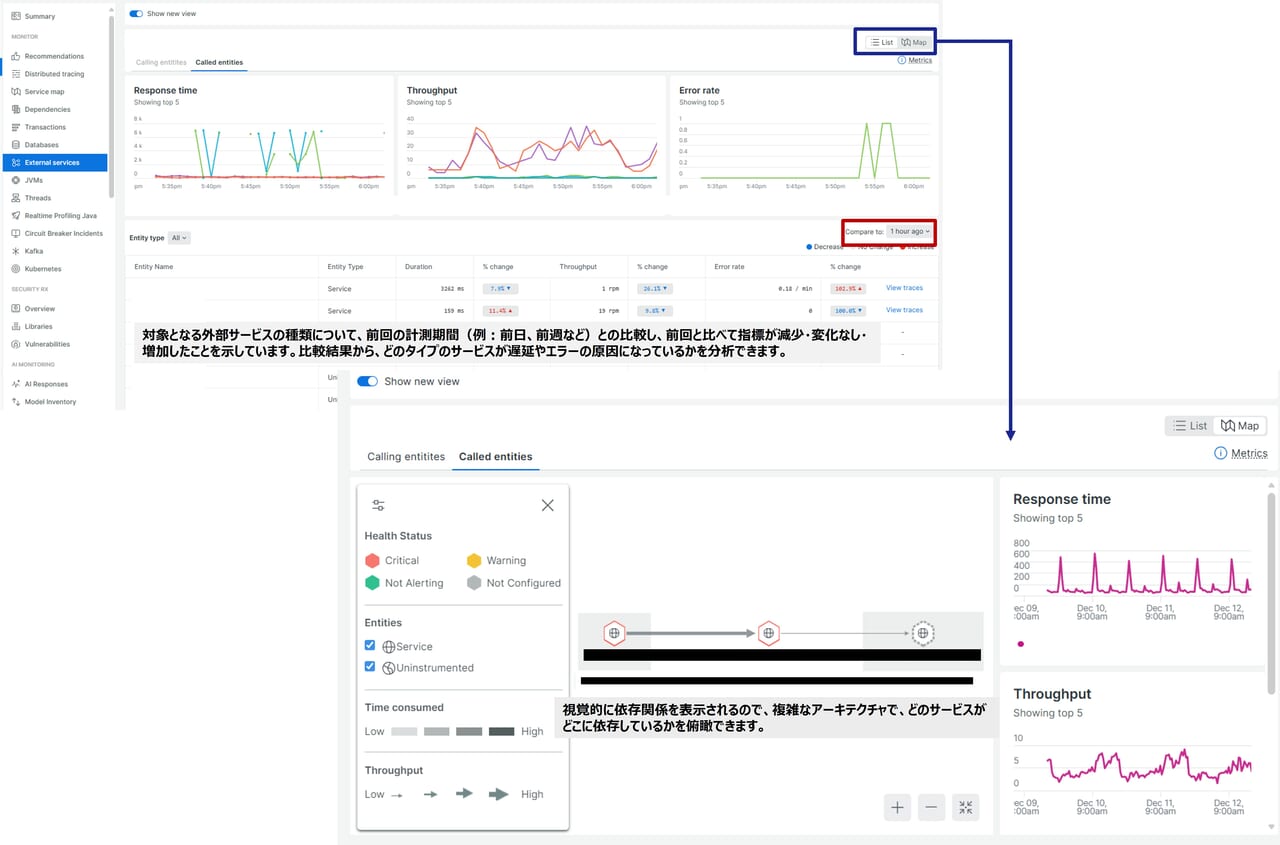
External services
External services(外部サービス機能)は、サービス間の依存とボトルネックを可視化し、応答時間が急に長くなった場合や、外部API呼び出しがボトルネックになっているか、サービス間の依存関係や遅延の原因を調べたいときに使います。

JVMs
Javaアプリの内部状態(メモリ・CPU・スレッドなど)をリアルタイムで可視化し、パフォーマンスや障害の兆候を早期に発見できる機能です。
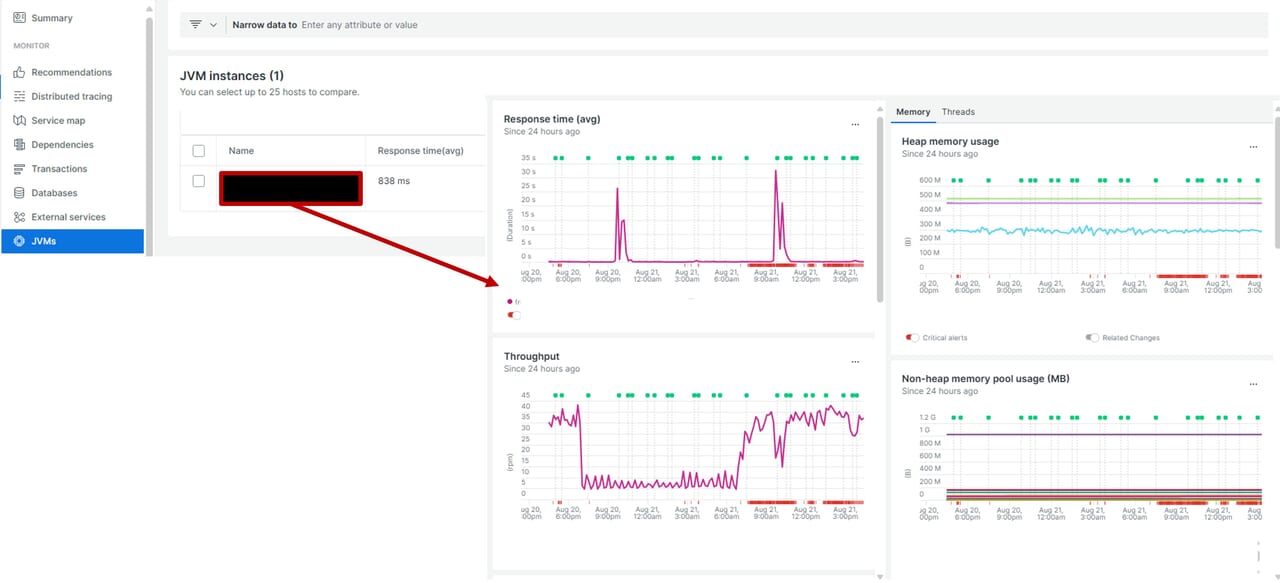

Threads
Threads機能は、スレッドが何をしているのかを観察するツールです。アプリケーションの中では、いろんな処理が同時に動いていることが多く、これらの処理はスレッドと呼ばれます。
- Threadsの特徴:関数やメソッド単位で時間を特定、CPU消費の可視化、スレッド動作分析、全体のコード実行状況把握
- 使用シーンと具体例:アプリ遅延、CPU高負荷、並列処理の詰まり、トランザクショントレースでは見えない問題
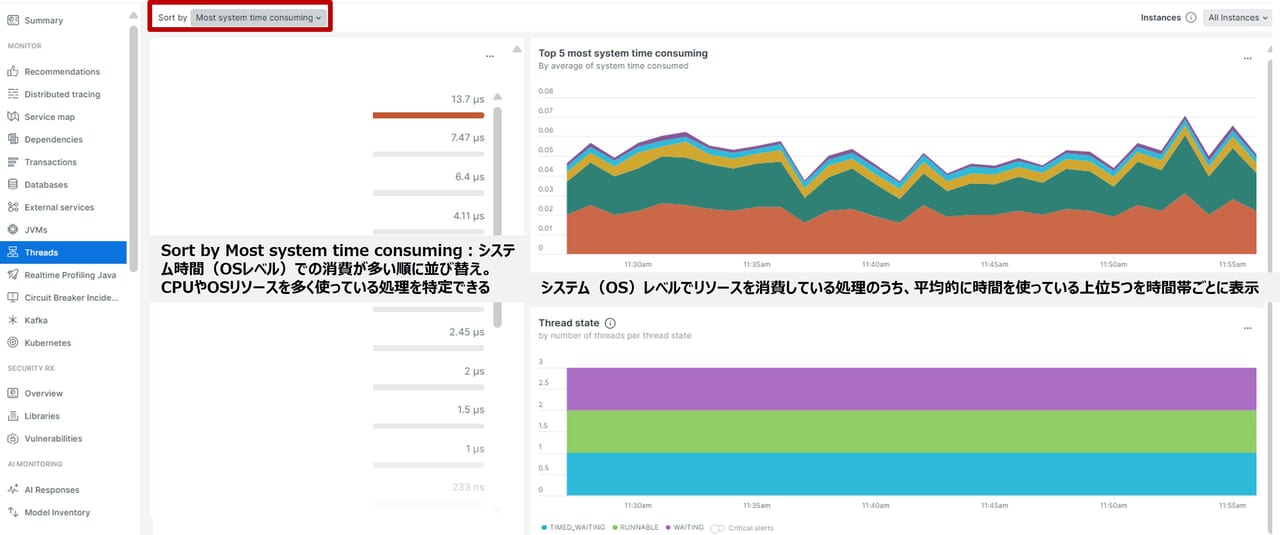
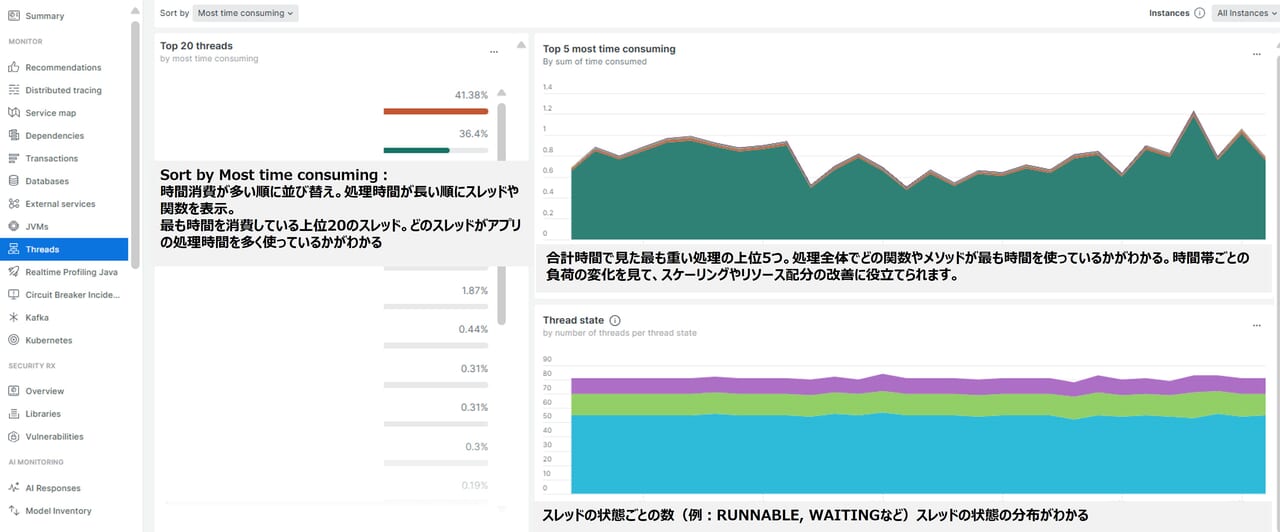
| スレッド状態 | 意味 | 次のアクション |
| RUNNABLE | 実行可能状態。CPUを使って処理中またはすぐに処理できる状態 | 多すぎる場合は、CPU負荷が高い可能性 → 処理の最適化やスレッド数の調整を検討 |
| WAITING | 他のスレッドの通知を待っている状態(例:Object.wait()) | 長時間待機している場合は、同期処理の見直しやロックの解消を検討 |
| TIMED_WAITING | 一定時間待機している状態(例:Thread.sleep()) | 不要な待機がないか確認。待機時間の短縮や非同期処理への変更を検討 |
| BLOCKED | 他のスレッドがロックを保持していて、処理できない状態 | ロック競合が発生している可能性 。ロックの粒度を下げる、非同期化などの改善策を検討 |
| NEW | スレッドが作成されたが、まだ開始されていない状態 | 多すぎる場合はスレッド管理の見直しを検討 |
| TERMINATED | スレッドが終了した状態 | 終了済みなので問題なし。ただし異常終了がないかログ確認は有効 |

Vulnerability
APMエージェントを活用してアプリ全体の脆弱性状況を可視化・依存関係の脆弱性を自動検出し、CVSSやランサムウェア情報に基づいて修復の優先度を決定します。AWS Security Hub の調査結果やAWS GuardDuty と Inspector の結果をインポートし、ダッシュボードまたはNRQLで表示することもできます。

All Vulnerabilities
脆弱性が CVSS(重要度)、EPSS(悪用可能性)、ランサムウェア使用状況のデータに基づいて優先度順にランク付けされています。 優先順位付けにより、アプリの公開範囲や影響に応じた対応計画が立てやすくなります。 アラート設定も可能なため、継続的な脆弱性管理を提供できます。
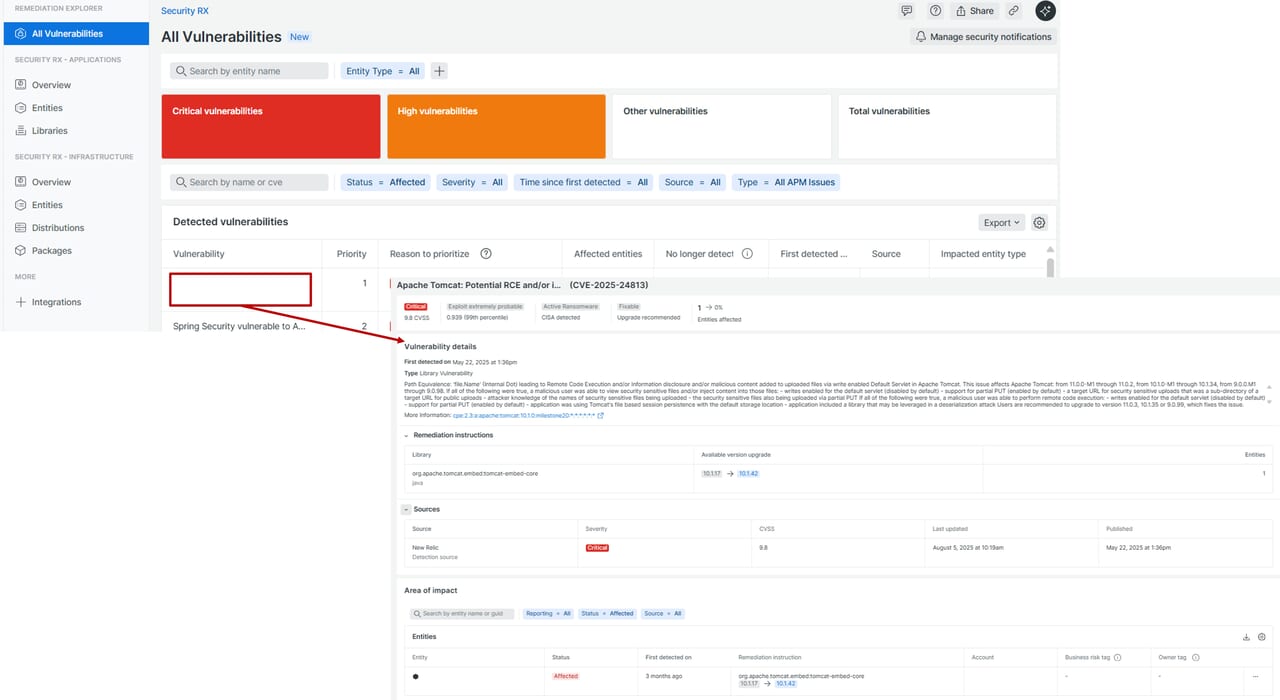


Apps Overview
APMエージェントを使ってアプリ依存ライブラリの脆弱性を自動検出し、CVSSやEPSSなどで優先順位を付けて修復を支援します。組織全体/個別アプリの視点で脆弱性状況を可視化することができます。
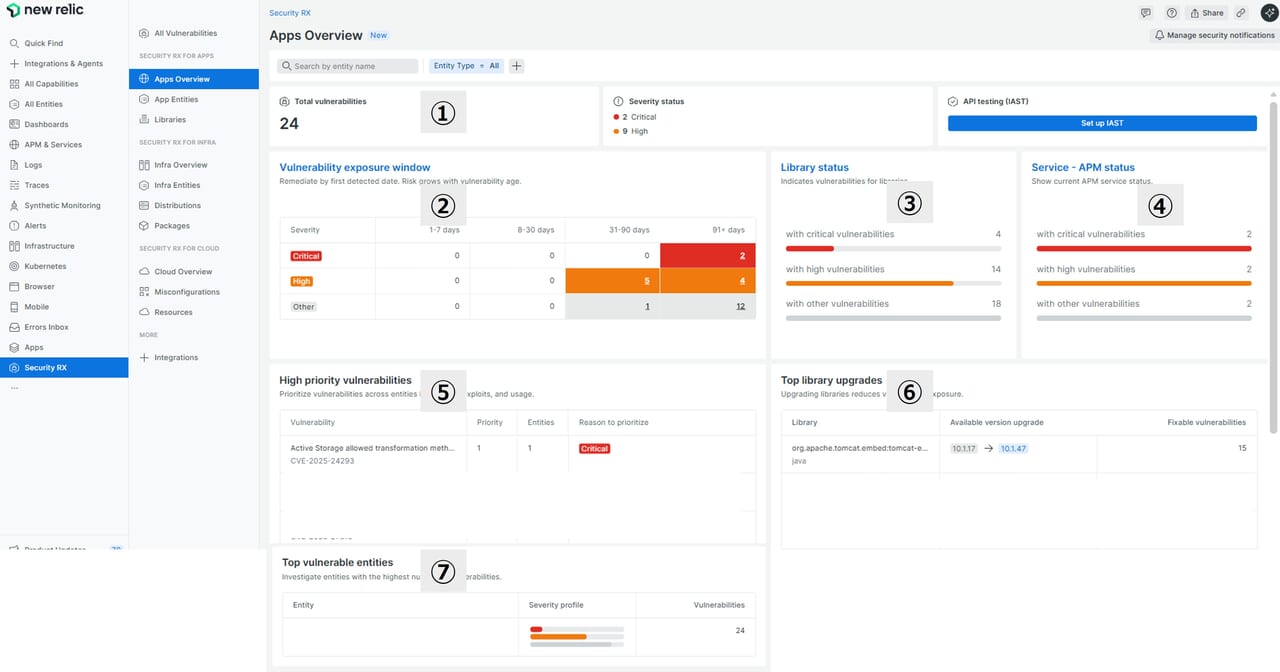
| 画面 | 内容 | 確認観点 |
| ①Total vulnerabilities | 検出された脆弱性の総数と重大度別件数 | 全体のリスク規模を把握 |
| ②Vulnerability exposure window | 脆弱性が放置されている期間を重大度別に表示(ヒートマップ) | 長期間放置されているCritical脆弱性は最優先で対応 |
| ③Library status | 脆弱性を含むライブラリの件数(Critical、High、その他) | ライブラリ単位でアップグレード対象を確認 |
| ④Service・APM status | APM監視サービスの脆弱性状況(CriticalやHighを含むサービス数) | 影響範囲をサービス単位で把握 |
| ⑤High priority vulnerabilities | 優先度の高い脆弱性一覧(CVE番号、重大度、優先度スコア) | 修正すべき脆弱性を特定 |
| ⑥Top library upgrades | 脆弱性解消のためにアップグレードすべきライブラリ一覧(現行バージョンと推奨バージョン) | アップグレード計画に活用 |
| ⑦Top vulnerable entities | 脆弱性が最も多いエンティティと重大度分布(赤=Critical、オレンジ=High)を表示 | Criticalを含むエンティティは最優先で対応 |


障害対応の流れ(一例)
障害対応は最初の一手で混乱しがちですが、まずは全体をざっくり見るところから始まります。もちろん、アラートで原因がほぼ特定できているケースや、過去の経験からこのサービスが落ちると大体ここが怪しいと目星がつく場合もあります。その場合は、最初からSummary画面を見ることも多いです。状況によって入り口は変わりますが、どこが赤くなっている?どのサービスが遅れている?と俯瞰しておくと、全体像が掴みやすく、原因の方向性も自然と見えてきます。この記事では、私が New Relic を使って実際に辿っている障害調査のステップをまとめました。
1.全体像の把握(どこで起きているか?)
今どこで何が起きているのかをざっくり掴むところからスタートします。個人的には、障害対応の時はアタフタしがちなので、まずService Mapで全体の流れを眺めます。赤くなっているサービスや、突然応答が遅くなっている部分がないか?この時点で、障害が特定のサービス単体なのか、依存関係(上流・下流)によるものかを確認します。
2. サービス概要の確認(何が起きているか?)
対象のサービスを特定したら、APMのSummaryページでGolden Signals(応答時間・リクエスト数・エラー率)を確認します。普段と比べてどうなのかを確認したいときは、「Compare with yesterday/last week」 を使うと異常が出始めたタイミングが一目でわかります。エラーのスパイクや、普段ない遅延が出ていれば、ここで気づくことができます。
3. 原因の深掘り(どんな処理の流れか?)
次は Transactions を確認します。ここを見ると「/api/v1/data が妙に遅いな…」みたいに 遅延の正体がスッと腑に落ちる瞬間があります。さらに掘るときは Transaction Trace が便利で、どのメソッドが重いのか、どの SQL が詰まっているのか、ここで原因の目星がつきます。
4. エラーの詳細確認(なぜ起きたか?)
エラーが増えているときは Errors Inbox が頼りになります。似たようなエラーをまとめてくれるので、「エラーが多すぎて追えない」という状況でも、原因パターンが整理されます。
5. 外部要因の調査(データベース・外部API)
アプリ側が正常でも、依存先が遅れているだけ、というのはよくあります。Databases で遅いクエリを確認したり、External Services で外部 API(決済・認証など)の応答遅延を調べるのも重要です。インフラ側の CPU・メモリ・ネットワーク I/O も見ておくと、原因を取りこぼしにくいと言えると考えています。
さいごに
この記事では、New Relic APM が提供する主要な可視化機能や、日々の運用で役立つ画面の見方について解説しました。APM を活用することで、アプリケーション内部の処理を詳細に把握でき、ボトルネック調査や性能改善に役立てることができます。また、トランザクションの流れや外部サービスとの連携状況、データベース処理の負荷といった運用上重要なポイントを多角的に分析できる点も大きな特徴です。APM のデータを Infrastructure やログ、分散トレースと組み合わせることで、アプリケーションとインフラ全体を通した統合的な可視化が可能になります。これにより、個別のコンポーネントだけでなく、システム全体を俯瞰した観点での最適化や改善にもつながります。
SCSKはNew Relicのライセンス販売だけではなく、導入から導入後のサポートまで伴走的に導入支援を実施しています。くわしくは以下をご参照のほどよろしくお願いいたします。
