
 本記事は TechHarmony Advent Calendar 2025 12/23付の記事です。 本記事は TechHarmony Advent Calendar 2025 12/23付の記事です。 |
こんにちは。SCSK渡辺(大)です。
肩こりが酷すぎたのでYouTubeで首回りのストレッチ動画を参考にやってみたらスッキリしました。
首剥がしとストレートネック治しの動画はお勧めです。
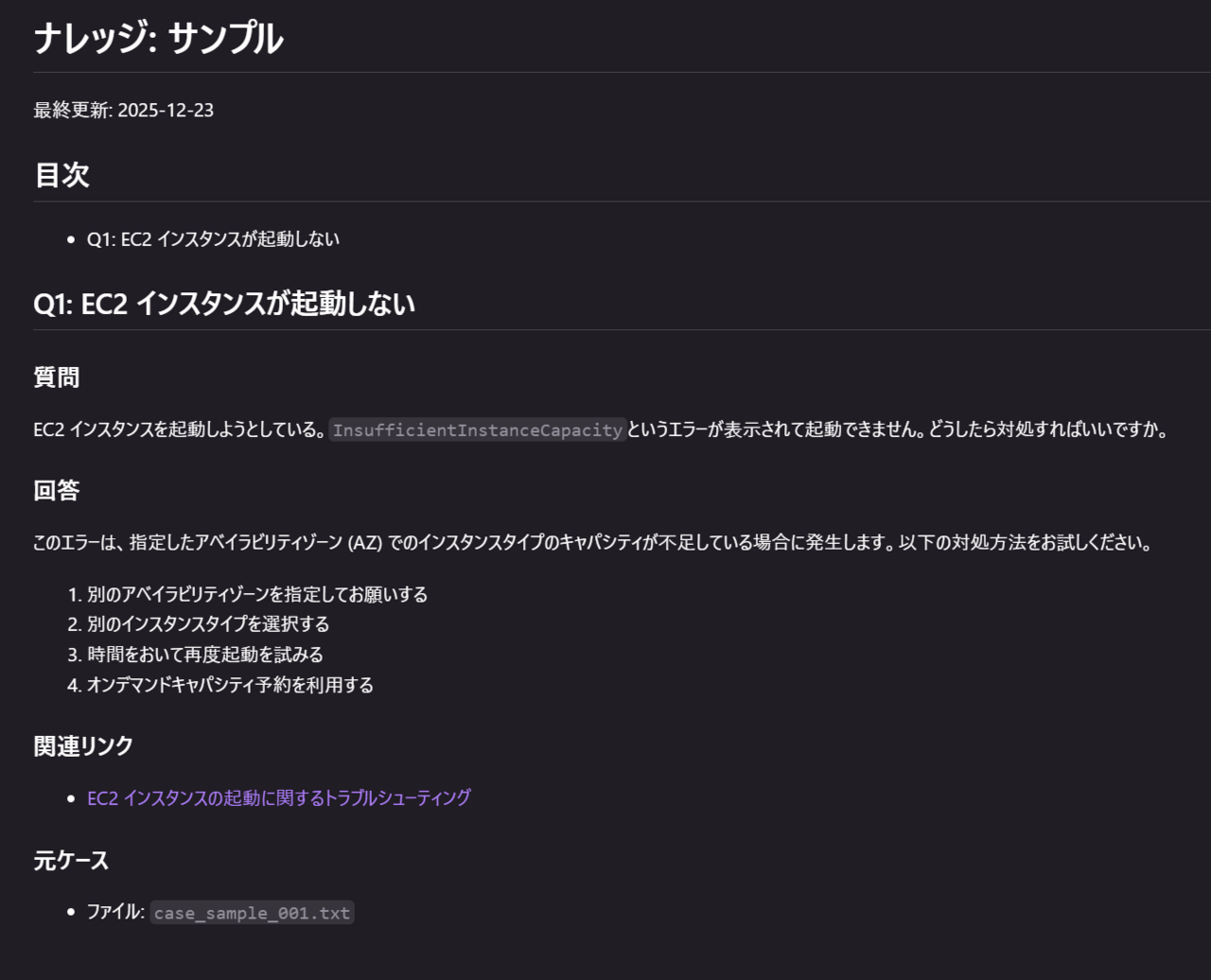
サンプルのナレッジ
以下のようなナレッジを作ることが出来ました。
背景
楽してナレッジを作りたかったのです。
AIの進化のおかげで重たい腰が上がった
※あくまで一個人の見解です。
恐らく1年前だったら1つのケースをナレッジ化するのに1分掛かるか、トークンが多すぎて1度の指示で全てのケースをナレッジ化することは出来なかったかと思います。
それが今では、スクリプトの作成から始め、スクリプトの実行、ケースをカテゴリ別に仕分け、すべてのケースのナレッジ化までを丸っとAIにお任せすることが出来ます。
※Kiroに実行許可をしていない場合には、スクリプトの実行など必要なタイミングでは人間の介在が必要です
最早、AIが「AWS Support のケースをナレッジ化するために進化してきました!」と言っているようなものです。
なので有難く使わせてもらいました。
思い立ったが吉日
ということで早速取り掛かってみようと、AWSマネジメントコンソールの AWS Support の画面を眺めていたところ、約2年前のケースまでしか残っていませんでした。
調べてみたところ、AWS Supportのケース履歴は、AWSマネジメントコンソール上では直近24か月間(2年間)までしか残っていません。[1]
また、Boto3のリファレンス[2]では直近12か月(1年間)までとなっていますが、実際にはAWSマネジメントコンソールと同様に、直近24か月間(2年間)まで取得できます。(実際に試しました)
つまり、ナレッジ化したいと感じたらすぐに取り掛かったほうが良いということです。
理由は、直近24か月を超過したケースは見れなくなってしまうためです。
概要
AWS Support でクローズ済のケースをKiroにナレッジ化してもらいました。
大まかな流れ
- AWS Support ケース情報の取得(リクエスト)
- AWS Support ケース情報の取得(レスポンス)
- カテゴリ分類した後、カテゴリ単位でナレッジを作成
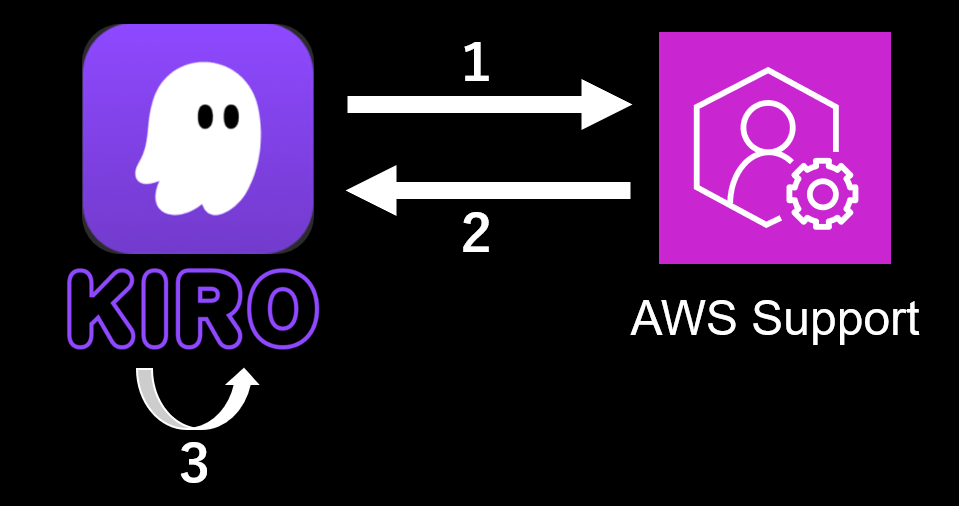
もう少し細かい流れ
Kiroに実行許可をしていない場合には、スクリプトの実行など必要なタイミングでは人間の介在が必要ですが、殆どKiroにお任せできます。
- ユーザーがKiroに指示文(後述)を伝える
- KiroがPython スクリプトを実行してケース情報を取得
- Kiroが進捗管理表を確認
- 存在する → 続きから処理(5 へ)
- 存在しない → 新規作成
- Kiroが未分類のケースを読み込み、進捗管理表に記録
- Kiroがカテゴリ単位で ナレッジ を作成し、進捗管理表を更新
- Kiroが未処理のケースがあるか確認
- ある → 3 へ戻る
- ない → 完了
- Kiroのセッションが中断した場合 → 新しいセッションで 2 へ戻る
必要なもの
- ローカル
- Kiro(他のエージェント型IDEでも良いと思いますが私は試してません)
- Pythonスクリプト(AWS Support ケース情報を取得する処理)
- boto3(Pythonスクリプトで使うため必要)
- Python 3.10 以上(boto3を使うために必要[3])
- AWS 認証情報(boto3を使うために必要)
- AWS CLI 2.32以上(aws loginでAWS認証する場合には必要)
- AWS
- AWS Support プラン(Developer/Business/Enterprise)
- AWS Support ケース(解決済み)
- IAM権限(以下)
-
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sts:GetCallerIdentity", "support:DescribeCases", "support:DescribeCommunications" ], "Resource": "*" } ] }
-
Pythonスクリプト(AWS Support ケース情報を取得する処理)
畳んでいます。
Pythonスクリプト
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
AWS Support ケースダウンローダー
サポートケースをダウンロードし、
各ケースをテキストファイルとして保存する。
"""
import json
import logging
import os
import sys
from datetime import datetime
from pathlib import Path
import boto3
from botocore.exceptions import NoCredentialsError, ClientError, BotoCoreError
OUTPUT_DIR = 'support_cases'
EXCLUDED_KEYWORDS = [
"[除外したいケース名に含むキーワード1]",
"[除外したいケース名に含むキーワード2]"
]
def setup_logging() -> logging.Logger:
"""ロギング設定"""
os.makedirs(OUTPUT_DIR, exist_ok=True)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
log_file = f"{OUTPUT_DIR}/download_{timestamp}.log"
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(log_file, encoding='utf-8'),
logging.StreamHandler(sys.stdout)
]
)
return logging.getLogger(__name__)
def get_aws_credentials():
"""認証情報を取得"""
# ~/.aws/credentials があればboto3デフォルトに任せる
creds_file = Path.home() / '.aws' / 'credentials'
if creds_file.exists():
return 'default'
# aws login キャッシュから取得
cache_dir = Path.home() / '.aws' / 'login' / 'cache'
if not cache_dir.exists():
return None
cache_files = list(cache_dir.glob('*.json'))
if not cache_files:
return None
latest_file = max(cache_files, key=lambda f: f.stat().st_mtime)
with open(latest_file, 'r', encoding='utf-8') as f:
data = json.load(f)
token = data.get('accessToken', {})
return {
'aws_access_key_id': token.get('accessKeyId'),
'aws_secret_access_key': token.get('secretAccessKey'),
'aws_session_token': token.get('sessionToken'),
}
def create_session(logger):
"""boto3 セッション作成"""
creds = get_aws_credentials()
if creds == 'default':
logger.info("Using ~/.aws/credentials")
return boto3.Session(region_name='us-east-1')
if not creds or not creds.get('aws_access_key_id'):
raise NoCredentialsError()
logger.info("Using aws login cache")
return boto3.Session(
aws_access_key_id=creds['aws_access_key_id'],
aws_secret_access_key=creds['aws_secret_access_key'],
aws_session_token=creds['aws_session_token'],
region_name='us-east-1'
)
def validate_credentials(session, logger):
"""認証情報の有効性をテスト"""
try:
sts = session.client('sts')
identity = sts.get_caller_identity()
logger.info(f"認証成功: {identity.get('Arn', 'Unknown ARN')}")
return True
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code in ['InvalidUserID.NotFound', 'AccessDenied', 'TokenRefreshRequired', 'ExpiredToken', 'ExpiredTokenException']:
logger.error("AWS認証情報が無効または期限切れです。認証情報を確認してください。")
else:
logger.error(f"AWS API エラー: {error_code} - {e.response['Error']['Message']}")
return False
except BotoCoreError as e:
logger.error(f"AWS接続エラー: {e}")
logger.error("ネットワーク接続またはAWS認証情報を確認してください。")
return False
except Exception as e:
logger.error(f"認証テスト中の予期しないエラー: {e}")
import traceback
logger.error(traceback.format_exc())
return False
def download_cases(session, logger):
"""全サポートケースをダウンロードして保存"""
try:
client = session.client('support', region_name='us-east-1')
except Exception as e:
logger.error(f"Supportクライアント作成エラー: {e}")
raise
logger.info("Fetching cases...")
cases = []
next_token = None
try:
while True:
params = {'maxResults': 100, 'includeResolvedCases': True}
if next_token:
params['nextToken'] = next_token
response = client.describe_cases(**params)
cases.extend(response.get('cases', []))
next_token = response.get('nextToken')
if not next_token:
break
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'SubscriptionRequiredException':
logger.error("AWS Supportプランが必要です。Basic以上のサポートプランに加入してください。")
return 0
else:
logger.error(f"ケース取得エラー: {error_code} - {e.response['Error']['Message']}")
return 0
except Exception as e:
logger.error(f"ケース取得中の予期しないエラー: {e}")
return 0
logger.info(f"Found {len(cases)} cases")
saved_count = 0
for idx, case in enumerate(cases, 1):
case_id = case['caseId']
subject = case.get('subject', '')
logger.info(f"[{idx}/{len(cases)}] Processing: {case_id}")
# 除外キーワードのチェック
if any(kw in subject for kw in EXCLUDED_KEYWORDS):
logger.info(f" -> Excluded (keyword): {subject[:50]}")
continue
# 進行中のケース(クローズしていないケース)を除外
status = case.get('status', '').lower()
if status != 'resolved':
logger.info(f" -> Excluded (not resolved): {subject[:50]} (status: {status})")
continue
try:
comms = []
comm_token = None
while True:
params = {'caseId': case_id}
if comm_token:
params['nextToken'] = comm_token
resp = client.describe_communications(**params)
comms.extend(resp.get('communications', []))
comm_token = resp.get('nextToken')
if not comm_token:
break
filename = f"{OUTPUT_DIR}/case_{case_id}.txt"
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"ケースID: {case_id}\n")
f.write(f"件名: {subject}\n")
f.write(f"ステータス: {case.get('status', '')}\n")
f.write(f"作成日時: {case.get('timeCreated', '')}\n")
f.write(f"サービス: {case.get('serviceCode', '')}\n")
f.write(f"カテゴリ: {case.get('categoryCode', '')}\n")
f.write(f"重要度: {case.get('severityCode', '')}\n")
f.write("=" * 60 + "\n\n")
for i, comm in enumerate(comms, 1):
f.write(f"--- メッセージ {i} ---\n")
f.write(f"送信者: {comm.get('submittedBy', '')}\n")
f.write(f"日時: {comm.get('timeCreated', '')}\n")
f.write(f"内容:\n{comm.get('body', '')}\n\n")
saved_count += 1
logger.info(f" -> Saved: {filename}")
except Exception as e:
logger.error(f" -> Error: {e}")
logger.info(f"Completed: {saved_count} cases saved to {OUTPUT_DIR}/")
return saved_count
def main():
logger = setup_logging()
logger.info("Starting download...")
try:
session = create_session(logger)
# 認証情報の有効性をテスト
if not validate_credentials(session, logger):
return
count = download_cases(session, logger)
logger.info(f"Done: {count} cases saved to {OUTPUT_DIR}/")
except NoCredentialsError:
logger.error("AWS認証情報が見つかりません。認証情報を設定してください。")
except Exception as e:
logger.error(f"予期しないエラー: {e}")
logger.error("詳細なエラー情報:")
import traceback
logger.error(traceback.format_exc())
if __name__ == "__main__":
main()
Kiroへの指示文
畳んでいます。
指示文
# AWS Support ケースダウンロード & ナレッジ 化 指示書
## 重要な制約事項(必ず遵守)
### 禁止事項
- **追加のスクリプト(Python、シェルスクリプト等)を新規作成しないこと**
- 既存のスクリプト `aws_support_knowledge_generator_cli.py` を勝手に修正しないこと
- 指示書に記載されていない処理を勝手に追加しないこと
- 出力ディレクトリ以外の場所にファイルを作成しないこと
- **Kiro の SPEC 機能を使用しないこと**(この指示書に従って直接処理を行うこと)
### 許可される操作
- `aws_support_knowledge_generator_cli.py` の実行(ケースダウンロード)
- `support_cases_knowledge/` ディレクトリへの ナレッジ Markdown ファイルの作成のみ
- 既存ファイルの読み取り
---
## 1. ケースダウンロード(スクリプト実行)
### 実行コマンド
```bash
python aws_support_knowledge_generator_cli.py
```
### 動作内容
- 全サポートケースを `support_cases/` にテキストファイルとして保存
- ログは `support_cases/download_YYYYMMDD_HHMMSS.log` に出力
### 出力形式
各ケースファイル (`case_{ID}.txt`) には以下を含む:
- ケース ID、件名、ステータス、作成日時
- サービス、カテゴリ、重要度
- 全メッセージ履歴(送信者、日時、内容)
---
## 2. ナレッジ 化(Kiro による処理)
### 前提条件
- 事前に `python aws_support_knowledge_generator_cli.py` を実行してケースをダウンロード済みであること
- `support_cases/` ディレクトリにケースファイルが存在すること
### 処理手順(重要:セッション中断に備えた段階的処理)
**基本方針**: ファイル読み込み → 即座に進捗管理表に記載 → カテゴリ単位で ナレッジ 生成 → 次のファイル読み込み
#### ステップ 1: 初期確認
1. `support_cases_knowledge/progress_management.md`(進捗管理表)が存在するか確認する
2. 存在する場合は進捗管理表を読み込み、「分類済み」列と「ナレッジ 生成済み」列を確認する
#### ステップ 2: ファイル読み込みと即時分類(繰り返し)
1. `support_cases/` から**未分類のケースファイル**を可能な限り読み込む
2. **読み込んだら即座に**進捗管理表に追記する(「分類済み」に `✓`、「ナレッジ 生成済み」は空欄)
3. この時点でセッションが中断しても、次回は進捗管理表を見て続きから処理できる
#### ステップ 3: カテゴリ単位での ナレッジ 生成(繰り返し)
1. 進捗管理表から「ナレッジ 生成済み」が空欄のケースを**カテゴリ単位で**抽出する
2. そのカテゴリの ナレッジ ファイルを生成(または追記)する
3. ナレッジ 生成完了後、該当ケースの「ナレッジ 生成済み」列に `✓` を付ける
4. **1 つのカテゴリの ナレッジ 生成が完了してから**、次のカテゴリに進む
#### ステップ 4: 未読み込みファイルがあれば繰り返し
- ステップ 2〜3 を、全ケースファイルの処理が完了するまで繰り返す
### 進捗管理表(progress_management.md)
セッションをまたいでも処理状況を正確に把握できるよう、進捗管理表を管理する。
#### 進捗管理表の形式
```markdown
# 進捗管理表
最終更新: YYYY-MM-DD HH:MM:SS
## 処理状況サマリー
- 総ケース数: XX 件
- 分類済み: XX 件
- ナレッジ 生成済み: XX 件
## 分類済みケース一覧
| ケースファイル | カテゴリ | 件名 | 分類済み | ナレッジ 生成済み |
| -------------- | ----------------- | ---------------- | -------- | ------------ |
| case_xxx.txt | コスト・請求 | 請求に関する質問 | ✓ | ✓ |
| case_yyy.txt | セキュリティ・IAM | IAM 権限の設定 | ✓ | |
| case_zzz.txt | ネットワーク | VPC 設定について | ✓ | |
```
#### 進捗管理表の運用ルール(必須)
1. **即時記載の原則**: ケースファイルを読み込んだら、**その時点で即座に**進捗管理表に追記すること(全ファイル読み込み後ではない)
2. **2 段階チェック**:
- 「分類済み」列: ファイルを読み込んでカテゴリを判定したら `✓`
- 「ナレッジ 生成済み」列: そのケースを含む ナレッジ を生成したら `✓`
3. **カテゴリ単位処理**: 1 つのカテゴリの ナレッジ 生成を完了してから、次のカテゴリのファイル読み込みに進むこと
4. **セッション再開時**: まず進捗管理表を確認し、「分類済み」が空欄のケースのみ読み込み、「ナレッジ 生成済み」が空欄のカテゴリから処理を再開すること
5. **サマリー更新**: 進捗管理表を更新するたびに、処理状況サマリーも更新すること
### 応答言語
**Kiro からの応答は日本語で返すこと**
---
## 3. カテゴリ分類ルール
以下の 8 カテゴリに分類すること。複数カテゴリに該当する場合は、最も関連性の高い 1 つを選択する。
| カテゴリ名 | 対象サービス・キーワード |
| --------------------------- | ----------------------------------------------------------------------------- |
| 1. アカウント・サポート | アカウント設定、Organizations、サポートプラン、上限緩和申請、Service Quotas |
| 2. セキュリティ・IAM | IAM、認証、暗号化、セキュリティグループ、WAF、KMS、Secrets Manager、GuardDuty |
| 3. ネットワーク | VPC、Route 53、CloudFront、Direct Connect、ELB、ALB、NLB、Transit Gateway |
| 4. コンピューティング | EC2、Lambda、ECS、EKS、Batch、Fargate、Auto Scaling |
| 5. ストレージ・データベース | S3、EBS、RDS、DynamoDB、ElastiCache、Aurora、Redshift、EFS |
| 6. 開発・CICD | CodePipeline、CodeBuild、CodeDeploy、CloudFormation、CDK、CodeCommit |
| 7. 監視・運用 | CloudWatch、CloudTrail、Systems Manager、Config、EventBridge、X-Ray |
| 8. コスト・請求 | 料金、請求、Cost Explorer、Savings Plans、Reserved Instance、Billing、Budget |
---
## 4. ナレッジ ファイル生成ルール
### 出力先
- `support_cases_knowledge/` ディレクトリに出力すること(ディレクトリが存在しない場合は作成する)
- 他のディレクトリには出力しないこと
### ファイル命名規則
- `ナレッジ_カテゴリ名.md` 形式(例: `ナレッジ_コスト・請求.md`)
### 必須構成要素(すべて必須)
> **⚠️ 重要: 目次は必ず作成すること。目次がない ナレッジ ファイルは不完全とみなす。**
#### 4.1 目次(ファイル冒頭に必須)
**すべての ナレッジ ファイルの冒頭には必ず目次を設けること。** 目次がないファイルは作成完了とみなさない。
```markdown
# ナレッジ: カテゴリ名
最終更新: YYYY-MM-DD
## 目次
- [Q1: 質問タイトル](#q1-質問タイトル)
- [Q2: 質問タイトル](#q2-質問タイトル)
...
---
(以下、各 ナレッジ の本文)
```
#### 4.2 各 ナレッジ の構成
```markdown
## Q1: 質問タイトル
### 質問
(背景・状況を含めて、ユーザーからの質問内容を具体的に記載します。どのような状況で何を知りたいのか明確にします)
### 回答
(AWS サポートからの回答を詳細に記載します。手順がある場合はステップバイステップで記載します)
### 関連リンク
- [AWS 公式ドキュメント](https://docs.aws.amazon.com/...)
### 元ケース
- ファイル: `case_xxx.txt`
```
### 記載ルール
#### 文体
- **「です」「ます」調で統一**(質問、回答、説明文すべて)
#### 自己完結性(最重要)
- **ナレッジ 単体で問題と解決策が完全に理解できること**
- 元ケースを参照しなくても実用的な情報として成立させる
- 質問には背景・状況を含める(なぜその質問が発生したか)
- 回答は要約ではなく、実際に役立つ詳細さで記載
- 手順がある場合は番号付きリストでステップバイステップで記載
- AWS CLI コマンド、設定値、パラメータは省略せず完全な形で記載
#### 汎用性(重要)
- **特定環境に依存しない、誰でも使える ナレッジ にすること**
- 以下の情報は汎用的な表現に置き換える:
| 置換対象 | 置換後の表現 |
| ---------------------- | --------------------------------- |
| アカウント ID | `your-account-id` |
| ARN | `arn:aws:service:::your-resource` |
| バケット名・リソース名 | `your-bucket-name` 等 |
| メールアドレス | `your-email@example.com` |
| IP アドレス | `xxx.xxx.xxx.xxx` |
| 組織 ID | `o-xxxxxxxxxx` |
#### 禁止事項
- 「〜については元ケースを参照してください」という記載
- 具体的な値やコマンドを省略した曖昧な説明
- 元のケース内容に勝手な解釈を加えること
---
## 5. エラー対処
| エラー種別 | 対処方法 |
| ---------- | ------------------------------------------------------------ |
| 認証エラー | AWS 認証情報が不足しています。適切な認証設定を行ってください |
| 権限エラー | Business/Enterprise Support プランが必要 |
学んだこと
今回の学びで大きかったことは、Kiroの利用においては要約機能[4]が動くことを前提にした指示文にすべきだと感じました。
クレジット垂れ流し事件を起こさない方法
2025年12月12日にAWS IAM Identity CenterのユーザーでもClaude Opus 4.5が使えるようになった[5]ので、良い機会なのでClaude Opus 4.5のみ使用するように設定して指示文書を渡してみたのですが、なんとケース情報ファイルの読み込みだけでコンテキストを食い潰し、いざナレッジを作ろうとなった時にコンテキストの上限(80%)に達してしまいました。
それだけならまだ良かったのですが、要約機能が動いた後に再度ケース情報ファイルの読み込みが始まってしまい、またコンテキストの上限に達してしまい要約機能が動いて・・・という負のループに陥ってしまい、クレジットが垂れ流し状態になってしまいました。
上記の対応策として進捗管理表を作りました。
進捗管理表などを作成して随時更新するなどして要約機能が動いたとしても次のセッションで進捗が引き継がれるようにするべきであると、既に様々なところで言われていることですが今回とても痛感しました。
一方で、仕様書や設計書も作る必要があるような場合にはSpecs機能を使ってタスク管理しながら進めるほうが良いと思います。
Claude Opus 4.5 を利用した時のクレジット消費量が凄まじい
上記に関連してお伝えすると、Claude Opus 4.5 を利用した時のクレジット消費量が凄まじいです。
当記事に載せた指示文で実行した場合、完了するまでに約40クレジット消費しました。
約40ケースがナレッジ化の対象だったので、偶然かもしれませんが1クレジット/ケースでした。
Kiroを使ったことがある人は以下の画像を見ると震えるかもしれません。
![]()
![]()
![]()
ファイル名には「/」を含めないように指示するべき
ファイル名に「/」を含めるように指示をしてしまうと、「/」より前がディレクトリで後ろがファイル名として判断されてしまいます。
対応策の具体例は、「開発・CI/CD.md」は避けて「開発・CICD.md」で指示すべきです。
そうしないと以下の画像のようになってしまいます。

まとめ
業務におけるナレッジ作成は大変なので、AWS Support のケースだけでも楽にナレッジ化できそうであることが分かって良かったです。
後続の運用を考えた時には最新化や棚卸も必要になると思いますが、再度 AWS Support に問い合わせするようなことはしなくても、MCPサーバーを使って最新の情報を確認できるようにしてあげれば、それらの作業もAIで楽に出来そうですね。
私が実際の業務で使うかどうかは別問題ですが、当記事がどなたかの役に立ちましたら幸いです。
Kiro に興味を持った方は、ぜひ Kiro 公式サイト をチェックしてみてください。
参考情報
[1]AWS プレミアムサポートのよくある質問
–抜粋——————————————————-
ケース履歴の保存期間はどれほどですか?
ケース履歴情報は、作成後 24 か月間ご利用いただけます。
————————————————————–
[2]describe_cases – Boto3 1.42.9 documentation
–抜粋(日本語訳)——————————————
ケースデータは作成後12か月間利用可能です。12か月以上前に作成されたケースの場合、リクエストがエラーを返す可能性があります。
————————————————————–
[3]Quickstart – Boto3 1.42.9 documentation
–抜粋(日本語訳)——————————————
Pythonのインストールまたはアップデート
Boto3をインストールする前に、Python 3.10以降を使っていることを確認してください。
————————————————————–
[4]Summarization – IDE – Docs – Kiro
–抜粋(日本語訳)——————————————
要約
すべての言語モデルには「コンテキストウィンドウ」があり、これはモデルが一度に処理できる最大テキスト量です。コンテキストウィンドウの長さはモデルによって異なります。
Kiroと会話すると、その会話の過去のすべてのメッセージをメモリーとしてモデルに送信し、モデルが最新の応答を生成する際にそれらを考慮できるようにします。会話が長くなると、モデルのコンテキストウィンドウの制限に近づき始めます。この時、Kiroは会話内のすべてのメッセージを自動的に要約し、コンテキストの長さを制限以下に戻します。
チャットパネルのコンテキスト使用メーターを使って、モデルのコンテキスト制限のどのくらいの割合が使われているかを把握できます。使用率がモデルの上限の80%に達すると、Kiroは自動的に会話をまとめます。
————————————————————–
[5]Claude Opus 4.5 support for AWS IAM Identity Center users – Kiro
–抜粋(日本語訳)——————————————
AWS IAM Identity Centerユーザー向けのClaude Opus 4.5サポート
us-east-1 および eu-central-1 リージョンの両方で、AWS IAM Identity Centerユーザー向けにClaude Opus 4.5のサポートを追加しました。Claude Opus 4.5はKiro IDEとKiro CLIの両方で利用可能です。
————————————————————–