

こんにちは。SCSKの山口です。
今回は、BigQueryのテーブルにCSVデータを取り込む際、何度も遭遇したエラーたちと、その解消方法をご紹介します。
データを取り込む方法としては、下記「bq load」コマンドでGCS→BQに取り込むことにします。
| 実行コマンド |
| bq load –skip_leading_rows=1 [データセット].[テーブル] gs://[バケット/フォルダ]/[ファイル名] |
コマンドのオプション等、詳細情報は下記ドキュメントをご参照ください。
使用するテーブル情報です。
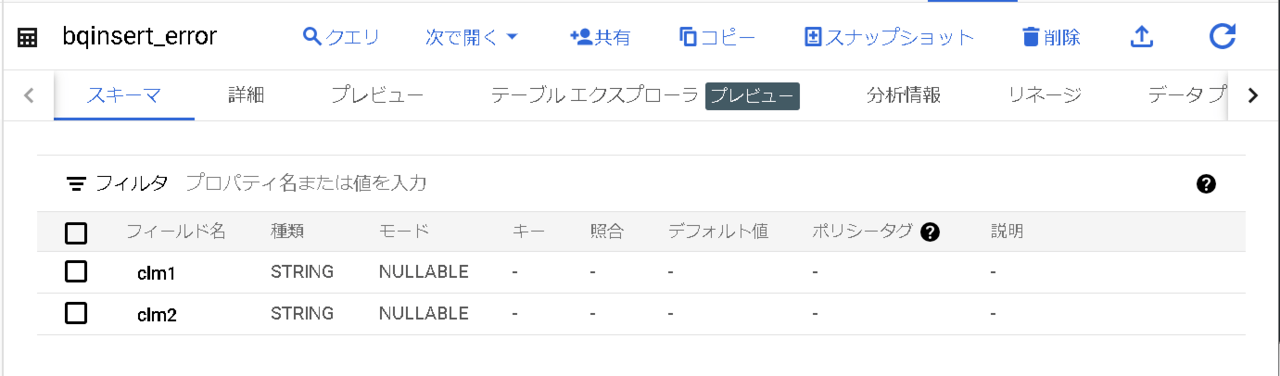
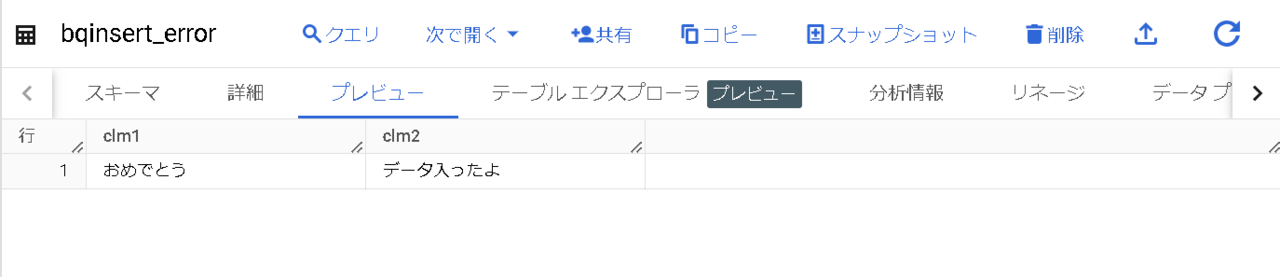
データが入ると祝福されます。
エラー①:データ内に「”」がある
原因データ
こんなデータの時に発生します。
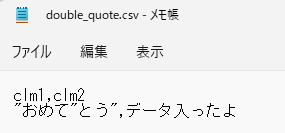
clm1(STRING)がご丁寧に「”」で囲まれているのと、濁点が「”」になってますね。(誰だこんなことしたのは。)
発生するエラー
こんなエラーが発生します。
エラー内容的には、「引用符(”)と区切り文字(,)の間になんか変なヤツが居るよ」みたいな感じですね。
構造化すると、最初の「””」のセットで囲まれている、
部分が「データ」として認識され、
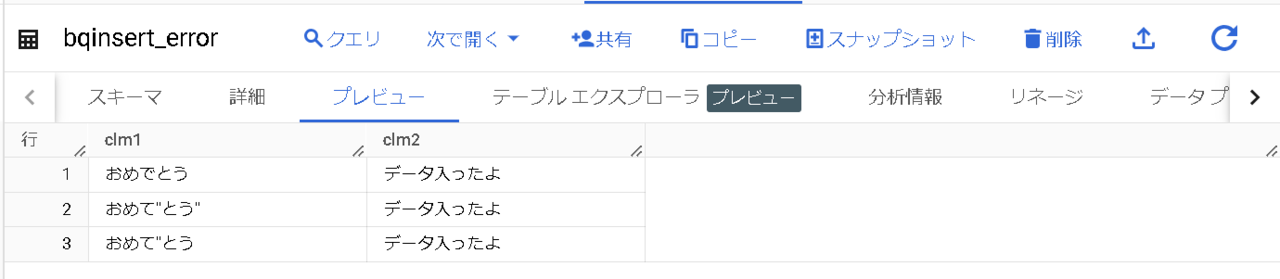
解消方法
入れたいデータに合わせて二パターン紹介します。
データ両端の「”」が不要な場合
BigQueryに「おめて”とう」の形で入れたい場合の解消方法です。
この場合は、データ内の「”」をエスケープしてあげることで解消できます。
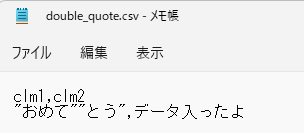
わかりづらいですが、データ内の「”」は前に「”」をもう一つつけることでエスケープ可能です。
| 実行コマンド |
| bq load –skip_leading_rows=1 yamaguchi_blog.bqinsert_error gs://yamaguchi_blog_bqerror/double_quote.csv |
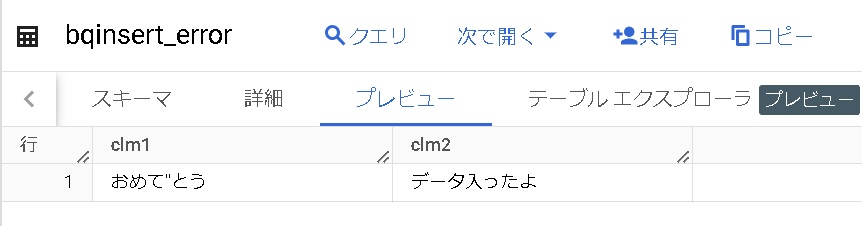
おめて”とうございます。データが入りました。
データ両端の「”」が必要な場合
BigQueryに「”おめて”とう”」の形で入れたい場合の解消方法です。
この場合は、引用符として別の文字を設定するのが一番簡単です。
bq loadのコマンドを使う場合、
されています。この引用符を変更することで解消可能です。
下記コマンドを実行します。
| 実行コマンド |
| bq load –skip_leading_rows=1 –quote=# yamaguchi_blog.bqinsert_error gs://yamaguchi_blog_bqerror/double_quote.csv |
今回は「#」を引用符として設定しましたが、データに含まれてなさそうな文字を選ぶのがポイントです。
コマンドを実行すると、
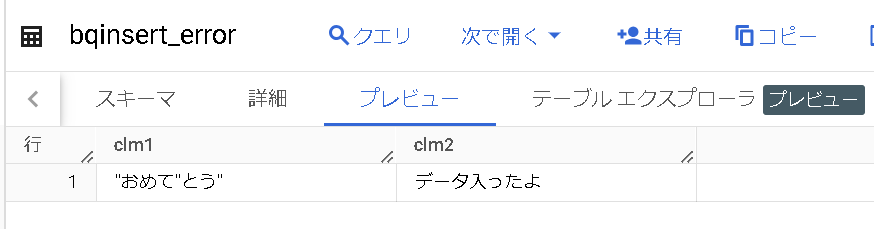
“おめて”とう”ございます。データが入りました。
エラー②:データ内に「,」がある
原因データ
CSVのデータ内に「,」があることで区切り位置がおかしくなり、「テーブルのスキーマ数とレコードのデータ数が合わないよ。」と怒られるエラーです。
こんなデータの時に発生します。

スキーマ数が2つなのに対し、データが3つになっていますね。
発生するエラー
こんなエラーが発生します。
「行内のデータが多すぎるわ、Y個だと思ってたらX個あったわ。」といった感じですね。
解消方法
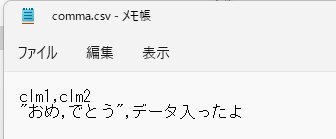
本来ならばCSV形式のデータ内の「,」はご法度ですが、今回は特別に「,」がデータ内にある状態で取り込む方法をご紹介します。
データ全体を引用符で囲む
先ほども登場した、引用符が活躍します。
| 実行コマンド |
| bq load –skip_leading_rows=1 yamaguchi_blog.bqinsert_error gs://yamaguchi_blog_bqerror/comma.csv |
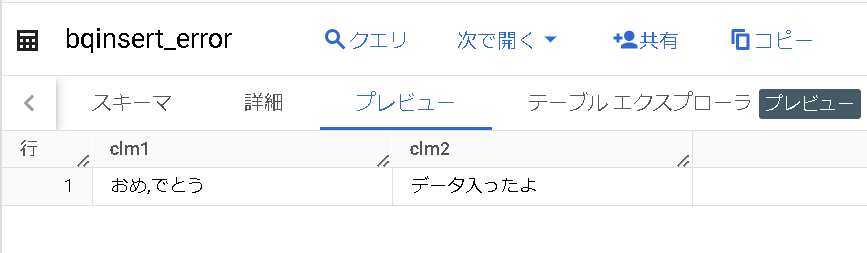
おめ,でとうございます。データが入りました。
区切り文字をタブ文字に変更する
区切り文字の変更で回避することも可能です。
この方法は、大規模なデータの際に有効です。
データのエクスポート時に区切り文字を「タブ文字」に変更しておくことで、全データに対する置換処理を省くことができます。
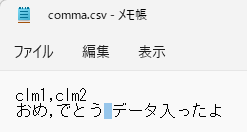
わかりづらいですが、色付部分がタブ文字になってます。
| 実行コマンド |
| bq load –skip_leading_rows=1 –field_delimiter=’\t’ yamaguchi_blog.bqinsert_error gs://yamaguchi_blog_bqerror/comma.csv |
区切り文字(field_delimiter)をタブ文字に変更しています。
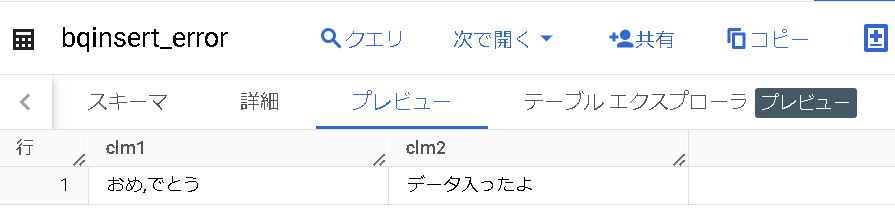
おめ,でとうございます。データが入りました。
エラー③:データ内に「改行」がある
原因データ
データ内に改行が含まれる際に発生します。
発生するエラー
こんなエラーが発生します。
contains only Y columns.
テーブルのX番目にあたるデータを見ようとしたけど、データがY個しかないよ。といった感じです。
データがまだ続くと思いきや改行があり、(実際には次の行にデータが続くが)その先データが無いように見えているのであれ?となっているんですね。
解消方法
改行許可オプションを使う
改行許可オプション「—allow_quoted_newlines」という便利なものが用意されています。これを使って解消します。
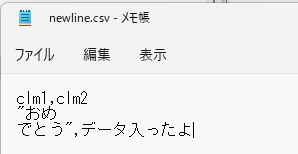
このオプションを使うには、データを引用符(デフォルトでは「”」)で囲む必要があります。
| 実行コマンド |
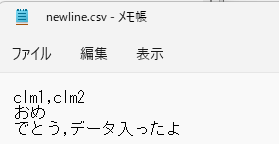
| bq load –skip_leading_rows=1 —allow_quoted_newlines=true yamaguchi_blog.bqinsert_error gs://yamaguchi_blog_bqerror/newline.csv |
改行許可オプションを有効にしています。
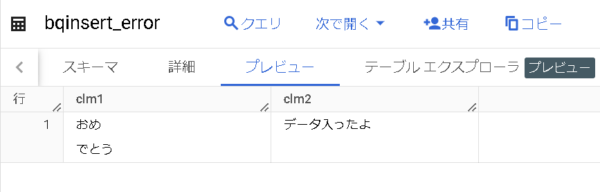
おめ
でとうございます。データが入りました。
まとめ
BigQueryにCSVデータを取り込む際にあたったエラーを備忘録を兼ねてまとめました。
大規模データの際は、これらのエラーが複合的に出てくることがあります。
その際も、今回ご紹介した解消方法を組み合わせることで(だいたいは)解消可能です。
また新たなエラーに遭遇した際は共有します。