

LifeKeeperの『困った』を『できた!』に変える!サポート事例から学ぶトラブルシューティング&再発防止策
こんにちは、SCSKの前田です。
いつも TechHarmony をご覧いただきありがとうございます。
前回の記事では、DataKeeperを用いたレプリケーション構成において、多くのエンジニアが最初に突き当たる壁である「ミラー同期中のフェイルオーバー挙動」や「性能評価の考え方」について解説しました。
DataKeeperによるリアルタイムなデータ同期は、障害発生時のデータ損失を最小限に抑えるための強力な手段です。しかし、実際の運用現場では、リアルタイム同期だけでは補いきれない「過去の特定時点への復旧」――すなわちバックアップとリストアの運用が不可欠となります。
クラウド環境においては、AWSやAzureが提供する「スナップショット機能」を利用したバックアップが一般的ですが、ここにDataKeeperが介在すると、運用は一気に複雑さを増します。 「スナップショットを取得しても、DataKeeperのミラーに影響はないのか?」「バックアップからデータを戻したはずなのに、なぜミラーが再開されないのか?」
こうした疑問やトラブルは、DataKeeperが「ディスクのセクタ単位でデータを管理している」という特性を、バックアップソフトやOS側が必ずしも意識していないことから発生します。
本連載カテゴリ4の第二弾となる今回は、データ保護の核心をさらに深掘りし、「バックアップ連携とリストア手順」にスポットを当てます。現場で実際に起きた事例をベースに、システムの「復旧」を確実なものにするための知恵を共有していきます。
💡 前回の記事(カテゴリ4 第1弾)はこちら!
▶【DataKeeper:ミラー同期とデータ保護の核心 #1】同期中だから切り替わらない!?フェイルオーバーの「絶対条件」と性能評価の罠 – TechHarmony
はじめに
今回の記事のテーマは、DataKeeper環境における「バックアップと復旧」です。
レプリケーションによって「常に最新のデータ」を維持していても、アプリケーションの誤操作やランサムウェア対策、あるいは大規模な環境移行の際には、バックアップからのリストアが必要になります。 しかし、DataKeeperボリュームに対してスナップショットやVSS連携を行う際には、特有の制限事項や作法が存在します。
この記事では、以下の3つの重要なステップを軸に、運用設計で絶対に外せないポイントを学びます。
- バックアップ時の盲点: クラウドのスナップショット機能やVSS連携がDataKeeperに与える影響
- リストア時の整合性: データを戻した後に必要となる「ミラー情報の同期」の重要性
- 環境移行の落とし穴: 物理変更やディスク付け替え時に確認すべき隠れたチェックポイント
「バックアップは取っていたけれど、リストア後のDataKeeperが上手く動かない……」そんなトラブルを未然に防ぎ、自信を持って運用できる状態を目指しましょう。
今回の「困った!」事例
バックアップと復旧に関連して、特に現場での判断が分かれやすい3つのケースを紹介します。
ケース①:AWSのVSS連携スナップショットは使っても大丈夫?
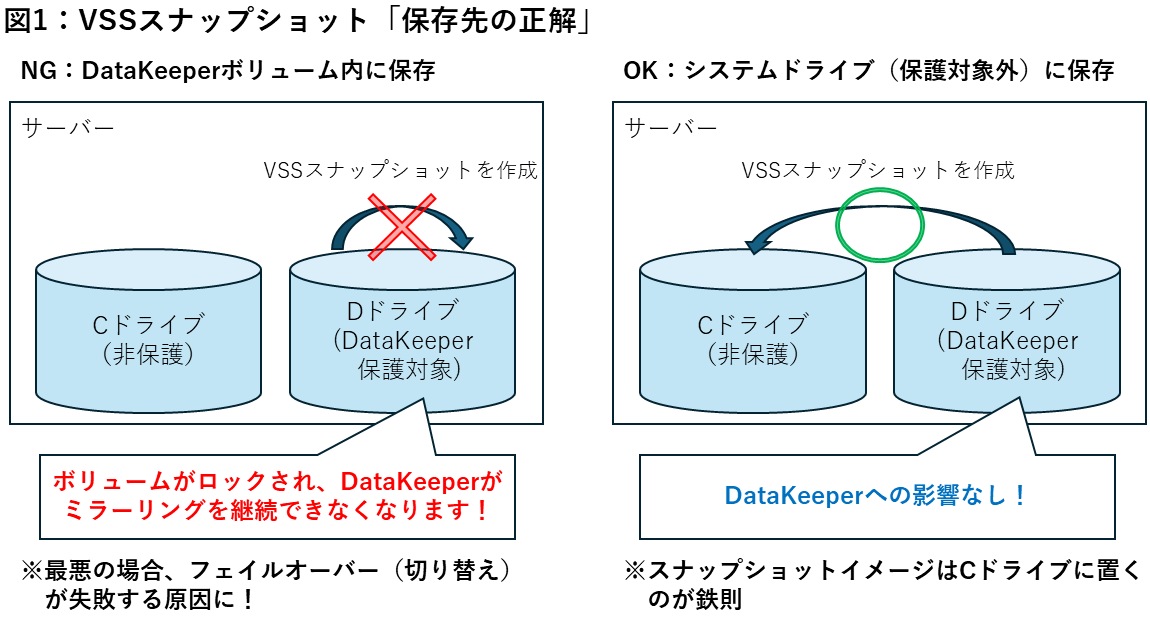
【事象の概要】 AWS環境で、VSS(Volume Shadow Copy Service)を利用したスナップショットを取得しているが、DataKeeperのマニュアルに「VSSスナップショットイメージを保存できない」という記述を見つけ、今の運用が制限事項に抵触しないか確認したい。
【原因究明と回答】 DataKeeperの制限事項にある「保存できない」とは、VSSのメタデータやスナップショットイメージ自体を、DataKeeperが保護しているボリューム(Dドライブなど)の中に保存することを指します。 AWS VSSスナップショットの場合、AWSが一時的に静止点を取るものの、イメージ自体はEBSの外側に保存されるため、基本的には問題ありません。ただし、設定ミスで「スナップショットの保存先」をDataKeeperボリュームに指定してしまうと、ボリュームがロックされ、フェイルオーバーが正常に行えなくなります。
ケース②:DataKeeper管理のドライブをスナップショットからリストアする際の注意点
【事象の概要】本番稼働中のシステムにて、データベースのマイナーバージョンアップ作業を実施しました。しかし、作業中にプログラムが異常終了し、データファイルの一部が破損して起動不能になるトラブルが発生しました。
個別にファイルを復旧させるよりも、作業直前にAWSスナップショットで取得していた「正常な状態のEBSボリューム」ごと差し替えてロールバック(作業前の状態へ巻き戻し)を行うのが最善と判断し、ディスクのリストアを実施しました。
ここで疑問となったのが、「ディスクを差し替えただけで、DataKeeperやLifeKeeper側の対応は完了と言えるのか?」という点です。
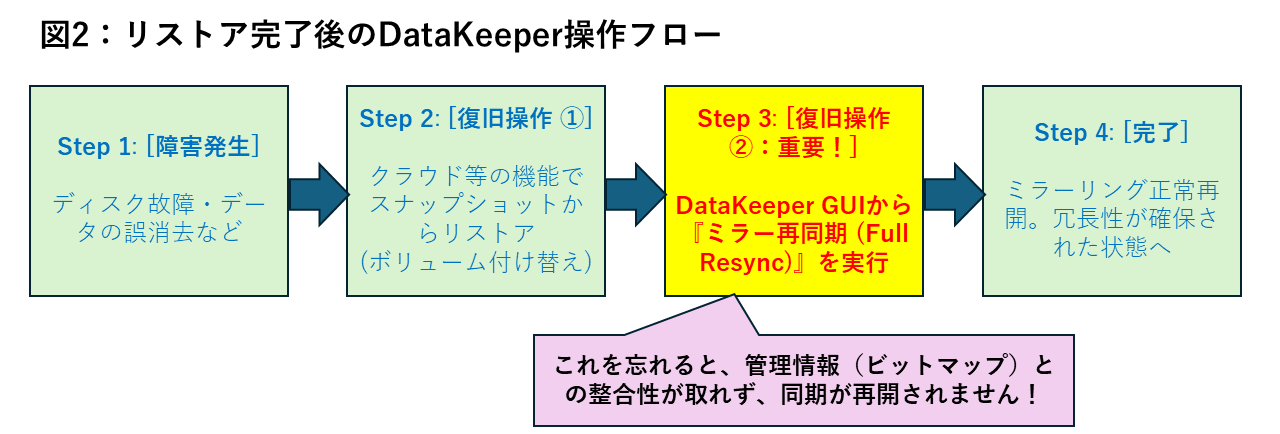
【原因究明と回答】DataKeeperは、ファイルシステムを介さずディスクの最小単位である「セクタ(ブロック)」に対して直接レプリケーションを行う仕組みです。そのため、OSの外側で行われた「スナップショットによるボリュームの差し替え」を、DataKeeperは検知することができません。
この状態で運用を再開すると、DataKeeperが管理している同期情報(ビットマップファイル)と、実際のディスクの中身に乖離が生じ、データの整合性が保てなくなります。
これを防ぐためには、リストア後に以下のいずれかの対応が必要です。
- 対応A:ドライブレター(E:など)に変更がない場合 DataKeeperは「中身が入れ替わったこと」に気付きません。そのため、手動で「ミラー再同期(Full Resync)」を実行し、強制的に全体の整合性を確保してください。
- 対応B:ドライブレターが変更された場合 DataKeeperリソースの定義そのものを修正する必要があります。既存のリソースを一旦削除し、新しいドライブレターで再作成してください。
※リソース再作成のプロセス内で「初期同期」が自動的に行われるため、別途手動での再同期は不要です。
ケース③:非同期モードでの自動フェイルオーバーでデータは壊れない?
【事象の概要】 「非同期モード」運用中にソース側が急停止した場合、未転送データはどうなるのか?ファイルシステムやDB(Oracle等)が壊れて起動しなくなるリスクはないか?
【原因究明と回答】 非同期モードで未転送データがある状態でフェイルオーバーが発生すると、そのデータは破棄されます。しかし、DataKeeperは「書き込み順序(Write Order)」を厳守して転送するため、ターゲット側のディスクは「ある一瞬で突然停電した状態(クラッシュ一貫性)」と等価になります。 現代のNTFSやDB(Oracle等)は、この状態からリカバリする機能を持っているため、ファイルシステム全体が認識不能になるような致命的な破損は防げますが、直前の更新データは失われるというリスクを理解しておく必要があります。
「再発させない!」ための対応策と学び
バックアップ・リストア運用で失敗しないための、エンジニア向けチェックリストを作成しました。
【運用・設計チェックリスト】
- バックアップ時
- VSS保存先の分離: VSSイメージの保存先は必ずシステムドライブ(Cドライブ等)にし、DataKeeperボリュームを保存先に指定しない。
- 非同期モードのリスク許容: RPO(目標復旧時点)の観点から、数秒~数分のデータロスが許容できるか再確認する。
- リストア・移行時
- 「迷ったら再同期」: リストア後、少しでもデータに不安があれば必ず「全ミラー再同期」を実施する。
- セクタ数のチェック(Linux): リストア先の新規ディスクが、元のディスクと「総セクタ数(偶数であること)」まで一致しているか確認する。
- ライセンスのRehost: ハードウェア(NIC等)が変わる移行では、ライセンスの再取得(Rehost)手順を事前に確認しておく。
ベストプラクティス
バックアップは「取ること」よりも「戻すこと」が難しいものです。DataKeeper環境では、データの戻し(リストア)作業と、DataKeeperのミラー状態(ビットマップ)の同期はセットで考えるべきです。「リストアが終わったら、管理情報の整合性を取るために手動でミラー再同期を行う」という手順を標準化してください。
まとめ
DataKeeperは強力なデータ保護ツールですが、スナップショットやバックアップソフトと組み合わせる際には、その「ブロックレベルで同期している」という特性を意識することが大切です。
「日々の運用でここを意識すれば、いざという時の復旧で慌てることはありません!」 今回紹介した事例を参考に、貴社のバックアップ運用を一度見直してみてはいかがでしょうか。
次回予告
データの保護(DataKeeper)について学んだ次は、クラスタが「誰が稼働系か」を正しく判断するための知恵を学びましょう。
次回の連載テーマは、クラスタの健全性を維持する「番人」の役割に焦点を当てます。
「カテゴリ5:Quorum/Witnessとコミュニケーションパス:クラスタ健全性維持の要」
その第一弾として、「記事案1:クラスタの番人Quorum/Witness:正しく理解し、正しく設定する」をお届けします。
- S3、共有ディスク、Witnessサーバ……自分の環境に最適なQuorumはどれ?
- 「Quorum喪失」が発生すると、クラスタはどう動くのか?
- 意外と知らない、ディスクパーティションやアラート設定の注意点
など、実例をベースに、システムの「意思決定の要」であるQuorum/Witnessのディープな世界を解説します。また、後続の記事では、誰もが恐れる「スプリットブレイン」を防ぐためのコミュニケーションパス設計についても触れていく予定です。
お楽しみに!
📚 本連載のバックナンバー
過去のトラブル事例と解決策もぜひあわせてご覧ください!
カテゴリ1:リソース起動・フェイルオーバー失敗の深層
▶【リソース起動・フェイルオーバー失敗の深層 #1】EC2リソースが起動しない!クラウド連携の盲点とデバッグ術 – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #2】ファイルシステムの思わぬ落とし穴:エラーコードから原因を読み解く – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #3】設定ミス・通信障害・バージョン違いの深層と再発防止策 – TechHarmony
カテゴリ2:OS・LKバージョンアップで泣かないために
▶【OS・LKバージョンアップで泣かないために #1】OSバージョンは変えていないのに!?カーネル更新の「落とし穴」と互換性の真実 – TechHarmony
▶【OS・LKバージョンアップで泣かないために #2】「設定が消えた!?」「亡霊IPが警告!?」を防ぐロードマップ:単純な上書き更新に潜む落とし穴と回避策 – TechHarmony
カテゴリ3:クラウド環境特有の落とし穴
▶【クラウド環境特有の落とし穴 #1】良かれと思った自動復旧が仇に!?AWS環境(EC2/Route53/S3)でハマる構成と回避策 – TechHarmony
▶【クラウド環境特有の落とし穴 #2】オンプレ感覚の「同一サブネット」はNG!?Azure環境のネットワーク要件とQuorum設計の最適解 – TechHarmony
カテゴリ4:DataKeeper:ミラー同期とデータ保護の核心
▶【DataKeeper:ミラー同期とデータ保護の核心 #1】同期中だから切り替わらない!?フェイルオーバーの「絶対条件」と性能評価の罠 – TechHarmony
▶【DataKeeper:ミラー同期とデータ保護の核心 #2】スナップショットから戻したのに動かない!?リストア後の「整合性」確保とバックアップ連携の盲点
カテゴリ5:クラスタ健全性維持の要
▶【クラスタ健全性維持の要 #1】クラスタの番人Quorum/Witness:その設定、本当に必要? 正しく選んで正しく守る設計術 – TechHarmony