

こんにちは、SCSKのhosynary(江浜)です。
SCSKでは現在、社内のデータ活用基盤としてSnowflakeを採用しており、Snowflake Intelligenceの利用についても検証を行っています。Snowflake Intelligenceを使って社内データ活用のPoCを始める – TechHarmony
特に回答精度については、現在運用中の定型ダッシュボードと同じデータモデルを参照したうえで、Snowflake Intelligence上で同等のインサイトを得ることができるか、といった観点でいくつかの品質確認項目を設けて検証を行っています。
検証を進める中で、
なぜ数値が合わないのか
なぜ意図した回答にならないのか
といった課題に直面しました。
本記事では、検証を通じて見えてきたSnowflake Intelligenceの運用においてチューニングが発生する可能性が高いポイントを、3つの観点から整理してみました。
Snowflake Intelligenceのチューニングポイント
運用の中でチューニングが発生するポイントは、大きく次の3つです。
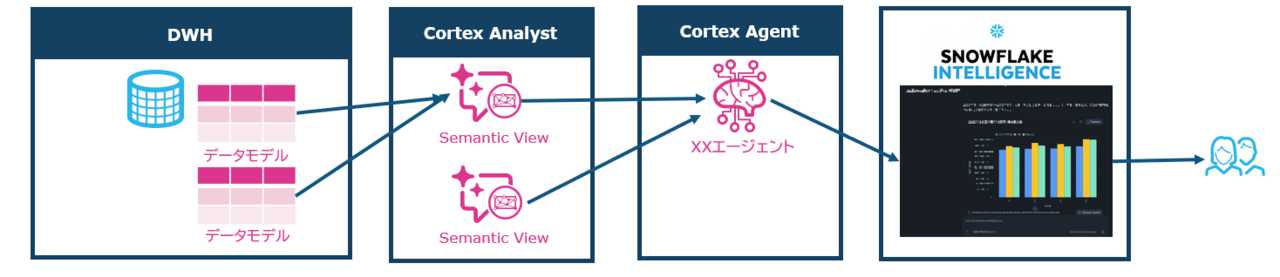
- Cortex Agent
- Semantic View
- データモデル
いずれもSnowflake Intelligenceの出力精度や使い勝手に直結する重要な要素です。
ここから、それぞれの項目についてチューニングポイントを述べていきます。
Cortex Agent
役割
Cortex Agent は、ユーザーからの自然言語による問い合わせを全体としてどのように解釈するかを制御する役割を担います。
使用するSemantic Viewの選択やWeb検索の有効/無効といったエージェント自体の設定だけでなく、
- 年度の考え方(例:4月~翌年3月を1年度とする)
指標の解釈ルール
分析時の前提条件の明文化
など、エージェントの出力全体に関わる共通ルールを定義します。
チューニングが必要になるタイミング
- 全体的に意図しない回答が生成される場合
- 回答内容がタイミングによってぶれる場合
こうしたケースでは、Cortex Agent側で定義内容を修正する対応が必要になります。
主な設定内容
- 会計等に関わる統一ルール
- 年度の考え方や、「売上」「売上高」「収益」は本システムでは同義語として扱う等同義語のルール
-
設定例イメージ
「“年度”という表現が使われた場合は、4月から翌年3月までの12か月を対象として分析する」
- 回答できない場合の設定
-
設定例イメージ
「データが不足している、または定義が曖昧な場合は、推測で回答せず「確認が必要」である旨を明示する。」
-
これらに加え、一般的にAIエージェントで広く設定されている項目についても、あわせて定義しておくことが重要です。
検証で見えてきたポイント
- 出力全体に関わる部分であるため、なるべく初期構築段階で必要そうな設定項目を洗い出しておくことが重要
- 修正自体は容易
Semantic View
役割
Semantic Viewは、Snowflake上のデータモデルをAIに解釈させるためのセマンティックレイヤーです。
- どのテーブルが何のデータか
- どのカラムがディメンションか/メトリクスか
- どの質問にどういったSQLを使うべきか
といった情報をyamlファイル等で定義します。
チューニングが必要になるタイミング
- データモデルが更新された場合
- 一部の質問で、意図しないSQLが生成される場合
- 合計値や指標の解釈がずれる場合
こうしたケースでは、Semantic View側でメトリクスや説明、検証済みクエリを修正、追記する対応が必要になります。
主な設定内容
- 質問パターンごとの参照先テーブル指定
- 「質問の分類化」欄を修正することで内容に応じてどのテーブルを参照させるか自然言語で定義することが可能です。
-
設定イメージ
「“組織別の売上に関する質問はXXXXを、品目別の売上に関する質問はXXXXXのテーブルを参照してください」
- メトリクス定義(合計・平均・条件付き集計など)の設定
- 「ディメンション」、「ファクト」、「メトリック」欄を修正することでどのカラムが何を表しているか、言葉の定義が何をもって計算されているか(計算ロジック)をカラム名やSQL関数等を用いて定義することが可能です。
-
設定イメージ
<任意のファクト名>
予算に対する見込の達成率。単位はパーセント
<見込値を表すカラム> / NULLIF(<予算値を表すカラム>, 0) * 100 ·NUMBER(29,9)
- 検証済みクエリ(想定SQL)の追加
- 検証済みクエリは質問内容とその際に実行する想定SQLをあらかじめ設定しておくことでより正確な回答を生成してくれます。
- 設定しておくと、質問に似ている場合にのみ検証済みクエリは使用され、レイテンシの低減にも繋がります。
-
設定イメージ
質問例:2025年度の計上済の売上推移について社外と社内売上の合計を月ごとに累積値で棒グラフで表現してください
SQL例:~
検証で見えてきたポイント
- Semantic Viewは既存のデータモデルから自動生成しただけでは完結しないケースが多く、正確なチューニングには社内ルールの把握や、業務・データへの理解が不可欠です。そのため、運用フェーズでは最も作業頻度が高くなりやすいポイントと言えます。
- 現状は公開いただいている自動生成プロシージャ(Snowflake のセマンティックビューを AI で自動生成しよう)や、Semantic View Autopilotを用いて初期で作成をしたのちに、出力やSnowflake Intelligenceのログを確認して正しい解釈を加えるチューニングを実施中です。
- 今後はCortex Code等のAI駆動型ツールや、Cortex Search等のテキストデータに特化した検索ツールを組み合わせて、連携先システムの設計書・仕様書、業務ロジック、社内定義を埋め込んだSemantic Viewを効率的に作成して、正しい解釈を加えていく方式を検討する必要があるなと考えています。
データモデル
役割
データモデルは、Snowflake Intelligenceが参照する実テーブルを指します。
出力の土台のようなものなので、ここが不安定だとどれだけAgentやSemantic Viewを調整しても限界があります。
チューニングが必要になるタイミング
- 分析対象データの拡大
- 新しい分析軸の追加
- 既存データの粒度や構造が合わなくなった場合
これらに対応するため、
- 新規テーブルの追加
- 既存テーブルへのカラム追加
- 集計・明細テーブルの分離
といったSQLによるデータモデル(テーブル定義)の修正が必要になります。
検証で見えてきたポイント
- AIが誤認しにくいよう、意味が明確で一貫性のあるデータモデルを整備することが重要だと感じています。
- 特に参照先がBIツール前提のデータモデルの場合、BI上では表示制御することで問題ないようなデータの持ち方でも、AIでは誤認識されるようなケースが出てきます。例えば合計値と明細が同一のテーブルに格納されていることで合計値を出力する際の2重計上されるケースや、年月の表記をBI出力用に文字列型に変換してあることで月次での出力結果が意図しない結果を出力するケースなどがあります。
- 意図しない出力に対して随時Semantic Viewに解釈を加えていくアプローチは、今後増えていく全てのSemantic Viewやエージェントに対して修正が増えていくことに繋がるので、元のデータモデルを見直すことは大きい意義を持ちます。
- またデータモデルから構築する場合はAI側が正しく理解できるようにモデルやカラムの命名についても留意する必要があります。
- 構築ルールや命名規則等を明確にし、Semantic View等と合わせてAIも人も理解しやすいデータモデルとして整備していくことが重要かと思います。
まとめ
Snowflake Intelligenceは導入すればなんでも正確に回答をしてくれるツールではありません。
- Cortex Agent
- Semantic View
- データモデル
この3層を運用しながら育てていくことが重要です。
一方で、これらの整備や運用に時間がかかりすぎてしまっては本末転倒です。
今後の課題として効率のよい開発方式や構成管理方式、運用方式を合わせて検討していくことが必要だなと感じています。
導入検討中の方、すでに検証を進めている方の参考になれば幸いです。