

こんにちは、SCSK小澤です。
生成AIを利用して自然言語によるデータ検索や要約を可能にしてくれる、Snowflake Intelligenceが一般提供(GA)になりました。
前回のブログでは、Snowflake Intelligenceの概要紹介や、伴走支援のご案内していました。
→ SCSKはSnowflake Intelligenceのローンチパートナーとなりました!

SCSKでは、社内のデータ活用基盤としてもSnowflakeを採用しており、Snowflake Intelligenceの利用についても取り組んでいます。
今回はSnowflake Intelligenceの活用PoCを始める流れについてご紹介いたします!
SCSKの社内データ活用
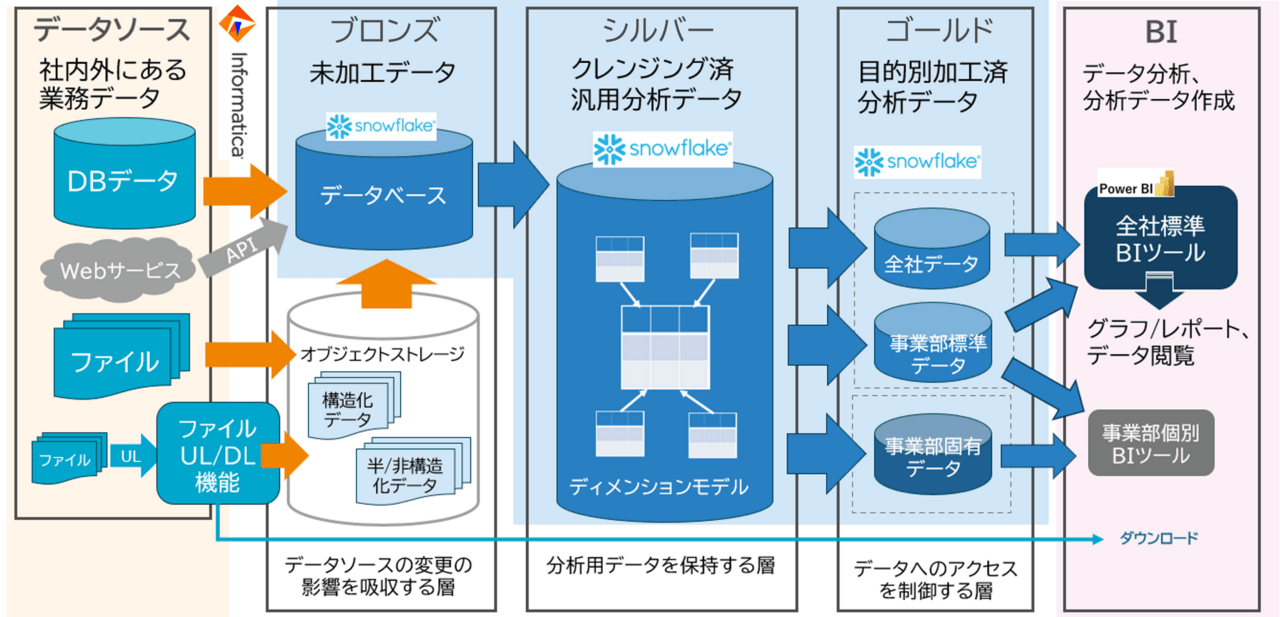
データ活用のアーキテクチャ
SCSKでは、以下のようなメダリオンアーキテクチャをSnowflake上に構築してデータを管理しています。
- ブロンズ層: ファイルやシステムのデータベースなど、データソースのデータをそのまま保持する
- シルバー層: 分析しやすいように整形した、汎用的に利用可能なテーブルがある層
- ゴールド層: BIで可視化するために、ダッシュボードごとに作成するテーブルがある層
ゴールド層に作成したテーブルをBIツール(Power BI)でインポートして、ダッシュボードを作成しています。
定型ダッシュボード作成によるデータ活用の課題
定型ダッシュボード作成に基づくデータ活用には以下のような課題があります。
- ダッシュボード公開までのリードタイムが長い
ニーズの把握からダッシュボードの公開まで、レイアウト検討・データモデリング・ストアドプロシージャ作成・BIツールでの実装など、ダッシュボード開発には必要な工程が多くあります。簡単な集計値の可視化であっても、実際に見たいデータが見れるようになるまでには、リードタイムが発生します。 - 限定的な分析軸での分析しかできない
ダッシュボードでは、組織別や年度別など、あらかじめ決められた分析軸での集計値しか確認することができません。たとえば、売上が伸びた要因を分析したくても、ダッシュボードで表示されている以上の情報を得ることはできず、発生事象の理由を分析することが難しいです。 - そもそもダッシュボードで情報を探すことが面倒
私たちはプライベートでも業務でも、なにかを知りたいときにはまず生成AIに問い合わせるようなりました。チャットベースでの検索に慣れすぎてしまいました。ダッシュボードを量産しても、ユーザは自分が欲しい情報があるダッシュボードがすぐに見つけられないとストレスを感じ、データ活用のモチベーションが下がってしまいます。
このように、定形ダッシュボード作成によるデータの可視化だけでは課題があります。
「必要な情報にすぐにアクセスできること」「多角的な分析が容易にできること」が、今後のデータ活用に求められています。
Snowflake Intelligenceの導入
Snowflake Intelligenceは、そんな課題を解決してくれるサービスです。
SCSKの社内データ活用においてもダッシュボードの作成と並行して、Snowflake Intelligenceの活用検討を行いPoCを開始しました。
Snowflake Intelligenceは、以下のような全体像になります。
一番下のDataから辿って、Snowflake Intelligenceに表示するまでの流れをご紹介します!
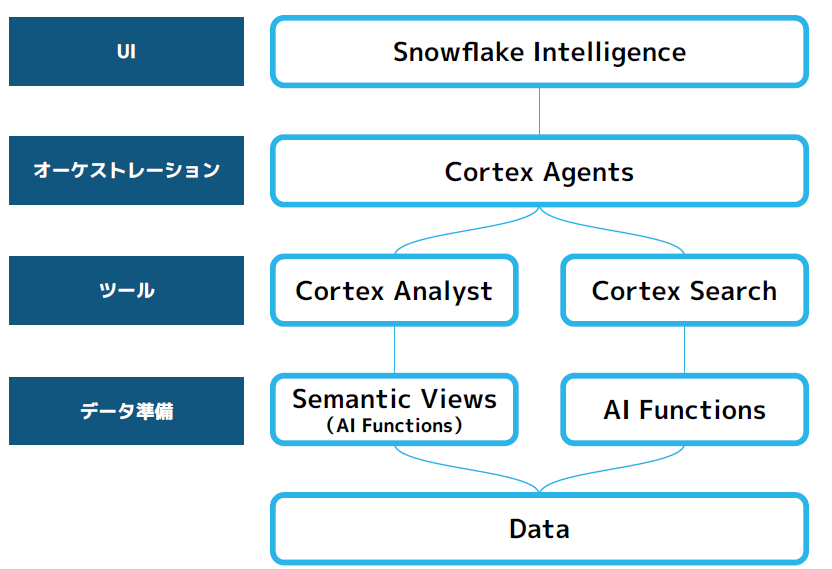
Data:分析対象とするデータの選定
メダリオンアーキテクチャにおけるシルバー層は、汎用的に利用できるテーブルを保持する層でした。
ダッシュボード開発では、このシルバー層のテーブルをもとにダッシュボード用のテーブルをゴールド層に作成しますが、当プロジェクトではSnowflake Intelligenceからこのシルバー層のテーブルにそのままアクセスできるようしました。
これにより、ユーザーが自由に問い合わせても幅広い分析軸での返答を得ることができます。
ディメンショナルモデリングに基づき、すでに約100以上のファクト/ディメンションのテーブルを用意していましたが、PoCとしてはそのうちの、PLデータ・引合データ・予算データなど主要なテーブルを対象に絞ることとしました。

データ準備:Semantic Viewの作成
先ほど選定したテーブルを対象に、Semantic Viewを作成します。
Semantic Viewの作成はファクトテーブルだけでなく、関連するマスタテーブルの作成も必要になります。
そのため、今回PoCとして選定したファクトテーブルは5テーブル程でしたが、それぞれのファクトテーブルに関連するマスタテーブルも含めると、約15テーブルのSemantic Viewの作成が必要になります。
それぞれのテーブルのカラムには数十のカラムがあり、Semantic Viewの作成を愚直に行っていると、PoCがなかなか始められません。
そこで、Snowflake 菅野様が公開されているSnowflake のセマンティックビューを AI で自動生成しようのストアドプロシージャで、Semantic Viewを自動作成することとしました。
各テーブルのSemantic Viewを作成した後、それぞれのSemantic View間(ファクトテーブル – マスタテーブル間)のリレーションの設定が必要になります。
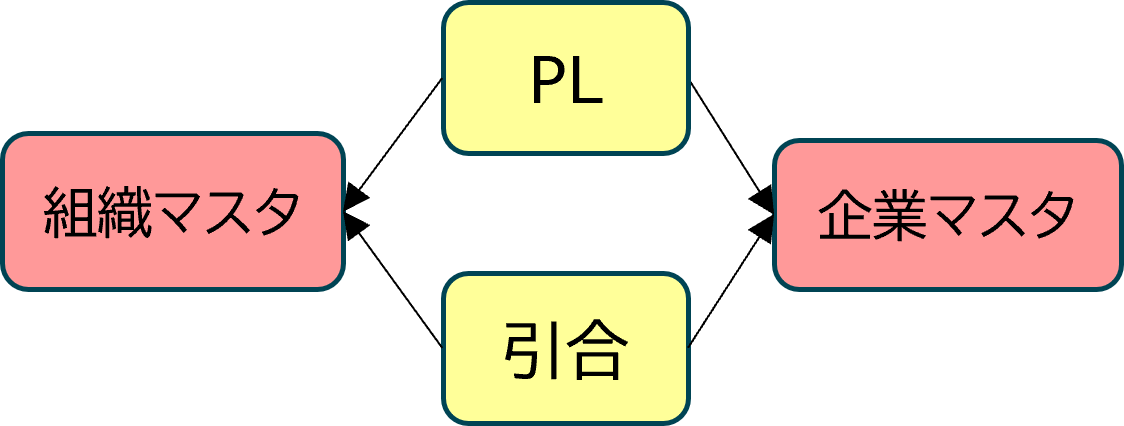
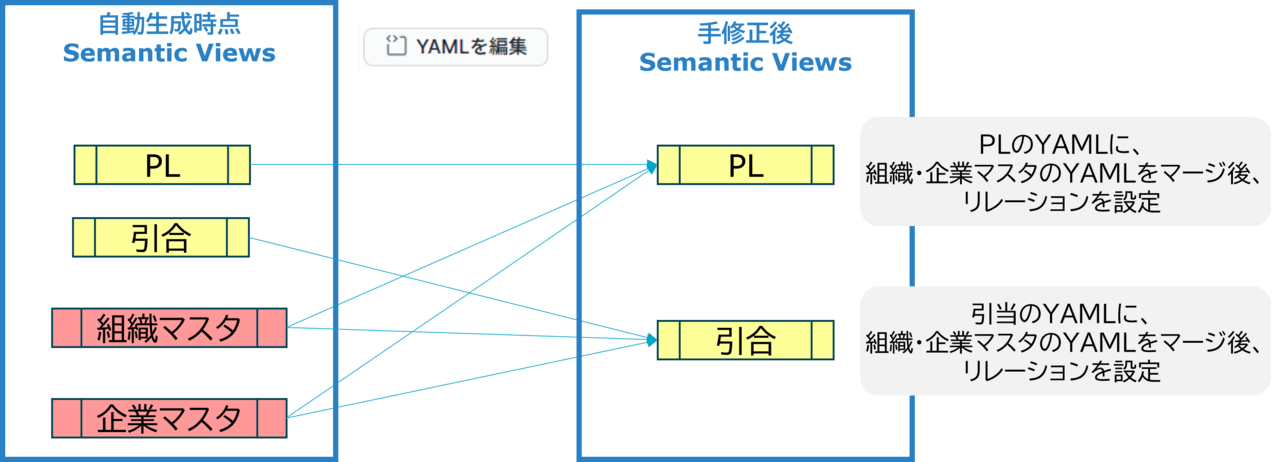
リレーションの設定には、同じSemantic Viewの定義内にリレーションの設定先のマスタテーブルの定義も含めておく必要があります。複数のファクトテーブル(PL、引合)から同一のマスタテーブル(組織マスタ、企業マスタ)を参照する場合もありますが、それぞれのファクトテーブルの定義ごとに、マスタテーブルの定義を含めておく必要があります。
そのため、以下のように作成されたマスタテーブルのYAML定義をコピーして、ファクトテーブルのYAML定義内にマージさせていく必要があります。その後、マスタテーブルへのリレーション設定を行います。
オーケストレーション:Cortex Agentsの作成
作成したSemantic Viewを元に、Cortex Agentを作成します。
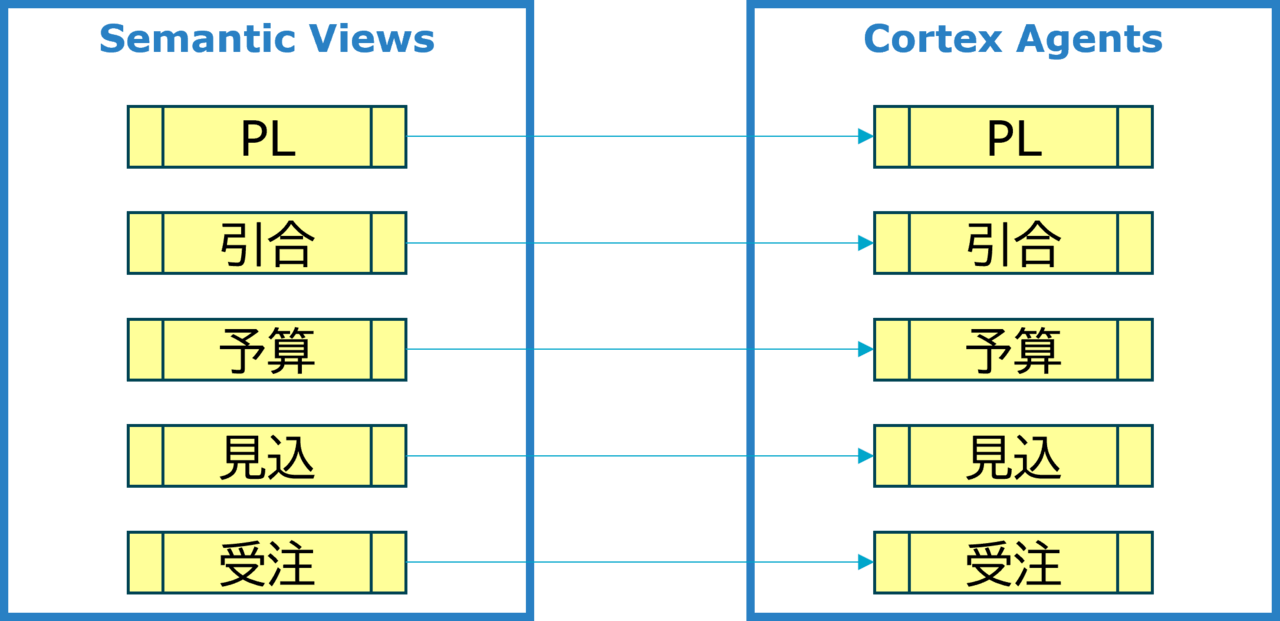
Snowflake Intelligenceの回答精度を上げるためには、関連のないデータのSemantic Viewを1つのCortex Agentに詰め込むべきではありません。
そのため、今回はPLエージェント、引合エージェントなど、Semantic ViewのそれぞれでCortex Agentを作成しています。
ユーザには、Snowflake Intelligenceの画面上から問い合わせたい内容に合ったエージェントを選択してもらいます。
ただし、それぞれのCortex Agentに対して1つのSemantic Viewsを作成していると、汎用的に回答できるはずのエージェントとしての有用性が薄れてしまう部分もあるので、どのようにCortex Agentにまとめていくかは考察の余地があります。
Cortex Agentsの設定では、「オーケストレーション手順」の設定も重要になります。
たとえば、”年度単位で売上を集計して下さい”と問い合わせた場合、1~12月で集計されてしまうため、4~翌3月で集計してもらいたい場合には以下のような「オーケストレーション手順」の設定を行います。
“年度”単位での集計・可視化の依頼が来た場合には、4月から3月の12カ月を集計期間として、分析をお願いいたします。例えば、2024年度の売上分析をしてください。という質問に対しては2024年4月から2025年3月までの集計期間で売上を分析するようにしてください。
Snowflake Intelligenceの利用デモ
Snowflake Intelligenceを実際に利用してみます。
PLに関する問い合わせを行いたいため、エージェントは「PL」を指定しておきます。
まずは、利益率の経年推移をみてみます。
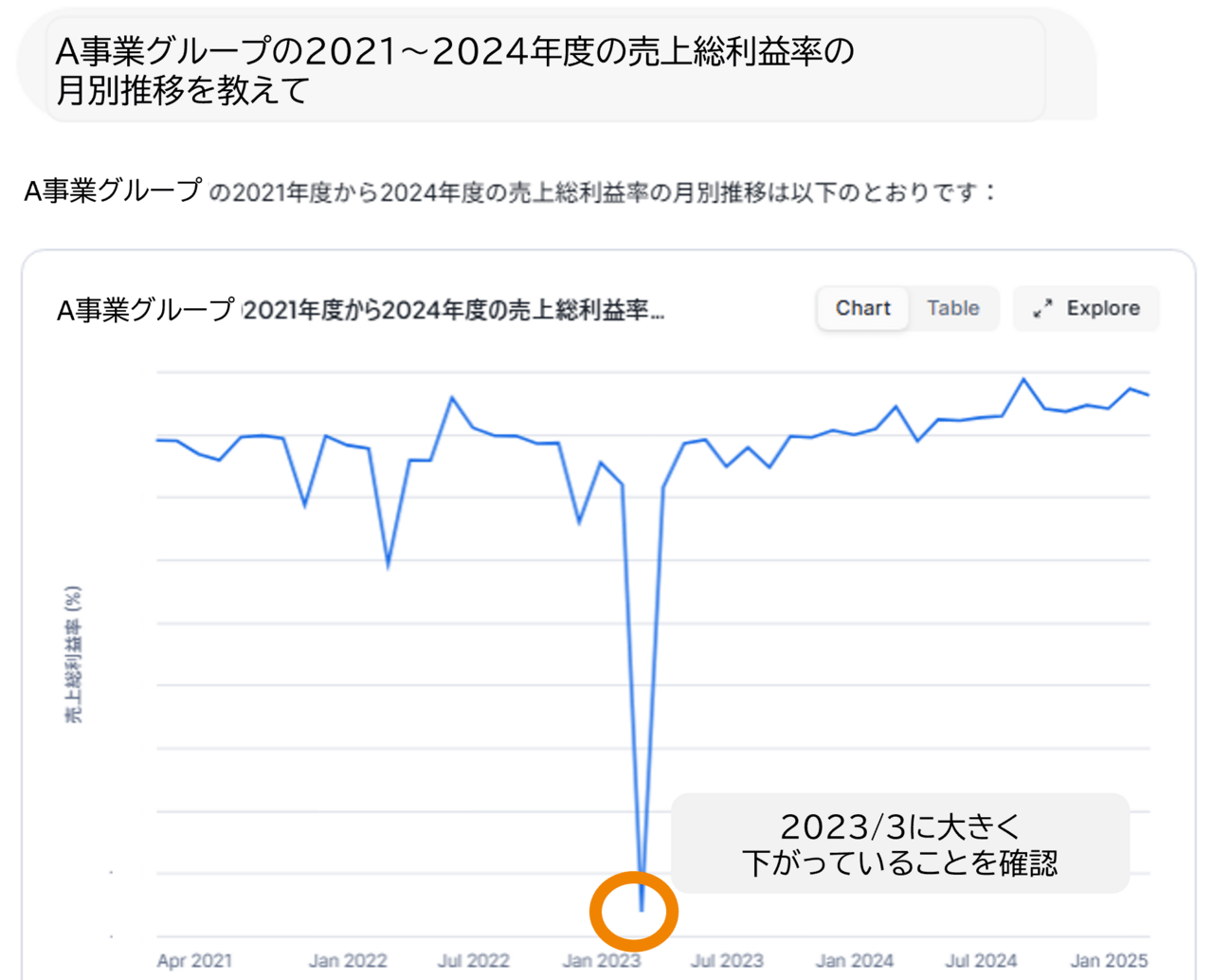
すると、2023/3に利益率が大きく下がっていることが確認できました。
ここまでは定型ダッシュボードでも確認できますが、ここから”なぜそうなっているのか?”を深堀して分析していくようなことは、Snowflake Intelligenceでないとできません。
次に、2023/3に利益がワースト3の案件を取得してみます。

特定の案件が抽出できました。
このワースト1位の案件について、月別の利益の傾向を見てみます。
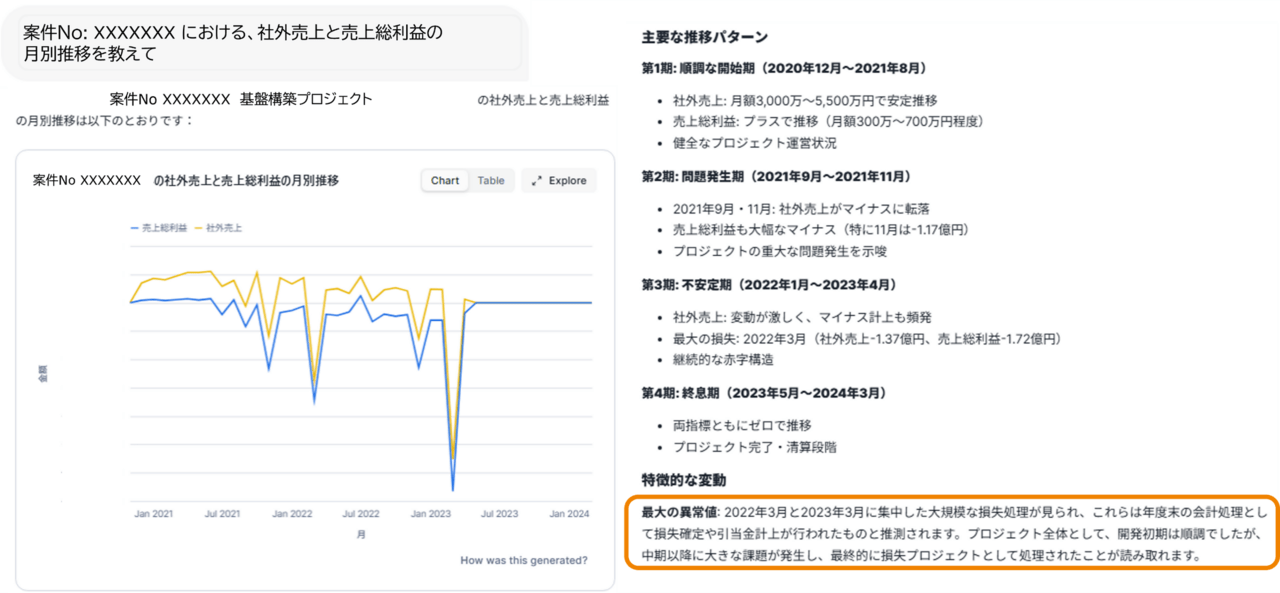
Snowflake Intelligenceで、グラフでの可視化に加え、トレンドの分析やなぜそのようになったかの推察まで行ってくれています。
このSnowflake Intelligenceの分析結果を踏まえて、
- AIによる考察を案件担当者に事実確認
- 案件悪化パターンを分析
- 悪化の変調をとらえるKPI設定し、ダッシュボードに追加
- 悪化案件が多い組織の特徴抽出
など、実際にビジネスへのアクションにつなげていくことが考えられます!
精度向上のためのポイント
Snowflake Intelligenceを実際に業務で利用していくには、回答速度や精度を向上させていく必要があります。
- 回答速度
現状は回答までに30秒以上かかっています。モニタリングから内訳を確認してみると、「SQL実行」は5秒程度ですが、それ以外の「LLMの計画」「LLM応答生成」の時間が多く占めています。
このような場合、ウェアハウスの性能を上げても大きな改善は見られず、LLMの回答速度を向上させていく必要があります。LLMの回答速度を向上させるためには、想定される質問をあらかじめ「検証済みクエリ」として登録しておくことが重要です。

- 回答精度
AI機能を使って自動生成したSemantic Viewをそのまま使っているため、まだまだ回答された数値の精度が出ていません。
回答の精度を向上させるには、実行されたクエリを確認して正しいものは「検証済みクエリ」として登録したり、間違っている場合は同義語を見直すなど、地道な調整が必要になります。
Semantic View精度向上のために、主に以下の設定を見直す必要があります。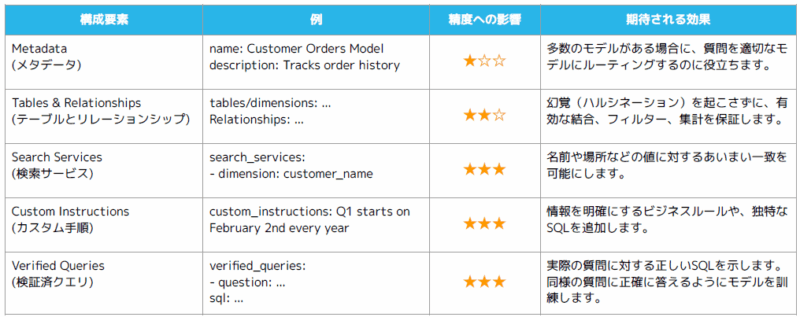

まとめ
Snowflake Intelligenceを実際に利用するまでの手順についてご紹介しました。
社内のデータ活用における現状としてはまだまだ回答の精度が得られず、Semantic Viewの設定見直しなどを行っています。
回答精度を向上させるための具体的な手順についても検証ができたら、また共有させていただきたいと思います!