

こんにちは、SCSK林です!
昨今のデータ活用において、マルチクラウド環境でのデータパイプライン構築は珍しい要件ではなくなっていると思います。
今回紹介する事例でも、AWS上のシステムから発生する大量のストリームデータを、分析基盤であるGoogle Cloud(GCP)のBigQueryへリアルタイム連携するという要件がありました。
ソースとなるのは Amazon Managed Streaming for Apache Kafka (Amazon MSK)で、 当初、MSK Connectの採用を検討しましたが、最終的にはGoogle CloudのCloud Runを用いた独自Consumerの実装というアーキテクチャに落ち着きました。
本記事では、MSK Connectではなく独自実装を選択せざるを得なかった問題と、AWS-Google Cloud間を専用線でセキュアにつなぐためのアーキテクチャ設計の変遷について共有します。
初期構想:MSK Connect
当初構想していた構成は以下のとおりです。構成的にもマネージドサービスを使用しており申し分はなかったと思っています。
- Source:Amazon MSK
- Connector:MSK Connect (Sink Connector to Google Cloud Pub/Sub)
- Sink : Pub/Sub(Google Cloud)
- Network:AWS Direct Connect と Google Cloud Partner Interconnect を使用した専用線接続
※参考URL:https://docs.cloud.google.com/pubsub/docs/connect_kafka#convert-to-pubsub
技術検証の結果、専用線経由でのGoogle Cloudエンドポイントへの到達性や、基本的なデータ転送自体には問題がないことが確認できました。機能要件としては、MSK Connectで満たしている構成でした。
課金問題とアーキテクチャの転換
ただ、この構成ではサービス制約から以下の問題が生じました。
「1コネクタ = 1 Pub/Subトピック」の制約
今回採用しようとしたコネクタの構成上、「1つのMSK Connectリソースにつき、1つのPub/Subトピックへの連携しか定義できない」という制約がありました。
通常、Kafka Consumerであれば1つのプロセスで複数のトピックをSubscribeし、ロジックで振り分けることが容易です。しかし、MSK Connect(および該当のプラグイン)の仕様に準拠すると、連携したいトピックの数だけMSK Connect(Connector)を作成する必要がありました。初期フェーズではトピック数は10個ほどでしたが、次フェーズでは計100トピックまで拡張予定だったので、運用面からも受け入れられない状態となりました。
コストの大幅な増加
MSK Connectの課金体系は MCU (MSK Connect Unit) × 利用時間 です。
データ流量が少ないトピックであっても、コネクタを分割すれば最低1MCU分のコストが発生します。今回のシステムには多数のトピックが存在したため、それら全てに対して個別にConnectorを立ち上げると、MCUの総数がトピック数に比例して増加し、月額コストが想定以上に超過することが判明しました。
※参考URL:https://aws.amazon.com/jp/msk/pricing/
上記問題の解決:集約による効率化
上記制約から、解決策は「1つのコンピュートリソースで多対多(N対N)の処理をさばくこと」を実現する必要がありました。
- MSK Connectの採用断念:コネクタ管理の複雑さとコスト増が見合わないため。
- 独自実装(Cloud Run):コンテナベースのアプリケーションであれば、1つのConsumerグループで複数トピックをSubscribeし、メモリ上でPub/Subトピックへ振り分けるロジックを実装可能です。これにより、リソースを極限まで集約し、コストを圧縮できると判断しました。
最終アーキテクチャ:Cloud Run
最終的に採用したアーキテクチャは以下のとおりです。
- Consumer (Google Cloud):Cloud Run上にKafka Consumerアプリをデプロイ。
- Buffer (Google Cloud):取得したデータを一度 Pub/Sub へPublish。
- ETL (Google Cloud):Cloud Data Fusion が Pub/Sub からデータを読み出し、変換処理を行って BigQuery へロード。
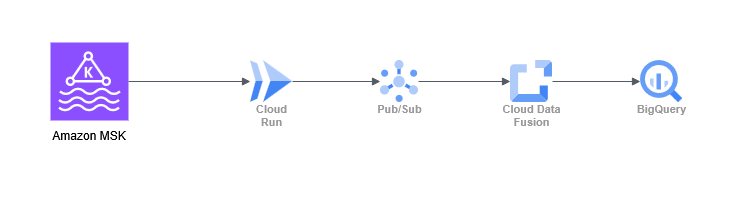
構成のポイントは以下の3点です。
Consumer Groupの集約によるリソース効率の最大化
MSK Connect(採用検討時のコネクタ)では「1コネクタ = 1トピック」という制約があり、トピック数に比例してコネクタ(MCU)が線形に増加する構造でした。これに対し、Cloud Runを用いた独自実装では、1つのコンテナアプリケーション(Consumer Group)で複数のトピックをまとめてSubscribeする方式を採用しました。
- Before (MSK Connect案):トピックごとにコネクタプロセスが起動。データ流量が少ないトピックでも最低限のMCUリソースを占有し、コスト効率が極めて悪い。
- After (Cloud Run案):1つのConsumerアプリで複数のトピックをSubscribe。メモリ空間を共有しながら効率的にメッセージを処理し、Cloud RunのCPU使用率ベースでオートスケールさせることで、リソースの余剰が少なくなるようにしました。
※今回はGoogle CloudのCloud Runで実装しましたが、AWS上での実装でもよいと思います。
Pub/Subをバッファとした「疎結合」なパイプライン
もう一つの重要な設計判断は、Consumerアプリ(Cloud Run)から直接BigQueryへ書き込まず、必ず Google Cloud Pub/Sub を挟む構成にしたことです。これにより、システムを「データ取得層」と「データ加工・ロード層」に明確に分離(疎結合化)しました。
- 責務の分離:
- Cloud Run (Consumer):「MSKからデータを取り出し、Pub/Subへ投げる」ことだけに集中。データの変換ロジックやBigQueryのスキーマ定義を持たないため、軽量かつステートレスに保たれます。
- Data Fusion (ETL):Pub/SubからデータをPullし、複雑な変換を行ってBigQueryへロード。
- 耐障害性の向上: 仮にBigQueryやData Fusion側で障害や遅延が発生しても、データはPub/Subに滞留(バッファリング)するだけです。Cloud Run(Consumer)は影響を受けず、AWS MSKからのデータ取得を継続できます。これにより、「AWS側のログ保持期間切れ(データロスト)」のリスクを最小限に抑える設計としました。
AWS-Google Cloud間のセキュアな接続
このアーキテクチャを支えるネットワークは、AWS Direct ConnectとGoogle Cloud Partner Interconnectを結ぶ専用線です。
AWS側のSecurity Groupでは、Google Cloud Cloud RunがデプロイされているサブネットからのInboundのみを許可し、かつConsumer Groupの集約によって接続元IPの管理もシンプルになりました。
まとめ
今回の最終的な構成は、おそらく初期検討段階では確実に外される構成だと思います。
機能的には要件を満たしていても、高トラフィック環境下、エンタープライズ環境ではコストがボトルネックになる場合があります。AWSの課金体系を深く理解し、全体的に適切な構成を選択していくことの重要性を改めて認識しました。
今回の構成、事例がどなたかのお役に立つと幸いです。